
SQL Server Agent can be used to run a wide variety of tasks within SQL Server. The built-in monitoring tools, though, are not well-suited for environments with many servers or many databases.
Removing reliance on default notifications and building our own processes can allow for greater flexibility, less alerting noise, and the ability to track failure conditions that are not typically tracked by SQL Server!
Introduction
At the heart of the SQL Server Agent service is the ability to create, schedule, and customize jobs. These jobs can be given schedules that determine at what times of day a task should execute. Jobs can also be given triggers, such as a server restart or alert to respond to. Jobs can also be called via TSQL from anywhere that has the appropriate access and permissions to SQL Server Agent.
The built-in notification system allows you to define operators and contact them when a job fails. While convenient, this does not scale well when large numbers of servers are involved, large numbers of jobs exist, or when more complex jobs are devised.
Customizing a job failure notification process is far simpler than it may seem, and in this article, we will walk through how to gather the necessary SQL Server Agent history data and use it to alert operators in far more meaningful ways than the default tools allow.
How Does SQL Server Agent Track Job Status?
SQL Server Agent maintains job, schedule, and execution details in tables within the MSDB database. The following tables provide what we will need to capture to track and alert on failures:
MSDB.dbo.sysjobs
This table contains a row per SQL Server Agent job defined on a given SQL Server instance:
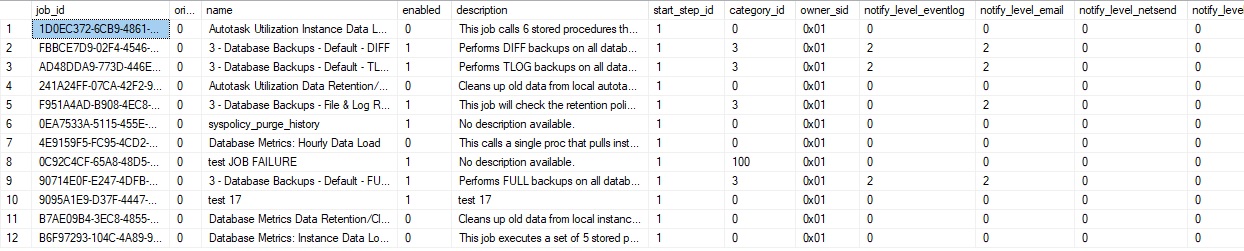
The job_id is a UNIQUEIDENTIFIER that ensures a unique primary key for each job. This table also provides the name, description, create/modify dates, and a variety of other useful information about the job. This table can be queried to determine how many jobs exist on a server or to search based on a specific string in job names or descriptions. We could also search based on owner_sid to determine if any jobs are owned by the wrong login (such as a departing employee or job creator).
MSDB.dbo.syscategories
From within a SQL Server, you may select a category for each job. This allows for classification of reports, data collection processes, alerts, etc…When acting on jobs, we can take that category into account in order to increase the priority of some jobs or decrease the priority of others. For example, we could set some jobs as unmonitored and ignore them. Alternatively, we could set some jobs as critical and have them hit up the on-call operator’s cell phone the moment they fail.
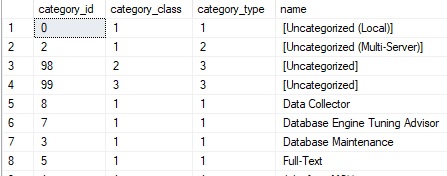
This table is simple enough, and is mostly useful to pull the category name. The category class & type are hard-coded literals that determine where an alert can be used:
- Class: 1 = job, 2 = alert, 3 = operator.
- Type: 1 = local, 2 = multiserver, 3 = none.
MSDB.dbo.sysjobhistory
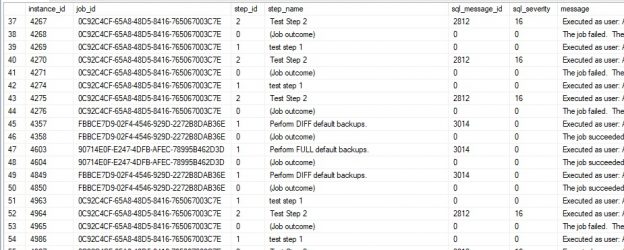
This table contains a row per SQL Server Agent job or job step. Both step status and overall job status are contained in this table:
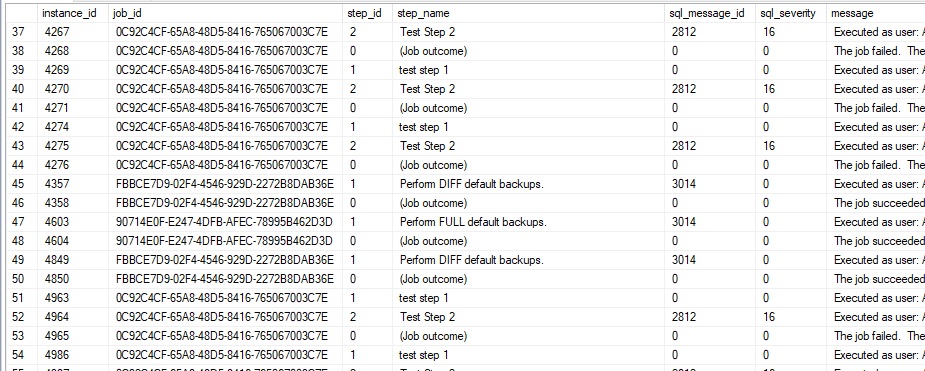
In addition to the corresponding job_id, step, and error information (if applicable), this table provides details on job runtime, run status, run date and time, and who was notified (if anyone).
