The purpose of this article is to give newbies some basic advice about SQL performance tuning that helps to improve their query tuning skills in SQL Server.
Read more »
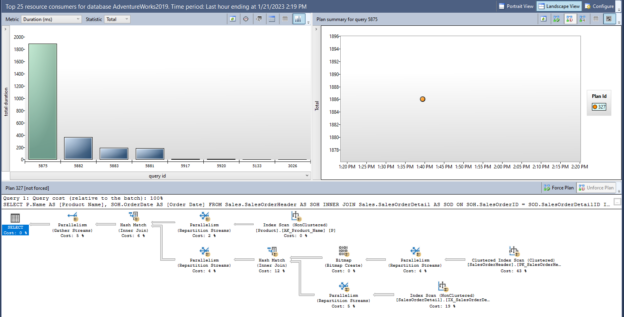
The purpose of this article is to give newbies some basic advice about SQL performance tuning that helps to improve their query tuning skills in SQL Server.
Read more »
This article explains some of the popular SQL Server monitoring tools and techniques.
Read more »
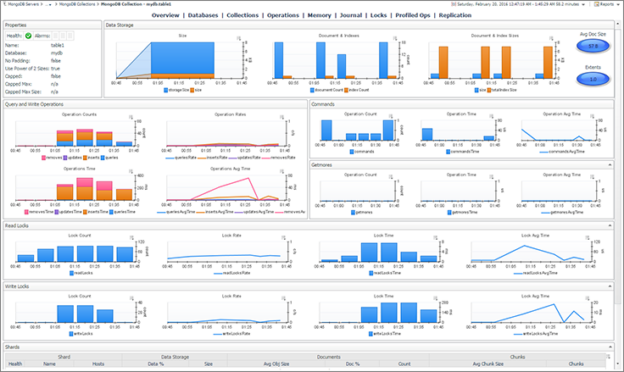
This article explains what database monitoring is and why it is essential. Then, it illustrates the different methods for monitoring MongoDB NoSQL databases.
Read more »
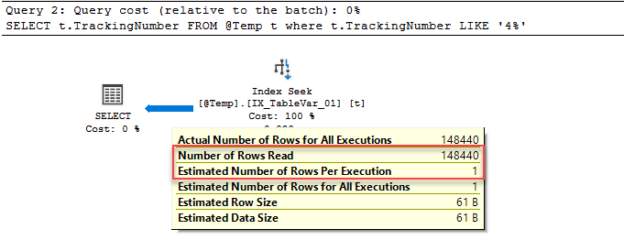
In this article, we are going to make a SQL practice exercise that will help to prepare for the final round of technical interviews of the SQL jobs.
Read more »
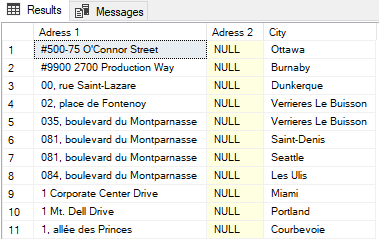
In this article, we are going to learn some best practices that help to write more efficient SQL queries.
Queries are used to communicate with the databases and perform the database operations. Such as, we use the queries to update data on a database or retrieve data from the database. Because of these functions of queries, they are used extensively by people who also interact with databases. In addition to performing accurate database operations, a query also needs to be performance, fast and readable. At least knowing some practices when we write a query will help fulfill these criteria and improve the writing of more efficient queries.
