
In the previously published article, we talked briefly about Hadoop, and we gave an overview of the SSIS Hadoop components added in the SQL Server 2016 release, and we focused on the Hadoop connection manager and the Hadoop file system task.
As illustrated, there are two SSIS Hadoop components at the package data flow level:
- HDFS Files Source
- HDFS File Destination
Figure 1 – SSIS Hadoop components within the toolbox
In this article, we will briefly explain the Avro and ORC Big Data file formats. Then, we will be talking about Hadoop data flow task components and how to use them to import and export data into the Hadoop cluster. Then we will compare those Hadoop components with the Hadoop File System Task. Finally, we will conclude our work.
Note: To run an experiment, we will use the AdventureWorks2017 database, which can be downloaded from the following link.
Big data files formats
There are many file formats developed for Big Data, but we will talk only about Avro and ORC since they are supported by HDFS source and destination components.
Avro
Apache Avro is a row-oriented data serialization system developed within the Hadoop framework. It relies mainly on JSON to define data types, structure, and to serialize data. Also, it can be used to communicate between Hadoop nodes. You can read more about this technology from the official documentation.
Optimized Row columnar (ORC)
Apache ORC is a column-oriented data storage format developed for the Hadoop framework. It was announced in 2013 by HortonWorks in collaboration with Facebook. This format is mainly used with Apache Hive, and it has a better performance than row-oriented formats. You can read more about this technology from the official documentation.
HDFS File Destination
HDFS file destination is a component used to store tabular data within the Hadoop cluster. It supports text, Avro, and ORC files.
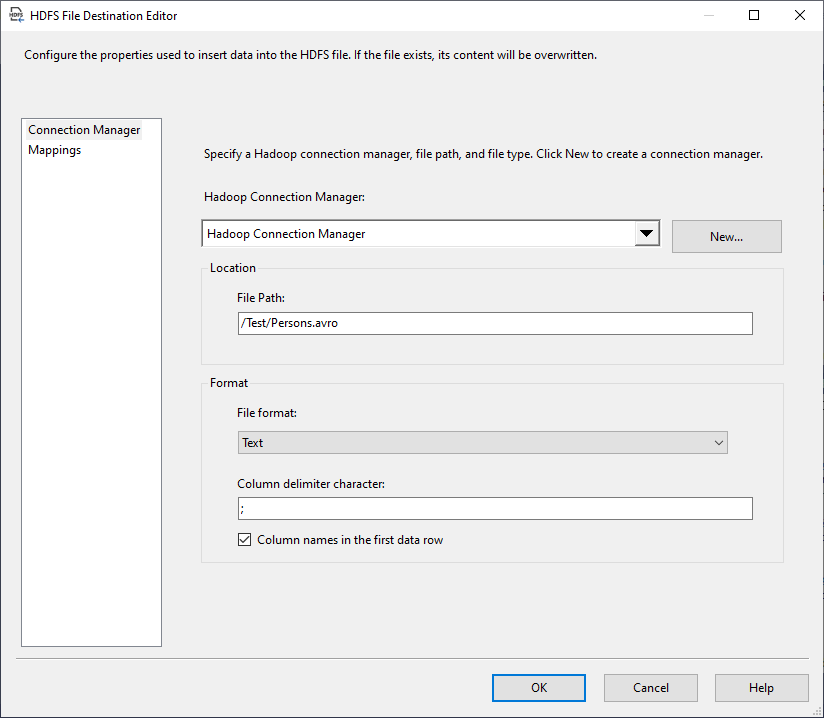
Figure 2 – HDFS file destination editor
If we open the HDFS file destination editor, we can see that it contains two tab pages:
- Connection Manager: Where we should specify the Hadoop connection and the destination file format:
- Hadoop Connection Manager: We should select the relevant Hadoop connection manager (Creating and configuring an SSIS Hadoop connection manager is illustrated in our previously published article in this series, SSIS Hadoop Connection Manager and related tasks)
- Location (File Path): The file path within the Hadoop cluster (it must start with a slash “/”. As an example: “/Test/Persons.avro”).; you don’t need to create directories manually since they are automatically generated before data is inserted.
- File Format: Text, Avro, or ORC
- Column delimiter character (Only available for the Text file format)
- Columns names in the first data row (Only available for the Text file format)
- Mappings: Where we should set the columns mappings
Additional properties
Besides these properties, there are some additional properties that are not shown in this component editor. You can find them in the properties tab (Select the HDFS File destination component and click F4).
