
The Data Flow Task is an essential component in SQL Server Integration Services (SSIS) as it provides SSIS ETL developers with an ability to conveniently extract data from various data sources; perform basic, fuzzy to advance data transformations; and migrate data into all kinds of data repository systems. Yet, with all its popularity and convenience, there are instances whereby the Data Flow Task is simply not good enough and recently, I got to experience such inefficiencies. To demonstrate some of the limitations of SSIS’s Data Flow Task, I have put together a random list of Premier League’s leading goal scorers for the 2019-2020 season.
Pos | Player | Nationality | Club | Goals | Jersey Number |
1 | Jamie Vardy | England | Leicester City | 17 | 9 |
2 | Pierre-Emerick Aubameyang | Gabon | Arsenal | 13 | 14 |
2 | Danny Ings | England | Southampton | 13 | 9 |
4 | Marcus Rashford | England | Manchester United | 12 | 10 |
4 | Tammy Abraham | England | Chelsea | 12 | 9 |
Table 1: Premier League Leading Goal Scorers
Script 1 shows a definition of a SQL Server table that will be used to store data imported from Table 1.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE [dbo].[PLGoalScorers]( [Pos] [tinyint] NULL, [Player] [varchar](50) NULL, [Nationality] [varchar](50) NULL, [Club] [varchar](50) NULL, [Goals] [tinyint] NULL, [Jersey Number] [tinyint] NULL ) ON [PRIMARY] GO |
Script 1: Sample Create table statement in SQL Server
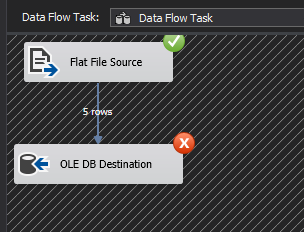
With my source (Table 1) and destination (SQL Server table in Script 1) defined, I proceed to save the data from Table 1 into a CSV file and successfully import it using a Data Flow Task in SSIS, as shown in Figure 1.
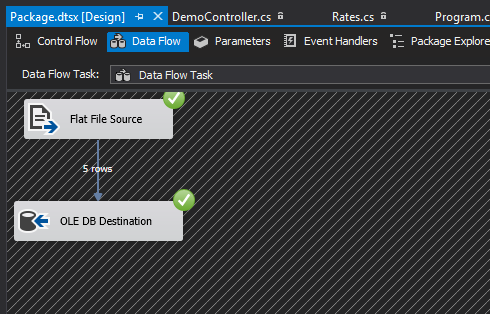
Figure 1: Flat File to SQL Server table Data Migration using Data Flow Task in SSIS
Data Flow Task Limitation #1: Unable to Automatically Refresh Column Mappings
Now, suppose our source dataset is later updated to include a player’s Age column, as shown in Figure 2.
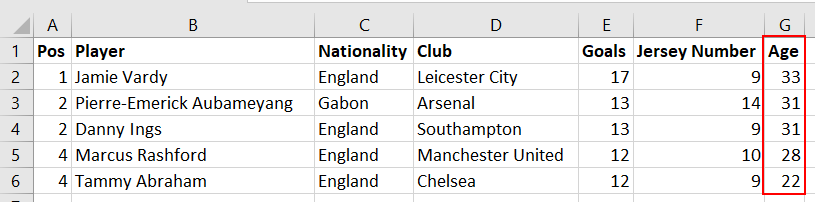
Figure 2: Premier League’s leading goal scorer’s dataset with a newly added column
In order to bring in this new column, we refactor the definition of our SQL Server target table to include the “Age” column. However, when we run our SSIS Data Flow Task package – without updating the metadata of its flat file connection, you will notice in Figure 3 that all data under the “Age” column has been appended to the existing “Jersey Number” column. This is because the column mappings in both the flat file connection and the Data Flow Task have not dynamically refreshed to detect the latest structural changes in both source and target datasets.
