
In the previous article of this series, SQL Server Index Structure and Concepts, we described, in detail, the anatomy of QL Server indexes, the B-Tree structure, the properties of the indexes, the main types of indexes and the advantages of using the indexes for performance tuning.
You may recall how we described the index previously as a double-edged sword, where you can derive significant benefits from an index, that is well designed, in improving the performance of your data retrieval operations. On the other hand, a poorly designed index, or the lack of necessary indexes, will cause performance degradation in your system. In this article, we will go through the basics and best practices that help you in designing the most effective index to meet the requirements of your system with the possible performance enhancements.
The decision of choosing the right index that fits the system’s workload is not an easy task, as you need to compromise between the speed of data retrieval operations and the overhead of adding that index on the data modification operations. Another factor that affects index design decisions is the list of columns that will participate in the index key, where you should take into consideration that, more columns included in the index key to cover your application queries will require more disk space and extra maintenance overhead. You need also to make sure that, when you create the table index, the SQL Server Query Optimizer will choose the created index to retrieve data from the table in most cases. The SQL Server Query Optimizer decision whether to use the index or not depends on the performance gain that will be taken from using that index.
Workload type
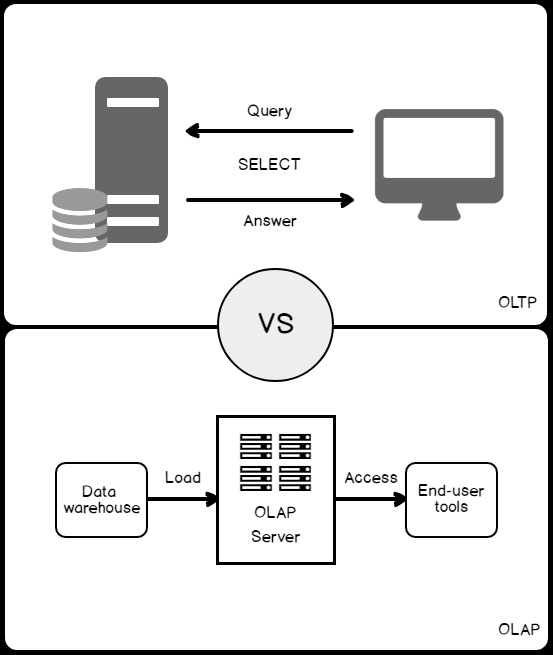
Before creating an index, you should understand the workload type of the database. On Online Transaction Processing (OLTP) database, workloads are used for transactional systems, in which most of the submitted queries are data modification queries. In contrast, Online Analytical Processing (OLAP) database workloads are used for data warehousing systems, in which most of the submitted queries are data retrieval queries that filter, group, aggregate and join large data sets quickly. The difference between the OLTP and OLAP databases can be summarized in the figure below:
Creating a large number of indexes on a database table affects data modification (e.g. Updates) operations performance. When you add or modify a row in the underlying table, the row will also be adjusted appropriately in all related table indexes. Because of that, you need to avoid creating a large number of indexes on the heavily modified tables and create the minimum possible number of indexes, with the least possible number of columns on each index. You can overcome this problem by writing queries that add or modify rows in batches, rather than writing a single query for each insert or modify operation. For Online Analytical Processing (OLAP) workloads, in which tables have low modification requirements, you can create a large number of indexes that improve the performance of the data retrieval operations.
Table Size
It is not recommended to create indexes on small tables, as it takes the SQL Server Engine less time scanning the underlying table than traversing the index when searching for a specific data. In this case, the index will not be used and still affect the data modification performance, as it will be always adjusted when modifying the underlying table’s data.
Table Columns
In addition to database workload characteristics, the characteristics of the table columns that are used in the submitted queries should be also considered when designing an index. For instance, the columns with exact numeric data types, such as INT and BIGINT data types and that are UNIQUE and NOT NULL are considered optimal columns to participate in the index key.
