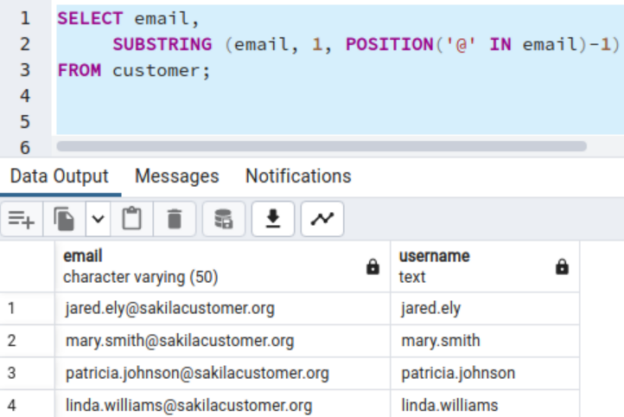
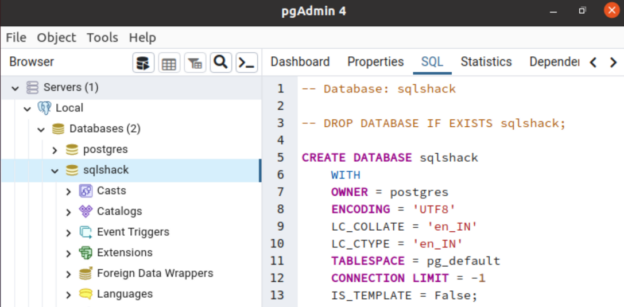
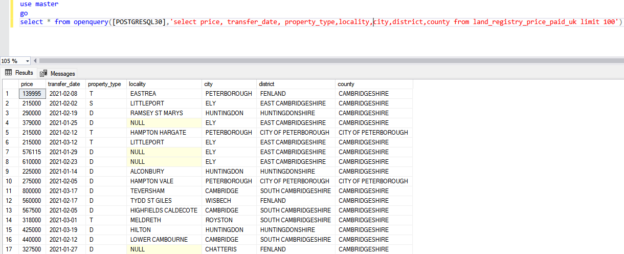
PostgreSQL is an open-source, object-oriented relational database system with reliability, performance, and robustness. It supports SQL (relational) and JSON (non-relational) queries.PostgreSQL’s popular features include Multi-Version Concurrency Control (MVCC), point-in-time recovery, granular access controls, tablespaces, and asynchronous replication.
Read more »