

The SQL Server FILESTREAM feature in SQL Server allows storing the large documents files directly into the file systems. In my previous articles, we explored the concepts of FILESTREAM feature in SQL Server. We also learned the folder structures, metadata information and the process of garbage collection. In this article, we are going to learn about the backup and restores in SQL Server.
Before we move further below are the pre-requisites for this article.
- Enable the FILESTREAM feature at the instance level (either during the SQL Server installation or by the SQL Server Configuration Manager)
- Configure for the FILESTREAM access level
We have the following FILESTREAM database and the content inside it.
|
1 2 3 4 |
SELECT [FileId] ,[FileName] ,[File] FROM [FileStreamDB].[dbo].[DemoFileStreamTable_1] |

You can find below file in the FILESTREAM container.

In the FILESTREAM database, We need to specify below things you do differently from a standard database in SQL Server.
- Specify a FILESTREAM filegroup
- Create a FILESTREAM data file into that filegroup
Backup and restore is a critical task for database administrators. The primary objective is to restore the database in case of any failure, data deletion. The same concepts apply to FILESTREAM enabled databases as well. If someone deleted the files accidentally from the file share, you should be able to recover that.
In SQL Server, when we execute a full backup on the SQL Server FILESTREAM database, it takes the backup of following items:
- Backup of the data files (.MDF,.NDF) of the database
- Transaction log backup
- FILESTREAM file group backup along with the associated files
SQL Server database backup includes the FILESTREAM filegroup and the files inside it. Let us first execute the full backup of the database.
- Right click on the database ->Tasks ->Back Up.
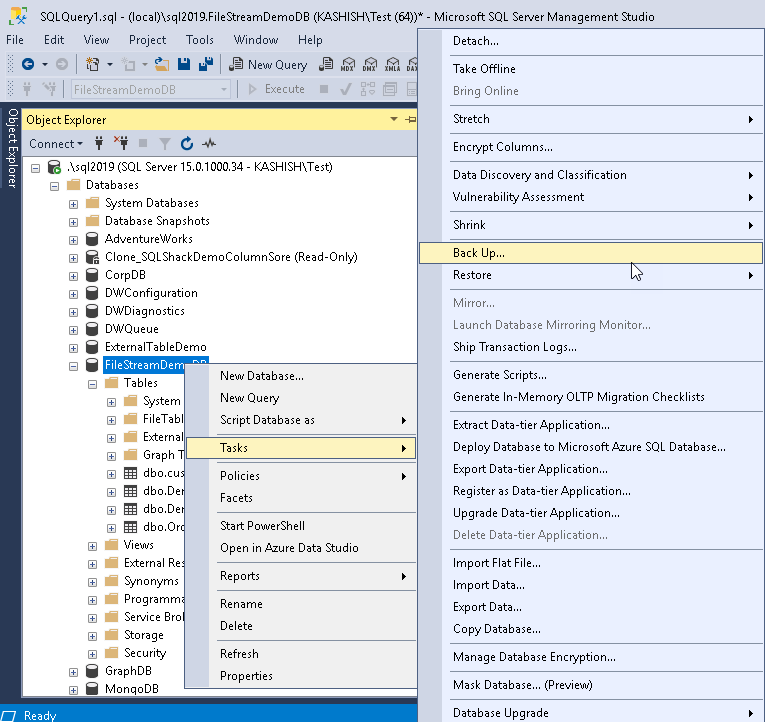
- In the backup database wizard, specify the backup type ‘Full’ and the backup location. This backup location should have sufficient free space

- Click on ‘OK’ to execute the database backup. We can also generate the script using the ‘Script Actions to new query window’. Let us generate the script.
