
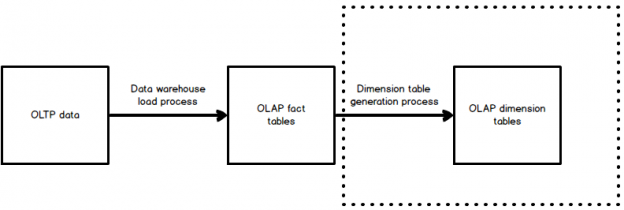
Description
When building reporting structures, we typically have the need to build fact and dimension tables to support the apps that will consume this data. Sometimes we need to generate large numbers of dimension tables to support application needs, such as in Tableau, Entity Framework, or Power BI.
Creating this schema by hand is time-consuming and error-prone. Automating it can be a way to improve predictability, maintainability, and save a ton of time in the process!
Introduction
Consider a database in which we have a number of tables. These tables may be fact tables in a data warehouse or OLTP-style tables with a variety of columns that contain dimension-type data. This is fairly typical in nearly any database we design. Important columns describe a job title, country of origin, pay grade, security clearance, or one of any other type of descriptive metadata.
Many applications require or prefer these dimensions to be spelled out for them with literal lookup tables, rather than referencing the fact data directly. We can design, test, and implement each table as needed, and then add code to populate and maintain them. This solution is viable but time-consuming. The alternative that I’d like to present here is a solution that can generate dimension tables using a tiny amount of metadata and code as the backbone of the process.
We can model a process that would generate dimension tables like this:
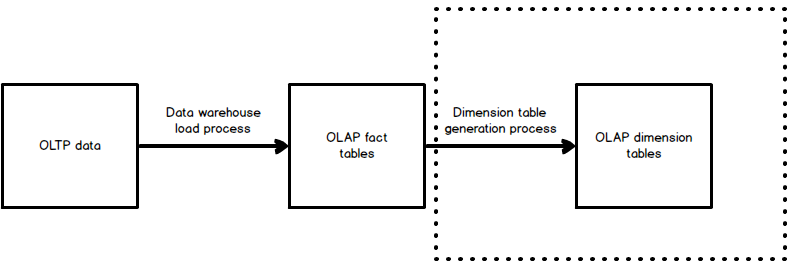
The area in the dotted lines represents what we will be creating in this article!
Setting up our schema
Our solution relies on a table of metadata that briefly describes what tables & columns we would like to process and where to place the resulting dimension data. The goal is to keep everything as absolutely minimalist and simple as possible.
A metadata table can be replaced with direct queries against system views if your schema is exceedingly well-organized. We could also hard-code these table names into the stored procedure, though I tend to prefer metadata, as it’s easier to modify. In addition, metadata updates are less risky and easier to maintain when larger and more complex applications may also be involved.
In order to transform fact data into dimension data, we need to enumerate the following details of that data:
- source schema
- source table
- source column
- target dimension table name
With this information, we can scan a column’s contents, create a dimension table with the new name, and deposit that data into it. Here is a table definition that meets our needs:
|
1 2 3 4 5 6 7 |
CREATE TABLE dbo.Dimension_Table_Metadata ( Dimension_ID SMALLINT IDENTITY(1,1) NOT NULL CONSTRAINT PK_Dimension_Table_Metadata PRIMARY KEY CLUSTERED, Target_Dimension_Table_Name VARCHAR(50) NOT NULL, Source_Fact_Schema_Name VARCHAR(128) NOT NULL, Source_Fact_Table_Name VARCHAR(128) NOT NULL, Source_Fact_Column_Name VARCHAR(50) NOT NULL ); |
We could use the source table as a natural clustered primary key, but I’ve chosen to use a surrogate instead. This allows for the possibility that you might need to copy the contents of a given column into multiple places. If needed, we won’t violate a primary key in the process.