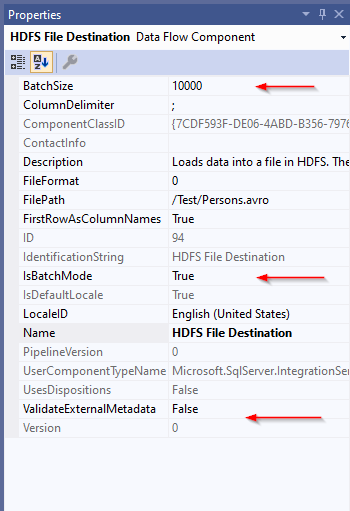
Figure 3 – HDFS File destination properties
These properties are:
- IsBatchMode: Specify whether data is imported in batch mode
- BatchSize: Specify the batch size
- ValidateExternalMetadata: Select whether metadata is validated before data is inserted (This property is common between all SSIS source and destination) components
Expressions
There are some properties of the HDFS file destination that can be evaluated as an expression. These properties are:
- BatchSize
- ColumnDelimiter
- FileFormat
- FilePath
- FirstRowAsColumnHeader
- IsBatchMode
To set these properties, select the data flow task, in the properties tab, click on expression. Then, you will find a list of these properties within the Property Expressions editor form, as shown below:
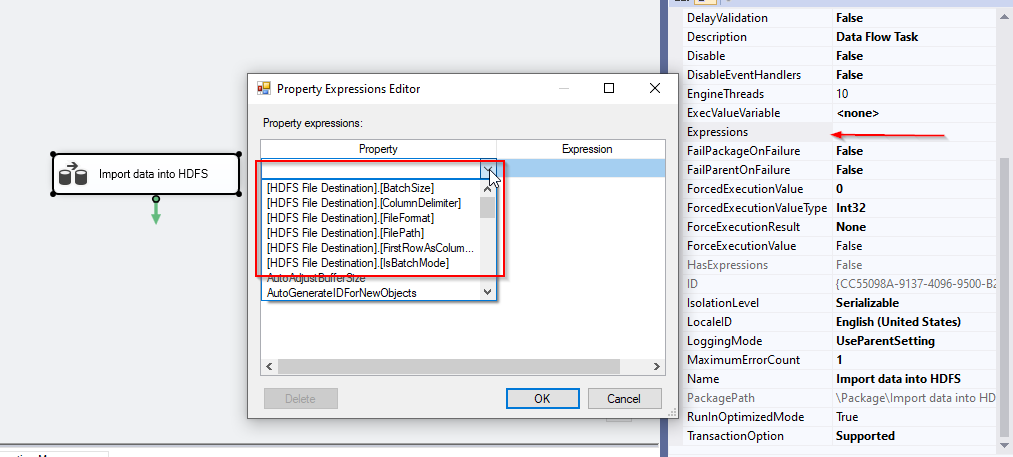
Figure 4 – HDFS file destination expressions
HDFS File Source
HDFS file source is a component used to read tabular data stored within the Hadoop cluster. It supports text and Avro files.
If we open the HDFS file source editor, we can see that it contains three tab pages:
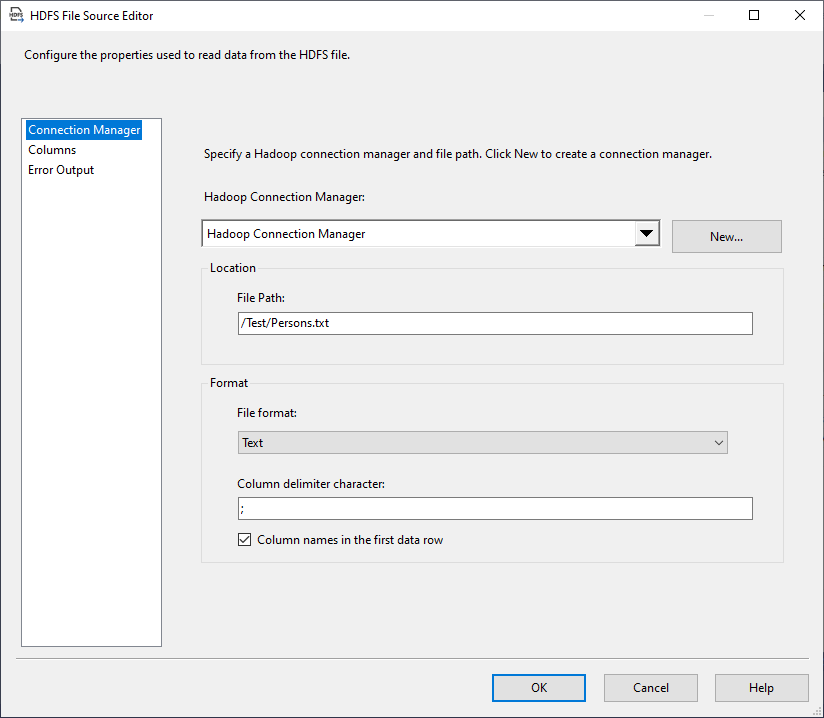
Figure 5 – HDFS File source editor
- Connection Manager: Where we should specify the Hadoop connection and the destination file format:
- Hadoop Connection Manager: We should select the relevant Hadoop connection manager
- Location (File Path): The file path within the Hadoop cluster (it must start with a slash “/”)
- File Format: Text or Avro
- Column delimiter character (Only available for the Text file format)
- Columns names in the first data row (Only available for the Text file format)
