Introduction
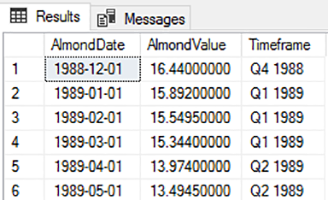
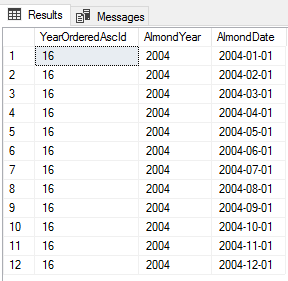
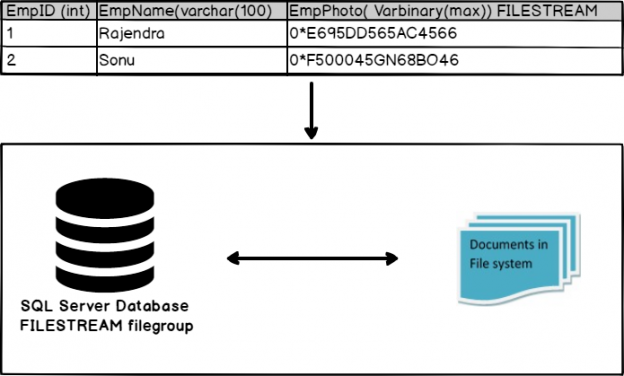
CSV (comma separated values) is one of the most popular formats for datasets used in machine learning and data science. MS Excel can be used for basic manipulation of data in CSV format. We often need to execute complex SQL queries on CSV files, which is not possible with MS Excel. See this article for what is possible with Power BI.
However, before we can execute complex SQL queries on CSV files, we need to convert CSV files to data tables.
Read more »