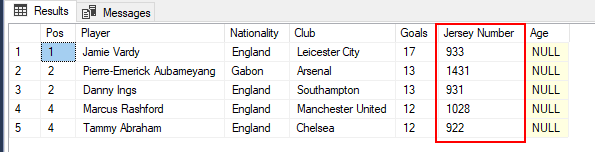
Figure 3: Preview in SQL Server table of mapping mismatch between Jersey Number and Age column
Data Flow Task Limitation #2: Reshuffling Column Positions Breaks the ETL
Another scenario that is likely to get your Data Flow Task throwing errors is when columns in the source dataset get reshuffled. For instance, Figure 4 shows the same dataset as Table 1, but this time, columns “Player” and “Pos” have swapped positions.
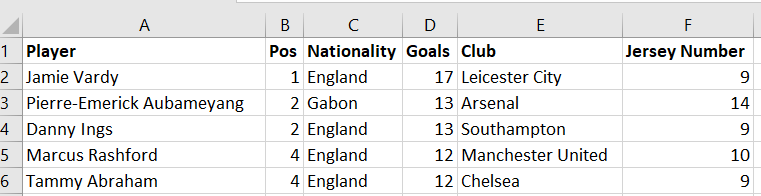
Figure 4: Preview of Premier League’s leading goal scorer’s dataset with reshuffled columns
The first thing you will notice when you try to import the reshuffled data is that whilst the content in rows appear to have been swapped – thus matching the changes in our latest dataset (in Figure 4) – the column headings in the flat file source output remain in their old positions thus creating a mismatch between values and labels, as shown in Figure 5.
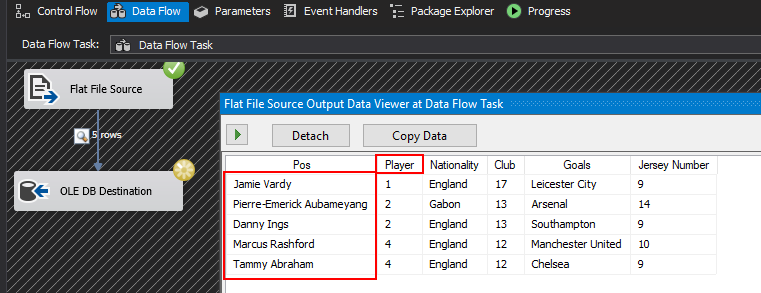
Figure 5: Preview of Flat File Source data via a Data Viewer within a Data Flow Task
Not surprisingly, when we press “Play” in the data viewer to allow this mismatched input data to continue downstream, we run into an error, as shown in Figure 6.
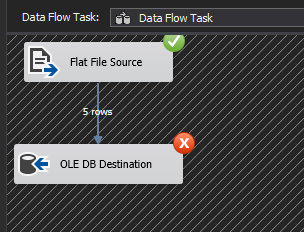
Figure 6: Error at the OLE DB Destination component during data migration using SSIS’s Data Flow Task
If you closely examine the details of the error encountered in Figure 6, you will see that a data conversion error occurred as the first column was expecting a numeric value instead of a string.

Figure 7: Data Flow Task error details relating to failure to convert value due to incorrect data type
To resolve this Data Flow Task error, we will have to manually refresh the metadata of the flat file source and then remap input and output columns of the Data Flow Task. Manually remapping input and output columns in a Data Flow Task can be tolerable if you are dealing with one or two sources with limited fields but can easily become a very daunting and frustrating exercise when dealing with multiple data sources with hundreds of columns.
Dynamic Source-To-Target column mapping using SqlBulkCopy class
The Data Flow Task limitation that was demonstrated above can easily be resolved by using the SqlBulkCopy class. As you might have guessed, the SqlBulkCopy class involves replacing your Data Flow Task with a .Net script, which can then be executed via a Script Task in SSIS. There are 3 main components to getting your data successfully imported using the SqlBulkCopy class.
-
Define your connections
Similarly to configuring a connection manager in the Data Flow Task, the SqlBulkCopy class requires that you specify a source and destination connections. In my case, I have defined two local variables that specify a connection string to a SQL Server database as well as a path to where my CSV source file is stored.

Figure 8: Declaration of local variables containing details about a SQL Server connection string and location of a CSV flat file document
Prepare your DataTable object
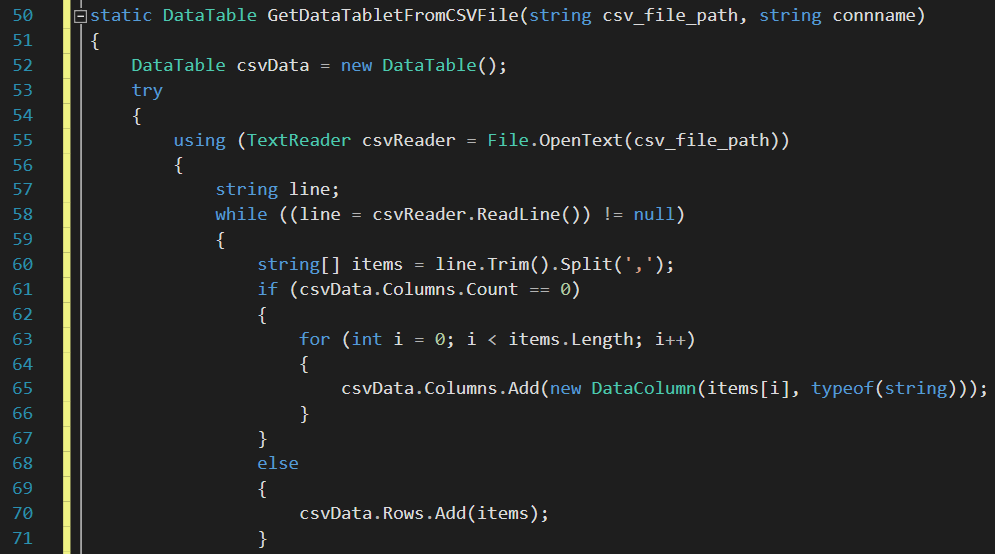
Next, we build a DataTable object as shown in Figure 9, which will be used to store data at runtime. In this example, the role of a DataTable is similar to that of a Data Flow Task in SSIS, however, with one significant advantage being the fact that a DataTable is a memory object that is created at runtime and disposed at the end of an execution – it is never persisted like a Data Flow Task. This means that the DataTable’s source to target column mappings is always refreshed every time the DataTable object is created, which is a valuable benefit when dealing with a SQL Server table or flat file with column structure that keeps on changing.
Figure 9: A sample implementation of a DataTable class in C# for extracting data from flat file document
-
Write data into SQL Server Table
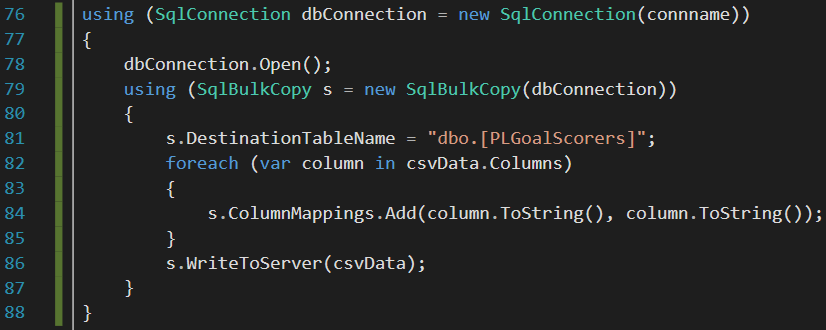
Once you have successfully extracted the contents of your source dataset into a DataTable, you can then bring on the SqlBulkCopy class and use it to bulk-copy the DataTable into a SQL Server table. As shown in line 86 in Figure 10, the SqlBulkCopy class method that is responsible for the actual transfer of data into SQL Server is called WriteToServer and it takes a DataTable as an argument.
Figure 10: Implementation of SQLBulkCopy class in C# to dynamically map source to target and write output using the WriteToServer method.