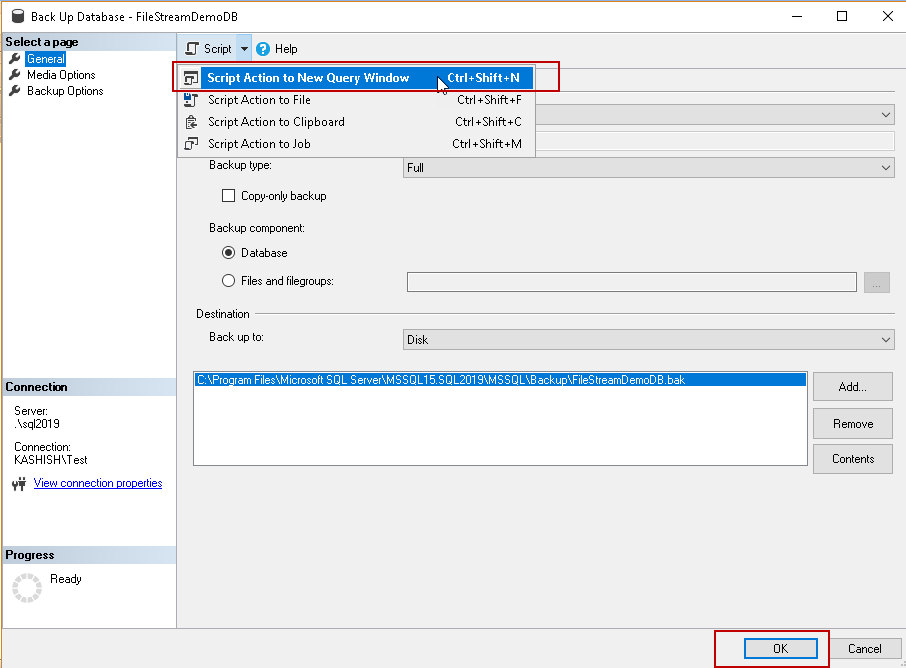
We get the below script to take a full backup. Backup of SQL Server FILESTREAM enabled database is similar to a standard database backup.
|
1 2 3 4 |
BACKUP DATABASE [FileStreamDB] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQL2019\MSSQL\Backup\FileStreamDB.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStreamDB-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 Go |
Let us execute this command and observe the output.
14 percent processed.
Processed 432 pages for database ‘FileStreamDB’, file ‘FileStreamDB’ on file 9.
20 percent processed.
30 percent processed.
….
81 percent processed.
91 percent processed.
Processed 2041 pages for database ‘FileStreamDB’, file ‘DemoFiles’ on file 9.
Processed 2 pages for database ‘FileStreamDB’, file ‘FileStreamDB_log’ on file 9.
100 percent processed.
BACKUP DATABASE successfully processed 2475 pages in 1.578 seconds (12.249 MB/sec).
Now let us compare the backup statement output with the database files (Right click on database and click properties and then go to files)
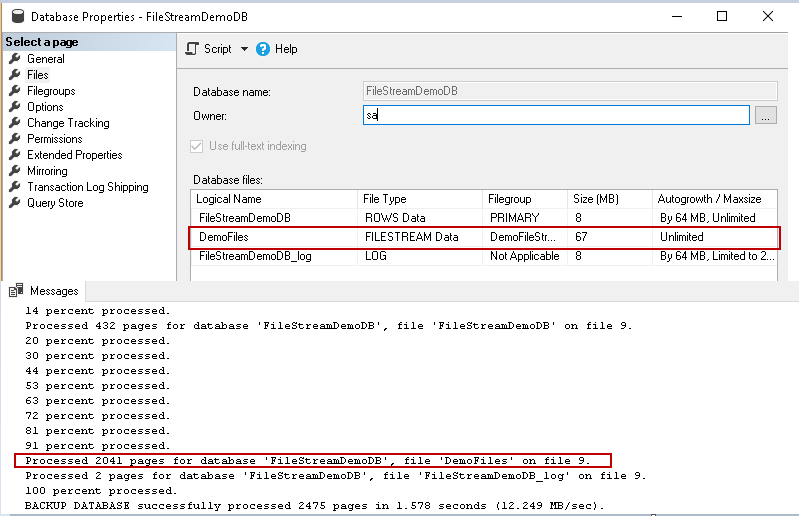
In the above image, you can notice that it took backup of the file ‘Demofiles’, which is a ‘FILESTREAM data’ file.
