
In the article FILESTREAM in SQL Server, we provided a SQL Server FILESTREAM overview with a focus on internal functionality. In this article, we will cover various additional aspects of the FILESTREAM feature.
Before we move further, let us check the data in the FILESTREAM table and the files in the file system container.

Below are the files in the container. We have two files present in the file system container. It also matches the metadata present in the table.
In the article, Managing data with SQL Server FILESTREAM tables, we wrote about how to update FILESTREAM objects.
Let us perform two updates for the existing records. In the first update, we are going to replace the file with 5 KB image file.
UPDATE DemoFileStreamTable_1 SET [File] = (SELECT * FROM OPENROWSET( BULK 'C:\sqlshack\logo.png', SINGLE_BLOB) AS Document) WHERE fileid = '8D114AD3-12AA-4064-A1D8-3E8749712D5D' Update DemoFileStreamTable_1 set filename='Logo files' WHERE fileid = '8D114AD3-12AA-4064-A1D8-3E8749712D5D' GO
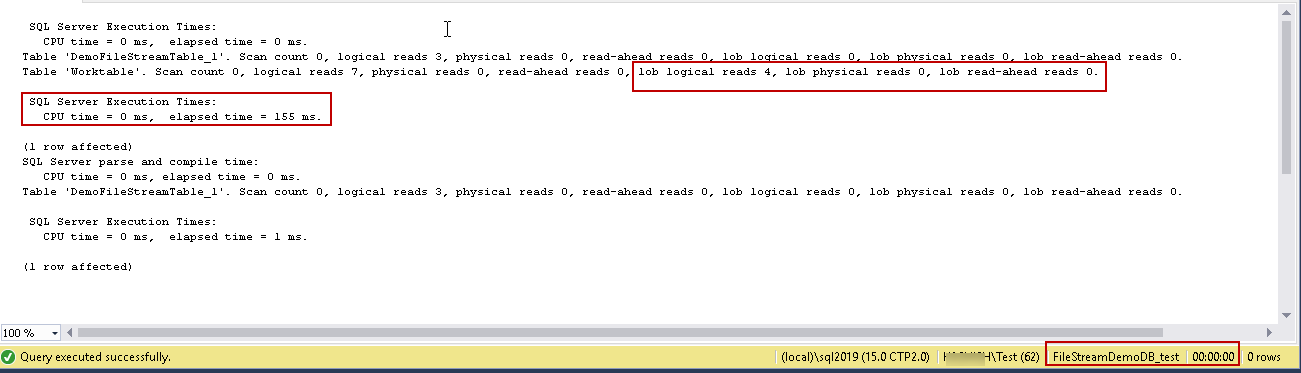
It took 155 ms elapsed time and 4 lob logical reads to complete the update.
Now in another update, we are going to replace the existing file with an ISO file of 1.53 GB size.
SET STATISTICS TIME ON SET STATISTICS IO ON UPDATE DemoFileStreamTable_1 SET [File] = (SELECT * FROM OPENROWSET( BULK 'C:\sqlshack\ubuntu-16.04.5-desktop-amd64.iso', SINGLE_BLOB) AS Document) WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8' Update DemoFileStreamTable_1 set filename='Installation files' WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8' GO
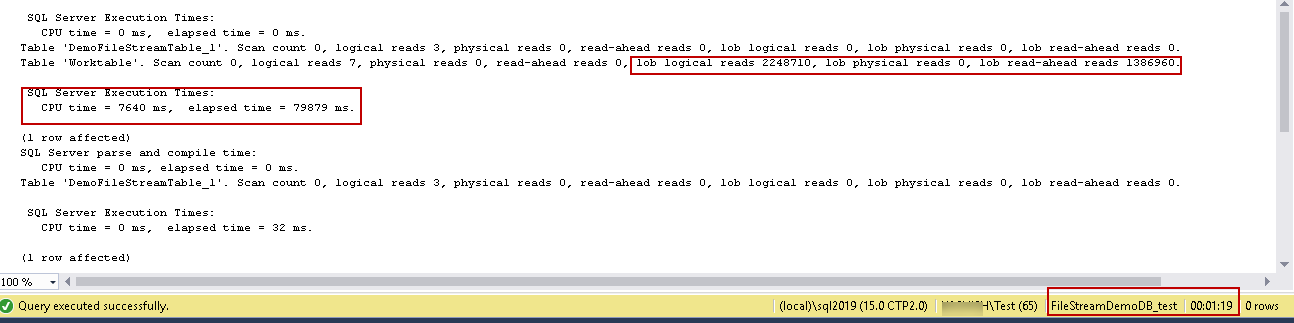
This time update took 1 minute 19 seconds to complete along with 2248710 lob logical reads and 1,386,960 lob read-ahead reads.