Read more »
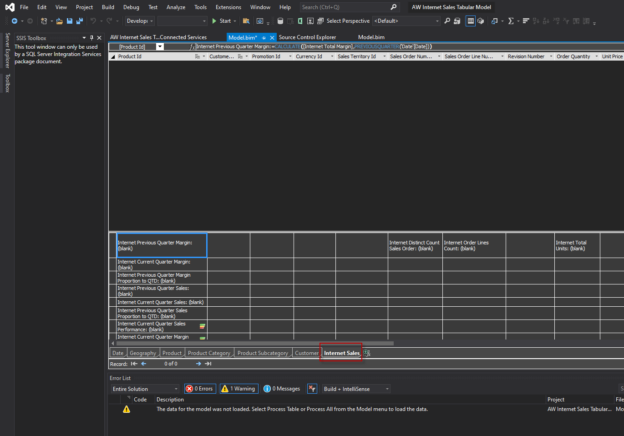
In SQL Server there are several kinds of SQL partitions. However, in general, we can say that a partition is a way to divide a table (sometimes a view) into smaller pieces for performance purposes. In this article, we will explain what partition does mean for a table partition and SSAS. We will also provide some guidance to automate the partition process.
Read more »
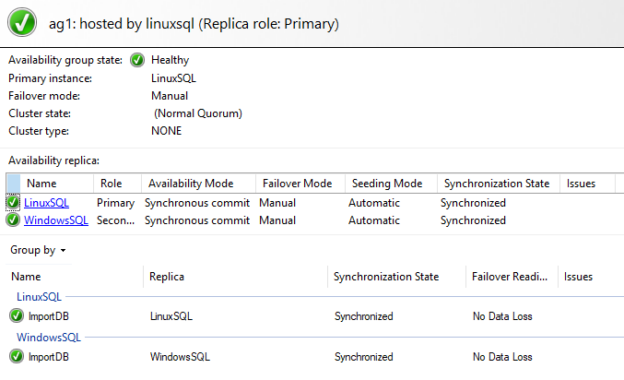
This article for the Always On Availability Groups series will show how to configure SQL Server Always On Availability Groups between Windows and Linux SQL instances.
Read more »
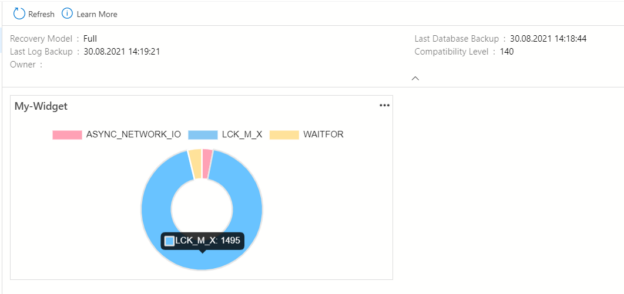
In this article, we will learn how to build a customized widget in Azure Data Studio that helps to monitor the performance metrics.
Read more »
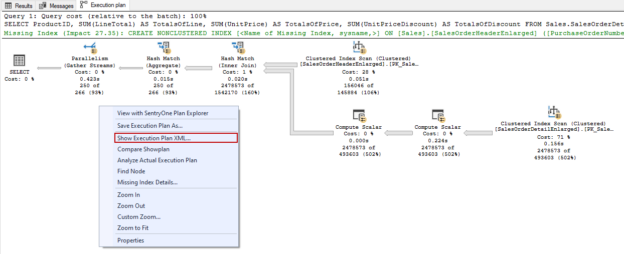
In this article, we will learn various methods of how to get an SQL execution plan of a query.
Read more »
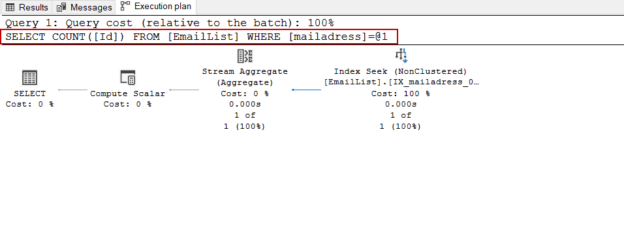
The purpose of this article is to provide insights into how parameter sniffing occurs for an ad-hoc query and how it affects their performance.