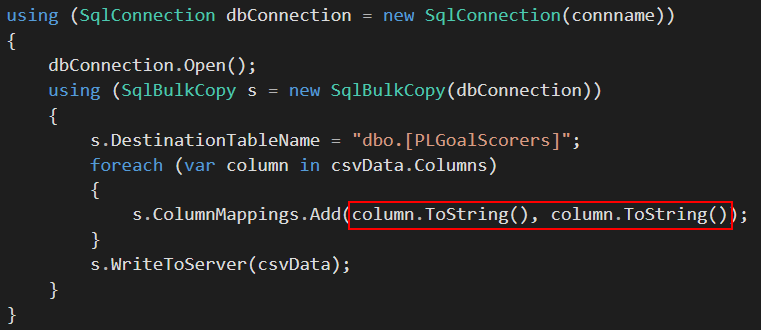
You would have noticed that the actual source to target column mapping in Figure 10 was implemented in line 84, wherein both source (input) and target (output) columns were mapped to similar column names. Mapping input and output columns to the same column name is just one of several column mapping options available within the SqlBulkCopy class. In the following section, we explore the rest of the column mapping options available within the SqlBulkCopy class.

SqlBulkCopy Class: Column Mapping Options
-
Option #1: Column Mapping by Name
The mapping of a column by name assumes that a given column name (i.e., “Player”) exists in both source and target. One advantage of this kind of mapping is that you don’t necessarily need to maintain the order of columns in both source and target datasets. Figure 11 demonstrates the SqlBulkCopy class mapping of a column by name.
Figure 11: Implementation of SQLBulkCopy class in C# using the column by name mapping option
Figure 12 shows how the mapping specified in Figure 11 results in the same column name “Player” being assigned to both destination and source columns.
Figure 12: Runtime demonstration of a column by name mapping between DestinationColumn and SourceColumn properties
One biggest drawback of a column by name mapping is that when there is no exact match on the specified column name, you will run into “The given ColumnMapping does not match up with any column in the source or destination.” Error. The rest of the pros and cons of using a column by name mapping within a SqlBulkCopy class are as follows:
Pros:
- Column by name mapping is not affected by column positions
Cons:
- Column by name mapping requires an exact match on column name – any spaces, hidden characters, etc. will cause a mapping mismatch which will result into a “The given ColumnMapping does not match up with any column in the source or destination.” error
-
Option #2: Column Mapping by Column Position or Index
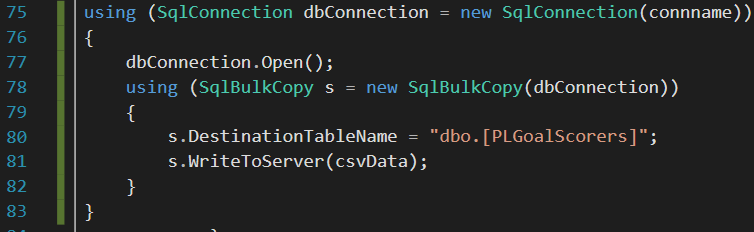
Another column mapping option within the SqlBulkCopy class involves mapping input and output columns by column position or index. This approach assumes that the source and target columns are positioned correctly. This is actually the default mapping behavior if you don’t implement the ColumnMappings.Add method, as shown in Figure 13.
