This article talks about the two standard ways of building SQL Database Projects in Azure Data Studio along with the simple steps of implementation.
Read more »
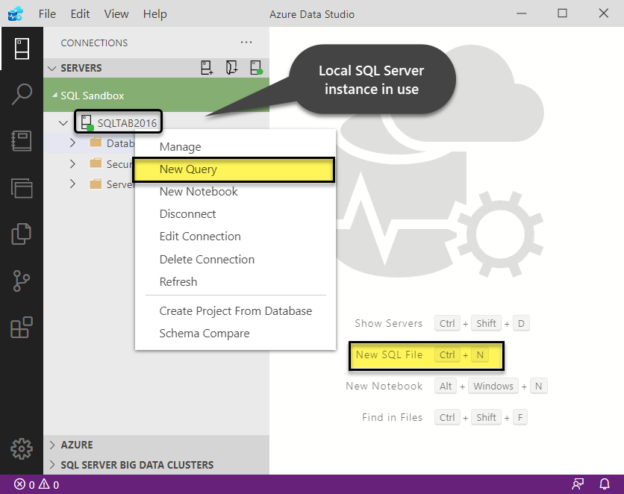
This article talks about the two standard ways of building SQL Database Projects in Azure Data Studio along with the simple steps of implementation.
Read more »
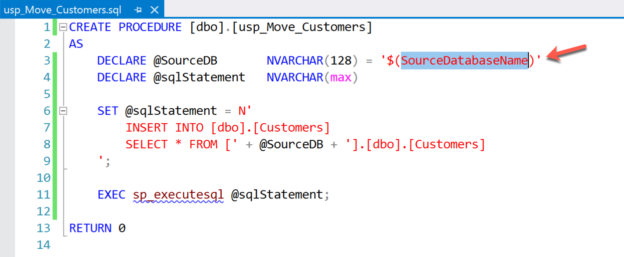
In this article, I am going to explain some of the advanced usages of data-tier applications in Visual Studio. In my previous article, Working with Database Projects, I have explained how you can start building your database applications for SQL Server and Azure SQL Database using Visual Studio. This article will specifically focus on using SQLCMD variables and Publish Profiles of the Data-Tier Application development. For a better understanding, I would recommend reading the previous article and it will help to clear the basic concepts.
Read more »
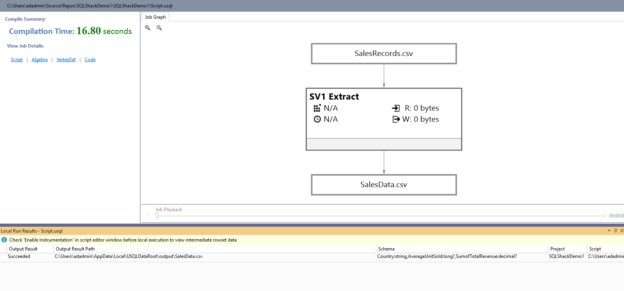
In the 2nd article of the series for Azure Data Lake Analytics, we will use Visual Studio for writing U-SQL scripts.
Read more »
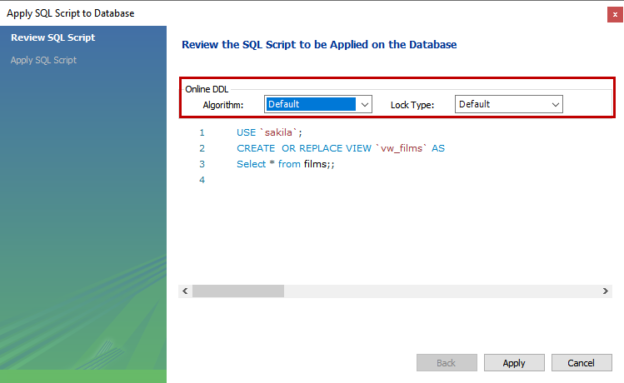
In this article, we are going to learn about the fundamentals of MySQL Views. In this article, I am going to cover the following topics:
Read more »
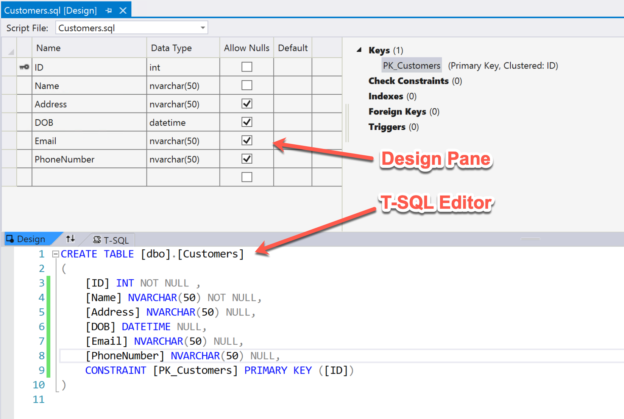
In this article, I am going to talk about developing and deploying a database project, also known as a data-tier application using Visual Studio. In my previous article Getting started with Data-Tier Applications using Visual Studio, I have provided an overview of the data tier applications and how can we create one using Visual Studio. This article is a follow-up to the previous article. I’d advise you to have a look at it before proceeding forward with this as this is a continuation of the previous. For the article, I would be using Visual Studio 2019, however, you are free to use any other versions of Visual Studio.
