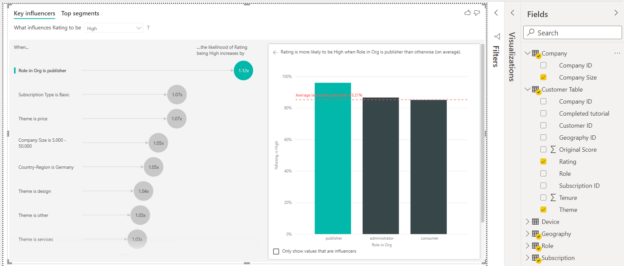
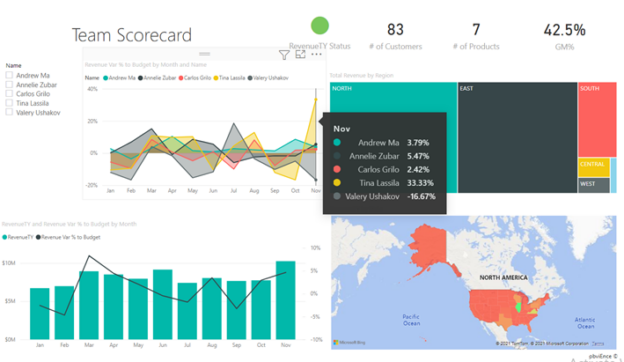
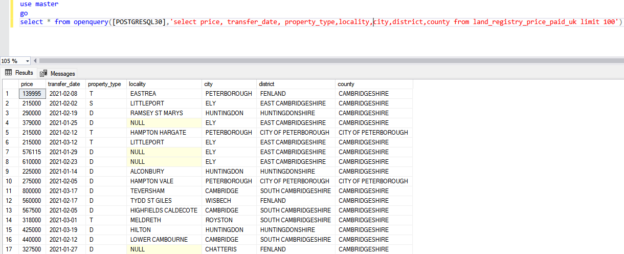
In this article, we will learn how to get started using PostgreSQL on Docker. PostgreSQL is one of the most popular open-source databases that is being used by a lot of developers. It is highly stable and has a large community that maintains and supports the database development lifecycle. PostgreSQL can be installed on any operating system like Windows, macOS, and Linux. With the rise in containerization technologies, PostgreSQL can now also be installed using Docker.
Read more »