Figure 13: Implementation of SQLBulkCopy class in C# using the column by column position mapping option – without using ColumnMappings.Add method
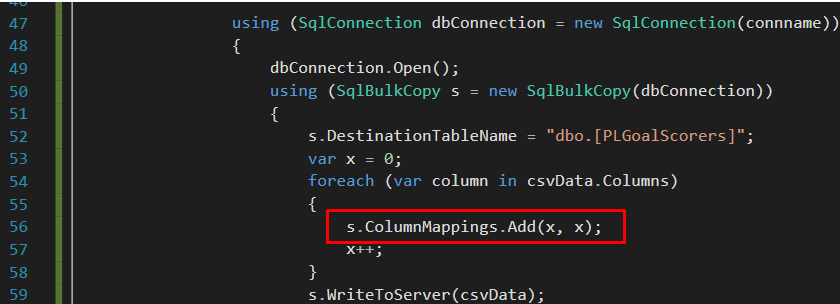
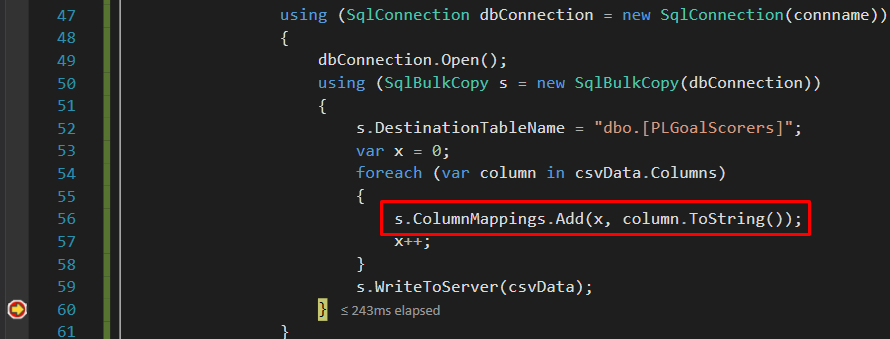
The column by column position mapping in the SqlBulkCopy class also has the option for developers to explicitly implement column mappings by specifying column positions. The simplest implementation of this mapping option is shown in Figure 14, whereby a local variable is declared and incremented at the end of every column mapping combination.
Figure 14: using ColumnMappings.Add method to implement column by column position mapping option of SQLBulkCopy class
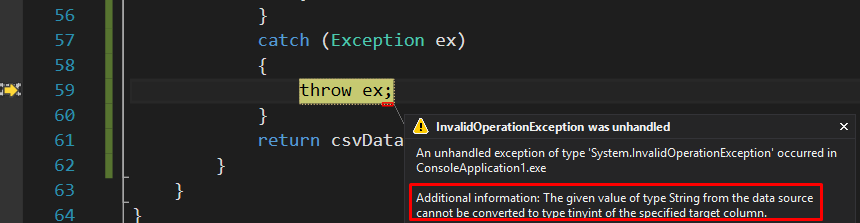
Unlike in the column by name mapping option, the column by column position mapping is not affected by a mismatch in the names of input and output columns instead, data is successfully migrated provided both source and target column data types are compatible. Thus, the responsibility falls with the developer to ensure that the column position and data types of source and target columns are compatible; otherwise, an error similar to that in Figure 15 will be returned.
Figure 15: Column by position mapping error relating to a mismatch between source and target data types
The column by column position mapping has its own pros and cons, as shown below:
Pros:
- Column by column position mapping is not affected by changes in column names
- Column by column position mapping can automatically map columns without specifying the ColumnMappings.Add method
Cons:
- Source and target columns must be positioned correctly
- Requires data type compatibility between source and target columns
-
Option #3: Hybrid of Column by Name & Column by Position Options
Another column mapping option available to you within the SqlBulkCopy class is to use the best of both worlds as it were – as demonstrated in Figure 16 wherein the input source columns are mapped by their positions against column names in the target. This means that column names in the target can be renamed or moved around without having to reorder column positions in the source. You will find this mapping option very useful when dealing with a source that doesn’t have column headers.
Figure 16: Hybrid of Column by Name & Column by Position mapping options available within the SQLBulkCopy class

In conclusion, consider using the SqlBulkCopy class inside a Script Task instead of SSIS’s data flow tasks when you are dealing with a data source whose structure keeps on changing. This will ensure that you can dynamically build column mappings at runtime between source and target without having to manually refresh the input and output column metadata, as is often the case with data flow tasks. Another benefit of using the SqlBulkCopy class is that it offers better data migration speed and performance over the data flow task. However, the SqlBulkCopy class has its own limitations:
- SqlBulkCopy class requires your ETL developers to pick up .Net programming skills
- SqlBulkCopy class can only write its output into a SQL Server table
- You can often come across “The given ColumnMapping does not match up with any column in the source or destination.” error while working with SqlBulkCopy class, which is actually vague
Downloads

Sifiso's LinkedIn profile
View all posts by Sifiso W. Ndlovu