
SQL Server FILESTREAM allows storing the Varbinary (Max) objects in the file system instead of placing them inside the database. In the previous article – FILESTREAM in SQL Server, we took an overview of the FILESTREAM feature in SQL Server and process to enable this feature in SQL Server Instance.
Before we move further in this article, ensure you follow the first article and do the following:
- Enable FILESTREAM from the SQL Server Configuration Manager
- Specify the SQL Server FILESTREAM access level using the sp_configure command or from SSMS instance properties
In this article, first, we will be creating a FILESTREAM enabled SQL Server database. To do this, connect to the database instance and right click on ‘Databases’ and then ‘New Database’ to create a new FILESTREAM database.
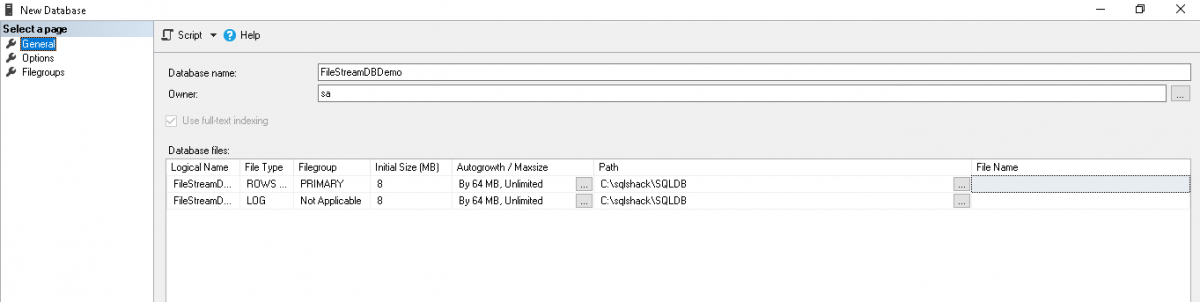
In the general page, specify the Database name and the location of the MDF and LDF files. In the demo, our database file and log file location is ‘C: \sqlshack\SQLDB.’
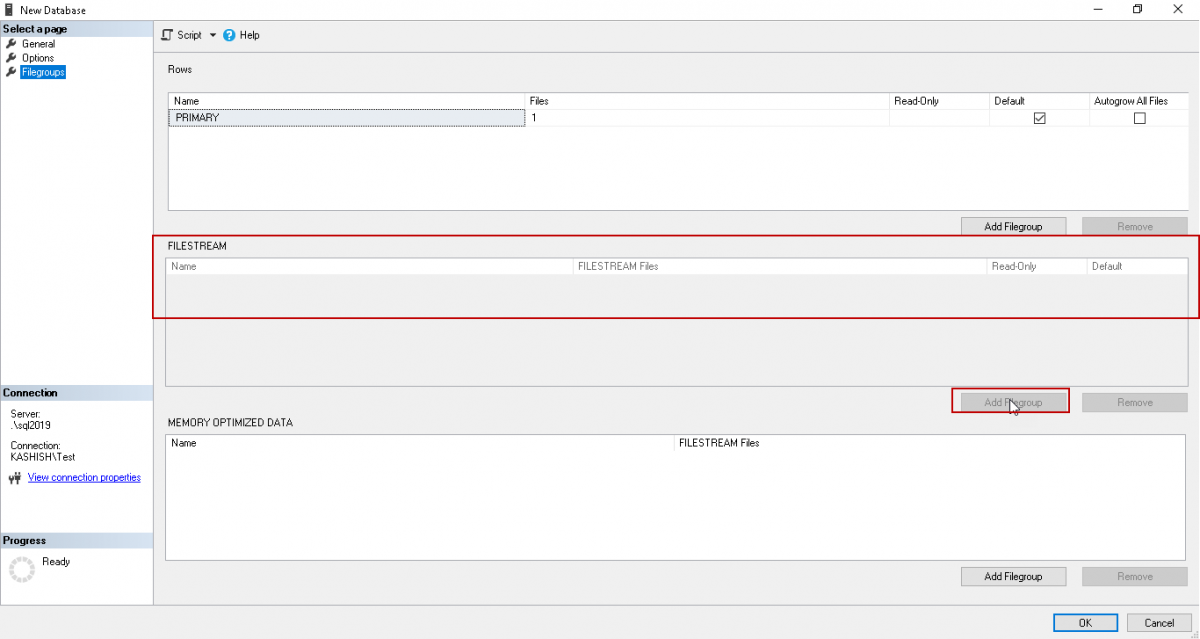
Click on the ‘Filegroups’ page from the left menu, and you can see a separate group for the FILESTREAM.
We need to add the SQL SERVER FILESTREAM filegroup here, but in the screenshot, you can see that the ‘Add Filegroup’ option is disabled. If we do not restart the SQL Service after enabling the FILESTREAM feature at the instance level from SQL Server Configuration Manager, you will not be able to add the FILESTREAM filegroup.