Read more »
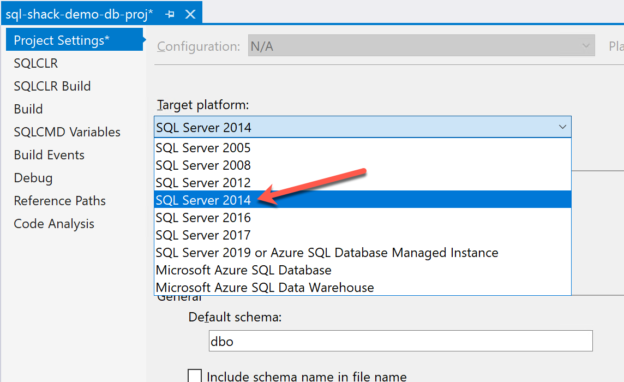
In this article, I am going to talk about creating a data-tier application using Visual Studio. In my previous article An introduction to Data-Tier applications in SQL Server, I have explained in detail what a data-tier application is all about. I have explained what the different types of data-tier applications are available and how can we create such applications from existing SQL Server databases. In this article, the primary focus would be to create data-tier applications from scratch using Visual Studio. For this article, I am going to use Visual Studio 2019, however, the technique will remain similar for other editions of SQL Server as well.
Read more »
In this article, we will show how to use the GIT repository during the pipeline development phase in Azure Data Factory, to save the changes incrementally before publishing it completely to the Data Factory production environment.
Read more »
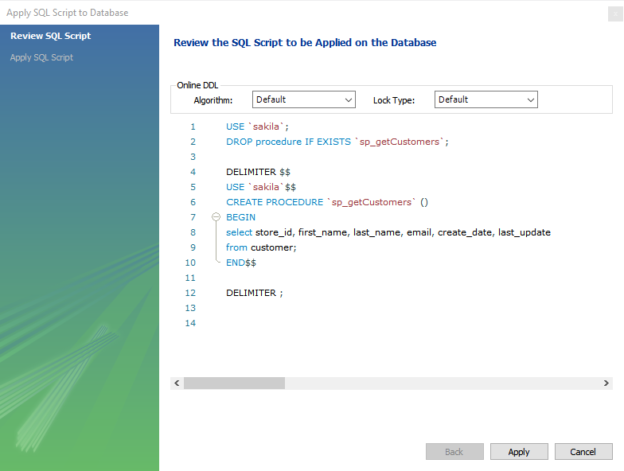
In this article, we are going to learn about the stored procedures in MySQL. In this article, I am covering the basics of the stored procedure that includes the following
Read more »
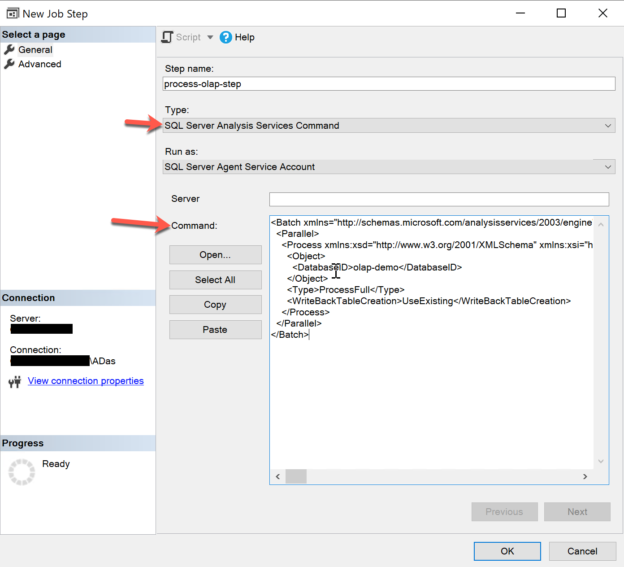
In this article, I am going to introduce some advanced usages of the SQL Server Agent service in Microsoft SQL Server. In my previous article, Introduction to SQL Server Agent, I have discussed in detail how to use the service and the various components