
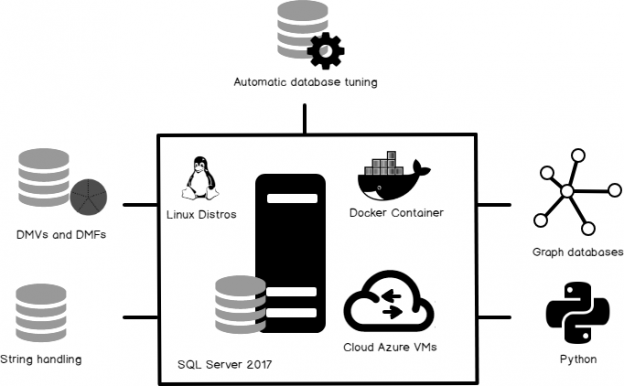
SQL Server 2017 is considered a major release in the history of the SQL Server life cycle for various reasons. From my personal point of view, SQL Server 2017 is indeed an interesting release. After writing lot about it and testing various features of SQL Server 2017, I’d like to walk you through some of its interesting features.
SQL Server 2017 …
- is now on the platform of or choice; SQL Server 2017 on several Linux distros, that can run on Docker containers, and SQL VM in Azure, along with the good ol’ SQL Server on Windows.
- expands its reach to support Graph database technology
- includes automatic database tuning
- supports Machine Learning by adopting Python
- contains new dynamic management views and functions
- has new string functions
- And more…
Time to dig in
Let’s uncover the mystery behind the faster development and deployment of SQL Server. The file size of the SQL Server executable, sqlservr.exe, is ~3 MB in SQL Server 2017, compared to ~64 MB in SQL Server 2008 R2. The SQL Server team realized the importance of decoupling and modularizing the surface area code into much smaller components. The entire architecture is broken down into multiple smaller micro-services so that the deployments and integration are made on each of the respective components, and that the process is seamless.
Starting with SQL Server 2017, Microsoft is no longer using the old model of release under which cumulative updates (CUs) were released every two months and service packs (SPs) containing all the fixes from the preceding CUs were released once a year. This new model allowed shortening the release cycle and features getting added to SQL Database and SQL Server faster than ever before. Most recently, the SQL Server engineering team managed to ship SQL Server 2017 along with the new cross-platform support within 15 months after the release of SQL Server 2016. This is in contrast with the legacy three-to-five-year shipping cycles of the past.
One would feel why SQL Server2016 and 2017 are such big releases in a matter of a difference of just a few months. However, starting with 2017, Microsoft is moving to a rapid-release cadence with enhanced functionality and new features being rolled out annually instead of having to wait two or three years between versions.
SQL Server 2017 on Linux
Clearly, two of the biggest changes with SQL Server 2017 are its support for Linux and Docker containers, both of which could have a big impact on the database trends of the future. The release of SQL Server 2017 for Linux has proven to be a step towards extending the capabilities to a high-performance platform, which has already set some TPC benchmark records.
In this release, we can look forward to running SQL Server instances on Linux computers. Many of our previous articles show you how to get started by creating a RedHat virtual machine in Microsoft Azure, as well as installing SQL Server on a CentOS machine. Here are some of the articles.
- Installation of SQL Server vNext CTP on Linux Distribution CentOS 7 is discussed in this article: Installation of SQL Server vNext CTP on Linux Distribution CentOS 7
- A Quick start Guide to Managing SQL Server 2017 on CentOS/RHEL Using the SSH Protocol is discussed in this article
- How to configure SQL Server 2017 on Linux with mssql-conf and other available tools is discussed in this article
Python support in ML (Machine Learning)
The next great feature that’s new in SQL Server 2017 is the addition of support for the Python scripting language, which is in addition to R, support for which was added in 2016, to form a new machine-learning services package. There’s no doubt that AI is now among the hottest buzzwords in IT. It seems like almost every IT product is now suddenly AI-enabled, and SQL Server is no exception in that regard. In April 2017, SQL Server was officially touted as “The first RDBMS with built-in AI!” Some of my articles that talk about these capabilities are:
- Kick start Python in SQL Server is discussed in this SQL Shack article: How to use Python in SQL Server 2017 to obtain advanced data analytics
- Read about the basic data interpolation techniques here: Data Interpolation and Transformation using Python in SQL Server 2017
- The benefits and importance it brings to DBAs are discussed in The importance of Python in SQL Server Administration
- Python and Powershell is two sides of the coin, according to this article: Why would a SQL Server DBA be interested in Python?
Graph Databases
This section explores the integration of Graph database components in SQL Server 2017. The pointer at the end of this section includes a working data set of relational and graph databases, and data models. In addition, it explains how to integrate graph databases with relational databases and how to convert the relational tuples into a graph data set.
A key concept of graph databases are edges and nodes. The relationships allow entities to be linked together directly, and in many cases retrieved with one operation. In some cases, due to stringent data modeling design, the relational data model may not be a good fit as it incurs costly join operations. In the past, the lack of viable alternatives and the lack of support made the graph model a difficult alternative, but that is no more the case.
We’ll also look at the integration of graph database support to help model many-to-many relationships as nodes and edges, rather than with the traditional relational model. The footprint of the graph database technology in the IT industry is clearly visible today, and for good reasons such as adding efficiency to social recommendations, IT network analysis, fraud detection, product recommendation, and so on.
Go ahead, look at a use case we picked to demonstrate the features of Graph databases in this article: An introduction to a SQL Server 2017 graph database
String functions
One of the major capabilities of modern computers is processing the human language. Basically, the strings are transformed into the code which is then processed by a machine. The built-in string functions have always been efficient in handling string literals. It is possible to find and alter string values using various options. However, string functions and string manipulation consume most of the query execution time in decoding the various parts of the character literals. SQL Server 2017 offers various new string manipulation functions, which have been in the talk for many of its features that simplify a developer’s life; no more writing long T-SQL statements with temporary tables and complex logic, only to manipulate and aggregate strings.
Here are some of the new string manipulation functions present in SQL Server 2017:
Read more about this in the article: Top string functions in SQL Server 2017
DMVs and DMFs
With the advent of system objects, the metadata of various pieces of SQL Server have been exposed for a better understanding of the entire system. These system objects, for the most part, are a cumulative collection of data, or the aggregation or accumulation of the various counter values or different data-structures of SQL Server. Most importantly, the data is real time, and obviously dynamic in nature. In most of the cases, the DMVs are used, and they define the baseline or pressure points of various metrics that determine the performance of the system. The DMFs provide cumulative statistics of the requested parameters.
The new DMVs introduced in SQL Server 2017 are as follows:
- sys.dm_tran_version_store_space_usage
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_exec_query_statistics_xml
- sys.dm_os_host_info
- sys.dm_os_sys_info
- A new column modified_extent_page_count introduced in sys.dm_db_file_space_usage to track differential changes in each database file of the database.
- Identify the free disk space using the new DMV sys.dm_os_enumerate_fixed_drives
|
1 |
SELECT * FROM sys.dm_os_enumerate_fixed_drives; |
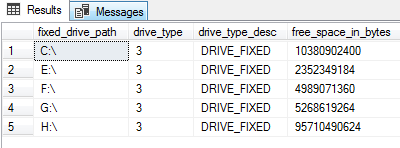
The new DMFs introduced in SQL Server 2017 are as follows
Read the Top 8 new (or enhanced) SQL Server 2017 DMVs and DMFs for DBAs to find out more.
Resumable Online Index Rebuild
SQL Server 2017 is the first commercial RDBMS to support pause and resume functionality for index maintenance operations. Most administrators consider index rebuild on VLDB’s a daunting task to manage. Many critical database solutions don’t permit to perform offline database maintenance operations. In most cases, the database design plays an important role in that regard. SQL Server 2017 provides index maintenance tasks with great flexibility as an alternative solution to managing the maintenance operations. There are situations where database administrators might need to temporarily free up system resources. For example, what if a priority task needs resources and a lower-priority index rebuild is eating away the resources? We’d rather have the index rebuild operation run in some other available maintenance window—but at the same time, what if the rebuild was halfway? We do not want to lose that state either. In such a case, the operation can be paused, and resumed during a maintenance window. This can be a termed as “piecemeal index maintenance operation.”
- Resume: Resume an index-rebuild operation, after a failure.
- Pause: Pause the rebuild operation (and resume it at a later point).
- Rebuild: Rebuild large indexes with minimal log space usage.
Let’s look at Overview of Resumable Indexes in SQL Server 2017, an article that covers resumable online index operations in detail
Automatic database tuning
Monitoring the databases for optimal query performance, creating and maintaining required indexes, and dropping rarely-used, unused, or expensive indexes is a common database administration task. SQL Server 2017 can now assist database administrators in performing these routine operations by identifying problematic query execution plans and fixing SQL plan performance problems. Automatic tuning begins with continuously monitoring the database, and learning about the workload that it serves. Automatic database tuning is based on Artificial Intelligence; AI is now providing great flexibility in managing and tuning the performance of database systems. More on this topic is discussed in a dedicated post on automatic database tuning: Understanding automatic tuning in SQL Server 2017
Wrapping up
I feel that SQL Server on Linux, Python Integration, Graph Databases and Resumable index operations stand out to be the top features of SQL Server 2017. The list of many features and enhancement does not stop here. I will discuss the other pieces we omitted, in a separate article. What are your top features in SQL Server 2017? Feel free to comment here!

My specialty lies in designing & implementing High availability solutions and cross-platform DB Migration. The technologies currently working on are SQL Server, PowerShell, Oracle and MongoDB.
View all posts by Prashanth Jayaram
- Stairway to SQL essentials - April 7, 2021
- A quick overview of database audit in SQL - January 28, 2021
- How to set up Azure Data Sync between Azure SQL databases and on-premises SQL Server - January 20, 2021