For all demos in this article, we will use data available in AdventureWorks. This can easily be replicated with any string columns in any table in any source database. With this table created, let’s populate it with some test data:
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO dbo.Dimension_Table_Metadata (Target_Dimension_Table_Name, Source_Fact_Schema_Name, Source_Fact_Table_Name, Source_Fact_Column_Name) VALUES ('Dim_Department_GroupName', 'HumanResources', 'Department', 'GroupName'), ('Dim_JobTitle', 'HumanResources', 'Employee', 'JobTitle'), ('Dim_PersonType', 'Person', 'Person', 'PersonType'), ('Dim_ProductColor', 'Production', 'Product', 'Color'), ('Dim_ProductInventoryShelf', 'Production', 'ProductInventory', 'Shelf'), ('Dim_TransactionType', 'Production', 'TransactionHistory', 'TransactionType') |
We can check and see how this looks by selecting all data from our new table:

We can see that we have chosen 6 source columns, providing the schema name, table name, and column name, in order to point us directly at the data we are interested in. We have also chosen a target dimension table name. This is completely arbitrary, though I’ve made an attempt to be descriptive in naming it. You may choose whatever names fit your standard database schema naming conventions as this will have no bearing on performance or results.
With these test columns ready, we may proceed to building a solution that will enumerate the contents of these columns into dimension data that could later be fed into a reporting tool, analytical engine, or some other destination.
The solution
We have constructed a problem and outlined what data we wish to transform. Our goal is to use as little code as possible to use system views and our metadata to generate some simple, yet complete dimension tables.
In order to do this, we will use a handful of system views in order to join and validate the metadata we have provided:
- Sys.tables: a list of all tables in a given database, along with a wide variety of attributes pertaining to them
- Sys.schemas: a list of schemas in a given database, along with some basic information about them
- Sys.columns: a list of all columns in a database, including the table they belong to and their data types
- Sys.types: a list of all available data types in a database
Each of these views can be joined together as follows to get a complete view of all tables/columns in a database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT schemas.name AS SchemaName, tables.name AS TableName, columns.name AS ColumnName, CASE WHEN columns.max_length = -1 THEN 'MAX' WHEN types.name IN ('char', 'varchar') THEN CAST(columns.max_length AS VARCHAR(MAX)) ELSE CAST(columns.max_length / 2 AS VARCHAR(MAX)) END AS ColumnSize, types.name AS TypeName FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id INNER JOIN sys.types ON columns.user_type_id = types.user_type_id WHERE types.name IN ('char', 'nchar', 'nvarchar', 'varchar') ORDER BY schemas.name, tables.name, columns.name; |
The result is a big list of everything, but one that tells us the data types and lengths of the strings we are considering:
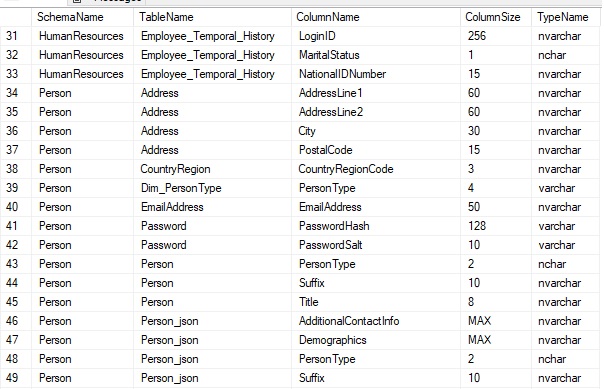
Note that the length of an NVARCHAR or NCHAR column will be twice the length of a similar VARCHAR or CHAR column in sys.columns, hence the need to divide max_length by 2 when determining the actual column size that you would see in SQL Server.
We can now take the metadata we created earlier, combine it with this system view data, and generate useful dimension tables using it. Let’s create a stored procedure that will consume each row of metadata in our table and generate a single dimension table for each. We’ll walk through the process step-by-step in order to explain each query:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
IF EXISTS (SELECT * FROM sys.procedures WHERE procedures.name = 'Generate_Dimension_Tables') BEGIN DROP PROCEDURE dbo.Generate_Dimension_Tables END GO CREATE PROCEDURE dbo.Generate_Dimension_Tables AS BEGIN SET NOCOUNT ON; DECLARE @Sql_Command NVARCHAR(MAX) = ''; |
This is the housekeeping for our stored procedure. If it exists, drop it, create a new proc, set NOCOUNT, and declare a string @sql_command for use in executing the dynamic SQL needed to create new tables. Dynamic SQL is a huge convenience here, allowing us to add schema, table, and column names, as well as the column size into the CREATE TABLE statement.
While it’s possible to write this stored procedure without using dynamic SQL, the result would be significantly longer and more complex. We could theoretically create a dummy table, rename it, rename the columns, and resize the string column in order to achieve the same results, but I was hunting here for short and sweet, which that would not be.