- Columns: Where we should select the input columns and add aliases
- Error output: Where we can configure the error output (Like other source components)
HDFS file source differs from the HDFS file destination component since it doesn’t have any custom properties that are not shown within the editor. Besides, only two properties can be evaluated as an expression, as shown in the screenshot below:
- FilePath
- FirstRowAsColumnName
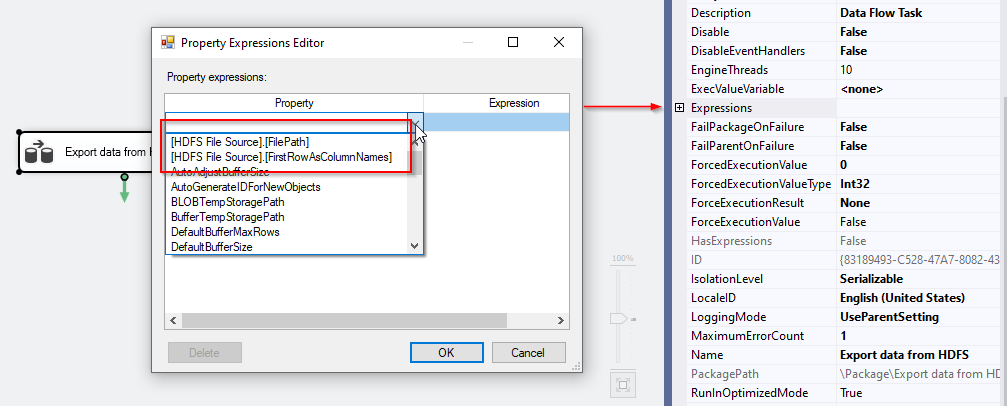
Figure 6 – Evaluating HDFS File Source properties as expressions
Example
To test these components, we will create an SSIS package and add three connection managers:
- Hadoop Connection Manager: to connect with the Hadoop cluster (check the previous article)
- OLE DB Connection Manager: to connect to SQL Server instance where AdventureWorks2017 database is stored
- Flat File Connection Manager: We will use it to export data from HDFS Source:

Figure 7 – Connection managers
We will add two data flow tasks:
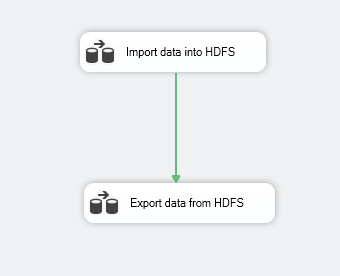
Figure 8 – Package control flow
- Import data into HDFS: it will read data from the [Person].[Person] table into the following file path: “/TestSSIS/Persons.txt”:
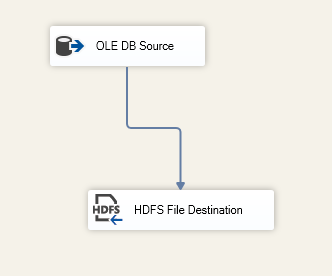
Figure 9 – First data flow task
- Export data from HDFS” it will read data from a file in HDFS within the following path: “/Test/Persons/txt” into a flat-file:
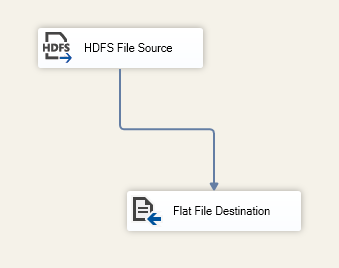
Figure 10 – Second data flow task
We run the SSIS package, and after execution is finished successfully, we can verify that the data is exported successfully from the Hadoop web interface.