Note that a row with step_id = 0 corresponds to the overall job status, and not that of any one step. It is possible for a job with no steps to fail or a job to fail prior to executing any job steps, therefore we can end up with an overall job status with no corresponding step success/failure details.
Sysjobhistory is only populated when a job or job step completes. In the unlikely event that a server restarts abnormally or SQL Server Agent crashes, then it is possible for a job to not be completely logged in this table (or logged at all).
Because this data exists and is readily accessible to us, we can collect, analyze, and use it for notification purposes.
Limitations of Built-In Notifications
By default, you can add notification steps to any SQL Server Agent jobs, either via the GUI or TSQL:
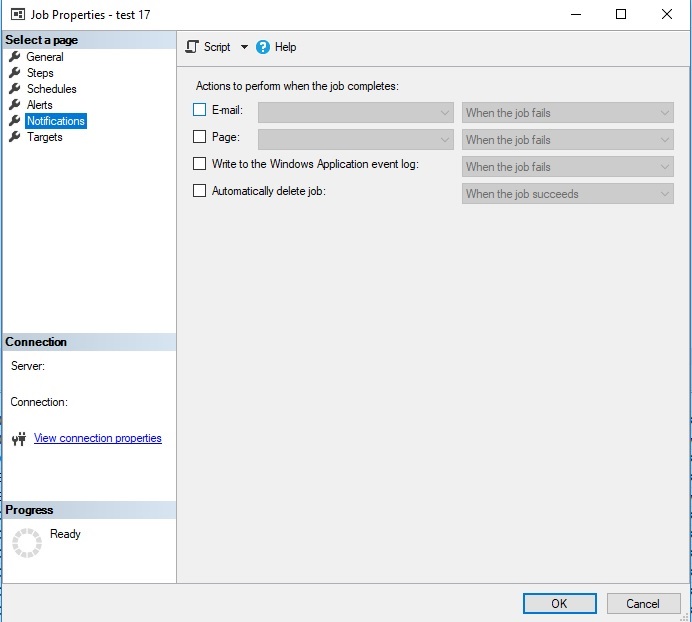
Whether a job fails, succeeds, or completes, you may add an email/page/logging to the end of it. While useful, this only addresses the state of a job when it completes, and not of any specific steps. In reality, we may care about the status of individual steps and wish to act on them on a more granular basis.
A significant (and somewhat confusing) caveat to how SQL Server Agent handles job step failures is that you may configure a job to continue executing, even if a step fails. In the event that a job step fails, the job continues, and future steps succeed, the job will report success, despite one or more steps failing. This is not easy to alert on in SQL Server and common solutions involve either breaking a job into numerous smaller jobs or adding customized alerting steps as needed.
For our purposes, we’d like to build a failure notification job that is simple and all-encompassing. The following are all possible failure conditions that we may wish to report on:
- A job fails due to one or more steps failing.
- A job succeeds, but one or more steps fail and we wish to report on those failures.
- All steps in a job succeed, but the job itself fails. This is often the result of a job configuration issue.
- A job fails that has no steps defined for it.
- A job fails prior to any steps executing. This is often the result of a job configuration issue.
To alert on all of these effectively, we will need to write some of our own code to detect, log, and report on them.
Another limitation of built-in notifications are the contents of the alert that you receive. Selecting a notification as shown above will result in a single pre-fabricated notification whenever it is triggered. This is good for letting you know that a job failed, but the included information is often not enough to troubleshoot without going back to the job and reading more details of the failure. The following is an example of what the subject and body of a default SQL Server Agent notification would look like:
SQL Server Job System: ‘Test Job’ completed on EdSQLServer
JOB RUN: ‘Test Job’ was run on 3/5/2018 at 07:00:00 AM
DURATION: 0 hours, 0 minutes, 17 seconds
STATUS: Failed
MESSAGES: The job failed. The Job was invoked by Schedule 3 (Daily at 7am). The last step to run was step 1 (Run the test script!).
This is useful, but could be far more useful. For starters, the error message is only the job failure message and does not include the detailed failure info from any failed job steps. Ideally, enough details would be provided in the alert to ensure that you could respond immediately, and not need to dig further for error messages every single time this happens. Customizing an alert process allows us to include as much (or as little) detail as we wish in order to make the notifications we receive as actionable as possible!