Restart the SQL Server service now and then again follows the steps above. You can see in below screenshot that the ‘Add filegroup’ option is now enabled.
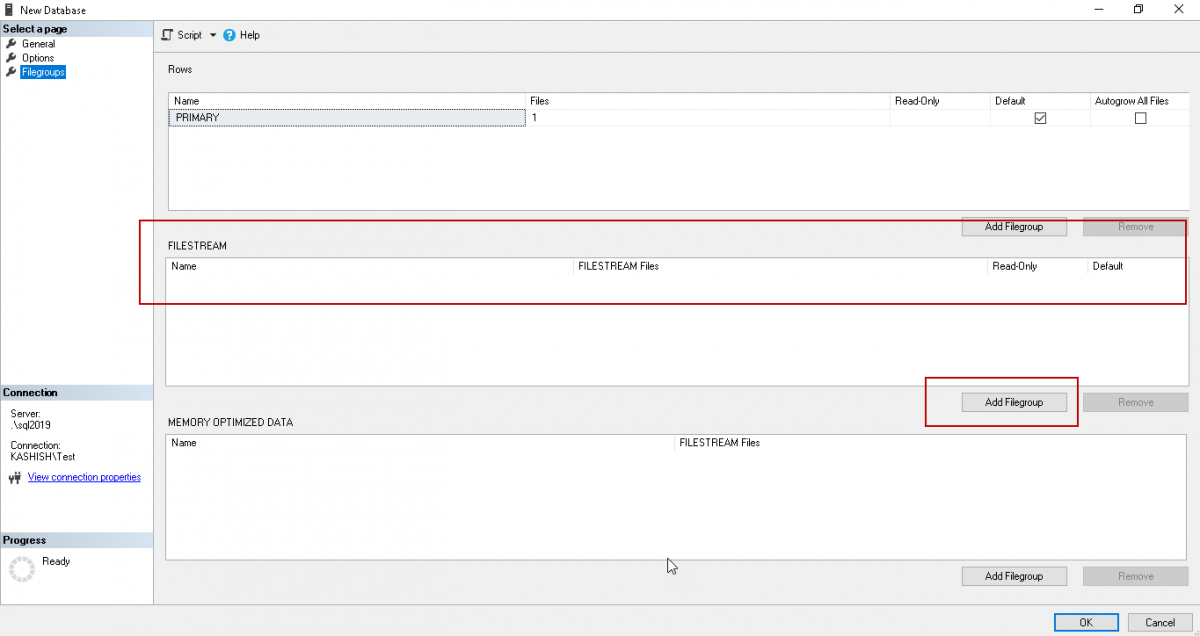
Click on ‘Add FileGroup’ in the FILESTREAM section and specify the name of the SQL Server FILESTREAM filegroup.
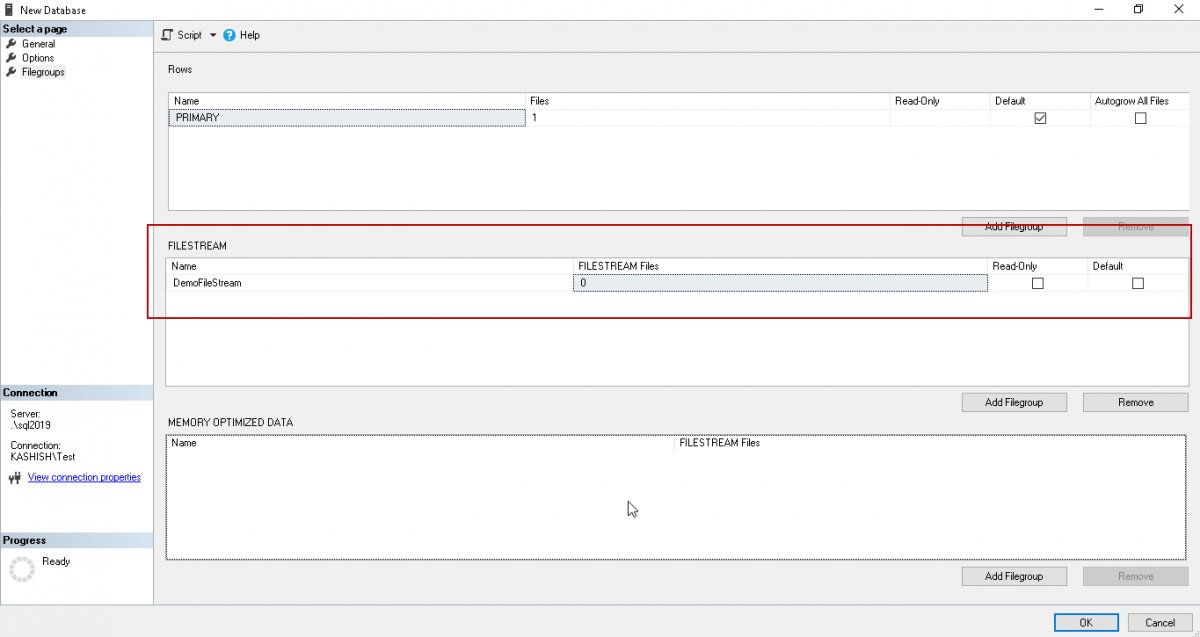
Click ‘OK’ to create the database with this new filegroup. Once the database is created, open the database properties to add the file in the newly created ‘DemoFileStream’ filegroup.
Specify the Database file name and select the file type as ‘FILESTREAM Data’ from the drop-down option. In the filegroup, it automatically shows the SQL Server FILESTREAM filegroup name. We also need to specify the path where we will store all the large files such as documents, audio, video files etc. You should have sufficient free space in the drive as per the space consumption of these big files.
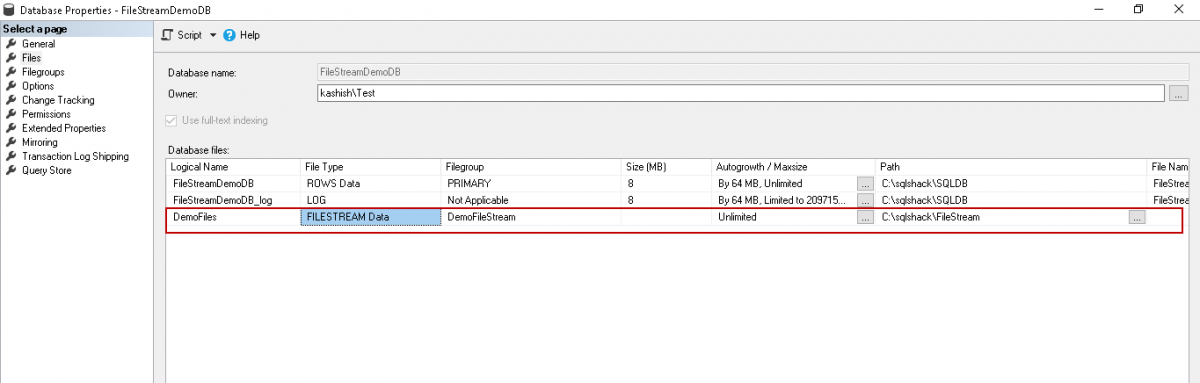
We can generate the script using the ‘Script’ option as highlighted below.
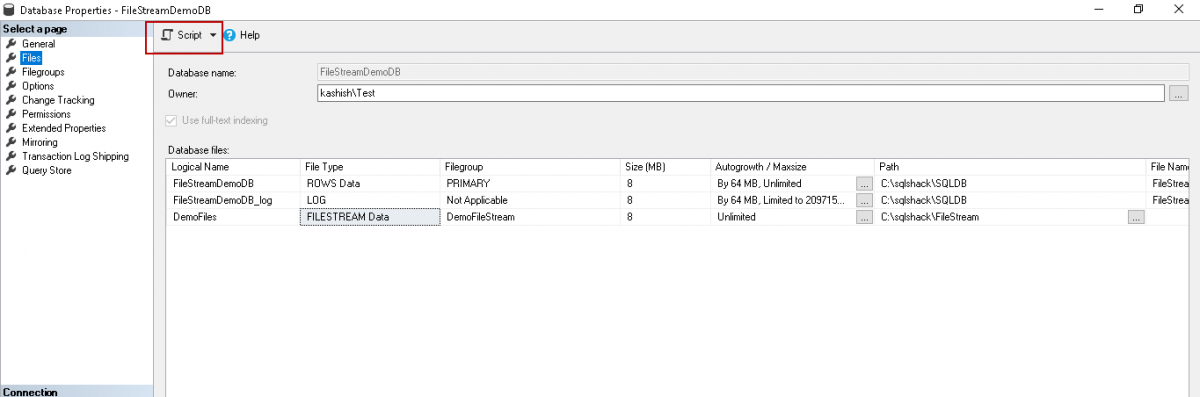
We can see the below scripts for the adding a SQL Server FILESTREAM filegroup and add a file into it.
|
1 2 3 4 5 6 |
