
This article covers the following topics:
- Overview of the Amazon Athena
- Query CSV file stored in Amazon S3 bucket using SQL query
- Create SQL Server linked server for accessing external tables
Introduction
In the article, Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package, we explored data import from a CSV file stored in an Amazon S3 bucket into SQL Server tables using integration package. Amazon S3 is an object storage service, and we can store any format of files into it.
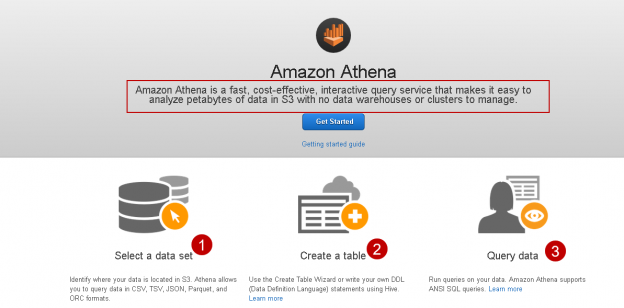
Suppose we want to analyze CSV file data stored in Amazon S3 without data import. Many Cloud solution providers also provide a serverless data query service that we can use for analytical purposes. Amazon launched Athena on November 20, 2016, for querying data stored in the S3 bucket using standard SQL.
Athena can query various file formats such as CSV, JSON, Parquet, etc. but that file source should be S3 bucket. Customers do not manage the infrastructure, servers. They get billed only for the queries they execute. We also do not need to worry about infrastructure scaling. Amazon Athena automatically scales up and down resources as required. It can execute queries in parallel so that complex queries provide results quickly. We can also use it to analyze unstructured, semi-structured, and structured data from the S3 bucket.
It also integrates with another AWS service Quicksight that provides data visualizations using business intelligence tools.
We will use the Amazon Athena service for querying data stored in the S3 bucket. We will also use SSMS and connect it with Athena using linked servers.
Prerequisites
-
We have the following data in a CSV format file:

-
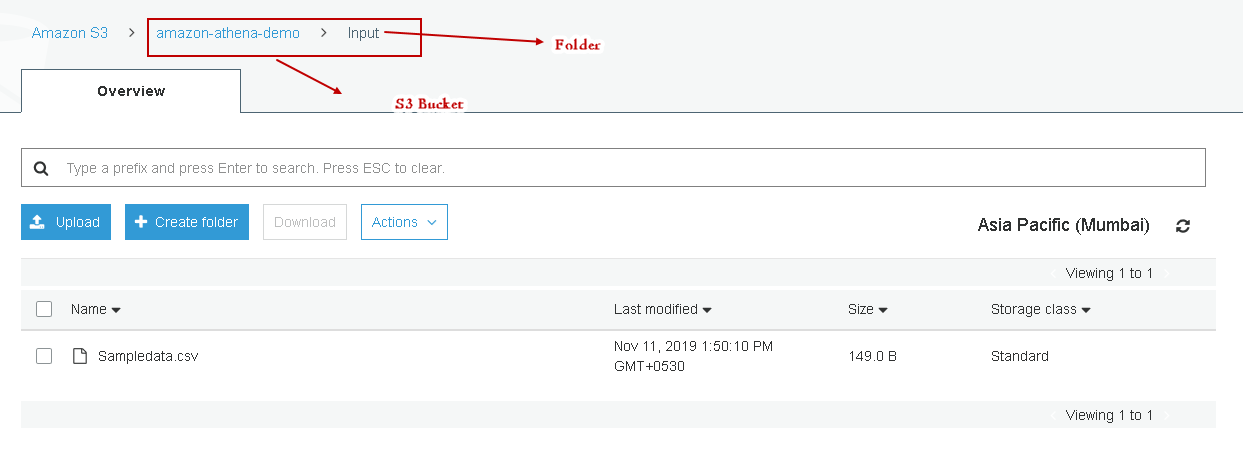
Upload this file into an Amazon S3 bucket
If you do not have an Amazon S3 bucket, follow Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package

In this screenshot, we can see the following:
- S3 Bucket Name: amazon-athena-demo
- Filename: Sampledata.csv
Configuration of Amazon Athena
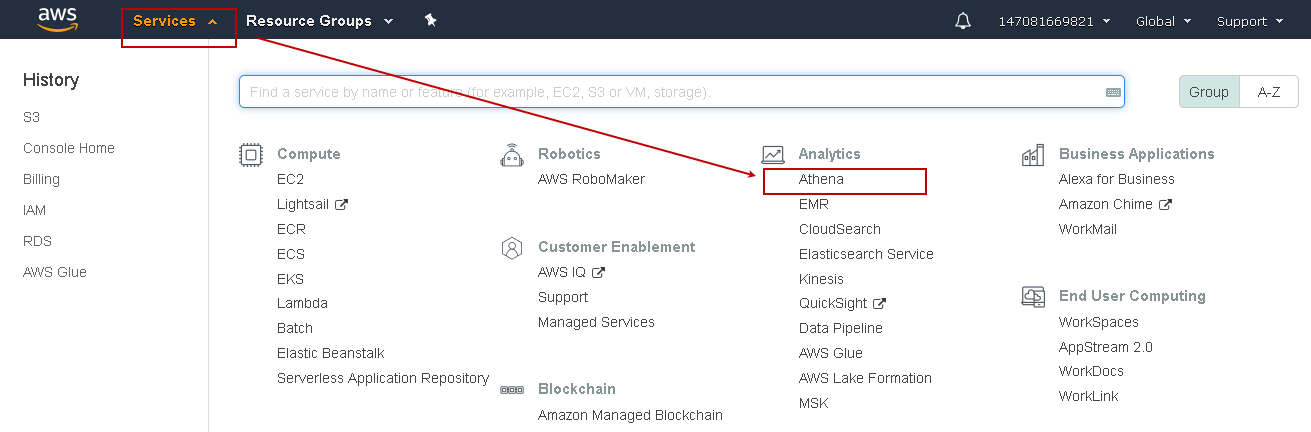
Navigate to services in AWS console, and you can find Athena under the Analytics group as shown below:
Click on Athena, and it opens the homepage of Amazon Athena, as shown below. It shows a brief description of the service and gives you high-level steps:
- Select a data set
- Create a table
- Query data
Click on Get Started button below the description:

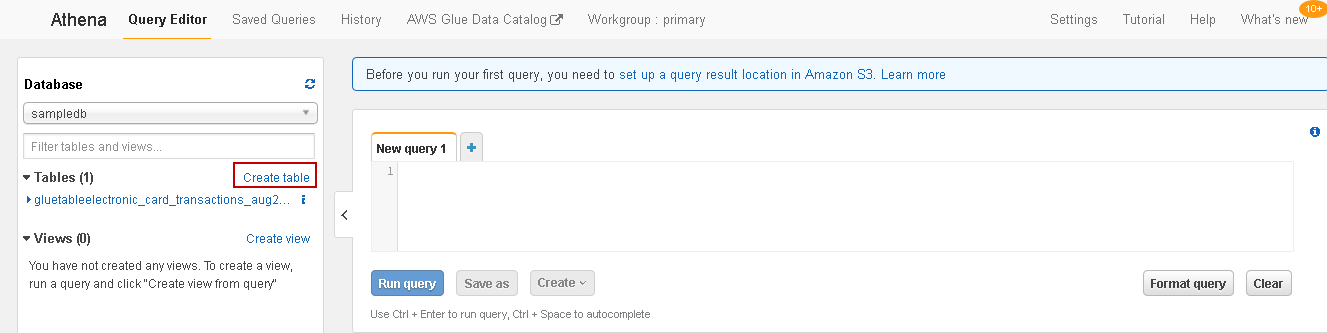
It opens the following screen. Click on Create table as highlighted above:
It gives the following options:
- Create a table from S3 bucket data
- Create a table from AWS Glue crawler
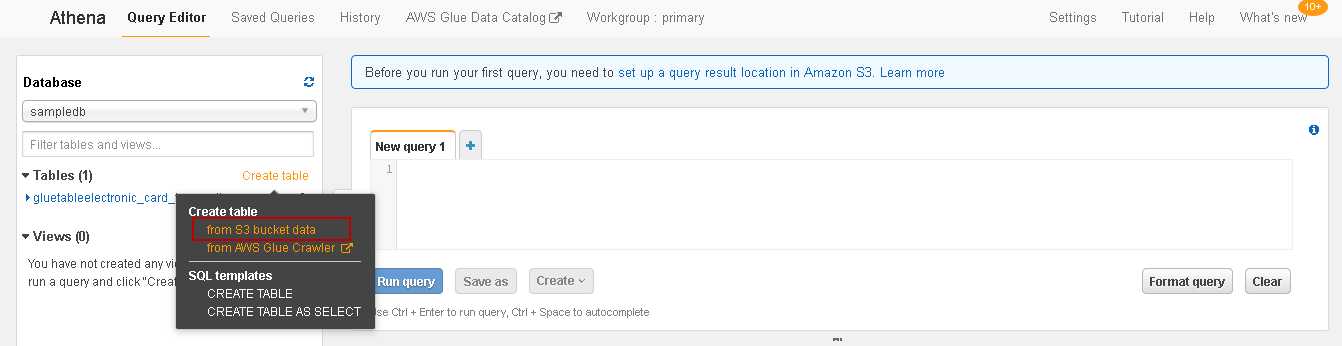
We have a CSV file stored in the Amazon S3 bucket, therefore, click on Create table from S3 bucket data. It opens a four-step wizard, as shown below:
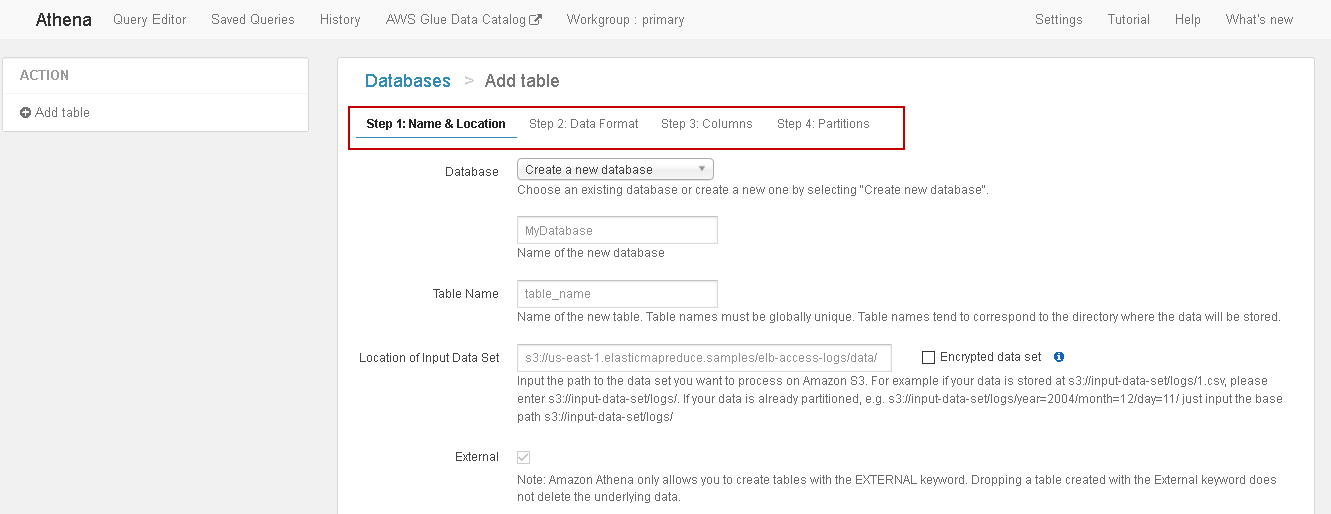
Step 1: Name & Location
In this step, we define a database name and table name.
- Database: If you already have a database, you can choose it from the drop-down
We do not any database, therefore, select Create a new database option and specify the desired database name.
- Table Name: Specify the name of the new table. It should be unique to the S3 bucket
- Location of input data set: Specify the location of the Amazon S3 bucket
You need to enter the location in the following format:
S3://BucketName/folder name
In my example, the location is S3://amazon-athena-demo/ as can be seen in the 4th step:
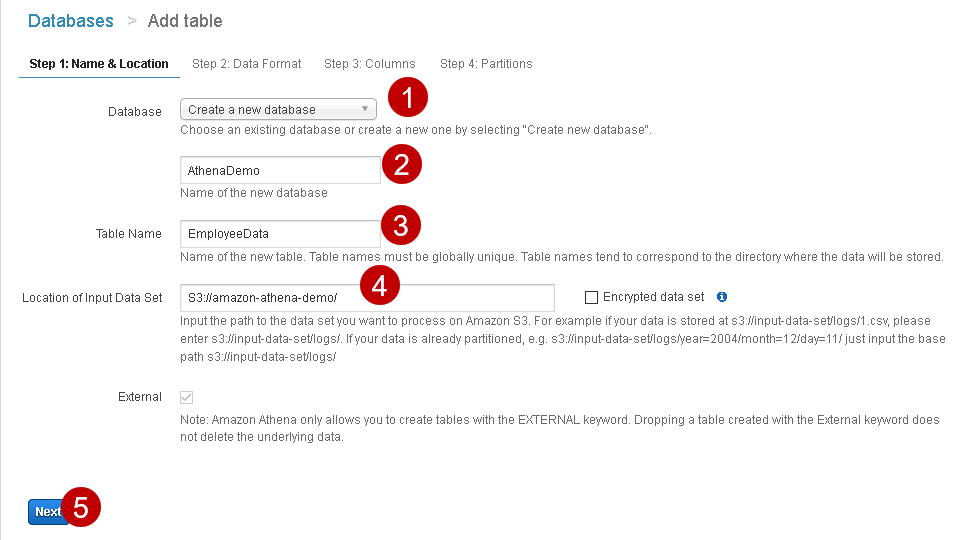
Click on Next, and it moves the wizard to the next page.
Step 2: Data Format
In this step, select the file format from the given options. In my example, we have a CSV file stored in the S3 bucket. Therefore, let’s choose the CSV format:
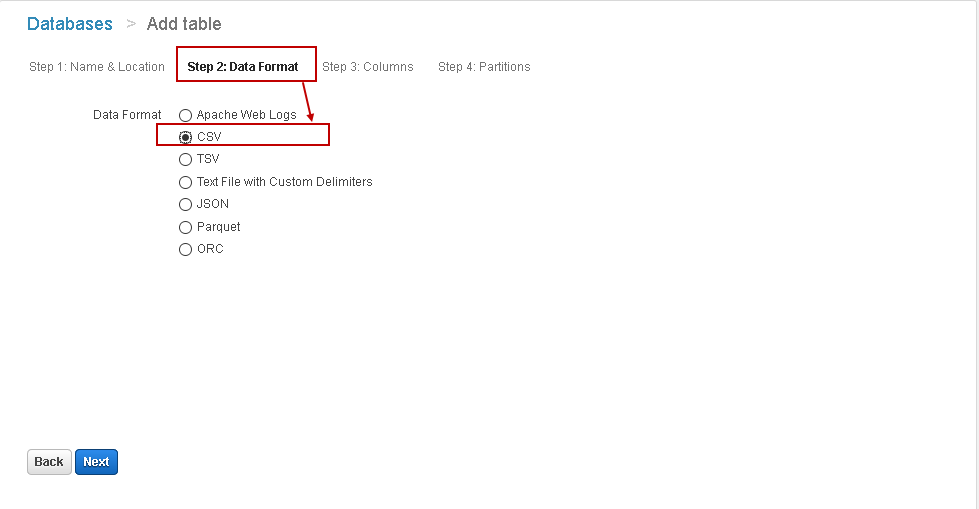
Step 3: Columns
In this step, we specify the column names and data type for each column available in the CSV:
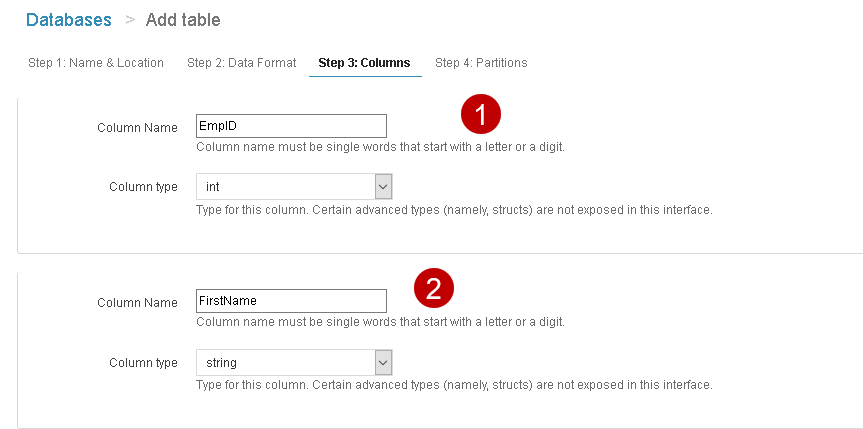
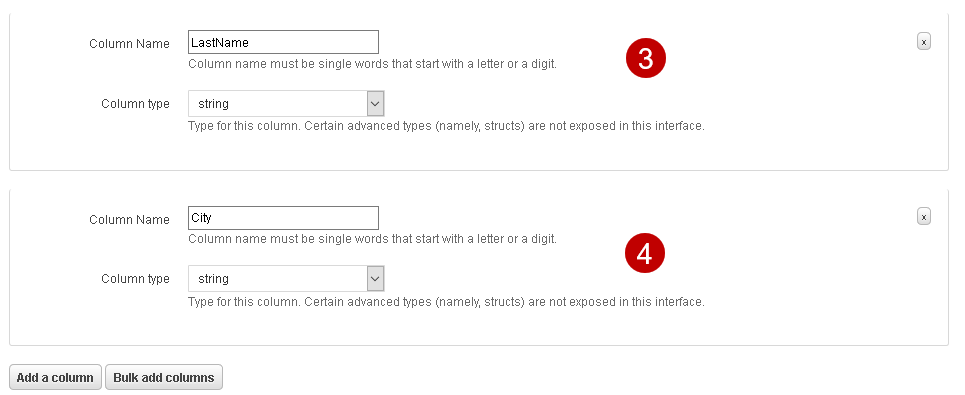
It might be a tedious job to specify the column name and their data types for each column, especially we have a large number of columns. We can use bulk add columns to specify columns quickly.
Step 4: Partitions
We do have complex data and do not require data partition. We can skip this step for this article.
In the next step, it shows the external table query. You can verify the database name that we specified in step 1:
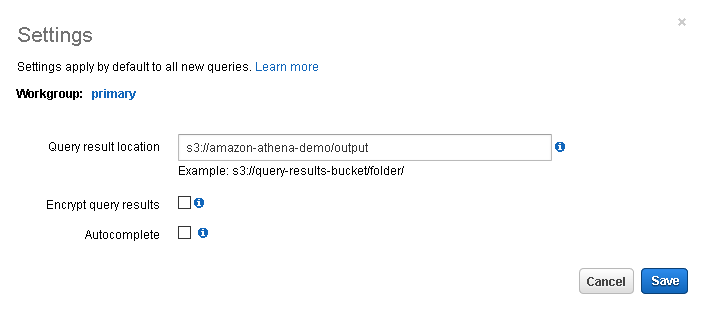
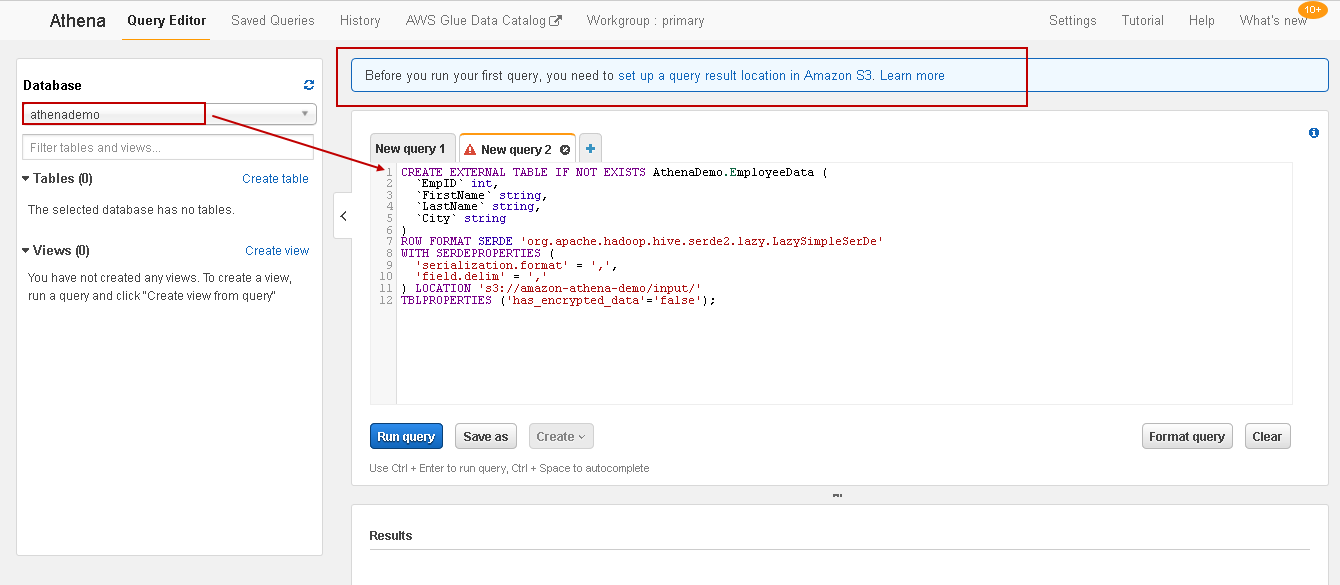
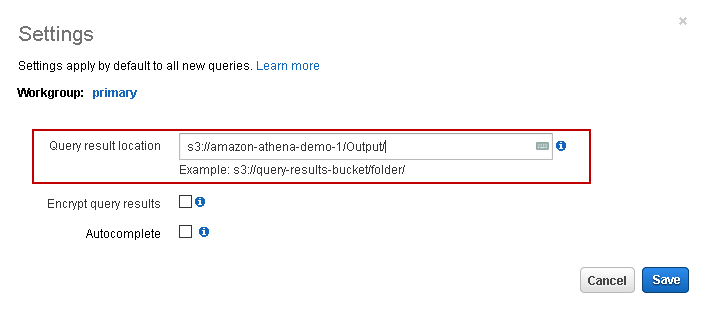
Before we execute the query, we need to specify the location of the query results, as shown in the highlighted message. Click on it, and it opens the pop-up box, as shown below:
Specify the Query result location and save it.
Query result format S3://bucketname/folder
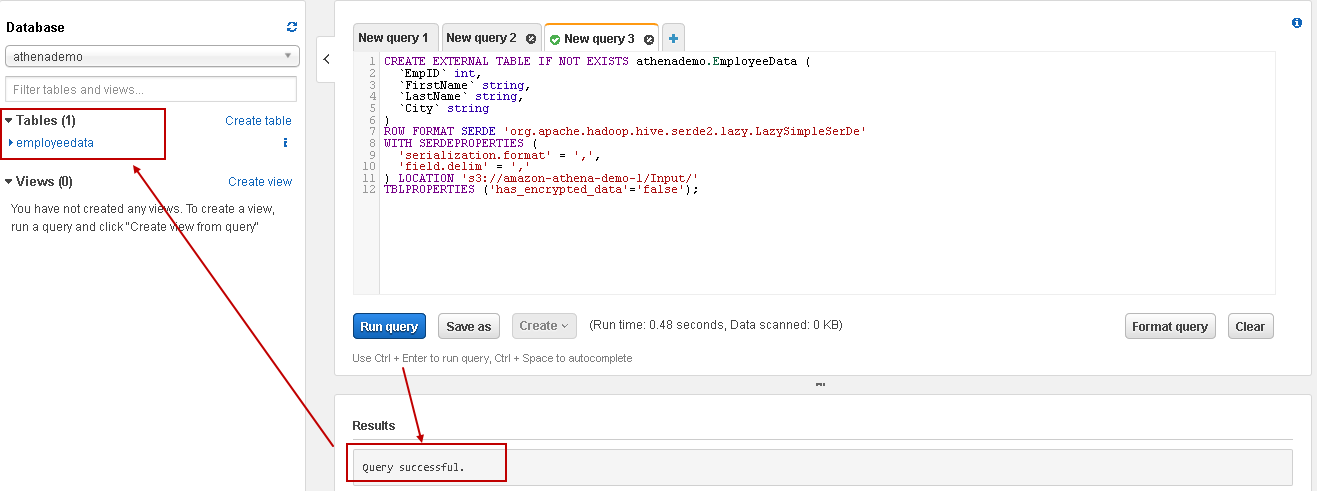
Now click on Run query, and it executes the query successfully for creating an external table. We can also see the newly created table in the tables list:
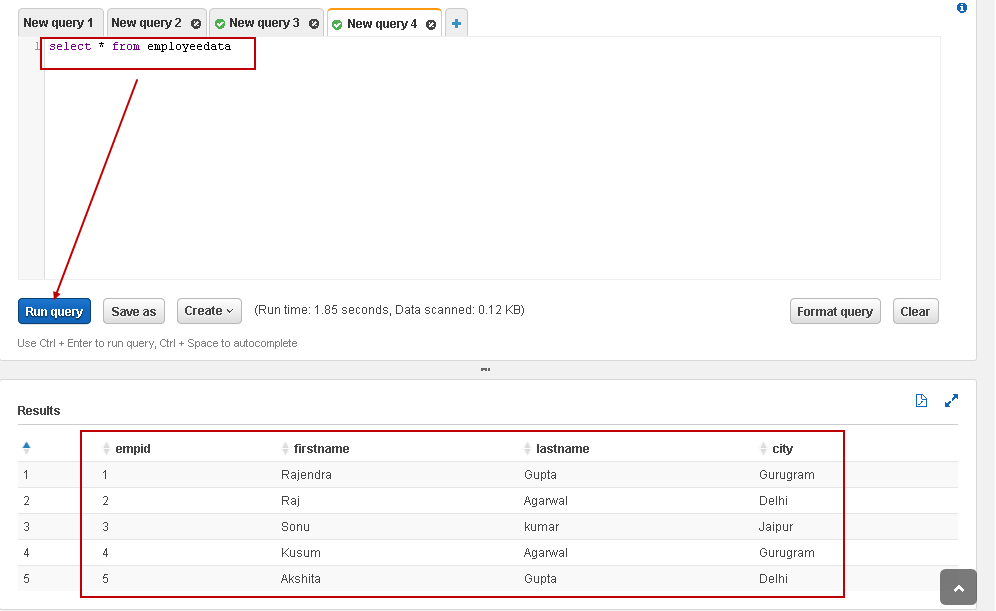
In the new query window, execute the following Select statement to view records from CSV file:
|
1 |
SELECT * FROM employeedata |
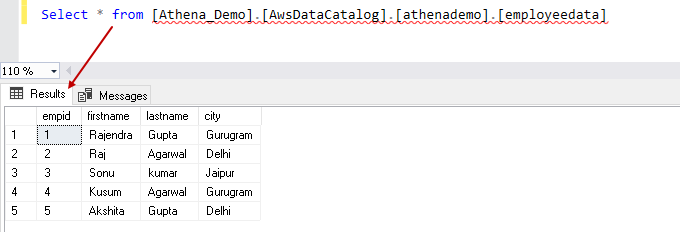
In the following screenshot, we can see the data from the external table that is same as of the CSV file content:
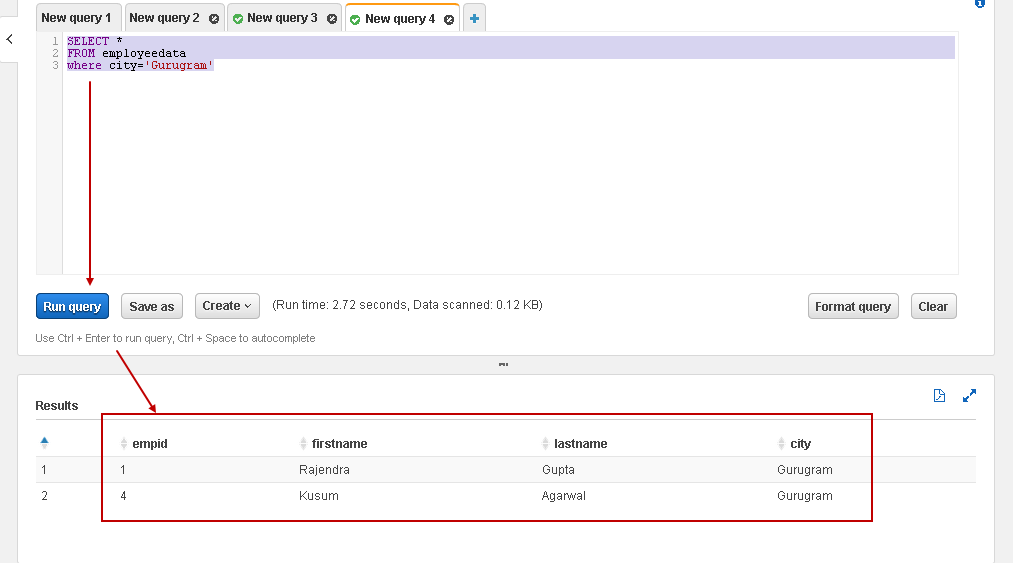
Let’s execute another query to filter the employee records belonging to Gurugram city:
|
1 2 3 |
SELECT * FROM employeedata WHERE city='Gurugram'; |
Similarly, we can use SQL COUNT to check the number of records in the table:
|
1 2 |
SELECT count(*) as NumberofRecords FROM employeedata |
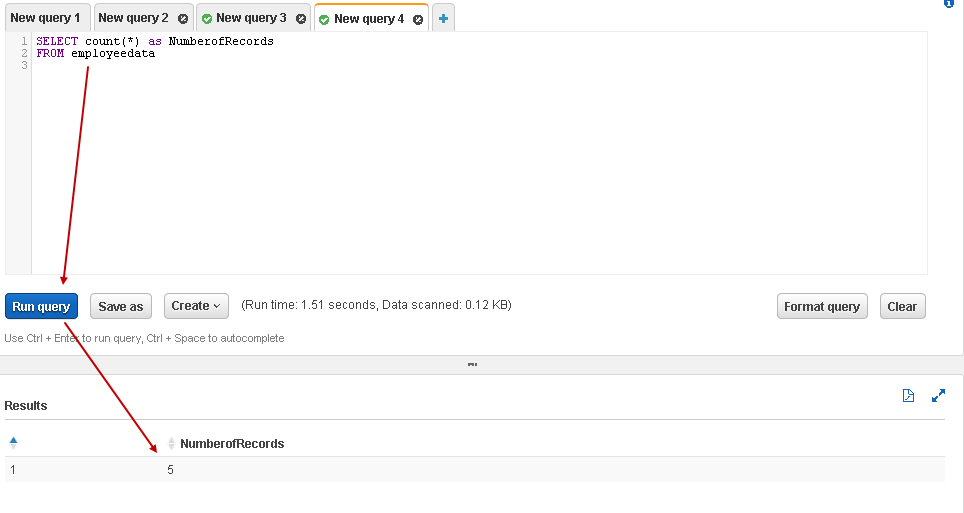
It is a cool feature, right! We can directly query data stored in the Amazon S3 bucket without importing them into a relational database table. It is convenient to analyze massive data sets with multiple input files as well.
Use SSMS to query S3 bucket data using Amazon Athena
In this part, we will learn to query Athena external tables using SQL Server Management Studio.
We can access the data using linked servers.
Steps for configuring linked server
Download 64-bit Simba Athena ODBC driver using this link:
Click on Next and follow the installation wizard:
Once installed, open the 64-bit ODBC Data source. It opens the following ODBC configuration. You can see a sample Simba Athena ODBC connection in the System DSN:
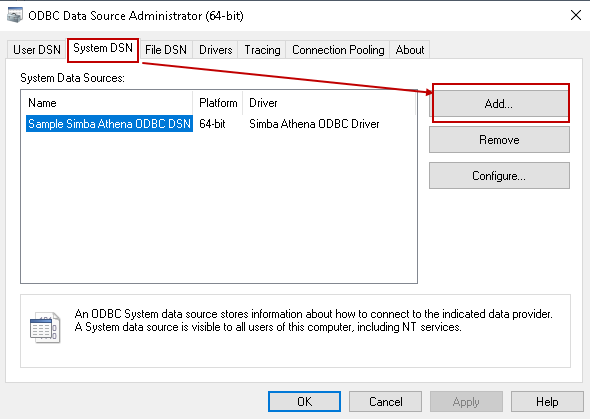
Click on Add and select the driver as Simba Athena ODBC Driver:
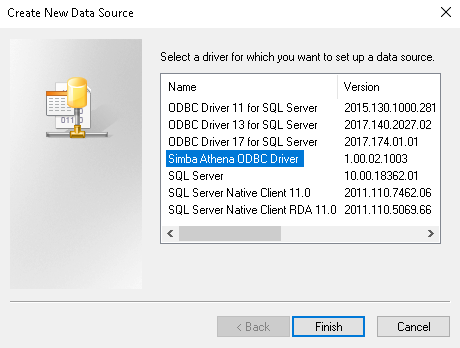
Click Finish, and it asks you to provide a few inputs:
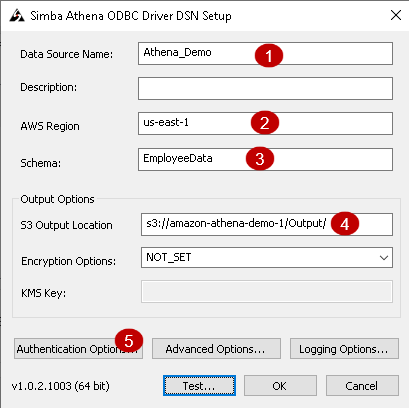
- Data Source Name: Specify any name of your choice for this ODBC connection
- AWS Region: It is the region of the S3 bucket that we use in the external table
- Schema: It is the external table name
- S3 Output Location: It is the S3 bucket location where the output will be saved
Authentication Option: Click on the authentication options and specify the access key, a private key for the IAM user. You can read more about the IAM user, access key and private key using the article Data Import from Amazon S3 SSIS bucket using an integration service (SSIS) package
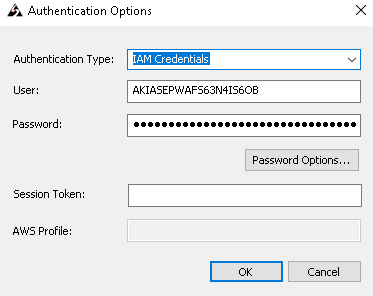
Click OK and test the connection. It shows successful status if all entries are okay:
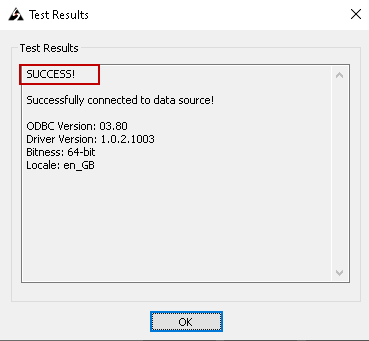
Let’s create the linked server for Amazon Athena using the ODBC connection we configured using the following query:
|
1 2 3 4 5 6 7 |
EXEC master.dbo.sp_addlinkedserver @server =N'Athena_Demo', @srvproduct=N'', @provider=N'MSDASQL', @datasrc=N'Athena_Demo' GO EXEC master.dbo.sp_addlinkedsrvlogin @rmtsrvname=N'Athena_Demo', @useself=N'False', @locallogin=NULL, @rmtuser=N'AKIASEPWAFS63N4IS6OB', @rmtpassword='m94O7wDLdgHcxi5kO2pSsPRCaG+nU2W1RFLmjOWH' GO |
In this query, you can make changes in the following parameters:
- @Server and @datasrc should contain an ODBC data source name
- @rmtuser should contain the Access key
- @rmtpassword should contain the secret key
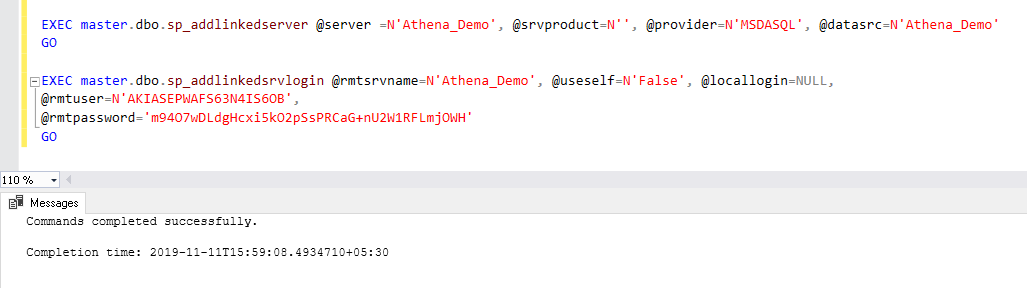
Expand the Server objects, and we can see the linked server. Right-click on the linked server and click on test connection. In the following screenshot, we can see a successful linked server connection:
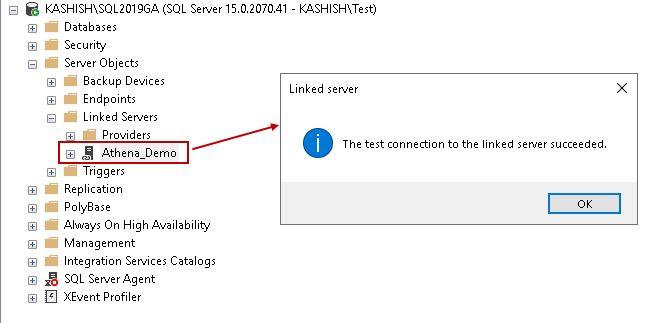
Now, expand the linked server, and we can see an external table:
- Athena_Demo: Linked server name
- AWSDataCatalog: linked server catalog name
- Athenademo.employeedata: external table name
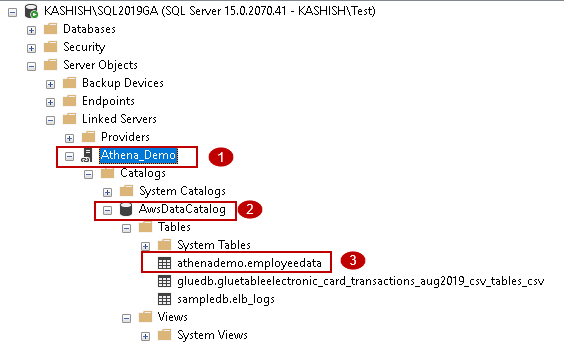
To query an external table using a linked server, we query the table in the following format:
|
1 |
Select * from [1].[2].[3] |
Here [1],[2] and [3] refers to objects as specified in the image above:
We can view the actual execution plan of this query by pressing CTRL+M before executing the query. In the execution plan, we can see a remote query operator. We can hover the mouse over this operator and view the remote query operator property, query:
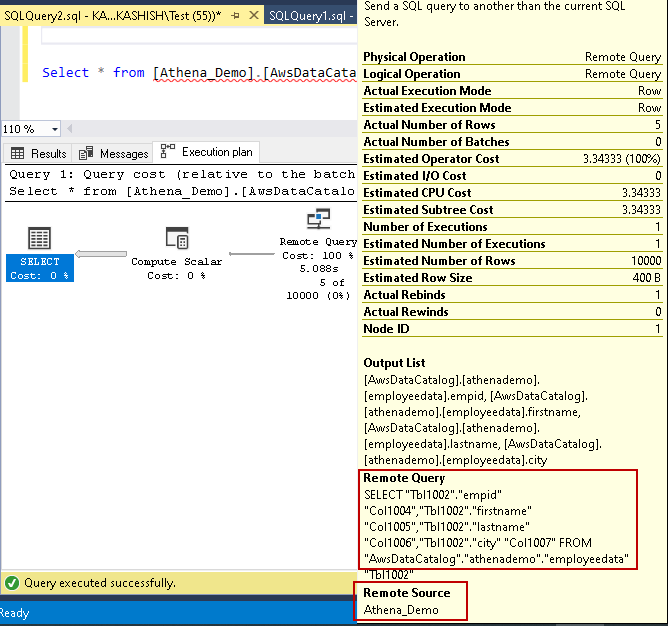
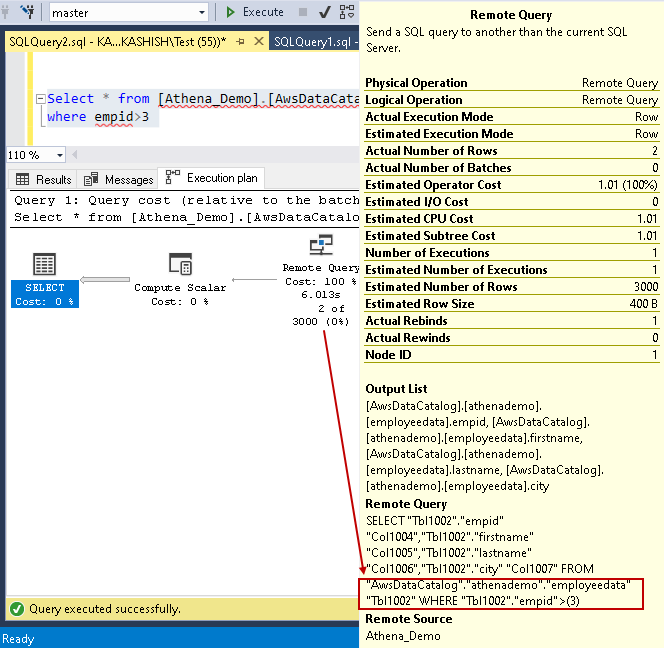
Let’s execute another query for data filtering and view the actual execution plan:
|
1 2 |
Select * from [Athena_Demo].[AwsDataCatalog].[athenademo].[employeedata] where empid>3 |
It filters the records at the Amazon Athena and does not cause SQL Server to filter records. It is an excellent way to offload data aggregation, computation over the data source:
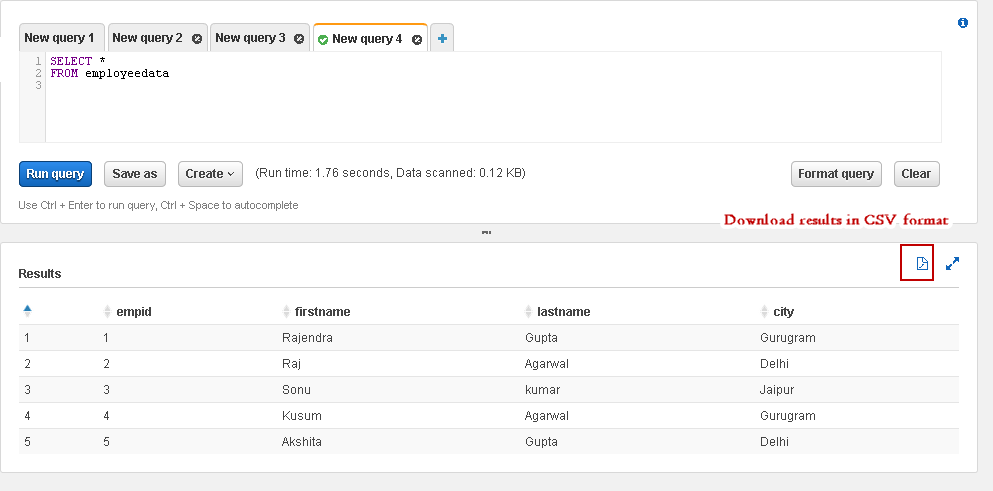
Download Amazon Athena query results
We can download the output of a query in AWS Athena in the following ways.
Query editor console
Once we execute any query, it shows results as shown below. You can click on an icon to download the results in a CSV format:
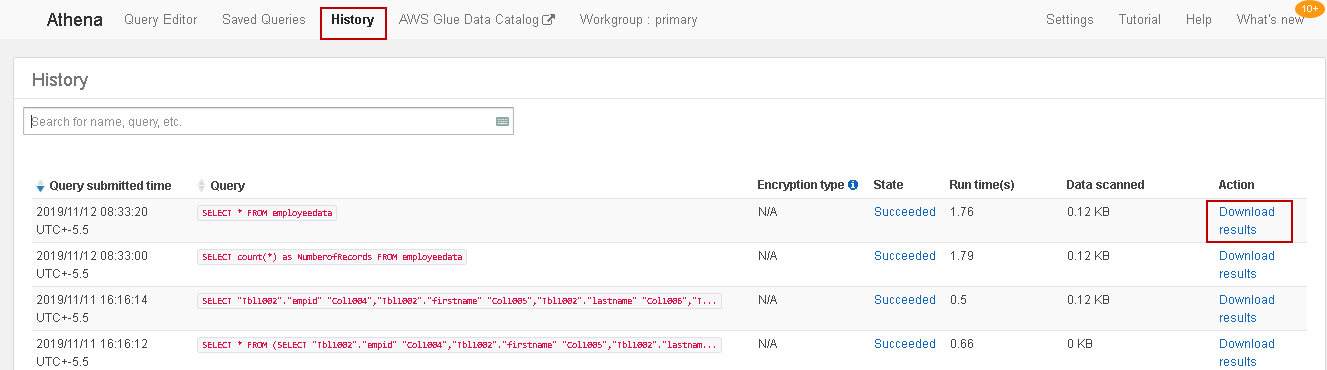
History
We can use the history tab to view query history along with the query, status, run time, data size and download result in CSV format:
Restrictions of Amazon Athena
- We can use it for DML operations only. We cannot use it for data definition language(DDL), Data Control Language(DCL ) queries
- It works with external tables only
- We cannot define a user-defined function, procedures on the external tables
- We cannot use these external tables as a regular database table
Conclusion
In this article, we explored Amazon Athena for querying data stored in the S3 bucket using the SQL statements. We can use it in integration with SQL Server linked server as well. It is a handy feature for data analysis without worrying about the underlying infrastructure and computation requirements.

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023