
In my previous article, Understanding common Data Structures, I have mentioned the most commonly used data structures in software programming. In this article, let us get into some more details about the other data structures that are a bit complex than the ones already discussed but also used quite often while designing software applications. Here, we will look into the following data structures.
- Hash Tables
- Trees
- Heaps
- Graphs
Hash Tables
Hash tables are an important data structure that stores mostly data in mostly key-value pairs. The key is generated from a hash function after performing some arithmetic functions on it. Once the hash function performs the operations on it, then the value that is generated is known as the hash value, which can be alphanumeric in nature. Hash tables also support an effective way to lookup for values if we know the key that is associated with the value. Hash tables are good at searching or inserting data irrespective of the size of the data that we are considering for.
When talking about hash tables, we must also need to understand the concept behind the Hash Functions and how do they work. As per the definition by Wikipedia, A hash function is any function that can be used to map data of arbitrary size to fixed-size values. The values returned by a hash function are called hash values, hash codes, digests, or simply hashes. The values are used to index a fixed-size table called a hash table.
You can provide any input to a hash function, but the output that you will receive will be a hash value.
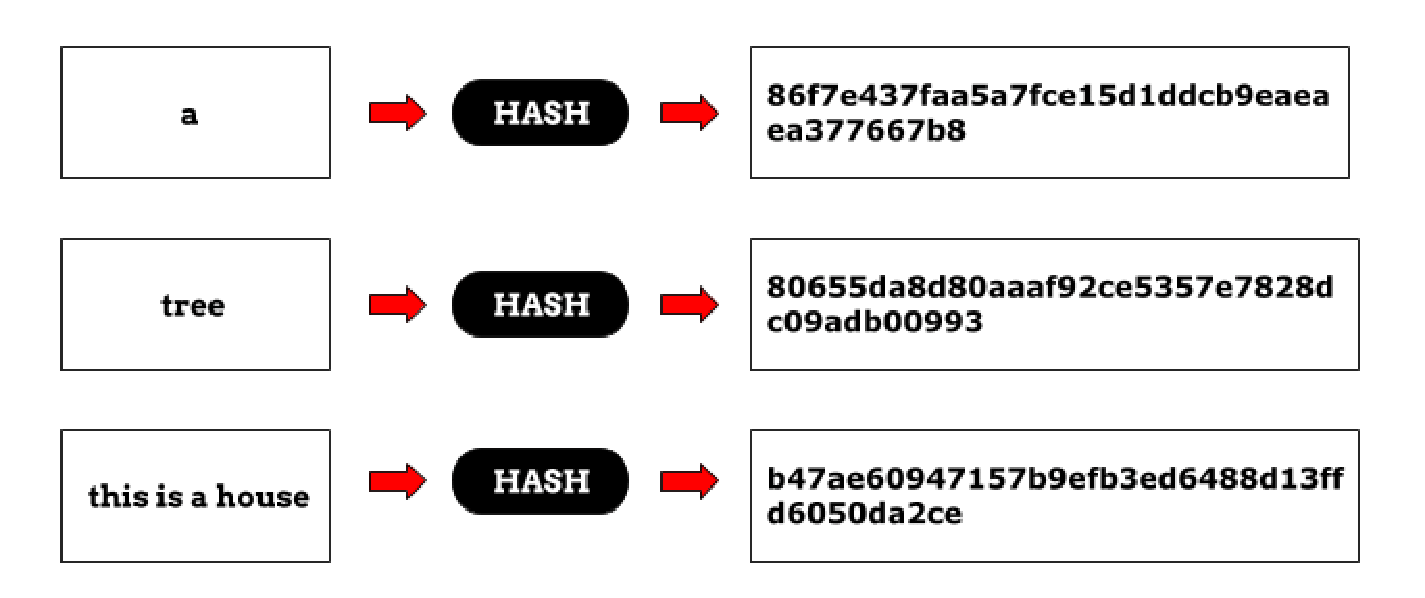
Figure 1 – Hash Function Illustration (Source)
Trees
Trees are another important data structure in which the elements are linked to each other in a hierarchical form. This structure differs from a typical linked list because, in a linked list, the elements are linked in a linear fashion, whereas in a tree, the elements are not linked linearly.