USE [master] Go ALTER DATABASE [FileStreamDemoDB] ADD FILEGROUP [DemoFileStream] CONTAINS FILESTREAM GO ALTER DATABASE [FileStreamDemoDB] ADD FILE ( NAME = N'DemoFiles', FILENAME = N'C:\sqlshack\FileStream\DemoFiles' ) TO FILEGROUP [DemoFileStream] GO |
You can verify the container in the FILESTREAM file path ‘ C:\sqlshack\FileStream\DemoFiles as per our demo.
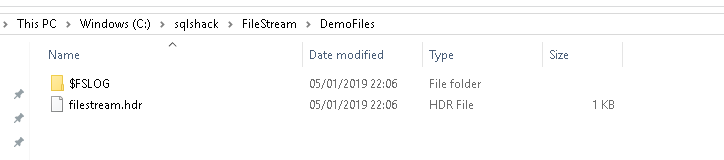
Here filestream.hdr file contains metadata for the FILESTREAM and $FSLOG directory is similar to the t-log in the database.
Creating a table in a SQL Server FILESTREAM database
Now let us create a table with the FILESTREAM data. In the below script, you can see we have used VarBinary(Max) FILESTREAM to create a FILEASTREAM table. As specified earlier, to use the FILESTREAM we should have a table with UNIQUEIDENTIFIER column with ROWGUIDCOL. In our script, [FileID] column contains unique non-null values.
|
1 2 3 4 5 6 7 |
Use FileStreamDemoDB Go CREATE TABLE [DemoFileStreamTable] ( [FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE, [FileName] VARCHAR (25), [File] VARBINARY(MAX) FILESTREAM); GO |
Now if we look at the FILESTREAM path, we can see a new folder with GUID values.
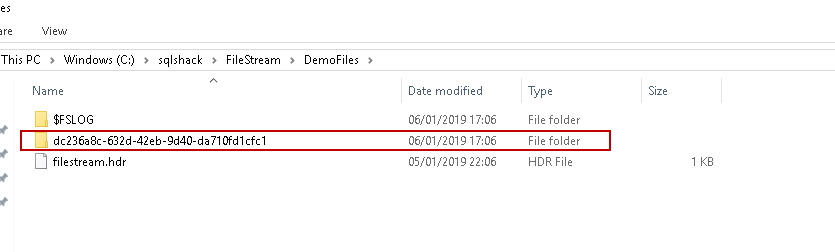
Let us create another FILESTREAM table in the same SQL Server database:
|
1 2 3 4 5 6 7 |
Use FileStreamDemoDB Go CREATE TABLE [DemoFileStreamTable_1] ( [FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE, [FileName] VARCHAR (25), [File] VARBINARY (MAX) FILESTREAM); GO |

