
In this article, we will explore Nested and Merge SQL Loops in the SQL Execution plan from a performance tuning view.
Even though reading execution is technical, it is more an art than science. The main iterator used when joining tables is a Loop. Nested and Merge loops are 2 of the most common. A plan can even have a loop without joining tables when a Seek needs a Lookup to find additional columns. This art of reading execution plan loops can help with performance tuning and debugging T-SQL. Once over the hump of reading a plan, going from beginner to intermediate is simple.
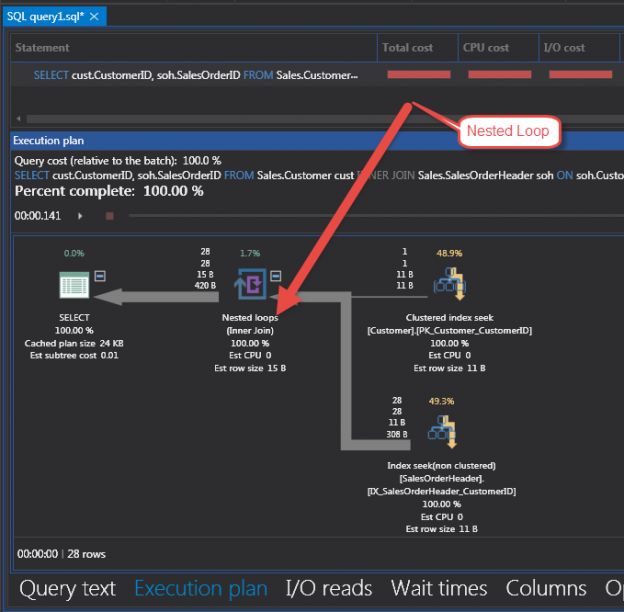
The first loop to look at is the Nested SQL Loop. Figure 1 is a Nested Loop from the INNER JOIN of tables SalesOrderHeader and Customer in the Adventure Works database.

The actual T-SQL is in the Code 1 example below. This example shows a Clustered Index Seek finding one row in the Customer table from the WHERE clause CustomerID = 11091.
|
1 2 3 4 5 |
SELECT cust.CustomerID, soh.SalesOrderID FROM Sales.Customer cust INNER JOIN Sales.SalesOrderHeader soh ON soh.CustomerID = cust.CustomerID WHERE cust.CustomerID = 11091 |
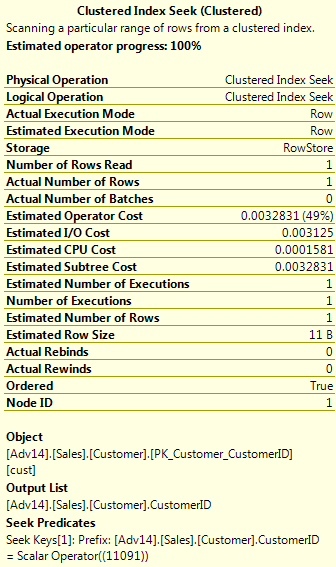
The WHERE clause in the T-SQL looks for key of the customer table. The Clustered Index Seek in Figure 1 returns one row for the customer in the PK_Customer_CustomerID index. This is the Primary Key (and clustered index) of the Sales.Customer table. Figure 2 shows the detail properties of the Seek Iterator. These properties include Cost, Rows, descriptions and many others that are helpful. The cost is separated into I/O, CPU, Subtree and Operator.
The one row from the Customer seek is then passed to the Nested SQL Loop to find the data in the joined table SalesOrderHeader. The outer part of the loop is where the data from the Clustered Index Seek is processed. In this case, there is only one row to traverse the outer loop. The inner loop takes each value from the outer SQL loop and processes more information.
The SalesOrderHeader table is being joined and requested for column SalesOrderId in the SELECT statement. The iterator from Figure 1 is an Index Seek on the index IX_SalesOrderHeader_CustomerID from SalesOrderHeader table. This is a non-clustered index seek to find data related to that one customer. It uses the _CustomerId index because the SalesOrderId is in the index. It is in the index because that Id is the Clustered Index (Primary Key) of the SalesOrderHeader table. The script for the both indexes is below in Code 2.
|
1 2 3 4 5 6 7 8 9 |
ALTER TABLE [Sales].[SalesOrderHeader] ADD CONSTRAINT [PK_SalesOrderHeader_SalesOrderID] PRIMARY KEY CLUSTERED ( [SalesOrderID] ASC ) CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID] ON [Sales].[SalesOrderHeader] ( [CustomerID] ASC ) |
Initially, some people are confused about the SalesOrderId column not visible in the create of the non-clustered index IX_SalesOrderHeader_CustomerID. An understanding of clustered indexes is needed. When creating non-clustered indexes, SQL Server needs the Cluster Index column(s) in the non-cluster indexes to lookup data. It makes a lot of sense once this is understood. If there is no clustered index on table (Heap table), it will use a RowId lookup which is an internal id in a Table for uniquely identifying a row in a data page.