Usually, there are a lot of implementation or examples of trees that exist. All these different types of trees were built to meet the need for certain applications. The few most common examples of trees are binary search trees, b-tree, AVL tree, red-black tree, etc.
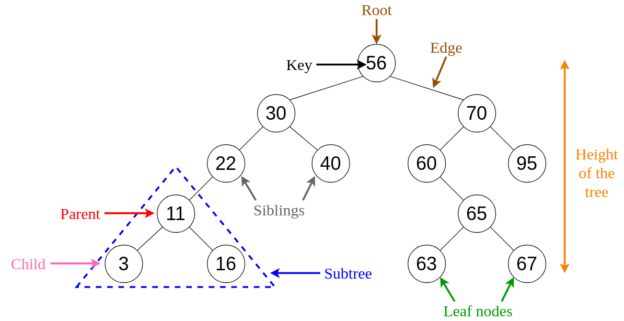
Let us understand in detail about the most common and easy to understand the concept in trees, which is a binary search tree. As you might have already guessed by the name, it is a kind of binary tree in which the data is usually organized hierarchically. Such a binary search tree stores the data in sorted order. Each element in the binary search tree is known as a node. There are three types of nodes, namely, the root node, the siblings, and the leaf node. The node which is at the top of the hierarchy is considered to be the root node, while the ones at the bottom are considered to be the leaf nodes.
Each node comprises the following attributes.
- Key – This denotes the value stored in the node
- Left – This points to the node which is on the left of the child
- Right – This points to the node which is on the right of the child
- Pointer – This is a pointer that points back to the parent node
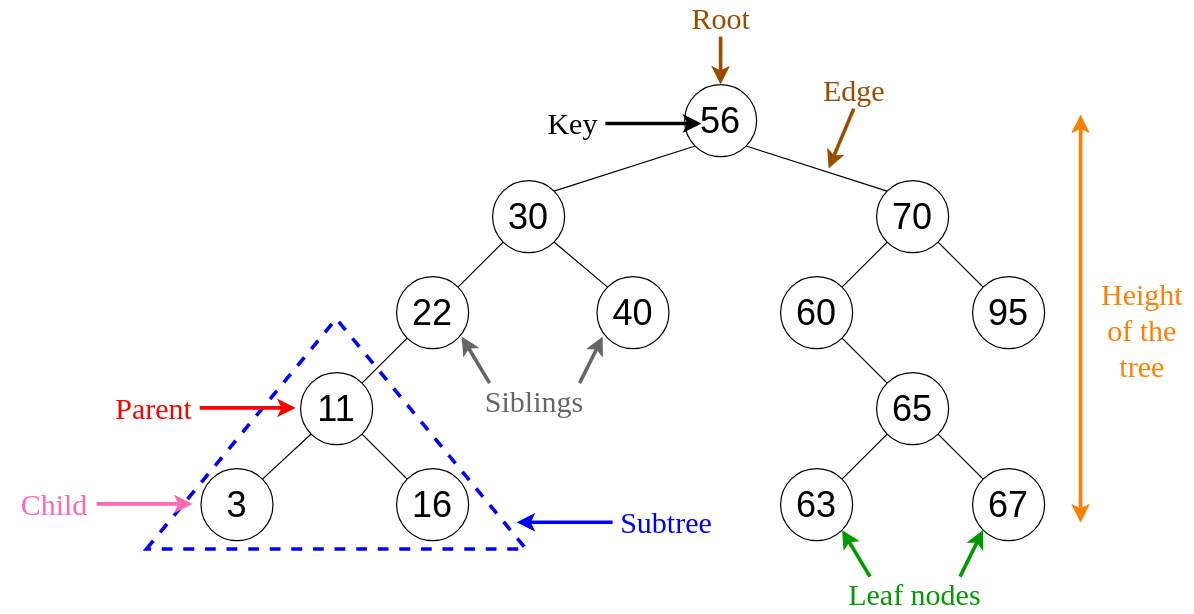
Figure 2 – Binary Search Tree Example (Source)
Binary Trees are used in a large number of search applications where data enters and leaves the system constantly. Apart from this, binary search trees are also used to implement expression solvers and expressions parsers. Treaps are a kind of binary tree which are used in the field of wireless networking.