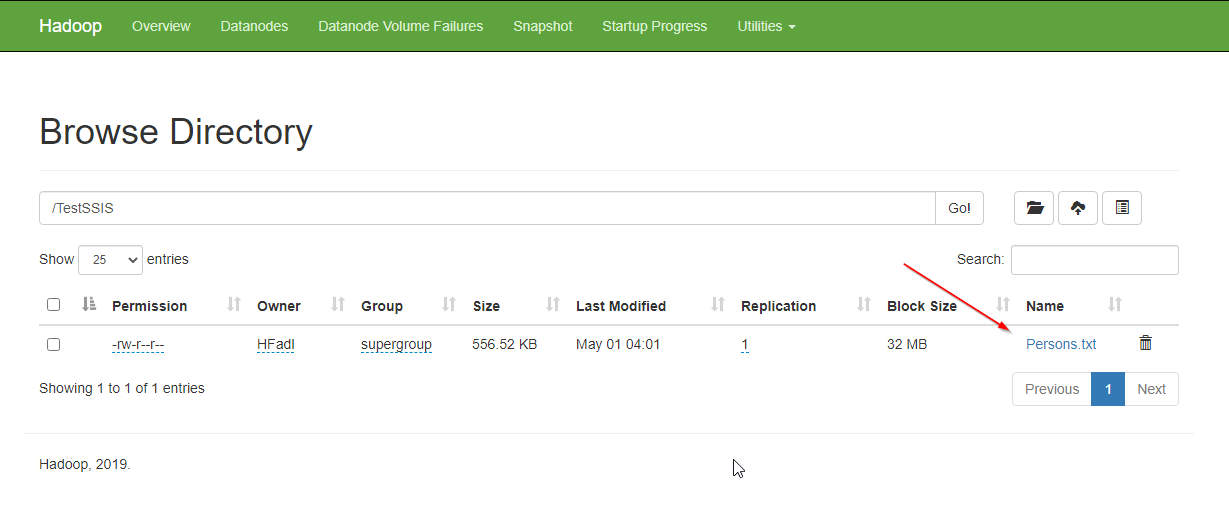
Figure 11 -Data import verified using the Hadoop web interface
Also, the text file is exported successfully into the local file system.

Figure 12 – File exported successfully into the local file system
Hadoop File System Task vs. Data Flow Components
As we mentioned in the previously published article in this series, there are three SSIS Hadoop components at the package control flow level:
- Hadoop File System Task
- Hadoop Hive Task
- Hadoop Pig Task
Since the data flow Hadoop components are used to import or export data from HDFS, one main question could be asked, When to use these components, especially that importing and exporting data can be done using the Hadoop file system task?
There are many differences between both Hadoop components concerning the supported data sources and other features, as shown in the following table.
Feature | Hadoop File System Task | SSIS Hadoop components |
Package level | Control Flow | Data Flow |
Data warehousing approach | ELT | ETL |
Data Sources | File Connection | All connection |
Supported connection manager | Hadoop connection manager | Hadoop connection manager |
Supported types | Files (any extension) + Directories | Text file, Avro, ORC |
Available transformations | No transformation can be applied | All data flow transformation can be applied to the data (Filter, Adding and removing columns, aggregations) |
Supported operations | Copy From HDFS, Copy to HDFS, Copy within HDFS | Copy From HDFS, Copy to HDFS, Copy within HDFS |
Performance | Higher performance since operations are high-level, and data is not validated | Lower than Hadoop tasks |
Figure 13 – Comparison table between Hadoop file system task and data flow components
Conclusion
In this article, we illustrated the SSIS Hadoop components in the data flow level and how to use them to import and export data from Hadoop on-premise cluster. Then we made a small comparison between them and the Hadoop File System Task.
Table of contents
| SSIS Hadoop Connection Manager and related tasks |
| Importing and Exporting data using SSIS Hadoop components |
| Connecting to Apache Hive and Apache Pig using SSIS Hadoop components |

Besides working with SQL Server, he worked with different data technologies such as NoSQL databases, Hadoop, Apache Spark. He is a MongoDB, Neo4j, and ArangoDB certified professional.
On the academic level, Hadi holds two master's degrees in computer science and business computing. Currently, he is a Ph.D. candidate in data science focusing on Big Data quality assessment techniques.
Hadi really enjoys learning new things everyday and sharing his knowledge. You can reach him on his personal website.
View all posts by Hadi Fadlallah
- An overview of SQL Server monitoring tools - December 12, 2023
- Different methods for monitoring MongoDB databases - June 14, 2023
- Learn SQL: Insert multiple rows commands - March 6, 2023