Building A Better Notification System
To build as simple of a job failure alert system as possible, we’ll follow a handful of steps to plan out and execute this project:
- Create tables to store job and job failure details.
- Create a stored procedure that logs recent job and failure details to these tables.
- Create a job that regularly calls this stored procedure.
A goal in this process is to keep things as basic as possible. There are many opportunities available here for overengineering a perpetual motion machine, but alerting on important failures is ideally simple so as to be as reliable as possible.
We’ll start by building a table that will store a list of SQL Server Agent jobs. Why build a table when MSDB already includes the sysjobs table? If a job is deleted, we want to retain the old job record for posterity. This allows us to report on failures for jobs that may have been recently deleted. It also allows us to retain information about past failures for jobs that no longer exist. Similarly, if we ever were to migrate this database to a new server or install a new version of SQL Server, then having the old job data will ensure that all of our job failure details will remain useful and not be associated with orphaned/unavailable job data in MSDB.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE dbo.sql_server_agent_job ( sql_server_agent_job_id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_sql_server_agent_job PRIMARY KEY CLUSTERED, sql_server_agent_job_id_guid UNIQUEIDENTIFIER NOT NULL, sql_server_agent_job_name NVARCHAR(128) NOT NULL, job_create_datetime_utc DATETIME NOT NULL, job_last_modified_datetime_utc DATETIME NOT NULL, is_enabled BIT NOT NULL, is_deleted BIT NOT NULL, job_category_name VARCHAR(100) NOT NULL); |
This table, in addition to keys, includes the job name, create/modify times, its category, and flags to indicate whether the job has been disabled or deleted. Feel free to add additional columns for any job metadata that is useful to you, but might not be listed here. We create a surrogate integer clustered primary key to avoid the need to have to index, join, and filter on the larger UNIQUEIDENTIFIER data type. If you are working with servers that have a very short and stable SQL Server Agent job list, then you could easily use a SMALLINT or even a TINYINT for the primary key ID column.
With a SQL Server Agent job table available, we can now build a table to store job failure metrics:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE dbo.sql_server_agent_job_failure ( sql_server_agent_job_failure_id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_sql_server_agent_job_failure PRIMARY KEY CLUSTERED, sql_server_agent_job_id INT NOT NULL CONSTRAINT FK_sql_server_agent_job_failure_sql_server_agent_job FOREIGN KEY REFERENCES dbo.sql_server_agent_job (sql_server_agent_job_id), sql_server_agent_instance_id INT NOT NULL, job_start_time_utc DATETIME NOT NULL, job_failure_time_utc DATETIME NOT NULL, job_failure_step_number SMALLINT NOT NULL, job_failure_step_name VARCHAR(250) NOT NULL, job_failure_message VARCHAR(MAX) NOT NULL, job_step_failure_message VARCHAR(MAX) NOT NULL, job_step_severity INT NOT NULL, job_step_message_id INT NOT NULL, retries_attempted INT NOT NULL, has_email_been_sent_to_operator BIT NOT NULL); CREATE NONCLUSTERED INDEX NCI_sql_server_agent_job_failure_sql_server_agent_job_id ON dbo.sql_server_agent_job_failure (sql_server_agent_job_id); CREATE NONCLUSTERED INDEX NCI_sql_server_agent_job_failure_sql_server_agent_instance_id ON dbo.sql_server_agent_job_failure (sql_server_agent_instance_id); |
This table contains a foreign key back to our newly created job table above. It also contains details of the failed job, including the start/fail time of the job and details of the error. The last column is a flag that will be used to signify when a failed job has been alerted on successfully, so that we do not repeatedly spam an operator with alerts on it. Note that we will include both the job failure and the step failure messages, allowing for easier troubleshooting directly from the alert, without the need to dig back into SQL Server Agent prior to resolving the problem.
The next step is to create a stored procedure that will check for job failures and place data into sql_server_agent_job_failure accordingly. This will be composed of a handful of steps:
- Update sql_server_agent_job with any new, deleted, or changed jobs.
- Collect data on new job failures.
- Collect data on new job step failures.
- Email an operator the details of these failures. Email can be replaced with another communication medium, if desired.
|
1 2 3 4 5 6 7 8 9 |
CREATE PROCEDURE dbo.monitor_job_failures @minutes_to_monitor SMALLINT = 1440 AS BEGIN SET NOCOUNT ON; -- Determine UTC offset so that all times can easily be converted to UTC. DECLARE @utc_offset INT; SELECT @utc_offset = -1 * DATEDIFF(HOUR, GETUTCDATE(), GETDATE()); |
Here is the stored proc declaration. @minutes_to_monitor tells it how far back to check for job failures. This will be set depending on how often you plan on running the monitoring job that calls this proc. My preference is to pull one day’s worth of data. This ensures that in the event of server maintenance, an outage, or some other interruption, we won’t miss any job failures. We’ll filter out already-alerted-on failures as we go, so that won’t be a problem.