We will get a new container for each FILESTREAM table in the path where we have created the FILESTREAM file.
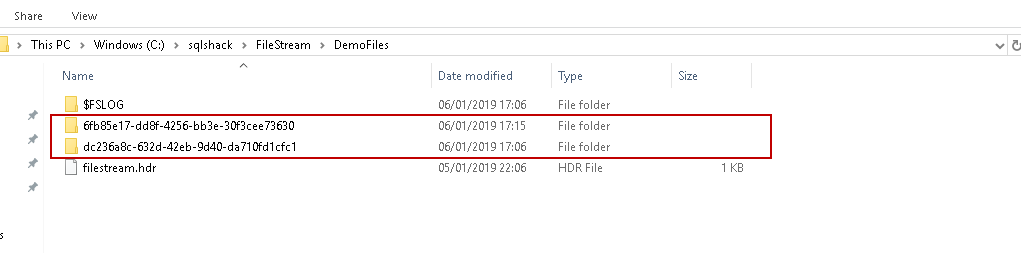
Open the container, and you can see another folder inside that. This folder shows the FILESTREAM column for the newly created table.

We will insert the data in the newly created FILESTREAM table. In this example, we will insert a picture which is located at the ‘C:\sqlshack’ folder.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\sqlshack\akshita.png', SINGLE_BLOB) as MyData; INSERT INTO DemoFileStreamTable_1 VALUES ( NEWID(), 'Sample Picture', @File ) |
We can select the records from the demo table. In the ‘File’ column you can see that the image is converted into the varbinary object.
|
1 2 3 4 |
SELECT TOP (1000) [FileId] ,[FileName] ,[File] FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1] |

Once we have inserted the data into the table, we can see a file into the folder. We can directly open this file using the compatible application program.

Right click this file and click ‘Open With’. Choose the program from the list of applications. In our example, we inserted image file; therefore, I choose ‘Photo Gallery’ to open it.
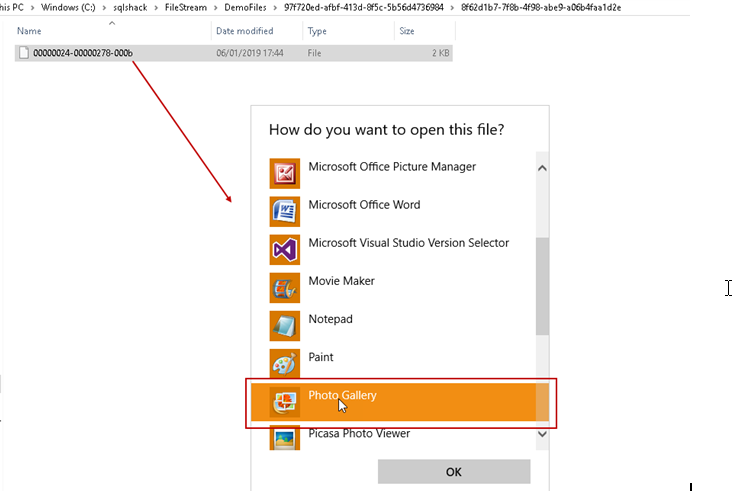
The image is opened in photo gallery as shown below.