related to the service. To recap briefly, the SQL Server Agent is a job scheduler service within SQL Server and allows us to schedule T-SQL scripts, SSIS jobs, automate database backups and other tasks etc. In the last article, I have shown how to schedule a simple T-SQL script using the SQL Server Agent. This article will focus more on advanced concepts like scheduling a package in SSIS and processing an OLAP cube.
Read more »
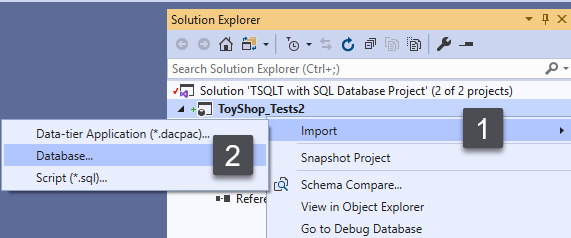
This article talks about multiple ways to install tSQLt for SQL unit testing database projects managed through SQL Server Data Tools (SSDT).
Read more »
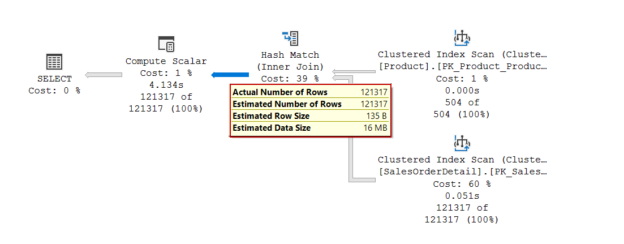
In this article, we will explore a new SQL Server 2019 feature which is Scalar UDF (scalar user-defined) inlining. Scalar UDF inlining is a member of the intelligent query processing family and helps to improve the performance of the scalar-valued user-defined functions without any code changing.
Read more »
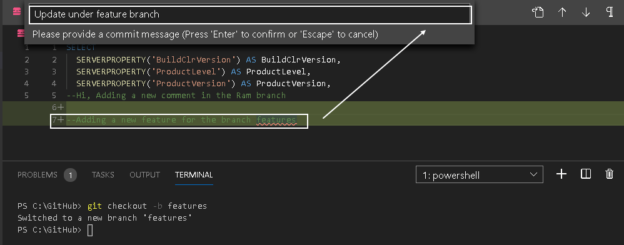
In this 5th article of the Source Control series, we will explore the concept of branches in a Git source control and GitHub repositories.
Read more »
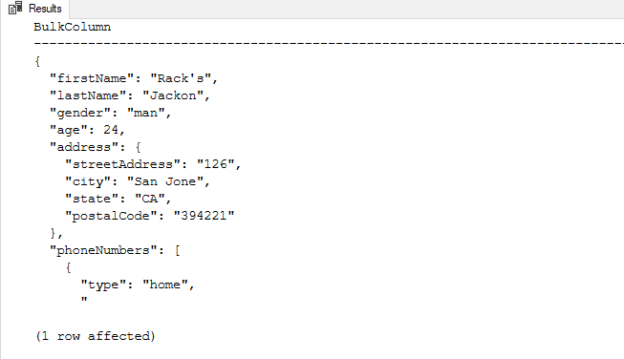
In this article, we will learn how to parse and query JSON in SQL Server with the help of the OPENJSON function. Firstly, we will briefly look at the data structure of the JSON and then we will learn details of the parsing and querying JSON data using the OPENJSON function.