We also pull the UTC offset and will store all DATE/TIME data in UTC time. This will result in more math needed up front, but more consistency for anyone that views this data. UTC can be converted to local time by determining the offset and adding it to the UTC time.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
MERGE INTO dbo.sql_server_agent_job AS TARGET USING (SELECT sysjobs.job_id AS sql_server_agent_job_id_guid, sysjobs.name AS sql_server_agent_job_name, sysjobs.date_created AS job_create_datetime_utc, sysjobs.date_modified AS job_last_modified_datetime_utc, sysjobs.enabled AS is_enabled, 0 AS is_deleted, ISNULL(syscategories.name, '') AS job_category_name FROM msdb.dbo.sysjobs LEFT JOIN msdb.dbo.syscategories ON syscategories.category_id = sysjobs.category_id) AS SOURCE ON (SOURCE.sql_server_agent_job_id_guid = TARGET.sql_server_agent_job_id_guid) WHEN NOT MATCHED BY TARGET THEN INSERT (sql_server_agent_job_id_guid, sql_server_agent_job_name, job_create_datetime_utc, job_last_modified_datetime_utc, is_enabled, is_deleted, job_category_name) VALUES ( SOURCE.sql_server_agent_job_id_guid, SOURCE.sql_server_agent_job_name, SOURCE.job_create_datetime_utc, SOURCE.job_last_modified_datetime_utc, SOURCE.is_enabled, SOURCE.is_deleted, SOURCE.job_category_name) WHEN MATCHED AND SOURCE.job_last_modified_datetime_utc > TARGET.job_last_modified_datetime_utc THEN UPDATE SET sql_server_agent_job_name = SOURCE.sql_server_agent_job_name, job_create_datetime_utc = SOURCE.job_create_datetime_utc, job_last_modified_datetime_utc = SOURCE.job_last_modified_datetime_utc, is_enabled = SOURCE.is_enabled, is_deleted = SOURCE.is_deleted, job_category_name = SOURCE.job_category_name; |
This TSQL performs a MERGE into our SQL Server Agent Job table. It matches on job_id, which is unique on each SQL Server and a reliable key for this purpose.
|
1 2 3 4 5 6 7 |
UPDATE sql_server_agent_job SET is_enabled = 0, is_deleted = 1 FROM dbo.sql_server_agent_job LEFT JOIN msdb.dbo.sysjobs ON sysjobs.Job_Id = sql_server_agent_job.sql_server_agent_job_id_guid WHERE sysjobs.Job_Id IS NULL; |
This additional query will check to see if any jobs no longer exist. That is, they are in sql_server_agent_job, but no longer in MSDB. We’ll flag any deleted jobs as disabled and deleted so that anyone reading this data knows that it is stored there for posterity and no longer references an active job.
A warning before we proceed: Dates, times, and statuses within many of the MSDB tables are stored using some outdated (read: scary) conventions. They were not stored as dates, times, datetimes, or even strings. Instead, times were stored as integers. For example, 8:41:53am is stored as 84153. Run durations were stored as integers. For example, a job that ran for 00:12:53 (twelve minutes and fifty-three seconds) will be stored as 1253. Lastly, dates are stored as VARCHAR(8) strings in the format YYYYMMDD. Converting this into more useful data types is critical to being able to meaningfully report on it.
As a result, we’re going to need some math and string manipulation to clean up dates and times that are stored as integer literals:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
WITH CTE_NORMALIZE_DATETIME_DATA AS ( SELECT sysjobhistory.job_id AS sql_server_agent_job_id_guid, CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS run_date_string, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS run_time_string, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS run_duration_string, sysjobhistory.run_status, sysjobhistory.message, sysjobhistory.instance_id FROM msdb.dbo.sysjobhistory WITH (NOLOCK) WHERE sysjobhistory.run_status = 0 AND sysjobhistory.step_id = 0), CTE_GENERATE_DATETIME_DATA AS ( SELECT CTE_NORMALIZE_DATETIME_DATA.sql_server_agent_job_id_guid, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 1, 4) AS DATETIME) + CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.run_time_string, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS job_start_datetime, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 1, 2) AS INT) * 3600 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 3, 2) AS INT) * 60 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 5, 2) AS INT) AS job_duration_seconds, CASE CTE_NORMALIZE_DATETIME_DATA.run_status WHEN 0 THEN 'Failure' WHEN 1 THEN 'Success' WHEN 2 THEN 'Retry' WHEN 3 THEN 'Canceled' ELSE 'Unknown' END AS job_status, CTE_NORMALIZE_DATETIME_DATA.message, CTE_NORMALIZE_DATETIME_DATA.instance_id FROM CTE_NORMALIZE_DATETIME_DATA) SELECT CTE_GENERATE_DATETIME_DATA.sql_server_agent_job_id_guid, DATEADD(HOUR, @utc_offset, CTE_GENERATE_DATETIME_DATA.job_start_datetime) AS job_start_time_utc, DATEADD(HOUR, @utc_offset, DATEADD(SECOND, ISNULL(CTE_GENERATE_DATETIME_DATA.job_duration_seconds, 0), CTE_GENERATE_DATETIME_DATA.job_start_datetime)) AS job_failure_time_utc, ISNULL(CTE_GENERATE_DATETIME_DATA.message, '') AS job_failure_message, CTE_GENERATE_DATETIME_DATA.instance_id INTO #job_failure FROM CTE_GENERATE_DATETIME_DATA WHERE DATEADD(HOUR, @utc_offset, CTE_GENERATE_DATETIME_DATA.job_start_datetime) > DATEADD(MINUTE, -1 * @minutes_to_monitor, GETUTCDATE()); |
Much of this TSQL is devoted to converting numeric representations of dates and times into an actual DATETIME that we can compare against. The first CTE cleans up those integers so that the run time and run duration string has leading zeroes to ensure it is 6 characters long. The second CTE converts these now uniform values into DATETIMEs using some very ugly string manipulation. The final SELECT converts those DATETIME values into UTC and places the results into a temporary table for use later in this stored proc.