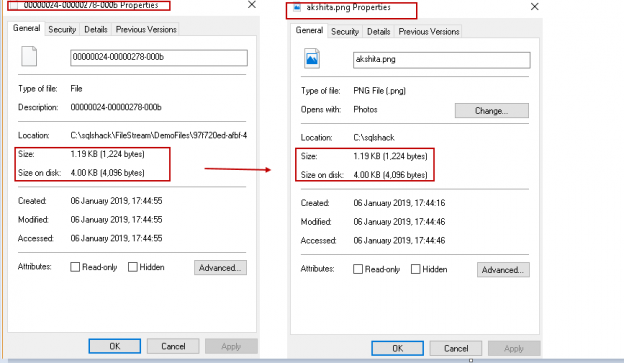
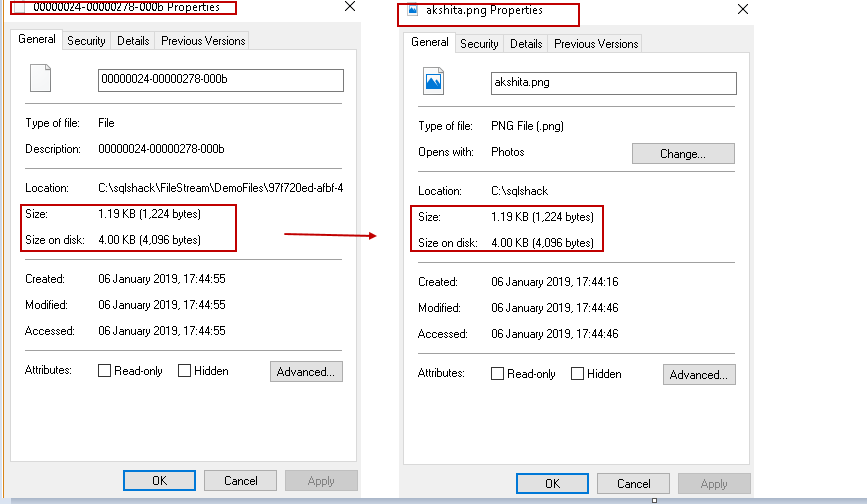
When we insert the document using the FILESTREAM feature, SQL Server copies the file into the FILESTREAM path. It does not change the file properties. In the below image, you can see the file stored in the container(C:\sqlshack\FileStream\DemoFiles\97f720ed-afbf-413d-8f5c-5b56d4736984\8f62d1b7-7f8b-4f98-abe9-a06b4faa1d2e) and the actual file (Path – C:\sqlshack) properties. You can see here that file size is the same for these files.
FILESTREAM Container | Actual File |
Size: 1.19 KB | Size: 1.19 KB |
Size on Disk: 4 KB | Size on Disk: 4 KB |
Updating Data stored in a FILESTREAM Table
Suppose we want to update the FILESTREAM document in our example. In this example, we want to replace the existing image with a word document. We can do it directly using the update command similar to the t-SQL command.
Below is the existing record in the table:
|
1 2 3 4 |
SELECT TOP (1000) [FileId] ,[FileName] ,[File] FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1] |

Run the below update command.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
UPDATE DemoFileStreamTable_1 SET [File] = (SELECT * FROM OPENROWSET( BULK 'C:\sqlshack\SQL Server Profiler in Azure Data Studio.docx', SINGLE_BLOB) AS Document) WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8' GO Update DemoFileStreamTable_1 set filename='Sample Doc' WHERE fileid = '60236384-AC5B-45D1-97F8-4C05D90784F8' GO |
Now let us verify the updated record in the table.
|
1 2 3 4 |
SELECT TOP (1000) [FileId] ,[FileName] ,[File] FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1] |

In the FILESTREAM path, you can see that we have a new word document file. We can open this file into the word document.
However, the FILESTREAM path contains the old image file as well. SQL Server did not remove this file.
In this case, we can see both the old and new FILESTREAM document. SQL Server removes the old files using the garbage collection process. This process will remove the old file if it is no longer required by the SQL Server. Initially, we saw a folder $log into the FILESTREAM path. It works similar to a transaction log in the SQL Server database.
SQL Server has a particular internal filestream_tombstone table, which contains an entry for this old file.
|
1 |
SELECT * FROM sys.internal_tables where name like ‘filestream_tomb%’ |
The garbage collection process removes the old file only if there is no entry for the file in the filestream_tombstone table. We cannot see the content of this filestream_tombstone table. However, if you wish to do so, use the DAC connection.
The database recovery model plays an essential role in the entry in the filestream_tombstone table.
- Simple recovery mode: In a database in simple recovery model, the file is removed on next checkpoint
- Full recovery model: If the database is in full recovery mode, we need to perform a transaction log backup to remove this file automatically
Take the transaction log backup with below command (you should have a full backup before to run a transaction log backup.
|
1 2 3 |
BACKUP LOG [FileStreamDemoDB] TO DISK = N'C:\Program Files\Microsoft SQL Server\MSSQL15.SQL2019\MSSQL\Backup\FileStreamDemoDB.bak' WITH NOFORMAT, NOINIT, NAME = N'FileStreamDemoDB-Full Database Backup', SKIP, NOREWIND, NOUNLOAD, STATS = 10 GO |

You can see now that old file is removed from the FILESTREAM path automatically.

We might need to run multiple transaction log backups if there are still VLF in the database. You can consider this similar to a standard transaction log truncate process.
We can run the garbage collector process file manually to remove the files from the container before the automatic garbage collector process cleans the file. We can do it using ‘sp_filestream_force_garbage_collection’.
Below is the syntax for ‘sp_filestream_force_garbage_collection’
|
1 |
sp_filestream_force_garbage_collection @dbname, @filename |
|
1 2 3 4 5 6 7 |
UPDATE DemoFileStreamTable_1 SET [File] = (SELECT * FROM OPENROWSET ( BULK ‘C:\sqlshack\Flow Map Chart Power BI Desktop.docx’, SINGLE BLOB) AS Document) WHERE fileid = ‘835FF1A7-DFFD-485F-ABAE-B718D277B258’ GO |
We have both the old and new file after the update.
Let us run the sp_filestream_force_garbage_collection for the SQL Server FILESTREAM database.
|
1 2 3 |
USE FileStreamDemoDB; GO EXEC sp_filestream_force_garbage_collection @dbname = N’FileStreamDemoDB’ |

Here you can see that value for the num_unprocessd_items is 1. It indicates that the garbage collector process does not remove the file. As highlighted earlier, it may be due to a pending transaction log backup, checkpoint or the long-running active transaction.
last_collected_lsn shows the LSN number to which garbage collector has removed the files.
Rerun the transaction log backup and rerun the procedure. We can see that the there are no unprocessed items (num_unprocessed_items=0) and last_collected_lsn is also modified as per the last log backup.
|
1 2 3 |
USE FileStreamDemoDB; GO EXEC sp_filestream_force_garbage_collection @dbname = N’FileStreamDemoDB’ |

Note: We need to have db_owner permission in the database to run this procedure.
Deleting FILESTREAM data
We can remove the rows from the FILESTREAM table using the delete statement similar to a standard database table.
|
1 2 3 4 |
SELECT TOP (1000) [FileId] ,[FileName] ,[File] FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1] |

|
1 2 3 4 |
SELECT TOP (1000) [FileId] ,[FileName] ,[File] FROM [FileStreamDemoDB].[dbo].[DemoFileStreamTable_1] |

We have deleted the row from the FILESTREAM table, however; the file will be deleted from the path once the garbage collector process runs.
Conclusion:
In this article, we explored how to create a database with a SQL Server FILESTREAM filegroup along with demonstrating DML activity on it. You can explore this exciting feature in the SQL Server Database yourself and continue to follow along as we will cover more on the SQL Server FILESTREAM feature in the next article.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023