When we perform an update for the files in the SQL Server FILESTREAM, it copies the entire file from the source location to the file stream container. In the second update, we replaced the previous file with 1.5 GB ISO file, therefore; it took time and system resources to copy the file in the FILESTREAM container.
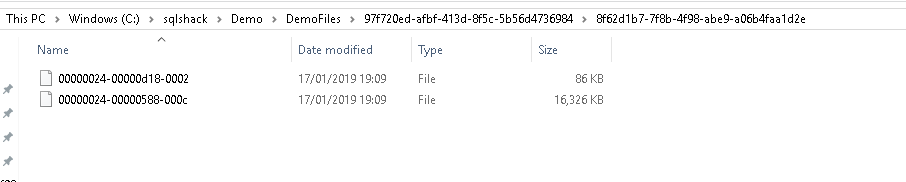
Now go to the FILESTREAM container and view the files there. We can see four files here. We did not insert any new files here however, it contains multiple files.
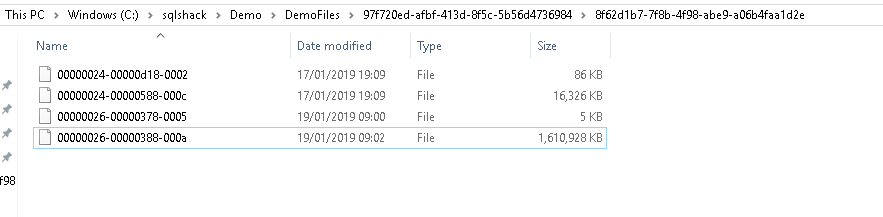
It contains the old files as well. In the article Managing data with SQL Server FILESTREAM tables, we provided an overview of the garbage collection process and how it works with the transaction log backup and CheckPoint. SQL Server maintains an internal table filestream_tombstone to track this garbage collection process. We can view the internal files using the dedicated administrator connection (DAC). DAC allows connecting to SQL Server even if no one can connect to it due to resources issues. We can enable the DAC connection using the below command.
Use master GO sp_configure 'remote admin connections', 1 GO RECONFIGURE with OVERRIDE GO
You can refer to article SQL Server Dedicated Admin Connection (DAC) – how to enable, connect and use for more information about DAC.
Now connect to the SQL Server using DAC using the connection string as ‘ADMIN: Instance’. Please note SQL Browser service should be running to use DAC connection.
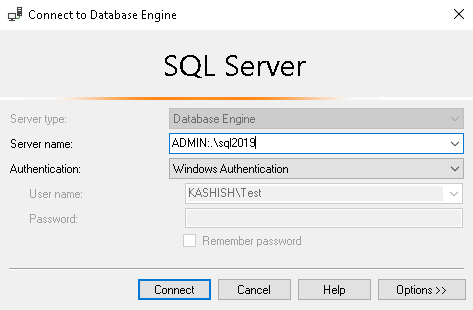
Once connected, execute the below command to check the internal tables for SQL Server FILESTREAM garbage collection.
use FileStreamDemoDB_test go select * from sys.internal_tables where name like 'filestream_tomb%'

In the above image, you get the internal table ‘ filestream_tombstone_2073058421’.