Read more »
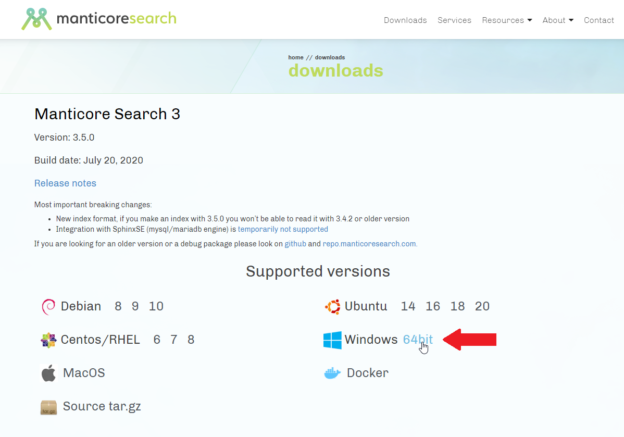
In this article, we will be talking about Manticore Search, which is an open-source search engine first released in 2017 as a fork of the Sphinx search engine. We will try to describe this search engine briefly, mention some of its differences from the Sphinx search engine, and we will provide a step-by-step guide on how to build full-text indexes from SQL Server databases. Finally, we will show how to connect to the Manticore engine from the SQL Server management studio using a linked server object. In our previously published articles in this series, we talked briefly about the Sphinx search engine and how to create full-text indexes from SQL Server databases.
Read more »
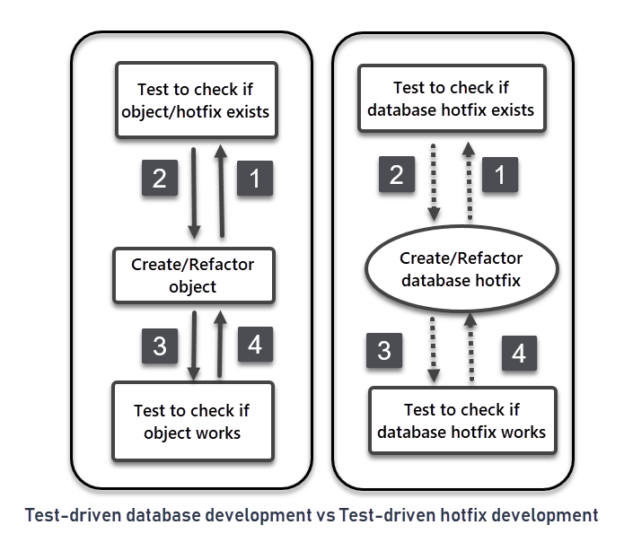
This article talks about test-driven database hotfix development using a very productive database testing framework called tSQLt applying the same SQL unit test based approach.
Read more »
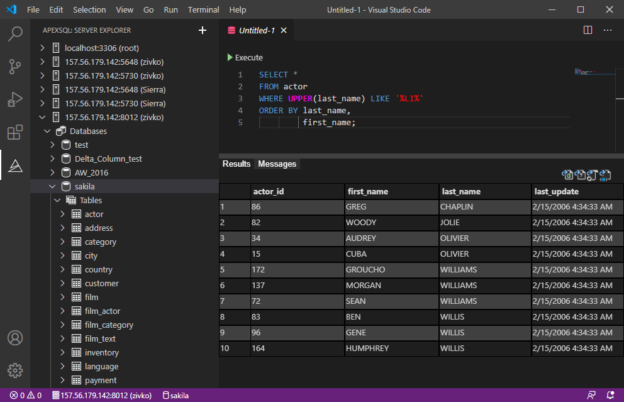
In this article, I’ll walk you through setting up Visual Studio Code for MySQL and MariaDB development using a third-party VS Code extension and give an overview of the basic features.
