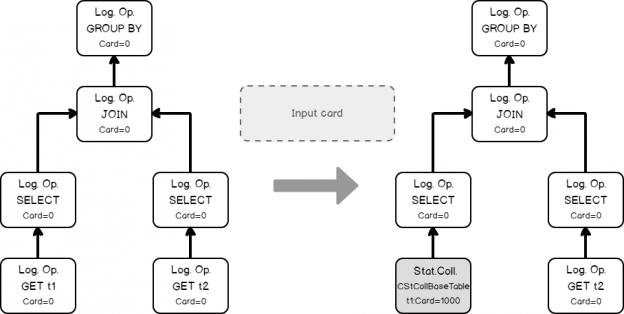
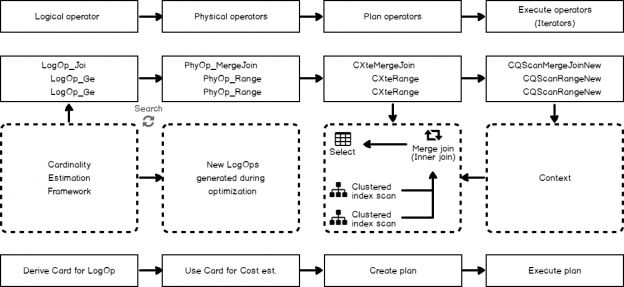
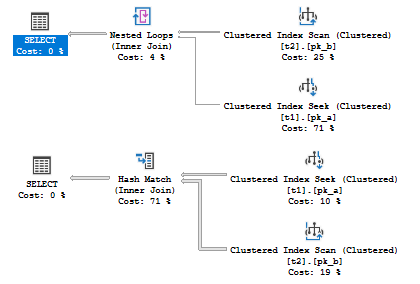
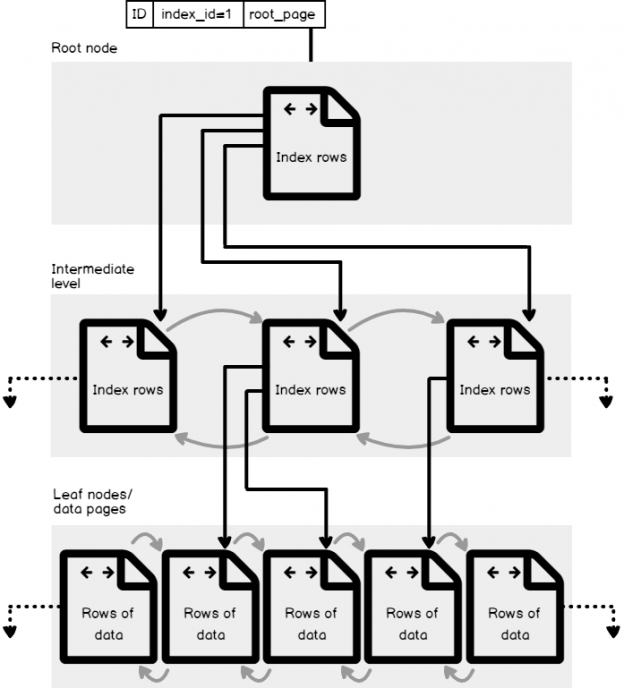
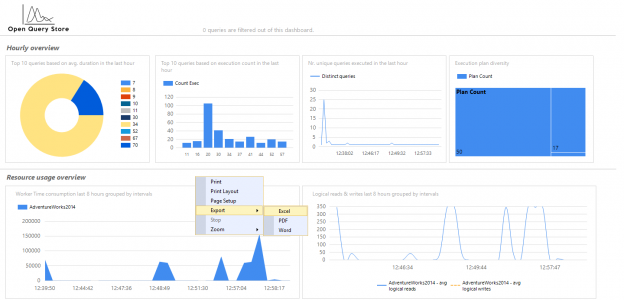
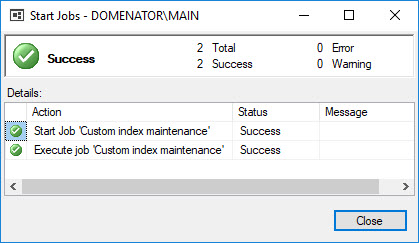
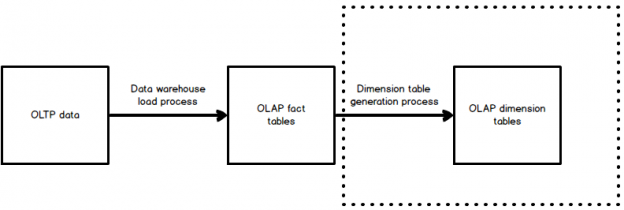
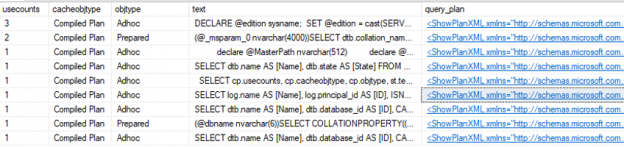
SQL Server Agent can be used to run a wide variety of tasks within SQL Server. The built-in monitoring tools, though, are not well-suited for environments with many servers or many databases.
Removing reliance on default notifications and building our own processes can allow for greater flexibility, less alerting noise, and the ability to track failure conditions that are not typically tracked by SQL Server!
Introduction
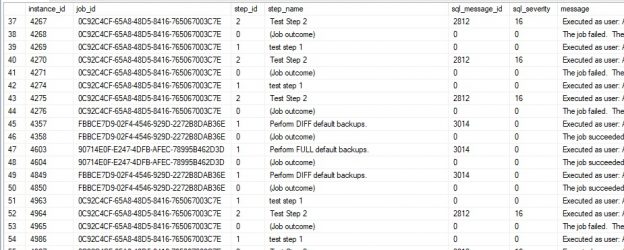
At the heart of the SQL Server Agent service is the ability to create, schedule, and customize jobs. These jobs can be given schedules that determine at what times of day a task should execute. Jobs can also be given triggers, such as a server restart or alert to respond to. Jobs can also be called via TSQL from anywhere that has the appropriate access and permissions to SQL Server Agent.
Read more »