IF the files contained in the FILESTREAM filesystem is open in another program, you get the below error message in the backup operation.
Msg 3056, Level 16, State 1, Line 1
The backup operation has detected an unexpected file in a FILESTREAM container.
The backup operation will continue
and include file ‘C:\sqlshack\FileStream\DemoFiles\97f720ed-afbf-413d-8f5c-5b56d4736984\8f62d1b7-7f8b-4f98-abe9-a06b4faa1d2e\00000024-00000588-000c\
C:\sqlshack\FileStream\DemoFiles\97f720ed-afbf-413d-8f5c-5b56d4736984\8f62d1b7-7f8b-4f98-abe9-a06b4faa1d2e\~$000024-00000588-000c’.
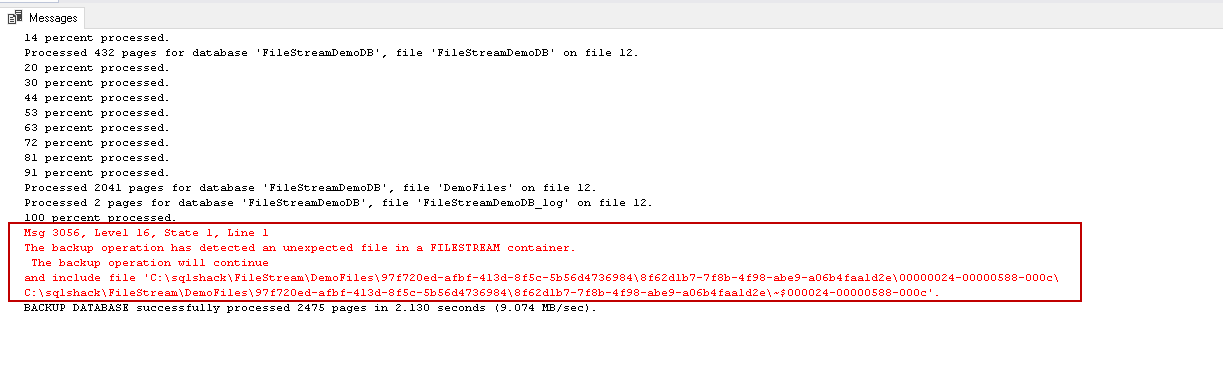
This error message shows that there is another file detected in the SQL Server FILESTREAM container. However, the backup operation will continue to run. In error, you can notice the unexpected file name (‘\~$000024-00000588-000c’). When we open any file in windows, it opens a hidden file into the same folder. By default, the hidden file is not visible in the folder. Open the FILESTREAM container folder and in the menu bar, click on the ‘Hidden items’. This option will allow viewing the hidden file in the folder.

Now, notice in the FILESTREAM container, you can notice the hidden file ‘\~$000024-00000588-000c’ in this folder. SQL Server backup does not recognise this file there it says that there is an unexpected file in the FILESTREAM container. SQL Server backup will also include this file during the backup activity.

We will look more in details about the SQL Server FILESTREAM database backup using the extended event ‘backup_restore_progress_trace’. You can use this extended event from SQL Server 2016.
You need to create the external event session from the extended event sessions. In the Management folder, Expand ‘Extended Extents’ and right click on the ‘Sessions’.
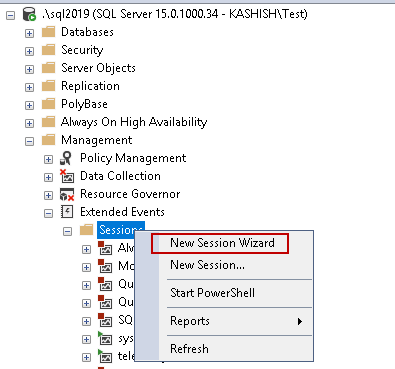
Enter a name for the extended event session.
