
We have discussed how to created estimated execution plans and actual execution plans in various formats in my previous article SQL Server Query Execution Plan for beginners – Types and Options.
In this article we will continue discussing the various execution plan operators related to clustered indexes, and what they do, when do they appear and what happens when they do.
When you look at execution plans and start actually doing query optimizations, each of these operators will provide you with some indicator of how SQL server is running.
These operators need to be understood, fundamentally, from the contextual activity, when they are seen, whether they are good or bad, as it pertains to performance implications.
If an operator occurs, we should be able to determine the action plan that we need to take so that these operators do not arise again or if they do arise we understand why.
It is most critical to understanding that these particular recommendations have to be taken with a pinch of salt but can be used without much of harm to SQL server.
Let me start with a table scan.
Table scan
- When: Table Scans occur when a table without a clustered index is accessed. Hence, there is no specific order in which SQL server goes about storing them, this particular heap is to be actually queried like in table scan.
- Good or bad: For very small tables it does not sometimes make difference. But if it is for a larger number of rows, you will not be happy with the appearance of this operator.
- Action item: Create a clustered index. Generally, a good practice is that if you have only one index on the table, it is better to be a clustered index.
Now, let me show you table scan operator. We will create the following simple table depending on [SalesOrderDetail] table from [AdventureWorks2014] database using the following script:
|
1 2 3 4 5 6 |
USE AdventureWorks2014 GO SELECT * INTO [SQL_SHACK].[dbo].[MySalesOrderDetail] FROM [AdventureWorks2014].[Sales].[SalesOrderDetail] GO |
Then, I will demonstrate something interesting.
First, let us try to select * from our sample table with including actual execution plan and statistics IO.
|
1 2 3 4 |
SET STATISTICS IO ON GO SELECT * FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] |
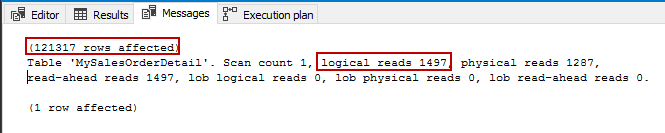
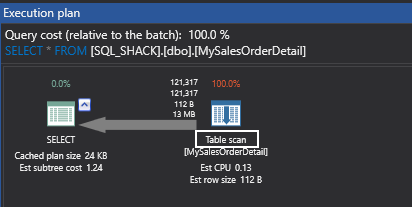
Here you can notice that we get the result of 121,317 rows with logical reads of 1,497.
Now, let us try to run the same query using a specific range of values:
|
1 2 3 4 5 |
SET STATISTICS IO ON GO SELECT * FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE SalesOrderID = 60726 AND SalesOrderDetailID = 74616 |
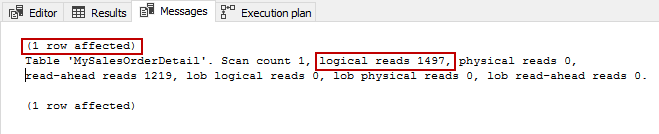
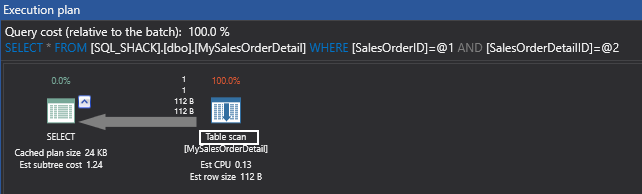
The interesting thing, alluded to previously, is that when you don’t have a clustered index you will end up with table scan which means you will have the same logical reads no matter how big the result you are selecting is. So, it will be much better if you have created a clustered index. This will be further demonstrated in the next section.
Clustered index scan
- When:
Table with a clustered index is accessed
- The table does not have non-clustered index
- The query cannot use the non-clustered index
- Good or bad: If I had to make a decision whether it is a good or bad, it could be a bad. Unless a large number of rows, with many columns and rows, are retrieved from that particular table, a Clustered Index Scan, can degrade performance.
- Action item: Evaluate clustered index keys
Clustered index seek
- When: A table with clustered index is being accessed and the B tree structure is able to narrow down, based on your clustered index, to get a limited set of rows from the table.
- Good or bad: This is the ideal condition. It is generally good to see the Clustered Index Seek
- Action item: Evaluate the possibility of using a non-clustered index, so that you gain the possibility of eliminating, if required, even the Clustered Index Seek.
For the previously created table “MySalesOrderDetail”, we are going to create a clustered index primary key on [SalesOrderID] and [SalesOrderDetailID].
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ALTER TABLE [SQL_SHACK].[dbo].[MySalesOrderDetail] ADD CONSTRAINT [PK_MySalesOrderDetail_SalesOrderID_SalesOrderDetailID] PRIMARY KEY CLUSTERED ( [SalesOrderID] ASC, [SalesOrderDetailID] ASC ) GO Now, let us go ahead and do the same, select all, from the table SET STATISTICS IO ON GO SELECT * FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] |