Read more »
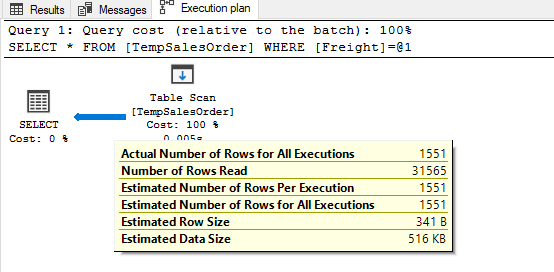
In this article, we will explore some internal working principles of SQL Server statistics.
Read more »
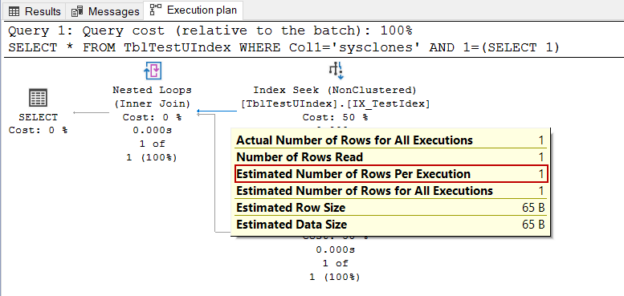
The goal of this article is to throw light on the less-known points about SQL Server statistics.
Read more »
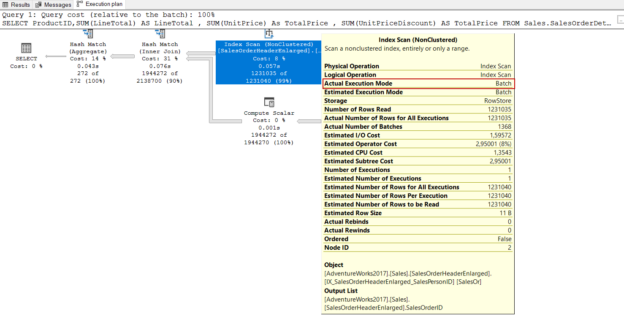
In this article, we will explore Microsoft SQL Server trace flags with all aspects, and we will learn also how to use them.
Read more »
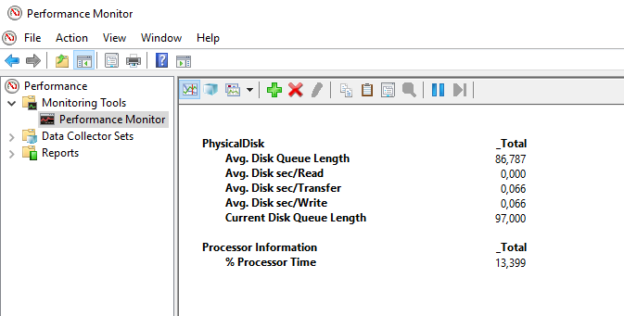
This article gives fundamental insights into which 5 reasons can cause to drop off the query performances in SQL Server.
Read more »
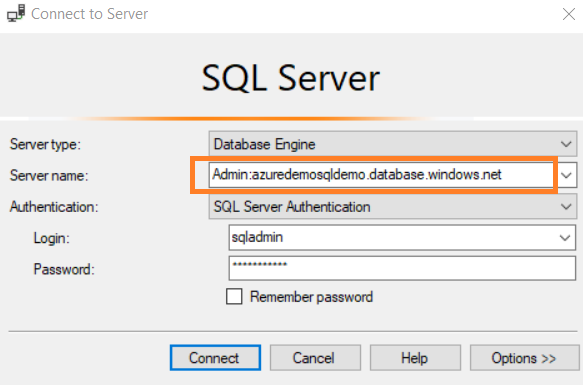
This article explains SQL Server Dedicated Administrator Connections and how you can use it for Azure SQL Database.