If other columns are added to the T-SQL SELECT, AccountNumber and OrderDate, the plan changes because the non-clustered index used in Figure 1 does not have these values.
|
1 2 3 4 5 |
SELECT cust.CustomerID, soh.SalesOrderID, soh.AccountNumber, soh.OrderDate FROM Sales.Customer cust INNER JOIN Sales.SalesOrderHeader soh ON soh.CustomerID = cust.CustomerID WHERE cust.CustomerID = 11091 |
Figure 3 shows the new plan with an additional Nested Loop to get the new columns from a lookup on the Clustered index of table SalesOrderHeader. The Index Seek is now an Index Seek plus Nested Loop to get additional columns in the Key Lookup of the clustered index.
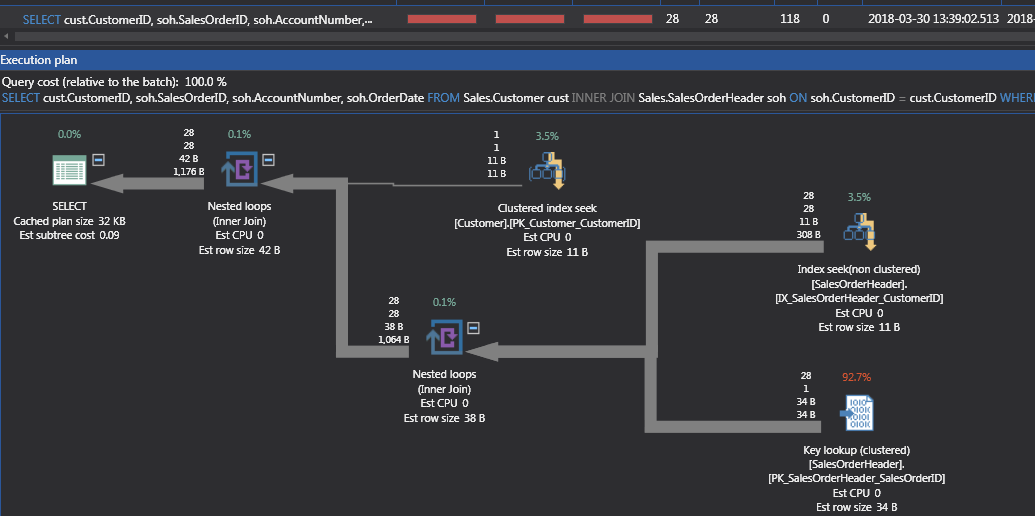
Figure 3 shows for each of the 28 records found in index IX_SalesOrderHeader_CustomerID a row is retrieved from the Clustered Index PK_SalesOrderHeader with Iterator Key Lookup. If the cost of the Key Lookup for the Clustered Index cost too much, a covering index could be created to improve performance. Code 4 shows a covering index that would help this query.
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_IncludeAcctNumOrderDate] ON [Sales].[SalesOrderHeader] ( [CustomerID] ASC ) INCLUDE (AccountNumber, OrderDate) |
This new index now ‘covers’ the query with additional columns. Figure 4 shows the new plan which no longer has the second Nested SQL Loop and uses the index created in Code 4 to get additional information.

NOTE: If this query changes, like more columns in the SELECT, the plan might change back to the one in Figure 3. Always monitor the usage of indexes on a database.
The Merge Loop is simpler than a Nested Loop. The data being merged together must be in the same order. The merge works like a zipper. The data is sorted on both streams as part of the join, and as intersections of the 2 streams happen, the data is joined together.
|
1 2 3 4 |
SELECT P.Name, total_qty = SUM(I.Quantity) FROM Production.Product P JOIN Production.ProductInventory I ON I.ProductID = P.ProductID GROUP BY P.Name |
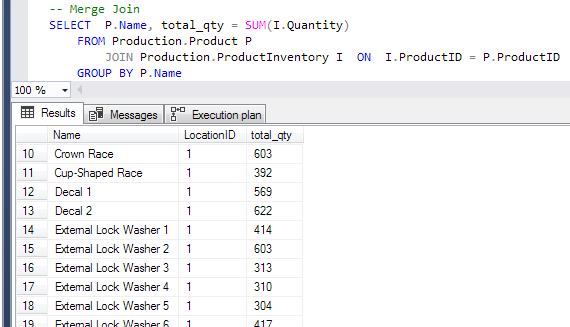
The T-SQL in Code 5 shows the joining of the Product table with the ProductInventory table. Since the key column is ProductID, both tables either have a Clustered or Non-Clustered Index to retrieve the data. The key field in the indexes is ProductID and is the first column in the main part of the index. Figure 5 shows a Merge Join in the execution plan.
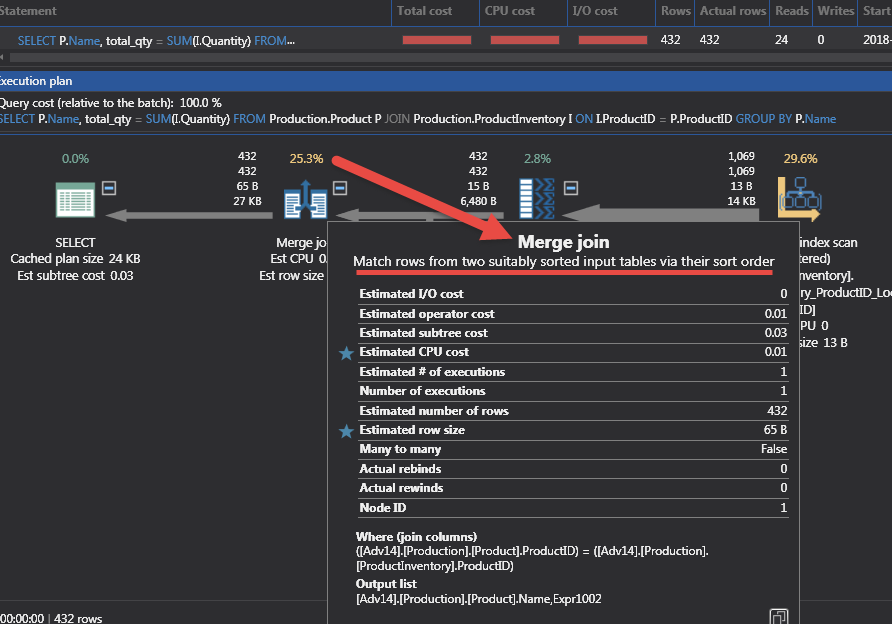
The outer part of the SQL loop is going through the ProductId of the rows from ProductInventory and joins the rows with data from the table Product. ProductId is unique because it is the primary key of the Product table. The T-SQL needs the product table to satisfy the GROUP BY in the T-SQL. The ProductInventory table does not have the Product Name column but is needed for the Sum of Quantity.
The join between the 2 tables is where the plan indicates to get the ProductID. Be aware when there is a Sort iterator in this kind of execution plan. Sorts are high in the cost and it might be wiser to not use a GROUP BY or DISTINCT that forces a Sort.
|
1 2 3 4 5 |
-- Add some columns SELECT P.Name, I.LocationID, total_qty = SUM(I.Quantity) FROM Production.Product P JOIN Production.ProductInventory I ON I.ProductID = P.ProductID GROUP BY P.Name, I.LocationID |
The T-SQL in Code 6 adds the additional column LocationID to the SELECT and GROUP BY. The Actual Execution Plan changes are shown in Figure 7.