Next, we need to generate our dynamic SQL from the metadata table. Since there can be any number of rows in the table, I will opt to build a command string via a set based string approach, rather than using a CURSOR or WHILE loop:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
SELECT @Sql_Command = @Sql_Command + ' USE AdventureWorks2016; IF EXISTS (SELECT * FROM sys.tables INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE tables.name = ''' + Dimension_Table_Metadata.Target_Dimension_Table_Name + ''' AND schemas.name = ''' + Dimension_Table_Metadata.Source_Fact_Schema_Name + ''') BEGIN DROP TABLE [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + ']; END CREATE TABLE [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] ( [' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '_Id] INT NOT NULL IDENTITY(1,1) CONSTRAINT [PK_' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] PRIMARY KEY CLUSTERED, [' + Dimension_Table_Metadata.Source_Fact_Column_Name + '] ' + types.name + '(' + CASE WHEN columns.max_length = -1 THEN 'MAX' WHEN types.name IN ('char', 'varchar') THEN CAST(columns.max_length AS VARCHAR(MAX)) ELSE CAST(columns.max_length / 2 AS VARCHAR(MAX)) END + ') NOT NULL); INSERT INTO [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] ([' + Dimension_Table_Metadata.Source_Fact_Column_Name + ']) SELECT DISTINCT ' + Dimension_Table_Metadata.Source_Fact_Table_Name + '.' + Dimension_Table_Metadata.Source_Fact_Column_Name + ' FROM [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Source_Fact_Table_Name + '] WHERE ' + Dimension_Table_Metadata.Source_Fact_Table_Name + '.' + Dimension_Table_Metadata.Source_Fact_Column_Name + ' IS NOT NULL;' FROM dbo.Dimension_Table_Metadata INNER JOIN sys.tables ON tables.name = Dimension_Table_Metadata.Source_Fact_Table_Name INNER JOIN sys.columns ON tables.object_id = columns.object_id AND columns.name COLLATE database_default = Dimension_Table_Metadata.Source_Fact_Column_Name INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id AND schemas.name = Dimension_Table_Metadata.Source_Fact_Schema_Name INNER JOIN sys.types ON columns.user_type_id = types.user_type_id WHERE types.name IN ('char', 'nchar', 'nvarchar', 'varchar'); |
This dynamic SQL accomplishes a few tasks for us:
- Does the dimension table already exist? If so, drop it. We do this in case the column length or type has changed. This will ensure the resulting table is of the correct type/size. Creating it takes little effort.
- Create the dimension table. We’ll place it in the same schema as the source table and customize the table and column names to reflect where the data is being pulled from. We’ll retain the same data type, as well as column size.
- Populate the new table with all distinct values from the source table. On a very large table, you’ll want this column to be indexed, or performance might be a bit slow. If it’s a reporting table with no OLTP workload against it, then you’ll have more flexibility available for a warehouse-style data load process such as this.
- We only insert non-NULL values. For the sake of this proof-of-concept, I saw little value in including NULL as a distinct dimension “value” and omitted it. If it’s important to your data model, feel free to include it. As always, though use caution when comparing against any NULLable column as equality and inequality operations will result in undesired results if ANSI_NULLS is set ON (the default and ANSI standard).
Lastly, we execute our dynamic SQL and wrap up our stored procedure:
|
1 2 3 |
EXEC sp_executesql @Sql_Command; END GO |
Now, let’s take the new proc for a spin:
|
1 |
EXEC dbo.Generate_Dimension_Tables; |
The proc runs in under a second, with no results or indication that anything happened. If desired, feel free to add logging into the process to provide some level of feedback or error trapping, in the event that you want to be notified in the event of unexpected results.