Our next step is to build a very similar query that will return data on job step failures. We intentionally do this work in a separate query as we will need to join these data sets together, and having them in separate temporary tables will make this significantly easier:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 |
WITH CTE_NORMALIZE_DATETIME_DATA AS ( SELECT sysjobhistory.job_id AS sql_server_agent_job_id_guid, CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS run_date_string, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS run_time_string, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS run_duration_string, sysjobhistory.run_status, sysjobhistory.step_id, sysjobhistory.step_name, sysjobhistory.message, sysjobhistory.retries_attempted, sysjobhistory.sql_severity, sysjobhistory.sql_message_id, sysjobhistory.instance_id FROM msdb.dbo.sysjobhistory WITH (NOLOCK) WHERE sysjobhistory.run_status = 0 AND sysjobhistory.step_id > 0), CTE_GENERATE_DATETIME_DATA AS ( SELECT CTE_NORMALIZE_DATETIME_DATA.sql_server_agent_job_id_guid, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_date_string, 1, 4) AS DATETIME) + CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.run_time_string, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS job_start_datetime, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 1, 2) AS INT) * 3600 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 3, 2) AS INT) * 60 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.run_duration_string, 5, 2) AS INT) AS job_duration_seconds, CASE CTE_NORMALIZE_DATETIME_DATA.run_status WHEN 0 THEN 'Failure' WHEN 1 THEN 'Success' WHEN 2 THEN 'Retry' WHEN 3 THEN 'Canceled' ELSE 'Unknown' END AS job_status, CTE_NORMALIZE_DATETIME_DATA.step_id, CTE_NORMALIZE_DATETIME_DATA.step_name, CTE_NORMALIZE_DATETIME_DATA.message, CTE_NORMALIZE_DATETIME_DATA.retries_attempted, CTE_NORMALIZE_DATETIME_DATA.sql_severity, CTE_NORMALIZE_DATETIME_DATA.sql_message_id, CTE_NORMALIZE_DATETIME_DATA.instance_id FROM CTE_NORMALIZE_DATETIME_DATA) SELECT CTE_GENERATE_DATETIME_DATA.sql_server_agent_job_id_guid, DATEADD(HOUR, @utc_offset, CTE_GENERATE_DATETIME_DATA.job_start_datetime) AS job_start_time_utc, DATEADD(HOUR, @utc_offset, DATEADD(SECOND, ISNULL(CTE_GENERATE_DATETIME_DATA.job_duration_seconds, 0), CTE_GENERATE_DATETIME_DATA.job_start_datetime)) AS job_failure_time_utc, CTE_GENERATE_DATETIME_DATA.step_id AS job_failure_step_number, ISNULL(CTE_GENERATE_DATETIME_DATA.message, '') AS job_step_failure_message, CTE_GENERATE_DATETIME_DATA.sql_severity AS job_step_severity, CTE_GENERATE_DATETIME_DATA.retries_attempted, CTE_GENERATE_DATETIME_DATA.step_name, CTE_GENERATE_DATETIME_DATA.sql_message_id, CTE_GENERATE_DATETIME_DATA.instance_id INTO #job_step_failure FROM CTE_GENERATE_DATETIME_DATA WHERE DATEADD(HOUR, @utc_offset, CTE_GENERATE_DATETIME_DATA.job_start_datetime) > DATEADD(MINUTE, -1 * @minutes_to_monitor, GETUTCDATE()); |
Note that the only significant difference between these queries is that we check for step_id = 0 when looking for overall job notification data and step_id > 0 for job steps that are associated with these jobs. Since sysjobhistory stored both job failures and job step failures, we will need to separate them from each other, and checking for step_id = 0 is a quick and easy way to do so.
