

This article will walk you through the way to export data out of Azure SQL Databases in a compressed format using Azure Data Factory.
Introduction
Transactional databases host a large volume of data often in relational databases in a normalized format. When this data is required to be analyzed or augmented with other data in different formats or repositories, there may be a need to extract this data and channel it to the desired data repository or processing engine. As it’s not possible to have integration of any given relational database with every possible data processing or data analytics engine, data is often staged or exported to a file store. In the case of Azure SQL Database – which is a transactional and relational database, data may be exported to containers hosted on Azure Data Lake Storage Gen2. While it’s a straight-forward process to export data out of a database and store it in the form of files, the larger the size of data the bigger would be the cost of storing the data. Ideally, the data that is exported can be stored in a compressed data format like parquet or compressed file format like gzip or bzip. In this article, we will learn how to export data out of Azure SQL Databases in a compressed format using Azure Data Factory.
Pre-Requisite
As we are going to be discussing exporting data out of SQL Database on Azure, the first thing we need is an instance of Azure SQL Database with some sample data populated in it. This article will assume that it’s already in place.
Next, we need an instance of Azure Data Factory created, using which we will build a data pipeline that would extract the data from Azure SQL Database and save it in a compressed file or data format. As this data would be stored on the Azure Data Lake Storage Gen2 account, we would need at least one such account with at least one container created on it, where we will store the compressed data. It’s also assumed this setup is in place too. Once the pre-requisite is met, we can proceed with the next steps.
In case, you are not sure about the above set up, check out the below articles that will get you started with these services.
Compressing data with Azure Data Factory
Navigate to the instance of Azure Data Factory and from the dashboard page, click on Author & Monitor link. This would open the Azure Data Factory portal as shown below.

Click on the Copy data option and it would pop-up a new wizard to create a new data pipeline. Provide the basic details in the first step, like task name, description and the execution frequency of the data pipeline.
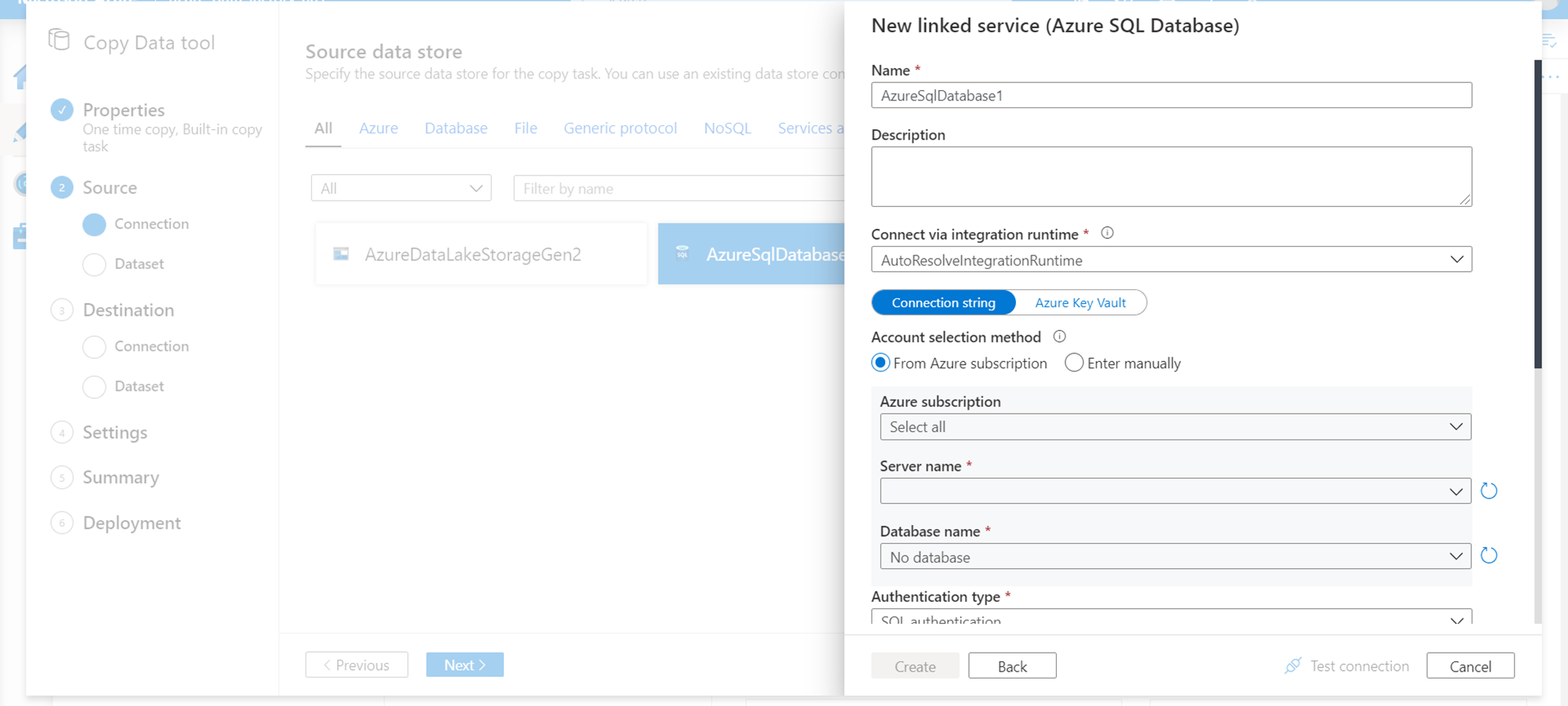
In the next step, we need to select the data source. In our case, the data source is the Azure SQL Database. Click on add new linked service and select the Azure SQL Database option. It would pop-up a detail window as shown below where we need to provide connection details and credentials of the database which hosts the data that we intend to extract and store in a compressed format.
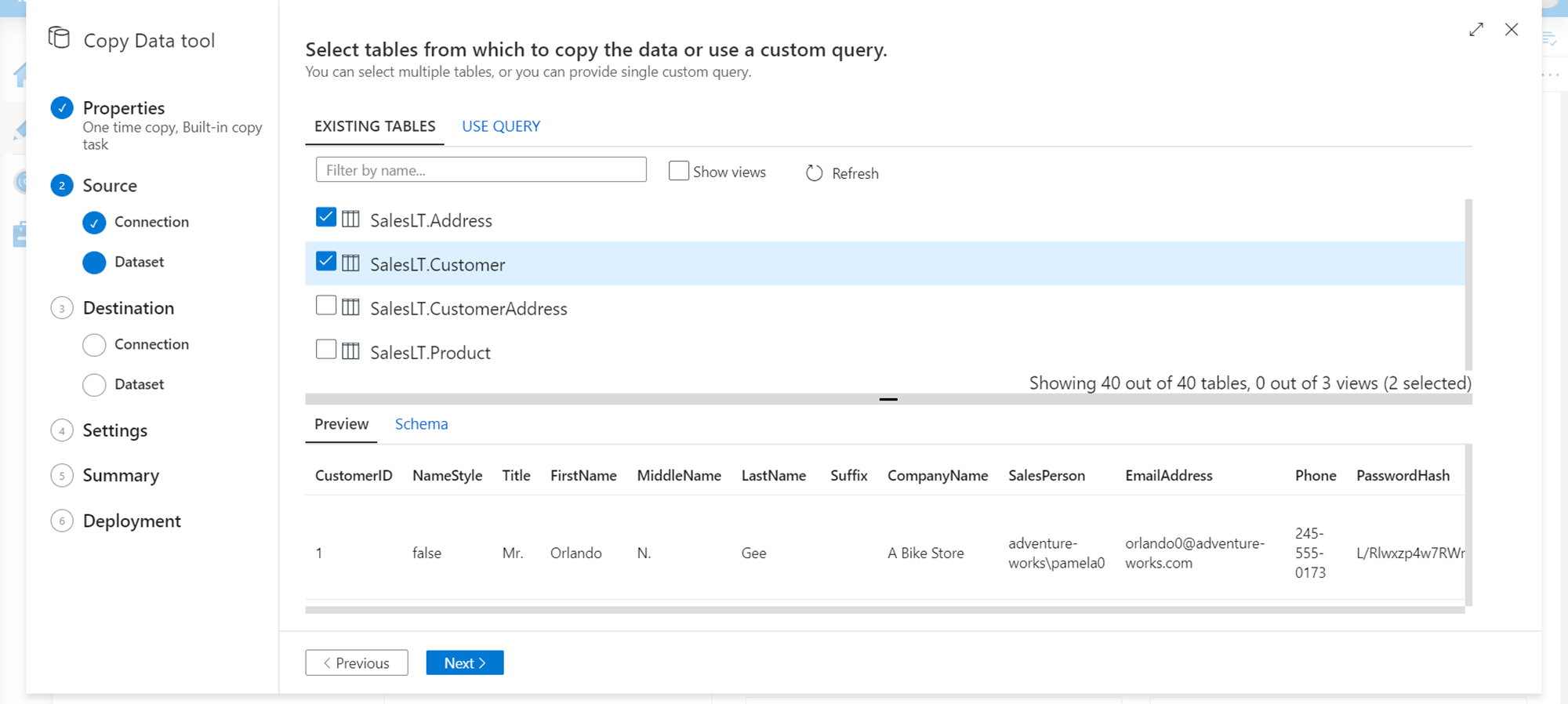
In the next step, we need to select the database objects that form the dataset from the database that we selected in the previous step. This forms the scope of data that would be extracted from the Azure SQL Database.
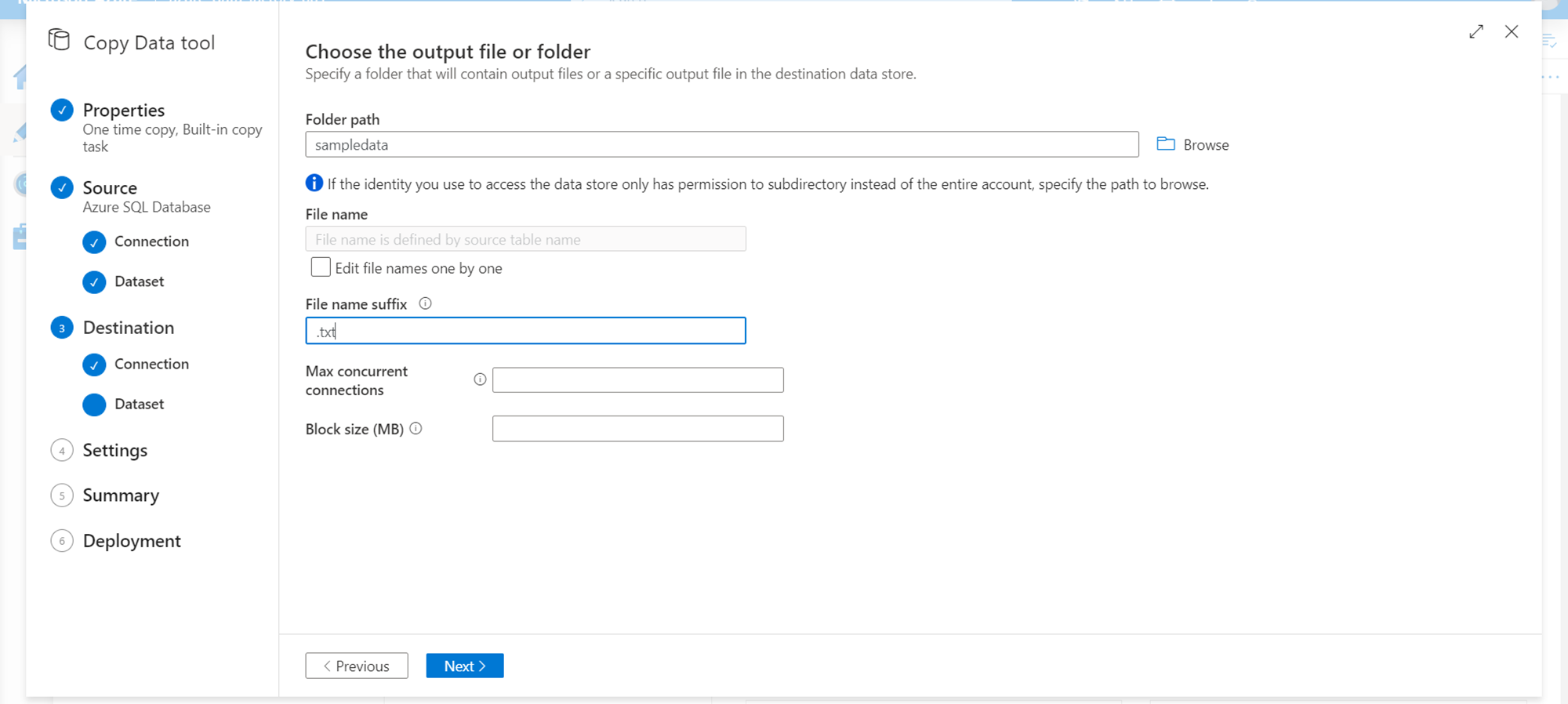
In the next step, we need to define the destination where the extracted data would be stored. As we already have an Azure Data Lake Storage Gen2 account, we would use the same as destination. Click on the Create new connection button and select Azure Data Lake Storage Gen2. It would pop-up the details window as shown below. Provide the path where we intend to store the extracted data. We can also specify the extension of the files that would be created, if we already know the format in which we are going to extract or convert the data before storing it in the destination.
This is the key step where we can specify the compression-related settings. There are two types of compression in consideration – compressed data formats and file compression. Data formats like parquet are columnar data formats that are compressed in nature and take lesser space to store the same amount of data than in other formats. So, if one does not want to zip compress the files, one can store data in compressed file formats. The other method of compression is the well-known method of zipping the files in gzip, tar, bzip, and similar formats which may be supported by Azure Data Factory. In case we intend to compress the file, we can select the compression type as shown below, and this would result in the output file being stored in a compressed format. By default, the compression type is set to None while results in the data stored in uncompressed format.
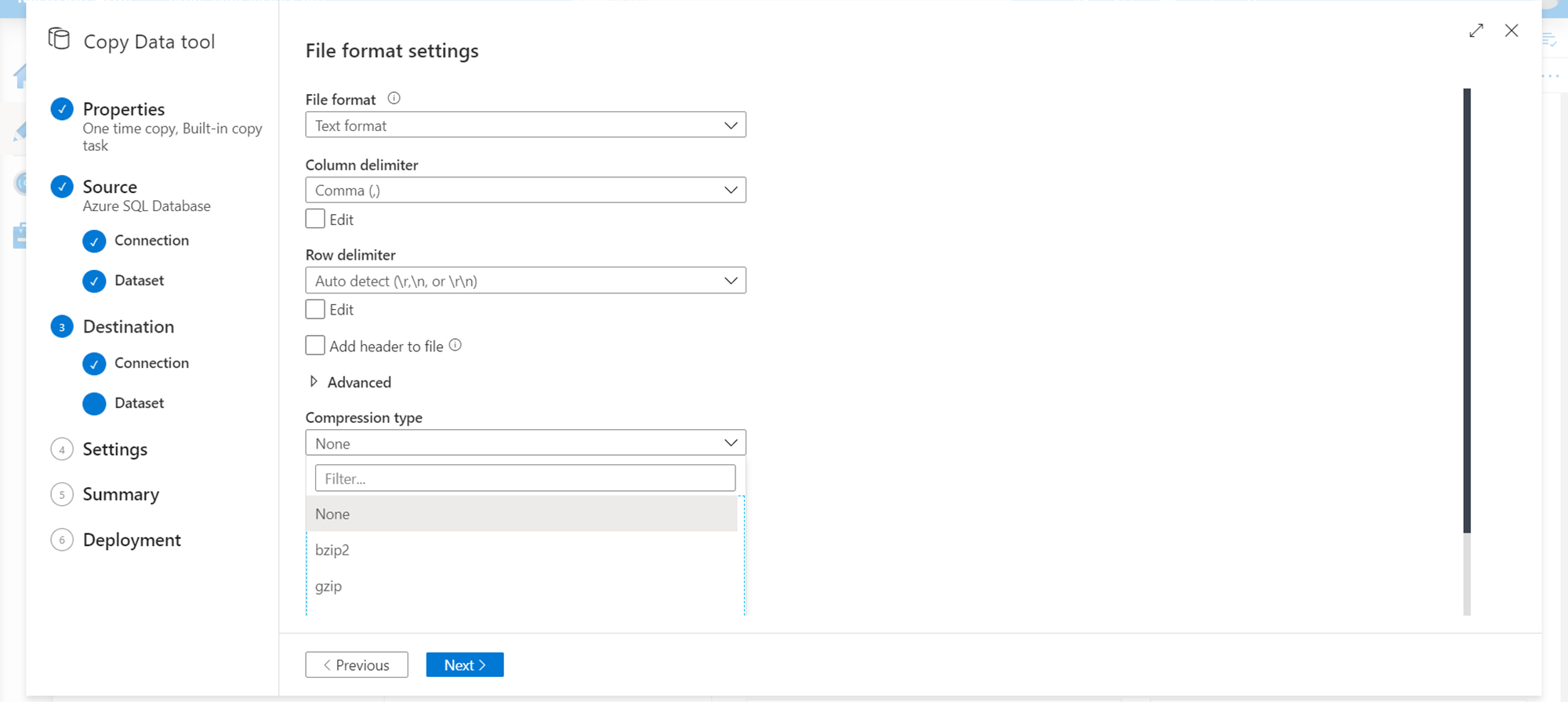
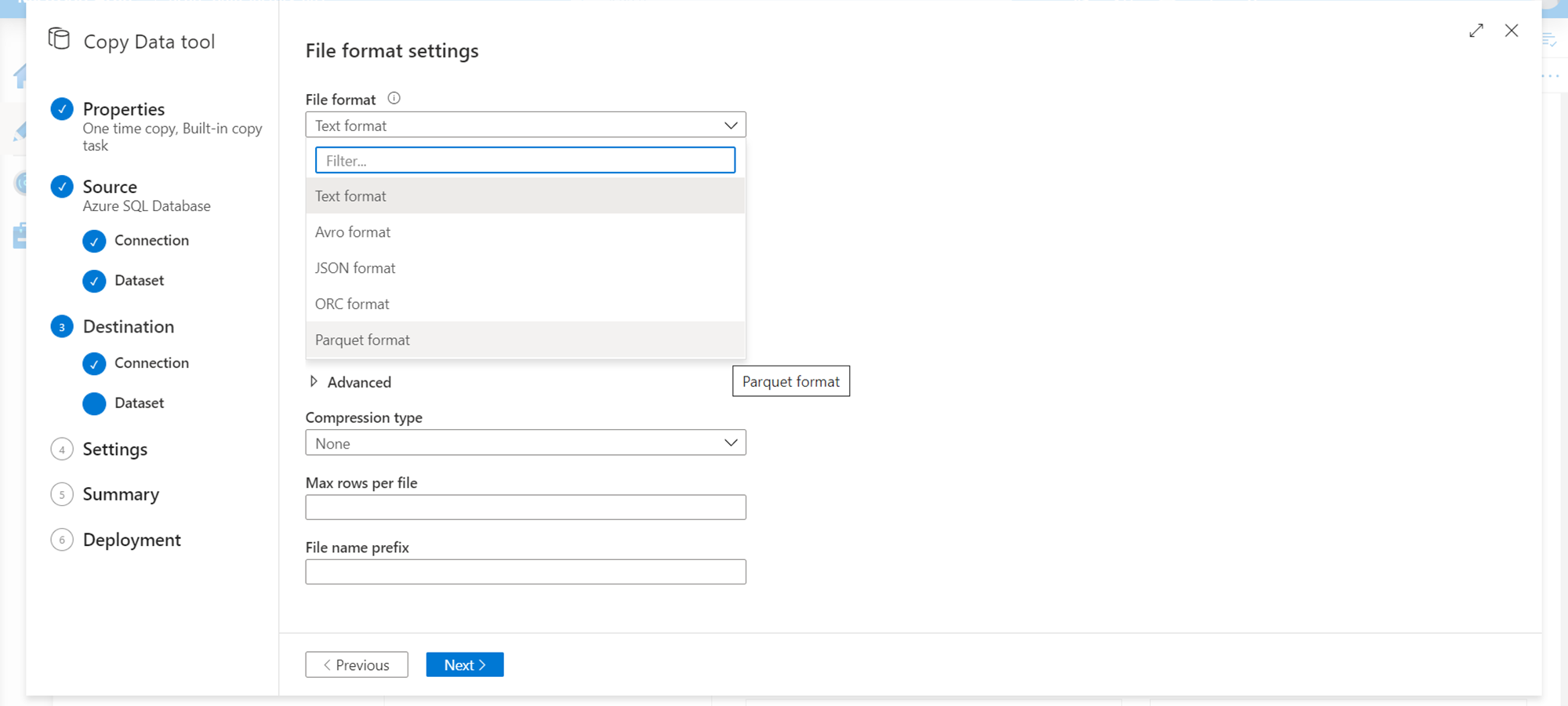
Another method of compression is the data compression method, which can be implemented by selecting a compressed data format like Parquet as shown below. This results in the files being stored in parquet format. If one is selecting this format, in the previous step, ensure that the file extension is of the right format.
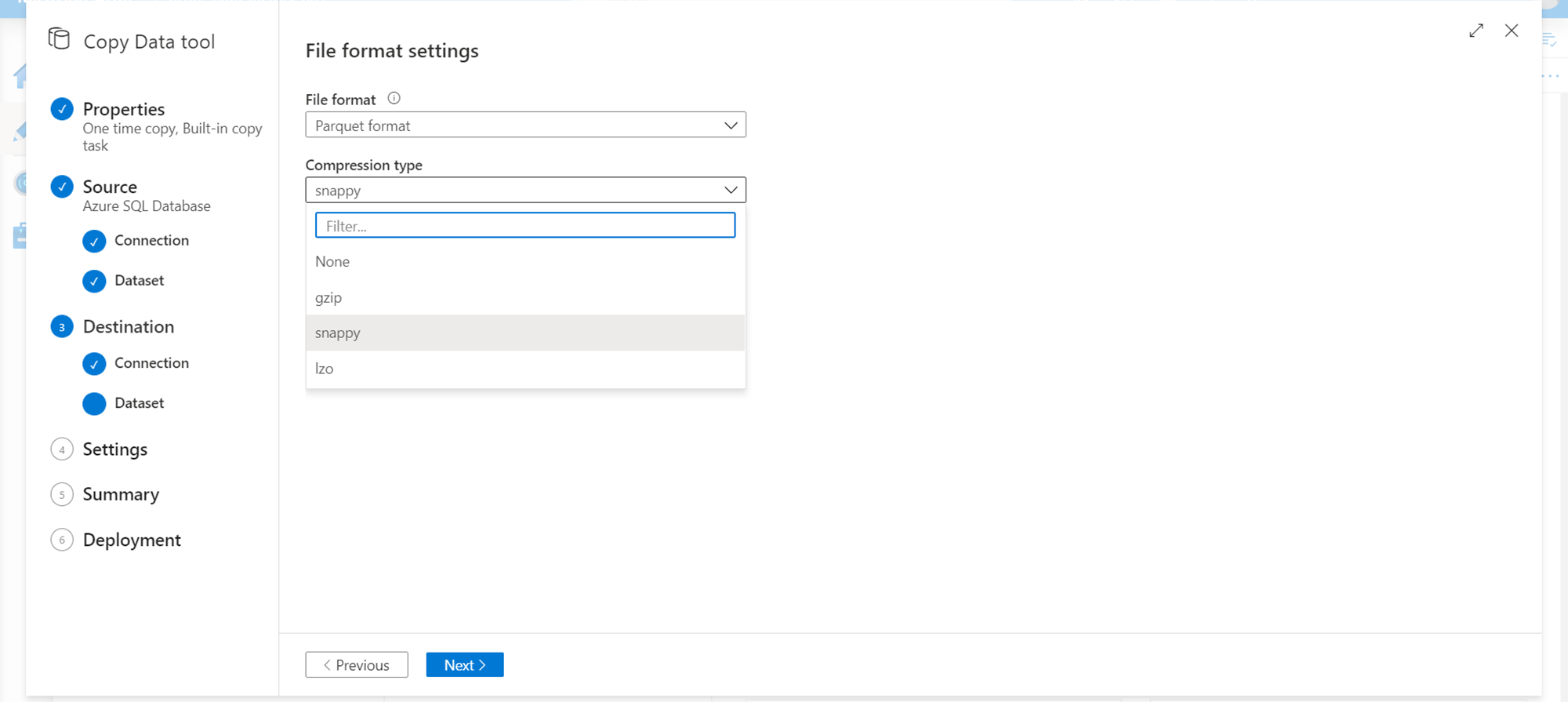
Also, it’s not that we need to select a compressed data format or file compression exclusively. When we select a compressed data format, we get a different type of file compression options like snappy, lzo, etc. as shown below.
After the compression settings are configured, continue with the next steps, configure required settings for the pipeline and execute the pipeline. Once the pipeline gets executed, the output files would be stored on the Azure Data Lake Storage Gen2 account. Shown below is a comparison of how a file size would differ in uncompressed and compressed format. In the scenario of tens of GBs to TBs of data, the compressing format can result in huge cost savings.
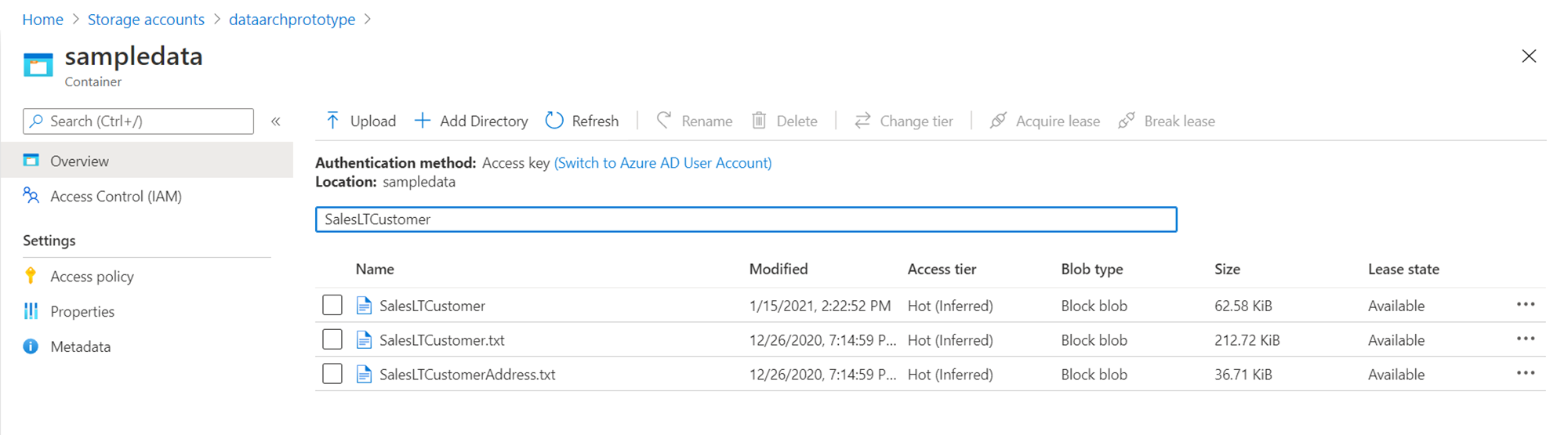
In this way, we can extract data from Azure SQL Database in compressed data or compressed file formats.
Conclusion
In this article, we created an instance of Azure SQL Database which hosts some sample data, and an instance of Azure Data Factory to execute a data pipeline that would compress the data in the pipeline and store it on Azure Data Lake Storage Gen2 account. We learned about various supported files and data formats that support compression, as well as we learned to configure it while developing a data extraction pipeline.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023