Heaps
Talking about heaps, it is a special kind of binary tree in which the parent node is compared to the child node, and then the values are arranged accordingly. It can also be referred to as a binary heap.
Heaps can be represented by both using a binary tree as well as by using an array.
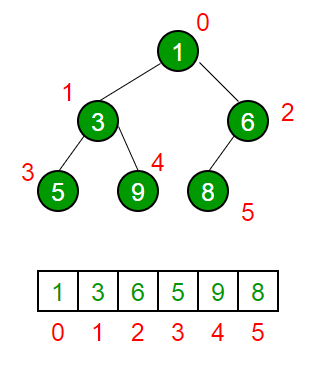
Figure 3 – Binary Heap Representation (Source)
If you look at the figure above, it represents a heap which is denoted by a binary tree, and then the same heap is also denoted by using an array.
There are two types of heaps, as follows:
- Max Heap – In this type of heap, the parent node will contain value more than the child nodes. The root node will, in fact, hold the largest value. This property is known as the max-heap property
- Min Heap – This is exactly opposite to the Max Heap. In this case, the parent node holds values less than the child nodes. So, the root node will hold the smallest possible value
Heaps are used in the heap-sort algorithm. Along with that, heaps can also be used to implement priority queues in which we can order the priorities based on the heap properties by using an array. In python, there is a wonderful module known as the “heapq” which can be used to implement heaps. You can follow this tutorial in case you need some more information on the same.
Graphs
A graph data structure is comprised of a limited set of vertices, also known as nodes, and the edges which connect these nodes. The number of nodes in the graph can be called the order of the graph, whereas the number of edges can be represented as the size of the graph. In a graph data structure, two nodes are considered to be adjacent if both the nodes are connected with a single edge.
There are two types of graph data structures:
- Directed Graphs
- Undirected Graphs
Directed Graphs – We can consider a graph to be directed if all the edges have a direction that can point and indicate the starting and the end nodes. Another concept in a directed graph is self-loops. Edges for which the starting and the ending nodes are the same are known as self-loops.
Undirected Graphs – A graph is typically considered undirected if there are no directions that can indicate the starting and end nodes. In such a graph, it can go in any way between the two nodes. There might also be some vertices for which there are no edges. Such a vertex can be referred to as an isolated vertex or node.
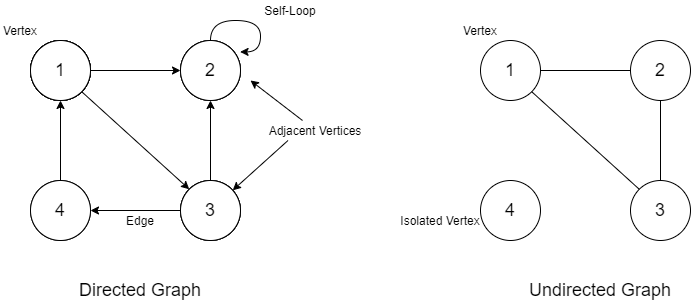
Figure 4 – Graph Data Structures
Some of the important applications of a graph database can be considered as follows.
- It is one of the fundamental parts of modern-day social media systems. You can consider each node as a user, and when the users connect with each other, then the edges are created
- Another important use case is the page ranking algorithm used by Google. In this, each page can be considered as a node, and when the search engines rank the page, they create hyperlinks that can be considered as the edges
- Also, used in the mapping industry to represent locations and routes. The locations are the nodes, whereas the routes are the edges
Conclusion
In this article, we have discussed some of the complex data structures that are quite frequently used within the software development world. Everyone must have a good grasp of these concepts before starting to work on any software projects. These basic concepts hold good for most of the programming languages in the world and can be used accordingly. You can refer to a cheat sheet for the time complexities of these data structure operations from this link.

He is a prolific author, with over 100 articles published on various technical blogs, including his own blog, and a frequent contributor to different technical forums.
In his leisure time, he enjoys amateur photography mostly street imagery and still life. Some glimpses of his work can be found on Instagram. You can also find him on LinkedIn
View all posts by Aveek Das
- Getting started with PostgreSQL on Docker - August 12, 2022
- Getting started with Spatial Data in PostgreSQL - January 13, 2022
- An overview of Power BI Incremental Refresh - December 6, 2021