Now that we have some data on job and step failures, we can begin generating failure data to insert into sql_server_agent_job_failure for the various failure scenarios that we identified earlier:
Jobs that Fail Due to Failed Steps
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
WITH CTE_FAILURE_STEP AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY job_step_failure.sql_server_agent_job_id_guid, job_step_failure.job_failure_time_utc ORDER BY job_step_failure.job_failure_step_number DESC) AS recent_step_rank FROM #job_step_failure job_step_failure) INSERT INTO dbo.sql_server_agent_job_failure (sql_server_agent_job_id, sql_server_agent_instance_id, job_start_time_utc, job_failure_time_utc, job_failure_step_number, job_failure_step_name, job_failure_message, job_step_failure_message, job_step_severity, job_step_message_id, retries_attempted, has_email_been_sent_to_operator) SELECT sql_server_agent_job.sql_server_agent_job_id, CTE_FAILURE_STEP.instance_id, job_failure.job_start_time_utc, CTE_FAILURE_STEP.job_failure_time_utc, CTE_FAILURE_STEP.job_failure_step_number, CTE_FAILURE_STEP.step_name AS job_failure_step_name, job_failure.job_failure_message, CTE_FAILURE_STEP.job_step_failure_message, CTE_FAILURE_STEP.job_step_severity, CTE_FAILURE_STEP.sql_message_id AS job_step_message_id, CTE_FAILURE_STEP.retries_attempted, 0 AS has_email_been_sent_to_operator FROM #job_failure job_failure INNER JOIN dbo.sql_server_agent_job ON job_failure.sql_server_agent_job_id_guid = sql_server_agent_job.sql_server_agent_job_id_guid INNER JOIN CTE_FAILURE_STEP ON job_failure.sql_server_agent_job_id_guid = CTE_FAILURE_STEP.sql_server_agent_job_id_guid AND job_failure.job_failure_time_utc = CTE_FAILURE_STEP.job_failure_time_utc WHERE CTE_FAILURE_STEP.recent_step_rank = 1 AND CTE_FAILURE_STEP.instance_id NOT IN (SELECT sql_server_agent_job_failure.sql_server_agent_instance_id FROM dbo.sql_server_agent_job_failure) AND sql_server_agent_job.job_category_name <> 'Unmonitored'; |
The CTE above will group job steps by job and job execution time, placing the last failure first. This allows us to determine which step failure was the direct cause of the job itself failing.
Jobs that Failed Without Any Failed Steps
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
INSERT INTO dbo.sql_server_agent_job_failure (sql_server_agent_job_id, sql_server_agent_instance_id, job_start_time_utc, job_failure_time_utc, job_failure_step_number, job_failure_step_name, job_failure_message, job_step_failure_message, job_step_severity, job_step_message_id, retries_attempted, has_email_been_sent_to_operator) SELECT sql_server_agent_job.sql_server_agent_job_id, job_failure.instance_id, job_failure.job_start_time_utc, job_failure.job_failure_time_utc, 0 AS job_failure_step_number, '' AS job_failure_step_name, job_failure.job_failure_message, '' AS job_step_failure_message, -1 AS job_step_severity, -1 AS job_step_message_id, 0 AS retries_attempted, 0 AS has_email_been_sent_to_operator FROM #job_failure job_failure INNER JOIN dbo.sql_server_agent_job ON job_failure.sql_server_agent_job_id_guid = sql_server_agent_job.sql_server_agent_job_id_guid WHERE job_failure.instance_id NOT IN (SELECT sql_server_agent_job_failure.sql_server_agent_instance_id FROM dbo.sql_server_agent_job_failure) AND NOT EXISTS (SELECT * FROM #job_step_failure job_step_failure WHERE job_failure.sql_server_agent_job_id_guid = job_step_failure.sql_server_agent_job_id_guid AND job_failure.job_failure_time_utc = job_step_failure.job_failure_time_utc); |
It is possible for a job to fail without any steps executing. This can be caused by a configuration error, a permissions problem, or some other high-level job or SQL Server Agent issue. We definitely want to know about these, so we check for all job failures that have no corresponding job step failures and insert them into sql_server_agent_job_failure.
Jobs Steps that Fail, but for Jobs that Succeed
Depending on the logic built into job steps, we may allow the job to continue even when a step fails. If this is the case, then SQL Server will not report failure, assuming the remainder of the job succeeds or follows similar rules.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
WITH CTE_FAILURE_STEP AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY job_step_failure.sql_server_agent_job_id_guid, job_step_failure.job_failure_time_utc ORDER BY job_step_failure.job_failure_step_number DESC) AS recent_step_rank FROM #job_step_failure job_step_failure) INSERT INTO dbo.sql_server_agent_job_failure (sql_server_agent_job_id, sql_server_agent_instance_id, job_start_time_utc, job_failure_time_utc, job_failure_step_number, job_failure_step_name, job_failure_message, job_step_failure_message, job_step_severity, job_step_message_id, retries_attempted, has_email_been_sent_to_operator) SELECT sql_server_agent_job.sql_server_agent_job_id, CTE_FAILURE_STEP.instance_id, CTE_FAILURE_STEP.job_start_time_utc, CTE_FAILURE_STEP.job_failure_time_utc, CTE_FAILURE_STEP.job_failure_step_number, CTE_FAILURE_STEP.step_name AS job_failure_step_name, '' AS job_failure_message, CTE_FAILURE_STEP.job_step_failure_message, CTE_FAILURE_STEP.job_step_severity, CTE_FAILURE_STEP.sql_message_id AS job_step_message_id, CTE_FAILURE_STEP.retries_attempted, 0 AS has_email_been_sent_to_operator FROM CTE_FAILURE_STEP INNER JOIN dbo.sql_server_agent_job ON CTE_FAILURE_STEP.sql_server_agent_job_id_guid = sql_server_agent_job.sql_server_agent_job_id_guid LEFT JOIN #job_failure job_failure ON job_failure.sql_server_agent_job_id_guid = CTE_FAILURE_STEP.sql_server_agent_job_id_guid AND job_failure.job_failure_time_utc = CTE_FAILURE_STEP.job_failure_time_utc WHERE CTE_FAILURE_STEP.recent_step_rank = 1 AND job_failure.sql_server_agent_job_id_guid IS NULL AND CTE_FAILURE_STEP.instance_id NOT IN (SELECT sql_server_agent_job_failure.sql_server_agent_instance_id FROM dbo.sql_server_agent_job_failure); |
The TSQL above will check for all failed job steps that do not have a corresponding failed job and report on them as well.
Notification
For this demo, we’ll use sp_send_dbmail to email a notification to an operator. If this is not your preferred method of alerting, feel free to substitute this with something else.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
DECLARE @profile_name VARCHAR(MAX) = 'Default Public Profile'; DECLARE @email_to_address VARCHAR(MAX) = 'ed@myemailaddress.com'; DECLARE @email_subject VARCHAR(MAX); DECLARE @email_body VARCHAR(MAX); DECLARE @job_failure_count INT; SELECT @job_failure_count = COUNT(*) FROM dbo.sql_server_agent_job_failure WHERE sql_server_agent_job_failure.has_email_been_sent_to_operator = 0; -- Send an email to an operator if any new errors are found. IF EXISTS (SELECT * FROM dbo.sql_server_agent_job_failure WHERE sql_server_agent_job_failure.has_email_been_sent_to_operator = 0) BEGIN SELECT @email_subject = 'Failed Job Alert: ' + ISNULL(@@SERVERNAME, CAST(SERVERPROPERTY('ServerName') AS VARCHAR(MAX))); SELECT @email_body = 'At least one failure has occurred on ' + ISNULL(@@SERVERNAME, CAST(SERVERPROPERTY('ServerName') AS VARCHAR(MAX))) + ': <html><body><table border=1> <tr> <th colspan="6" bgcolor="#F29C89" align="left">Total Failed Jobs: ' + CAST(@job_failure_count AS VARCHAR(MAX)) + '</th> </tr> <tr> <th bgcolor="#F29C89">Job Name</th> <th bgcolor="#F29C89">Server Job Start Time</th> <th bgcolor="#F29C89">Server Job Failure Time</th> <th bgcolor="#F29C89">Failure Step Name</th> <th bgcolor="#F29C89">Job Failure Message</th> <th bgcolor="#F29C89">Job Step Failure Message</th> </tr>'; SELECT @email_body = @email_body + CAST((SELECT CAST(sql_server_agent_job.sql_server_agent_job_name AS VARCHAR(MAX)) AS 'td', '', CAST(DATEADD(HOUR, -1 * @utc_offset, sql_server_agent_job_failure.job_start_time_utc) AS VARCHAR(MAX)) AS 'td', '', CAST(DATEADD(HOUR, -1 * @utc_offset, sql_server_agent_job_failure.job_failure_time_utc) AS VARCHAR(MAX)) AS 'td', '', sql_server_agent_job_failure.job_failure_step_name AS 'td', '', sql_server_agent_job_failure.job_failure_message AS 'td', '', sql_server_agent_job_failure.job_step_failure_message AS 'td' FROM dbo.sql_server_agent_job_failure INNER JOIN dbo.sql_server_agent_job ON sql_server_agent_job.sql_server_agent_job_id = sql_server_agent_job_failure.sql_server_agent_job_id WHERE sql_server_agent_job_failure.has_email_been_sent_to_operator = 0 ORDER BY sql_server_agent_job_failure.job_failure_time_utc ASC FOR XML PATH('tr'), ELEMENTS) AS VARCHAR(MAX)); SELECT @email_body = @email_body + '</table></body></html>'; SELECT @email_body = REPLACE(@email_body, '<td>', '<td valign="top">'); EXEC msdb.dbo.sp_send_dbmail @profile_name = @profile_name, @recipients = @email_to_address, @subject = @email_subject, @body_format = 'html', @body = @email_body; UPDATE sql_server_agent_job_failure SET has_email_been_sent_to_operator = 1 FROM dbo.sql_server_agent_job_failure WHERE sql_server_agent_job_failure.has_email_been_sent_to_operator = 0; END |
Some effort is taken here to structure the job failure details into a formatted HTML email with the failure count at the top and a table of failure data below. This makes reading the emails relatively easy and straight-forward. The following is an example of a job failure that was sent using this process:

These failures were staged, with the first being a scenario where a step fails, but the job succeeds and the second when a job fails due to a failed step. This email format consolidates all failures into a single table that includes details on what failed and why. While only 6 columns are included in this table, you can add more for any additional data that could be useful, such as job duration, number of retries, or further details about the job itself.