In most cases, a long-running query is caused by indexing a column with few unique values. Although it is not possible to add the columns with ntext, text, image, varchar(max), nvarchar(max), and varbinary(max) data types to the index key columns, it is possible to add these data types to non-key index columns, but only in case of critical need. A column with XML data type can be added only to an XML index type.
Columns Order and Sorting
It is recommended to create the indexes on columns that are used in the query predicates and join conditions in the correct order that is specified in the predicate. In this way, the goal is keeping the index key short, without including the rarely used columns, in order to minimize the index complexity, storage and maintenance overheads. You can also improve query performance by creating a covering index that contains all data required by the query, without the need to read from the underlying table.
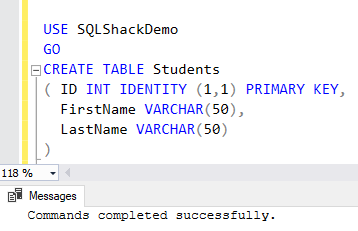
To check the importance of the column order in the index key, let us create a simple test table using the CREATE TABLE T-SQL statement below:
And create a non-clustered index on that table using the LastName and FirstName columns, as shown below:

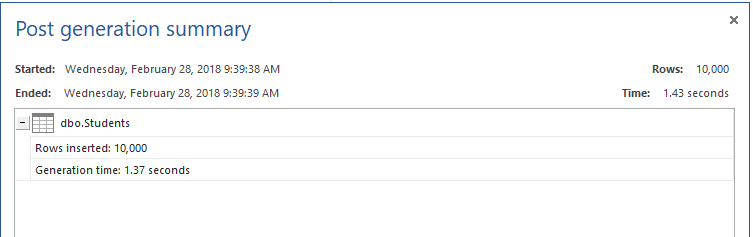
Then we will fill the table with 10K records, using the ApexSQL Generate, test data generator tool, as shown below:
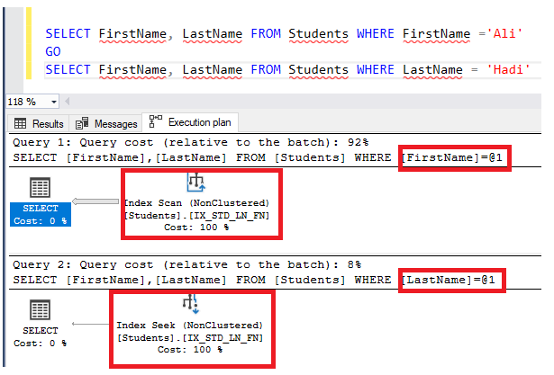
The table is ready now for our testing scenario. We will execute two SELECT statements, the first one will search using the FirstName column, which is the second column in the index key columns, and the second query will search using the LastName column, which is the first column in the index key columns.
From the result, it is clear that the SQL Server Engine will scan all the index data to search for the students with the FirstName value specified in the WHERE clause. The SQL Server Engine is not able to fully take benefits from the created index, due to the columns order in the created index. In the second query, the SQL Server Engine seeks directly for the requested value and takes benefits from the created index as we are using the LastName column in the WHERE clause, which is the first column in the index. You can also see that the weight of the query that is scanning the index is 92% of the overall weight, compared to the one that is scanning the index with weight equal to 8% of the overall weight, as shown clearly below:
It is also recommended when designing an index, to consider if the columns that participate in the index key will be sorted in ascending or descending order, with the ascending order as the default order, depending on the system requirements. In the previously created Students table, assume that we are interested in returning the students information sorted ascending by the FirstName and descending by the LastName. If the table has no index created on the FirstName and LastName, after dropping the old index as shown below:
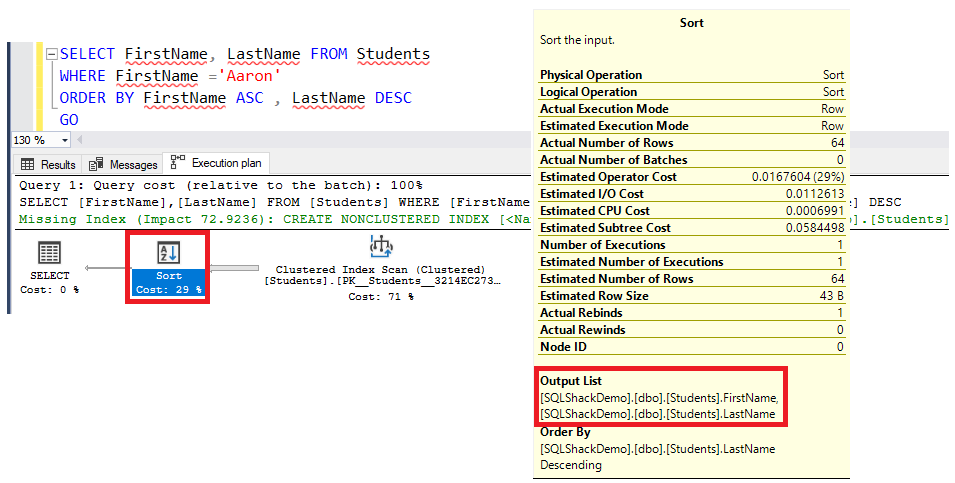