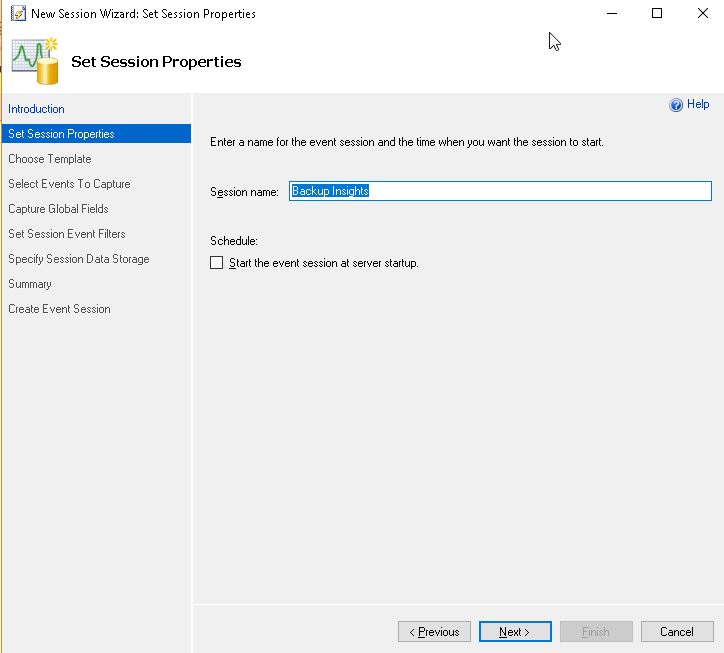
Search the extended event ‘backup_restore_progress_trace’ from the event library and take it towards the right window and click ‘Next’.

Now move to the ‘Specify Session Data Storage’ page. We can save it the event file for later use or work with the ring buffer to get the recent data. We will choose the option ‘work with only the most recent data (ring_buffer-data).
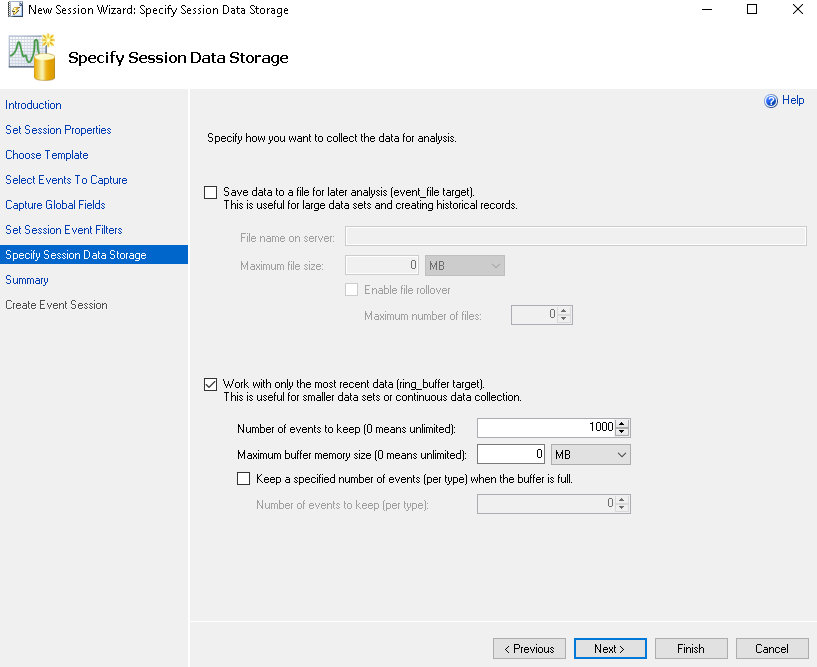
Select the below options as shown in the screenshot.
- Start the session immediately after the extended event session.
- Watch live data on screen once it is captured
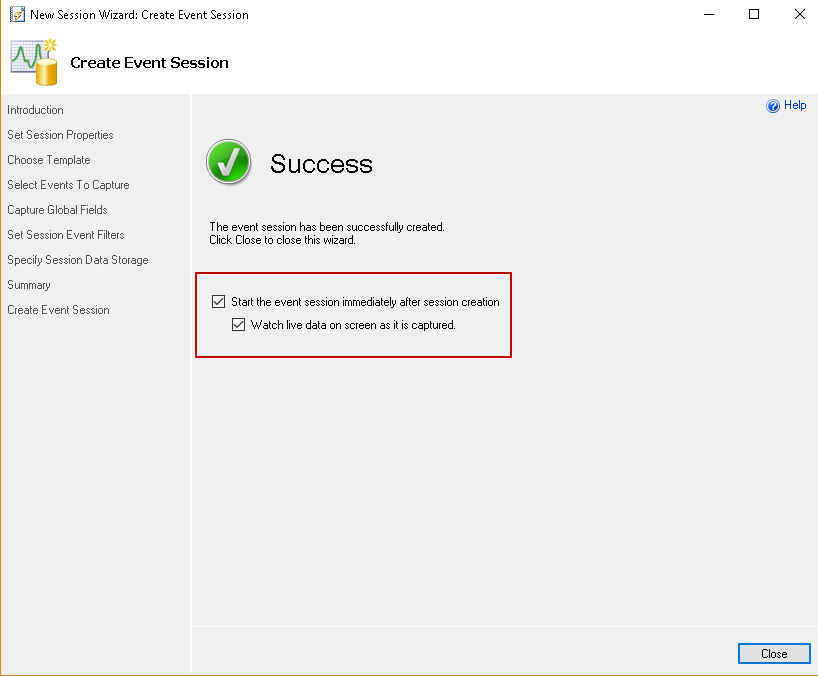
Execute the backup for the FILESTREAM database again and observe the output in the extended event session.
You can notice that below operations with the backups.
- Once we execute the database backup, it takes the S lock and bulk-op lock on the database. Since it is a full backup, it clears the differential bitmaps.
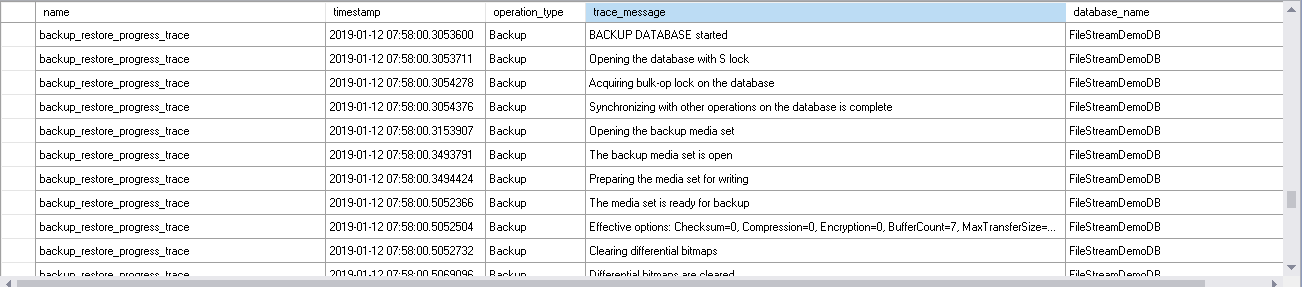
- It issues CHECKPOINT on the database and scans allocation bitmap. It also shows the first and last LSN of the database for the backup.
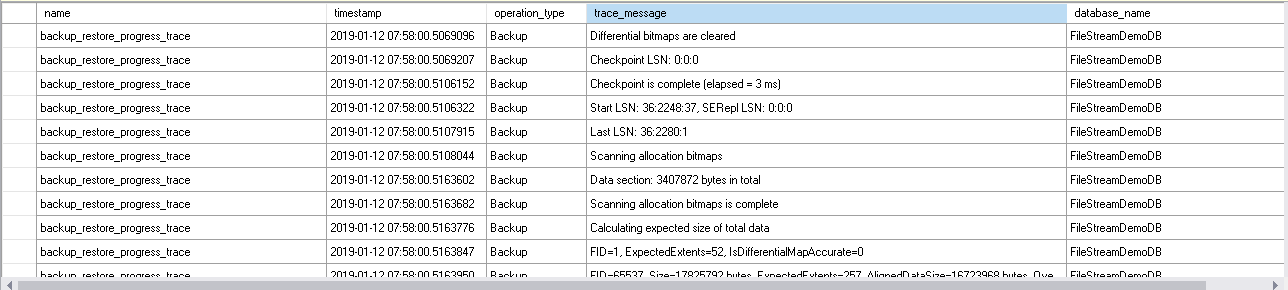
- Before copying the data for the backup, it forcefully applies the first CHECKPOINT and starts scanning the bitmap.
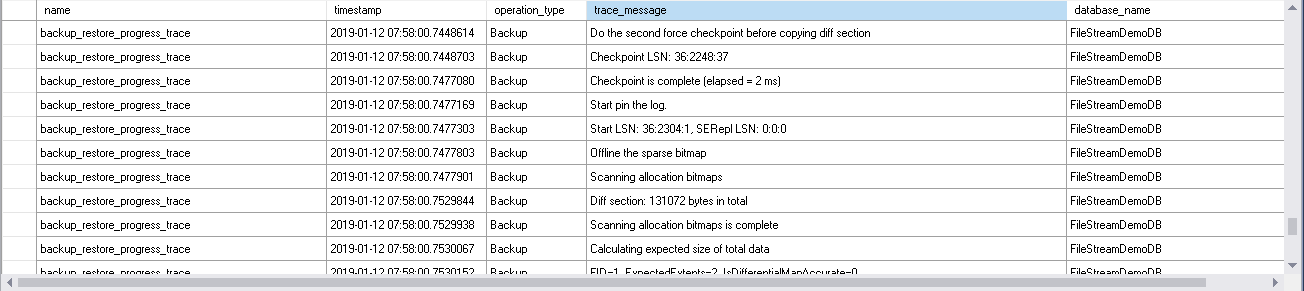
- It writes the backup metadata after a couple of force checkpoints.
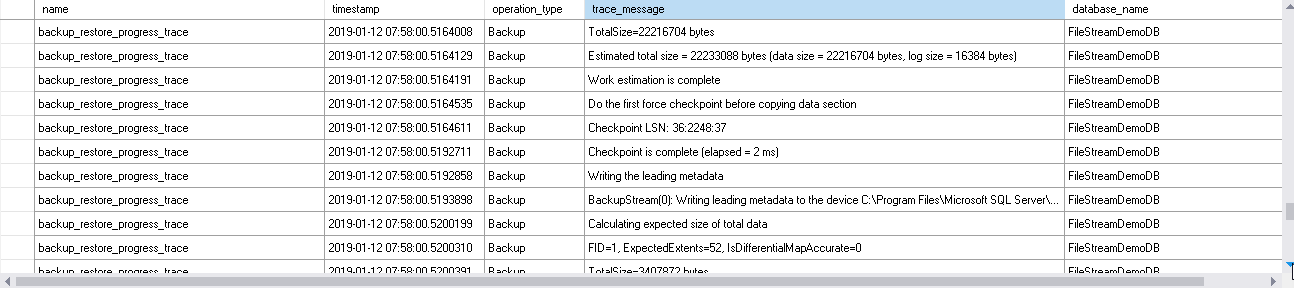
Below you can see it reads the.MDF file for the FILESTREAM database.

Now it copies the data into the backup file. You can see in below screenshot that it copies the data file followed by the FILESTREAM data.

In the end, it copies the transaction log, and backup database successful message is displayed.

In the extended event session, you can file for the FILESTREAM it performs the below steps for the backup.
- Data files
- Log Files
- SQL Server FILESTREAM backup.
SQL Server FILESTREAM filegroup backup in SQL Server
In SQL Server we can take FILEGROUP level backups as well. As you know that to use the FILESTREAM feature, we need to create a particular filegroup. Therefore, if we do not want to take a full backup, we can take FILESTREAM filegroup backup as well. It contains the FILESTREAM filegroup files.
In the backup database window, click on ‘Files and FileGroup’. It opens another window and allows selecting the filegroup for which we want to take the backup. In the following image, you can see we have selected the FILESTREAM filegroup.
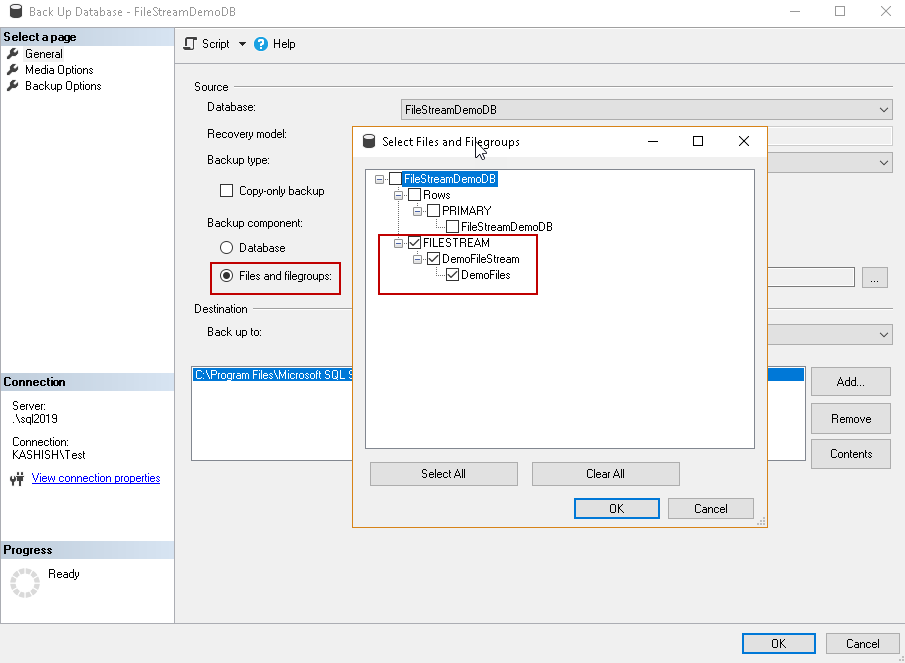
Click ‘Ok’ and generate the script for filegroup backup.
|
1 2 3 4 5 |
BACKUP DATABASE [FileStreamDB] FILEGROUP = N'DemoFileStream' TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQL2019\MSSQL\Backup\FileStreamDB.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStreamDB-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO |
It gives the below output message for the filegroup level FILESTREAM database backup.
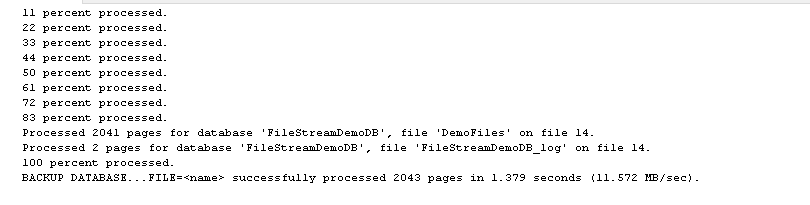
Conclusion:
In this article, we explored the various aspects of backup SQL Server FILESTREAM database including full and filegroup backups. We also learned about the internals of FILESTREAM database backup using the sessions of the extended event. We will cover the FILESTREAM database restore in my next article.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023