The goal of an alert such as this is to reduce the amount of homework that you need to do whenever something breaks. Instead of having to return to SQL Server Agent and read all of the information that could be presented here, you can begin troubleshooting right away.
SQL Server Agent Job
The stored procedure that was created above can be called from anywhere (Scheduled task, Powershell, SQLCMD, etc…), but for simplicity, I’ll use a SQL Server agent job:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
USE msdb; GO DECLARE @jobId BINARY(16); EXEC msdb.dbo.sp_add_job @job_name=N'Job Failure Collection and Notification', @enabled=1, @notify_level_eventlog=0, @notify_level_email=2, @notify_level_netsend=0, @notify_level_page=0, @delete_level=0, @description=N'No description available.', @category_name=N'[Uncategorized (Local)]', @owner_login_name=N'sa', @notify_email_operator_name=N'Ed', @job_id = @jobId OUTPUT; EXEC msdb.dbo.sp_add_jobstep @job_id=@jobId, @step_name=N'monitor_job_failures', @step_id=1, @cmdexec_success_code=0, @on_success_action=1, @on_success_step_id=0, @on_fail_action=2, @on_fail_step_id=0, @retry_attempts=0, @retry_interval=0, @os_run_priority=0, @subsystem=N'TSQL', @command=N'EXEC dbo.monitor_job_failures', @database_name=N'AdventureWorks2016CTP3', @flags=0; EXEC msdb.dbo.sp_update_job @job_id = @jobId, @start_step_id = 1; EXEC msdb.dbo.sp_add_jobschedule @job_id=@jobId, @name=N'Every 5 Minutes', @enabled=1, @freq_type=4, @freq_interval=1, @freq_subday_type=4, @freq_subday_interval=5, @freq_relative_interval=0, @freq_recurrence_factor=0, @active_start_date=20180208, @active_end_date=99991231, @active_start_time=100, @active_end_time=59; EXEC msdb.dbo.sp_add_jobserver @job_id = @jobId, @server_name = N'(local)'; GO |
This job executes every 5 minutes and sticks to the default of 1440 minutes (one day) for the monitoring interval. Any failures in sql_server_agent_job_failure that have not been flagged as sent to the operator will be sent out as part of any given run. Feel free to adjust the job run frequency to whatever meets your needs.
If a job is deemed mission critical and you need to know of its failure immediately, then you may wish to consider a separate notification on it if waiting up to 5 minutes is too long, or have this process run more frequently. Most processes are flexible and can allow for a short waiting period before we respond, though that priority is determined by you. For example, if a SQL Server instance restarts, we’d probably want to know right now, but if an overnight reporting process fails, waiting a few minutes is probably fine.
Note that I have included a built-in notification on this job that will email me if it fails. This is intentional and answers the question of, “What notifies us of a failure if the job failure notification process breaks”. The only larger issue than this would be if SQL Server Agent would become unavailable. Alerting on this is beyond the scope of this article, but could be accomplished by a service monitor pointed at SQL Server Agent.
Cleanup
Once in place and tested, this alerting system can take the place of any existing alerts. The benefits of this process are:
- Failures are stored in tables that can be queried and reported on later, if need be.
- Failures are grouped into individual notifications. This prevents a flood of alerts if a job fails frequently.
- Additional details are provided that built-in notifications do not report on.
- All failure conditions can be reported on, including unusual ones that SQL Server Agent may not catch.
Conclusion
Ultimately, reporting and alerting on failures are done on a case-by-case basis. This process was written to be as simple as possible, and therefore can be customized until it fully meets your needs. As an added bonus, we can create well-designed schema that relies on easy-to-understand data types for dates, times, statuses, and duration.
Creating your own job failure alerting process allows you to take charge of alerting and make the resulting notifications as meaningful and useful as possible. This is important as a major goal of alerting is to make the messages we get as actionable and informative as possible, without producing noise or distractions. We also do not want to miss potentially important failures that result from a misconfigured job.
Given the limitations of the build-in alerting options in SQL Server, this also provides us functionality that is not possible otherwise. We can adjust notifications to react to failure states such as failed steps or misconfigured jobs. We can also customize the notifications we receive to include additional information that allows us to jump straight into troubleshooting, without the need to revisit SQL Server Agent and collect more troubleshooting data.
Effective alerting improves our productivity, decreases distractions, but most importantly, it reduces late-night wake-up-calls, which is something we can all get behind!
Downloads

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019