Read more »
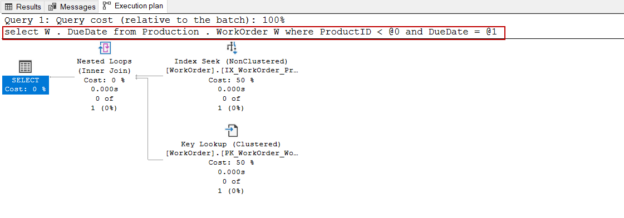
The goal of this article is to give details about the database query parameterization feature and explain its effects on query performance.
Read more »
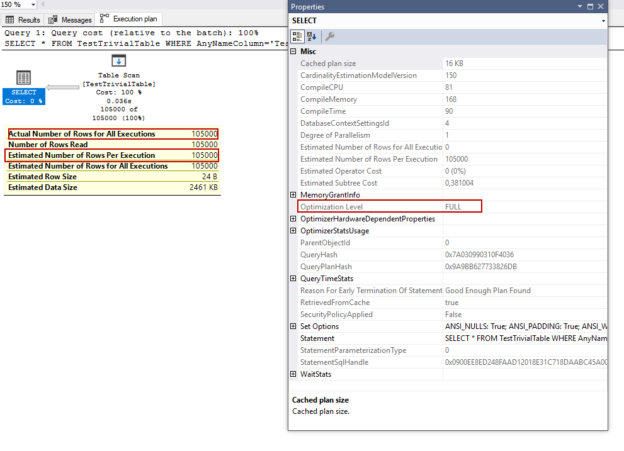
In this article, we will go through the details of the trivial execution plans and we will also tackle some examples about the trivial plans to explore effects on query performance.
Read more »
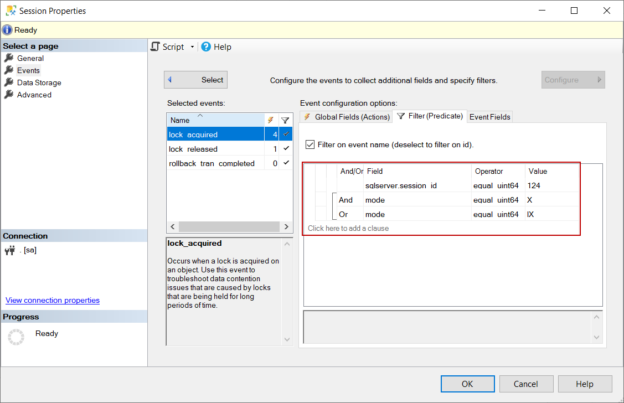
In this article, we will explore the details of what happens behind the scenes when a SQL delete statement is executed.
Read more »
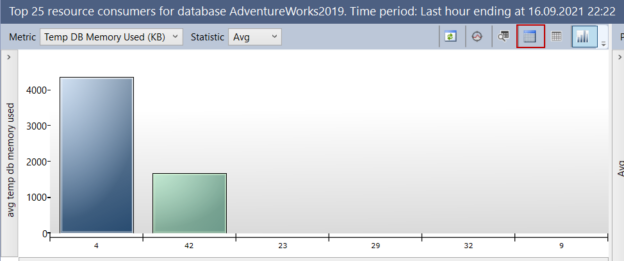
In this article, we will learn how we can detect which operations cause to fill up SQL Server tempdb through the dynamic management views.
Read more »
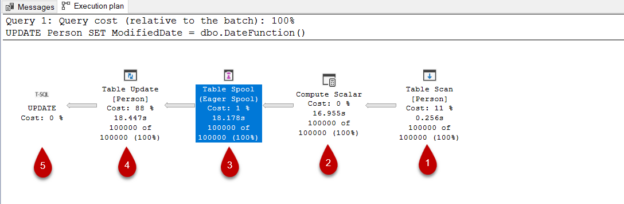
The SQL update statement is used to modify an existing record or records in a table and it is commonly widely used in databases applications. In this article, we will examine the update statement in terms of the performance perspective.
Read more »
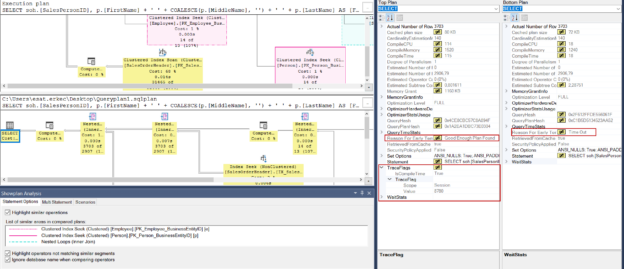
In this article, we will learn some query hints and trace flags that impact the query performance and also influence the SQL Server query optimizer’s default execution plan generation algorithm.
Read more »
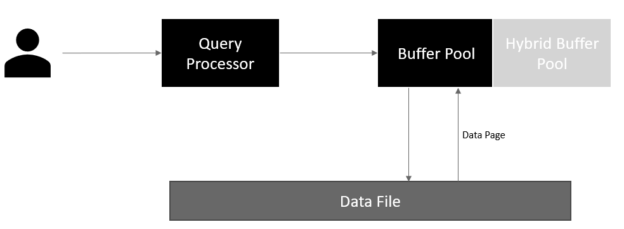
This article explores the Hybrid Buffer Pool feature available in the SQL Server 2019.
Read more »
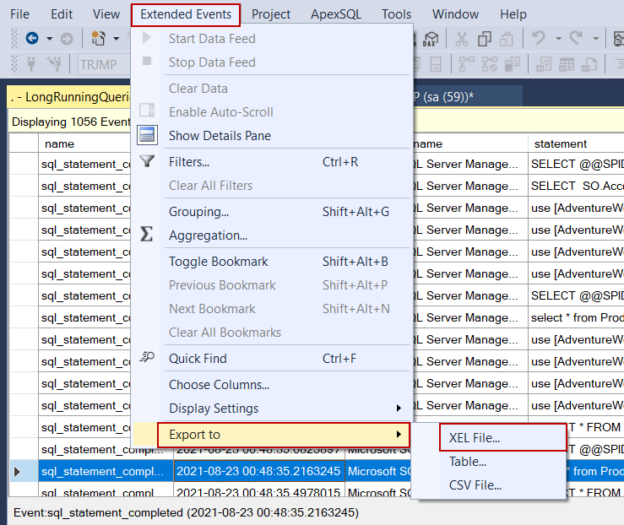
This article aims to provide some beneficial tips about SQL Server extended events that make it easier to create and use event sessions.
Read more »
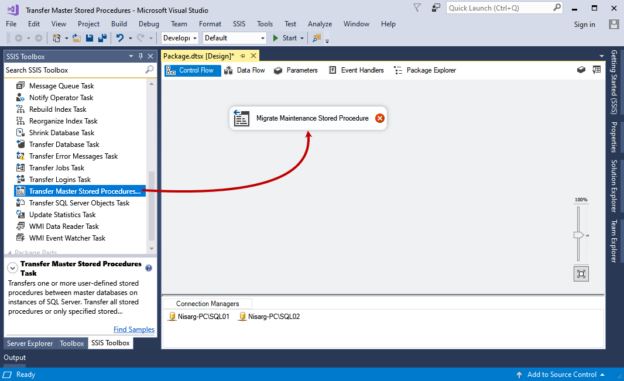
This is the second article in the series of Migrating SQL Server Objects using SSDT 2017. In this article, we will learn how to copy user stored procedures created in the SQL Server master database.
Read more »
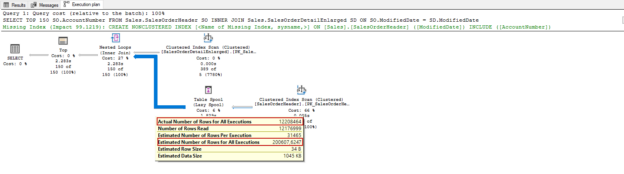
In this article, we will discuss the performance details of the SQL TOP statement, and we will also work on a performance case study.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy