Abstract
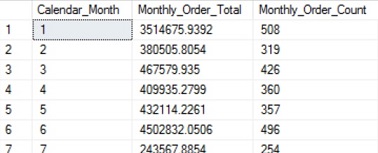
This article explains lock issues in SQL Server with DDL statements including SELECT INTO clause.
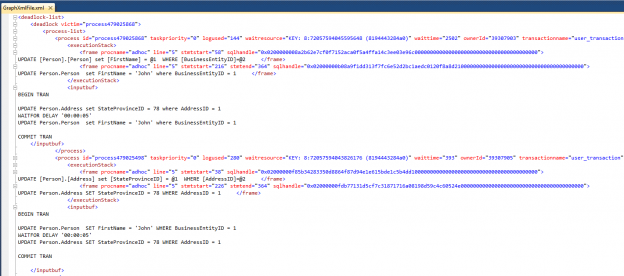
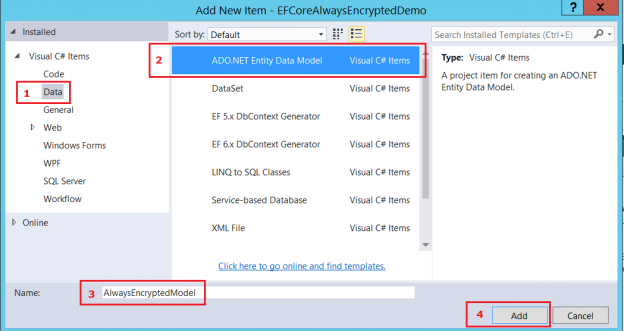
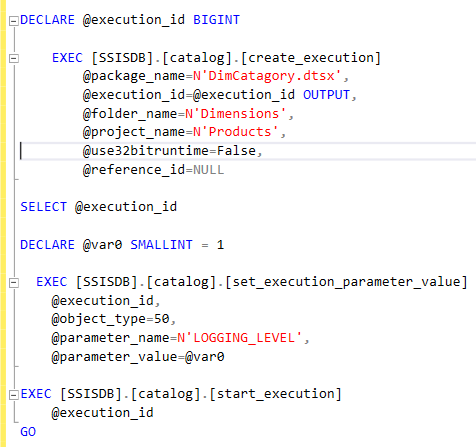
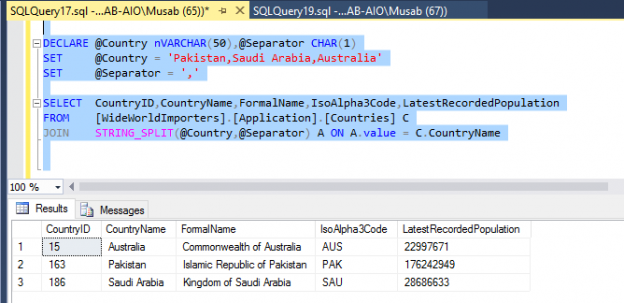
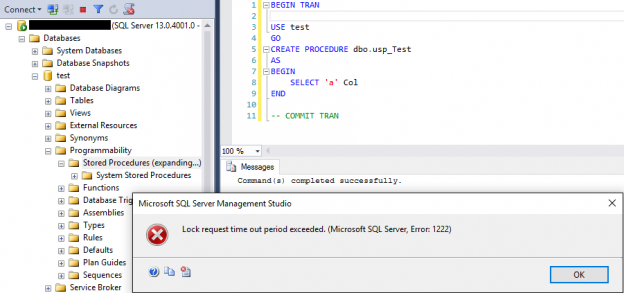
Use of explicit transaction is common in SQL Server development. Sometimes a developer might inadvertently specify a Data Definition Language clause within a long running explicit transaction, similar to the structure below, within a SQL Server object such as a stored procedure.
Read more »