Now view the content of this file. We need to use the ‘sys’ schema to view this table content using the select command.
use FileStreamDemoDB_test go select * from sys.filestream_tombstone_2073058421

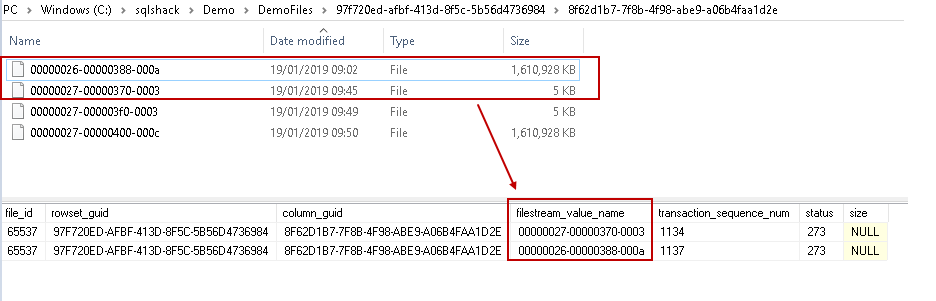
In this table sys.filestream_tombstone_2073058421 , you can get the old file names in the column filestream_value_name. Now we can compare the records in this table and files in the file stream container.
In the below image, you can notice that both the old files (before the update) are present in this internal table.
These tables get processed when the garbage collection process runs however, it does not clear the files until these changes are not backed up.
Lets us now run the transaction log backup.
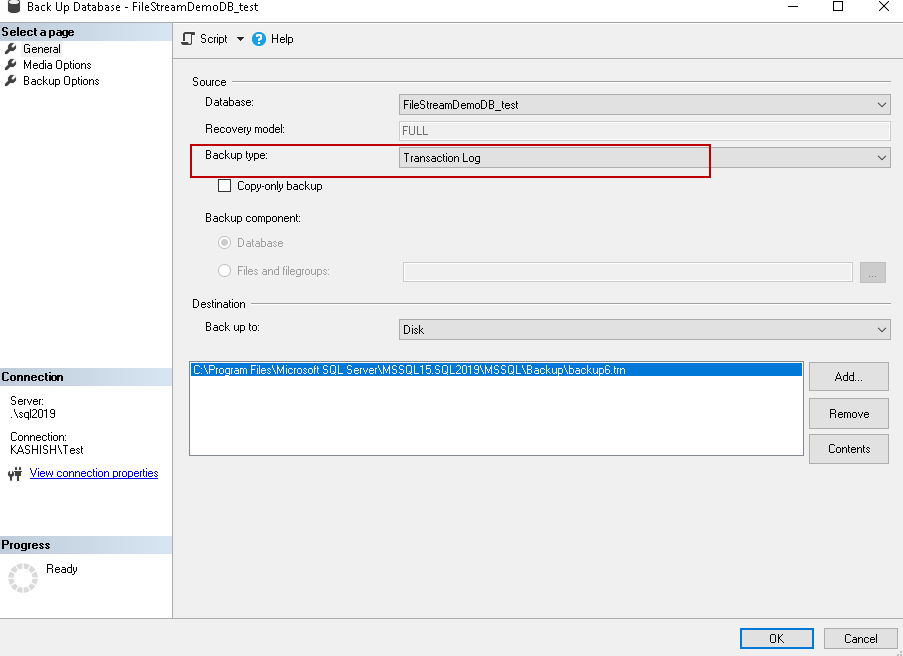
Once the transaction log backup is completed, check the content in the table sys.filestream_tombstone_2073058421 and as shown below 0 records found in the table.
In the SQL Server FILESTREAM container also, we can see the updated files (after update) only. It is how the internal garbage collection works.

In the article, FILESTREAM in SQL Server, we wrote about the folder structure using the FILESTREAM container. In the below image you can see these folders and files.
- Folder for each FILESTREAM table
- FILESTREAM Folder to show the column in the FILESTREAM table
- File in the FILESTREAM container

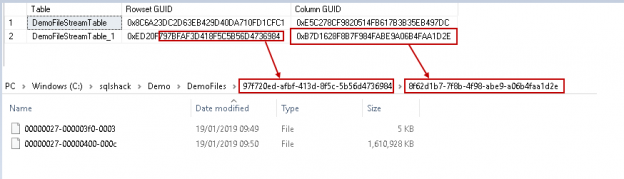
As you see these folders and files have specific names in the form of GUID. You might be wondering how these names are derived for the folders. We will execute the below command in the DAC connection window. Please note that you can have only one DAC connection. Therefore, if the DAC connection is already connected, use that connection only to run this query. If you run the query in standard connection, you get the error message. This error message comes because you cannot access the internal tables without a DAC connection.

Let us run the below query in DAC window,
SELECT
SELECT
[so].[name] AS [Table],
[r].[rsguid] AS [Rowset GUID],
[rs].[colguid] AS [Column GUID]
FROM sys.sysrowsets [r] CROSS APPLY sys.sysrscols [rs]
JOIN sys.partitions [pt]
ON [rs].[rsid] = [pt].[partition_id]
JOIN sys.objects [so]
ON [so].[object_id] = [pt].[object_id]
JOIN sys.syscolpars [sco]
ON [sco].[colid] = [rs].[rscolid]
WHERE [rs].[colguid] IS NOT NULL
AND [so].[object_id] = [sco].[id]
AND [r].[rsguid] IS NOT NULL
AND [r].[rowsetid] = [rs].[rsid];
GO

Let us compare the query output with the folder GUID.
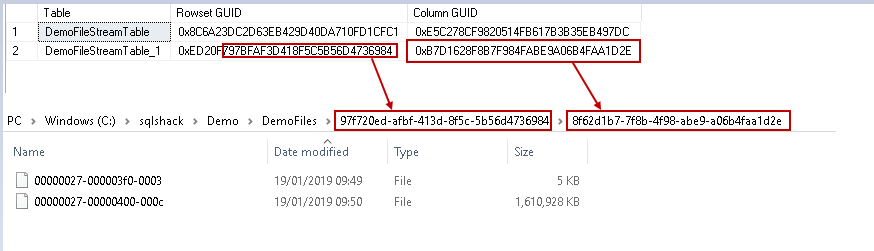
In the output, you can notice that the top-level directory GUID takes reference from the Rowset GUID and column level folder name shows name from the Column GUID. It is an interesting observation to know the internal of the system behaviour.
Now, we further want to dig into the internals and need to know the file name. As you know, FILESTREAM process copies the file from the source directory to the FILESTREAM container directory. Size of the source file and the container file is same, however; it does not maintain the file name inside the FILESTREAM container. There is a mechanism behind the file name. Let us explore this using the undocumented DBCC command, i.e. DBCC IND and DBCC Page. DBCC IND is used to identify the page that belongs to a table or index.
Execute the below command and pass the DB name and object name into the parameter. In this command, -1 displays all indexes for the object.
DBCC IND('FileStreamDemoDB_test','DemoFileStreamTable_1',-1)
The output of this command is as below.

We can examine a particular page using the DBCC page command. We need to turn on trace flag 3604 before running the DBCC Page command. DBCC Page shows the content of the database pages. Run the command with parameter ‘3’ to give the information about the page header and per row interpretation as well.
Run the below query to examine the page number 288 information with level 3.
DBCC traceon(3604)
DBCC Page ('FileStreamDemoDB_test',1,288,3)
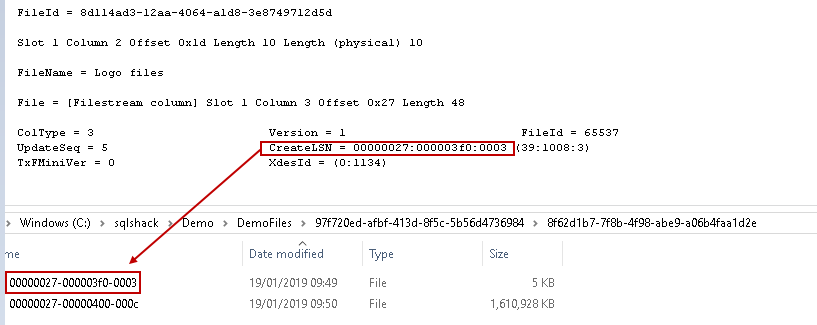
In the output, we need to look at the createLSN field.
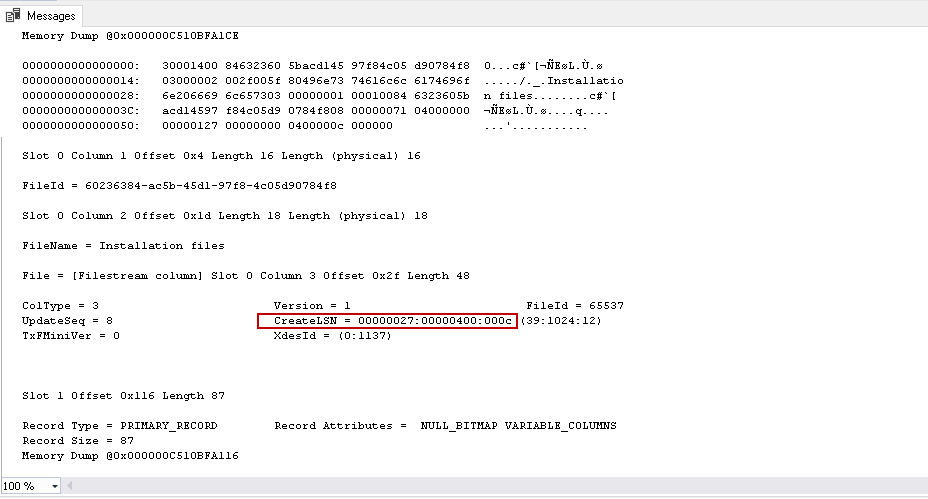
This CreateLSN value is the same as of the filename in the SQL Server FILESTREAM container file in the example image.
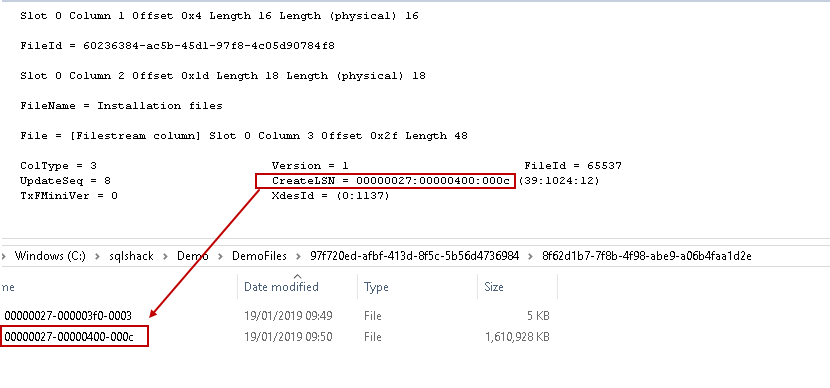
Similarly, the other file name also matches with the createLSN value.
Conclusion
In this article, we explored the internals of the SQL Server FILESTREAM processes including the garbage collector folder name and the file names. This gives a better understanding of the overall system process for the FILESTREAM if we know the internal threads of it. We will cover a few more aspects of this feature in future articles.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023