Then execute the below query, that will return the result sorted ascending by the FirstName and descending by the LastName. You will see that an extra operator will be used in the execution plan to Sort the result as specified in the ORDER BY clause. You can imagine the extra execution time consumed and performance overhead that is caused by the Sort operator, as shown below:
If we create an index on that table that includes both the FirstName sorted ascending and the LastName sorted descending, using the CREATE INDEX T-SQL statement below:

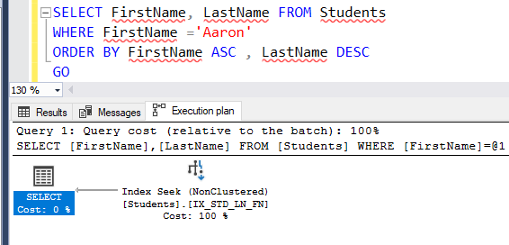
Then trying to run the same previous query again, you will see that the SQL Server Engine will directly seek for the requested data, without an extra overhead to sort the data, as it already matches the order specified in the ORDER BY clause, as shown below:
Index Type
Studying the available types of SQL Server indexes is also recommended, in order to decide which index type will enhance the performance of the current workload, such as Clustered indexes that can be used to sort huge tables, Columnstore Indexes that can be used to enhance the processing performance of the Online Analytical Processing (OLAP) read only workload of data warehouses databases or Filtered indexes for columns that have well-defined subsets of data, such as NULL values, distinct ranges or categorized values.
Index Storage
The storage location of the index may also affect the performance of the queries reading from the index. By default, the index will be stored in the same filegroup as the underlying table on which the index is created. If you design a Non-Clustered index to be stored in a data file different from the underlying table data file and located in a separate disk drive, or horizontally partition the index to span multiple filegroups, the performance of the queries that are reading from the index will be improved, due to the I/O performance enhancement resulted from hitting on different data files and disk drives at the same time.
The initial storage of the index can be also optimized by setting the FILLFACTOR option to a value different from the default value of 0 or 100. FILLFACTOR is the value that determines the percentage of space on each leaf-level page to be filled with data. Setting the FILLFACTOR to 90% when you create or rebuild an index, SQL Server will try to leave 10% of each leaf page empty, reserving the remainder on each page as free space for future growth to prevent the page splitting and index fragmentation performance problems.
Conclusion
After drawing your indexes design strategy, you can easily start applying it to create new useful indexes that the SQL Server Query Optimizer will choose and trust, in order to create the most optimal execution plan for the submitted queries, providing the best overall system performance.
Stay tuned for the next articles in this series, to be familiar with the operations that can be performed on the indexes and how to design, create, maintain and tune indexes.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021