Read more »
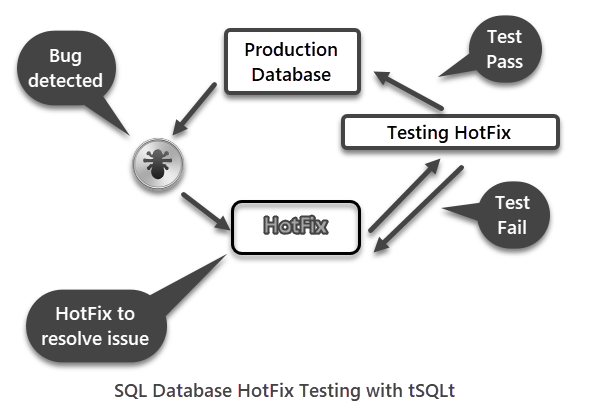
This article talks about getting your database hotfixes tested with tSQLt provided they do not have any inherited complexities or dependencies on things other than SQL database.
Read more »
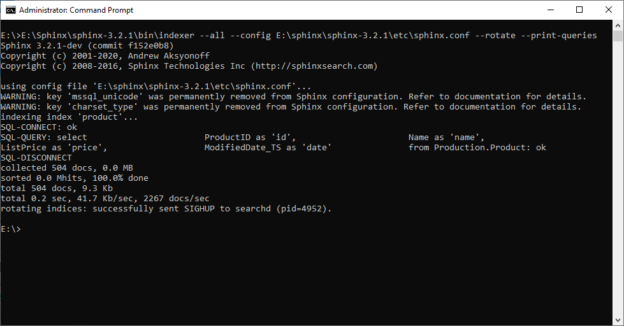
In the previously published article, Getting started with Sphinx search engine, we talked about the Sphinx search engine and how to install it on the Windows operating system. In this article, we will talk about building full-text indexes using Sphinx. We will be covering seven topics:
Read more »
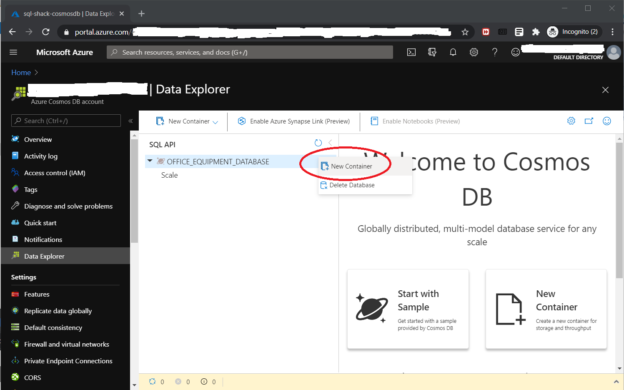
Microsoft Azure offers hundreds of cloud products, with more on the way. In the database space, Microsoft offers Azure Cosmos DB, a NoSQL database product. We can build Java, .Net, etc. applications around Cosmos DB resources. To extend this capability, this article will show how to query Cosmos DB directly from SQL Server.
Read more »
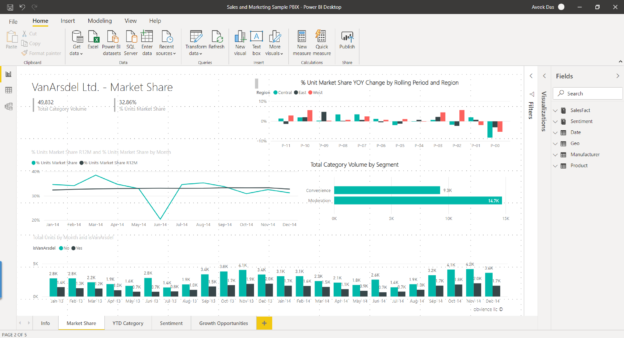
In this article, I am going to introduce the Tabular Object Model (TOM) in the Power BI Data Model and provide an understanding of how this model can be accessed outside of the Power BI environment. For more info about the Tabular Object Model in the Power BI Data Model, please read this article. In this tutorial, we are going to use the Visual Studio Code to simply write a dotnet console application and try to access the Tabular Object Model from the Power BI file. With the help of this knowledge, programmers and BI developers can not only view the underlying model in the Power BI Data Model but also can enhance the data model programmatically by writing a few lines of code. It can also be further improved by automating the creation of the Power BI models with the help of the Tabular Object Model library in dotnet.