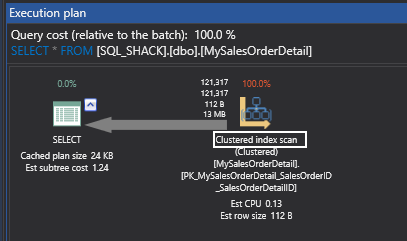
We can see that the query completes with 121,317 rows. Which is same as what we used to get before.
The messages tab, ironically, is giving me 1,502 logical reads. Now, this is a little bit more when compared to what we used to get with 1,497. The 5 additional pages that you are actually getting are based on the B tree that had to be formed because the intermediate notes and the first IAM had to be built and that is exactly what 1,502 is.
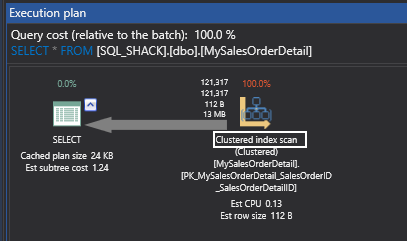
If I get to the execution plan here, you can see that unlike the previous time of Table Scan, you are getting Clustered Index Scan. This is a slight improvement that we have seen.
Now, let me get to the specific case where we went about doing value collection. In this particular case same as what we selected before
|
1 2 3 4 5 |
SET STATISTICS IO ON GO SELECT * FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE SalesOrderID = 60726 AND SalesOrderDetailID = 74616 |

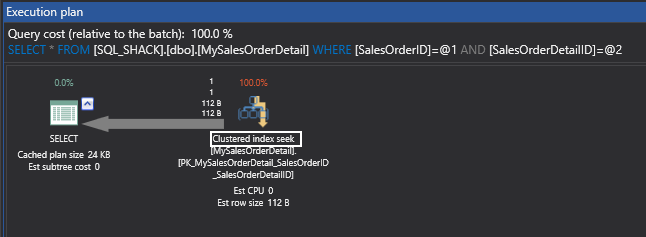
Here you get a single row and if I get to the messages tab I can see it shows three logical reads.
If I move to the execution plan, you can see the Clustered Index Scan which was in the previous case has been transformed into a Clustered Index Seek, hence SQL Server was able to narrow down, using the clustered index key, to obtain this particular value based on the where condition, which is in the seek predicate
Summary
Execution plans are a very important tool for optimizing query performance. Every DBA needs to know all operators that appear in the execution plan and decide whether it is good or bad and what to do if it is the latter. I tried to be simple in discussing the very basic details about the operators related only to clustered index. I hope this article has been informative for you.
Previous article in this series:

Living in Egypt, have worked as Microsoft Senior SQL Server Database Administrator for more than 4 years.
As a DBA, I design, install, maintain and upgrade all databases (production and non-production environments), I have practical knowledge of T-SQL performance, HW performance issues, SQL Server replication, clustering solutions, and database designs for different kinds of systems. I worked on all SQL Server versions (2008, 2008R2, 2012, 2014 and 2016).
I love my job as the database is the most valuable thing in every place in the world now. That's why I won't stop learning. In my spare time, I like to read, speak, learn new things and write blogs and articles.
View all posts by Ayman Elnory
- SQL Server Query Execution Plans for beginners – NON-Clustered Index Operators - April 24, 2018
- SQL Server Query Execution Plans for beginners– Clustered Index Operators - March 5, 2018
- A walk through the SQL Server 2016 full database backup - February 12, 2018