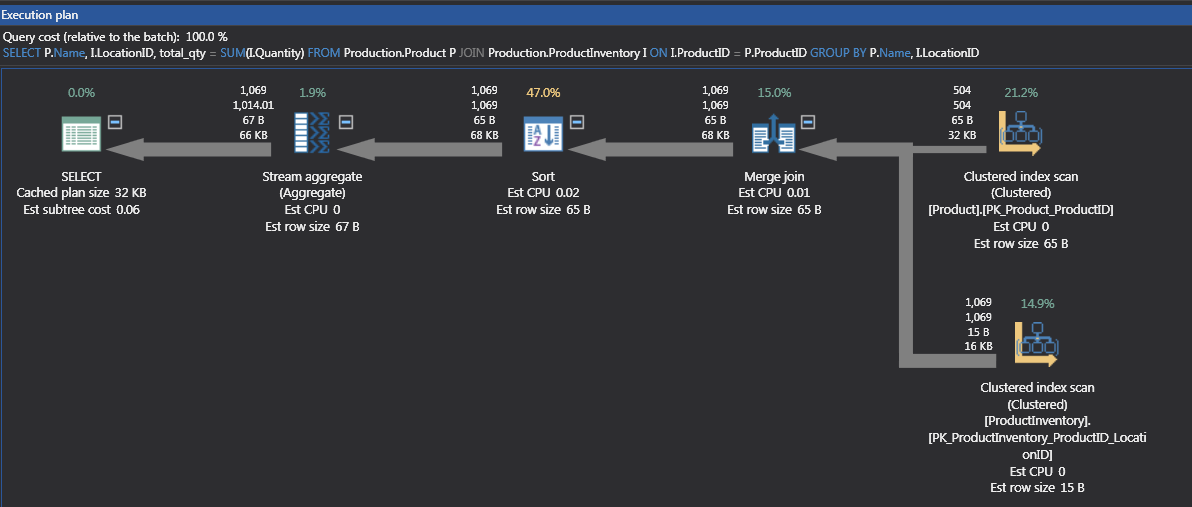
The new plan has a Sort added for the Product Name and Location ID combination, but we still have the Merge Join. The cost in Figure 7 show the Sort is 47% of the query. The Stream Aggregation has moved to the Left of the Merge Join because of the addition of the LocationId column. If the Sort is to costly, returning to the original T-SQL will product the first plan like in Figure 8.
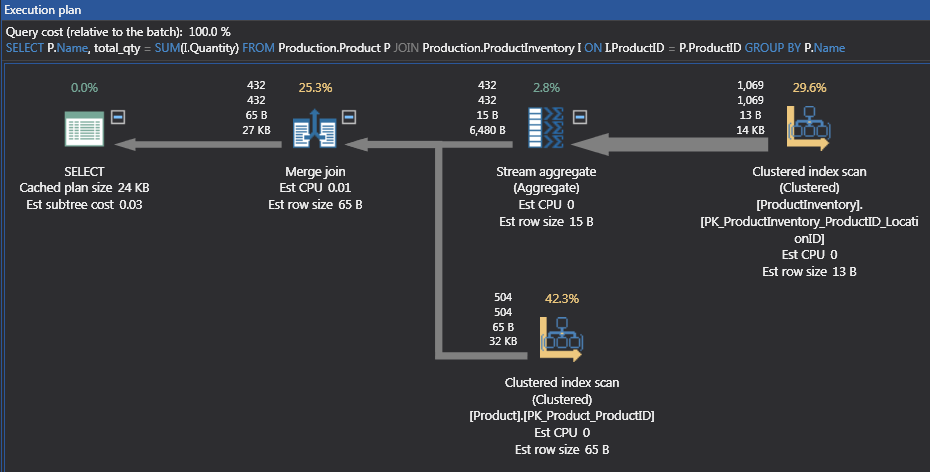
Seemingly simple additions can change a plan. Sometimes to the SQL loop but sometimes to another part of the plan like the new Sort iterator added for the new column. Knowing how to read a plan can help diagnose when a covering index can help or when adding a column can change a plan with a costly iterator. Even though the costly iterator is added, the cost might not be high even to be concerned. Usually the end user will notify IT if something is running too slow.
References

Starting as a developer in COBOL while at LSU, he has been a developer, tester, project manager, team lead as well as a software trainer writing documentation. Involvement in the SQL Server community includes speaking at SQLPASS.org Summits and SQLSaturday since 2011 and has been a speaker at IT/Dev Connections and Live! 360.
Currently, he is the Chair of the PASS Excel Business Intelligence Virtual Chapter and worked on the Nomination Committee for PASS Board of Directors for 2016.
View all posts by Thomas LeBlanc
- Performance tuning – Nested and Merge SQL Loop with Execution Plans - April 2, 2018
- Time Intelligence in Analysis Services (SSAS) Tabular Models - March 20, 2018
- How to create Intermediate Measures in Analysis Services (SSAS) - February 19, 2018