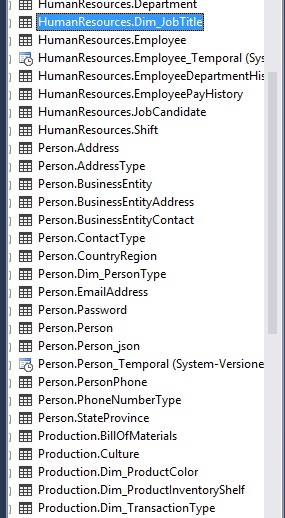
When we expand and refresh the tables list for the database, we can see the following new dimension tables added:
- HumanResources.Dim_JobTitle
- Person.Dim_PersonType
- Production.Dim_ProductColor
- Production.Dim_ProductInventoryShelf
- Production.Dim_TransactionType
Note that HumanResources.Department.GroupName did not get processed by our stored procedure. If we look at the table, we can see why:
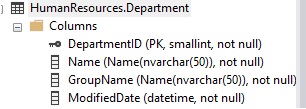
The column GroupName is defined as custom type “Name”, which is a NVARCHAR(50), but in sys.types will appear as Name instead. We can work around this if we wish by making an additional join to sys.types in order to find the corresponding system data type for the custom data type:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
SELECT schemas.name AS SchemaName, tables.name AS TableName, columns.name AS ColumnName, USERDATATYPE.name AS UserDataType, SYSTEMDATATYPE.name AS SystemDataType FROM sys.tables INNER JOIN sys.columns ON tables.object_id = columns.object_id INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id INNER JOIN sys.types USERDATATYPE ON columns.user_type_id = USERDATATYPE.user_type_id INNER JOIN sys.types SYSTEMDATATYPE ON SYSTEMDATATYPE.user_type_id = USERDATATYPE.system_type_id WHERE schemas.name = 'HumanResources' AND tables.name = 'department' AND columns.name = 'GroupName'; |
The result of this query shows that the actual data type is NVARCHAR:

If we want to support user-defined data types, this additional join could provide insight into the original data type. Alternatively, we could simply pass in the data type as a literal and check both system and user-defined data types for the string types we are looking for. To achieve this, we would adjust our dynamic SQL as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
SELECT @Sql_Command = @Sql_Command + ' USE AdventureWorks2016; IF EXISTS (SELECT * FROM sys.tables INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id WHERE tables.name = ''' + Dimension_Table_Metadata.Target_Dimension_Table_Name + ''' AND schemas.name = ''' + Dimension_Table_Metadata.Source_Fact_Schema_Name + ''') BEGIN DROP TABLE [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + ']; END CREATE TABLE [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] ( [' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '_Id] INT NOT NULL IDENTITY(1,1) CONSTRAINT [PK_' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] PRIMARY KEY CLUSTERED, [' + Dimension_Table_Metadata.Source_Fact_Column_Name + '] ' + USERDATATYPE.name + CASE WHEN USERDATATYPE.name IN ('char', 'nchar', 'nvarchar', 'varchar') THEN '(' + CASE WHEN columns.max_length = -1 THEN 'MAX' WHEN USERDATATYPE.name IN ('char', 'varchar') THEN CAST(columns.max_length AS VARCHAR(MAX)) ELSE CAST(columns.max_length / 2 AS VARCHAR(MAX)) END + ')' ELSE '' END + ' NOT NULL); INSERT INTO [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Target_Dimension_Table_Name + '] ([' + Dimension_Table_Metadata.Source_Fact_Column_Name + ']) SELECT DISTINCT ' + Dimension_Table_Metadata.Source_Fact_Table_Name + '.' + Dimension_Table_Metadata.Source_Fact_Column_Name + ' FROM [' + Dimension_Table_Metadata.Source_Fact_Schema_Name + '].[' + Dimension_Table_Metadata.Source_Fact_Table_Name + '] WHERE ' + Dimension_Table_Metadata.Source_Fact_Table_Name + '.' + Dimension_Table_Metadata.Source_Fact_Column_Name + ' IS NOT NULL;' FROM dbo.Dimension_Table_Metadata INNER JOIN sys.tables ON tables.name = Dimension_Table_Metadata.Source_Fact_Table_Name INNER JOIN sys.columns ON tables.object_id = columns.object_id AND columns.name COLLATE database_default = Dimension_Table_Metadata.Source_Fact_Column_Name INNER JOIN sys.schemas ON schemas.schema_id = tables.schema_id AND schemas.name = Dimension_Table_Metadata.Source_Fact_Schema_Name INNER JOIN sys.types USERDATATYPE ON columns.user_type_id = USERDATATYPE.user_type_id INNER JOIN sys.types SYSTEMDATATYPE ON SYSTEMDATATYPE.user_type_id = USERDATATYPE.system_type_id WHERE ( USERDATATYPE.name IN ('char', 'nchar', 'nvarchar', 'varchar') OR SYSTEMDATATYPE.name IN ('char', 'nchar', 'nvarchar', 'varchar')); |
The result will now perform the following logic for the table creation:
- If the data type is NCHAR, CHAR, NVARCHAR, or VARCHAR, then use it and add the size in parenthesis.
- If the type is user-defined and the basis of the user-defined type is NCHAR, CHAR, NVARCHAR, or VARCHAR, then use the user-defined type name. For this scenario, leave out the size as it is implicit to the custom data type.
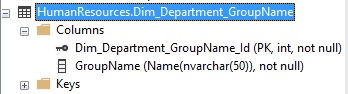
Refreshing the table list, we now see a new dimension table for our missing column. It’s been properly defined as type “Name”, which resolves to NVARCHAR(50).
Our other tables all contain the correct data types as well, for example:
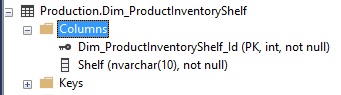
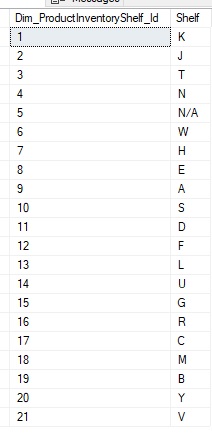
If we SELECT * from this new table, we can inspect the results and confirm that things look as they should:
Other data types
I limited our discussion to strings as they are the most common data types used in lookup tables and normalized dimensions. There is no reason that we could not expand this to include bits, numeric data types, or others that might be useful to you. The only additional work would be to:
- add the new data types to the various sys.types filters that we have
- ensure that the column length does not get included unless needed
- cast non-string columns as strings when needed in order to avoid a type clash in our dynamic SQL string between string and non-string data types
Testing is quite easy for this. An undesirable result will typically be that either the resulting table is never created, or a horrific error is thrown. Both of these are fairly easy to uncover, troubleshoot, and fix.
When in doubt, change the EXEC sp_executesql statement to a PRINT statement and step through the resulting TSQL to ensure it is valid and what you expect of it.
Security notes
Utilities like this are typically internal processes that are not exposed to the internet, end users, or others who might seek to take advantage of SQL injection.
That being said, whenever working with dynamic SQL and the creation/deletion of the schema, always ensure that:
- Security on the stored procedure, metadata table, and related jobs/tasks are limited to only those that should be executing it. Since this stored procedure takes no parameters, the only point of entry is the metadata table. Ensure that this is locked down appropriately, and you’ll greatly reduce the chances of accidents happening.
- Include brackets around schema, table, and column names. This makes injection more difficult and far more likely to trap errors, rather than result in logical flaws that can be exploited.
- Use sp_executesql rather than EXEC. This reduces the chances that the string can be tampered with.
- Maintain this outside of the internet-at-large, and outside of the company-at-large. Maintenance scripts should be limited to the experts that administer them, whether DBAs, developers, or other technicians. These are not meant for development by anyone that is not familiar enough with the scripts to understand their function.
- Feel free to add additional data consistency checks to the stored procedure in order to validate metadata from our table. TRY…CATCH can also be used to trap errors. The extent to which you add layers of security to this process should be based on the level of control (or lack thereof) you have over it.
Conclusion
Using 50 lines of TSQL, we were able to process a metadata table and generate any number of dimension tables based on its contents. We leveraged dynamic SQL and system views in order to gain an understanding of the data types involved and recreate the schema in a new and useful form.
This general approach can be applied in a myriad of ways in order to automate data or schema load processes. In addition, we improve the maintainability of processes by removing the need to hard-code schema, table, column, and data type names all over the place. The only hard-coded literal in our stored procedure is the database name, which could very easily be removed. Adding a new table is a matter of inserting a single row into dbo.Dimension_Table_Metadata.
This demo can be a fun proof-of-concept for anyone looking to create, alter, or drop schema on-the-fly. It can also show how we can generate a large quantity of dynamic SQL without using loops or cursors. Lastly, it can demonstrate how we can pull data from system views in order to better understand table structures and data types. As a bonus, we can quickly analyze user-defined data types and explore how they were created.
Enjoy!
Downloads

In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019