Read more »
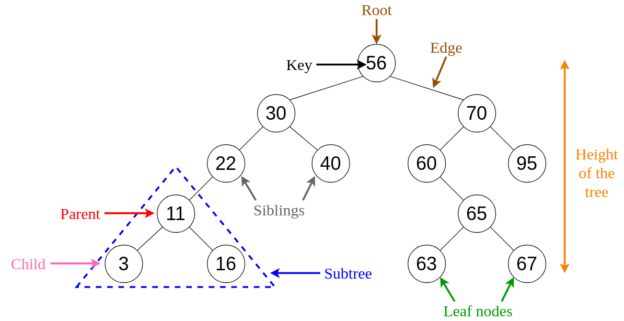
In my previous article, Understanding common Data Structures, I have mentioned the most commonly used data structures in software programming. In this article, let us get into some more details about the other data structures that are a bit complex than the ones already discussed but also used quite often while designing software applications. Here, we will look into the following data structures.
Read more »
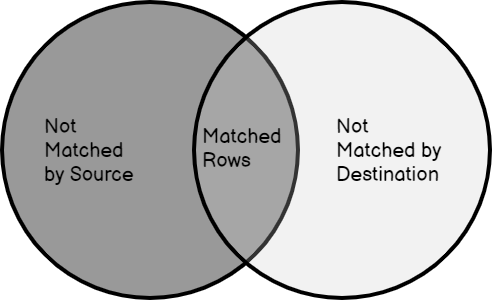
In this article, I am going to give a detailed explanation of how to use the SQL MERGE statement in SQL Server. The MERGE statement in SQL is a very popular clause that can handle inserts, updates, and deletes all in a single transaction without having to write separate logic for each of these. You can specify conditions on which you expect the MERGE statement to insert, update, or delete, etc.
Read more »
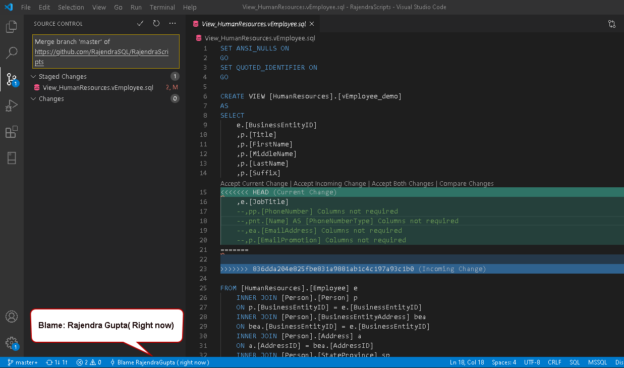
This article explores Visual Studio Code integration with Git Source Control.
Read more »
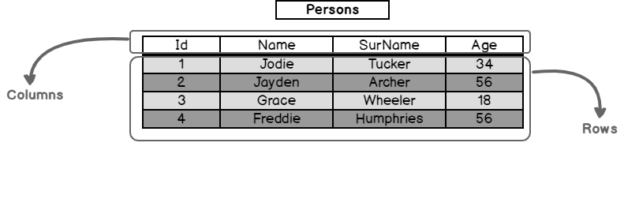
In this article, we will learn the concept of SQL tables and then work on how we can create tables with different techniques in SQL Server.
Read more »
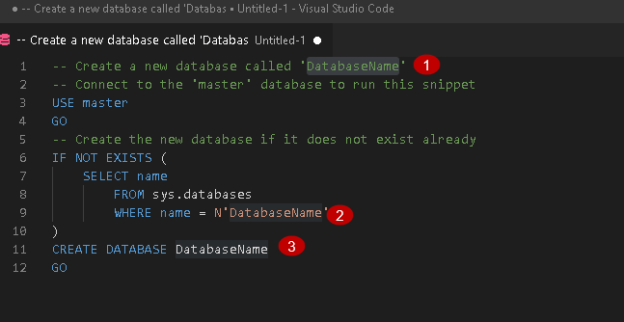
In the previous article, Getting started with Visual Studio Code (VS Code), we took a detailed overview of the popular code editor. It supports various programming languages t-SQL, Python, PHP, AWS CLI, PowerShell, etc. We need to use extensions in the VS code to work with these languages. For example, if we open the T-SQL script, it recommends you for the below extension.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy