In this article, we will learn how to use the ERD Project feature of pgAdmin to work with an instance of Azure Database for PostgreSQL for data modeling.
Read more »
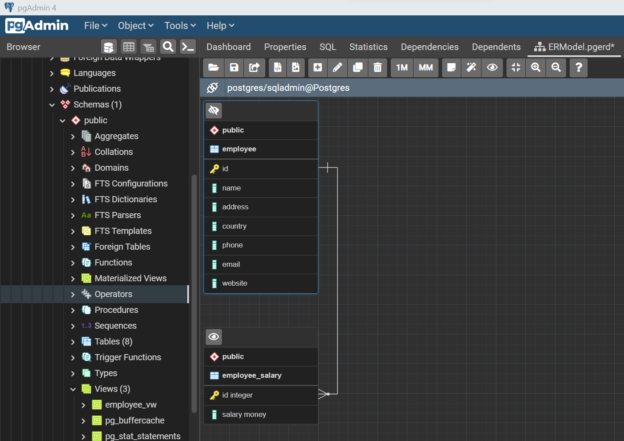
In this article, we will learn how to use the ERD Project feature of pgAdmin to work with an instance of Azure Database for PostgreSQL for data modeling.
Read more »
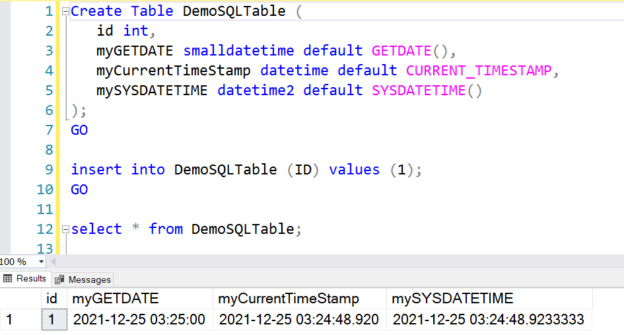
This article explores different SQL Commands (functions) to return the current Date and Time (Timestamp) in SQL Server.
Read more »
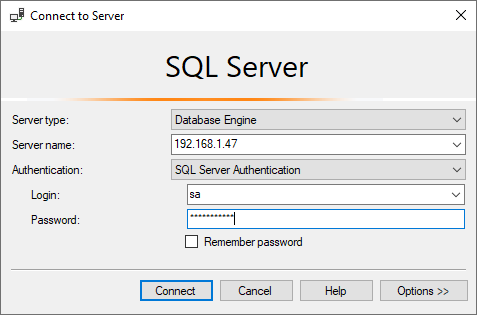
This article explains how to manage a data file and filegroups in an SQL database created on CentOS Linux. In my previous article, Manage filegroups of SQL Databases, we learned about the different types of filegroup and data files in SQL Server 2019 on windows and how to manage them using T-SQL queries. In this article, we will learn how to manage the filegroups in SQL Server 2019 on CentOS. I am going to cover the following topics in the article:
Read more »
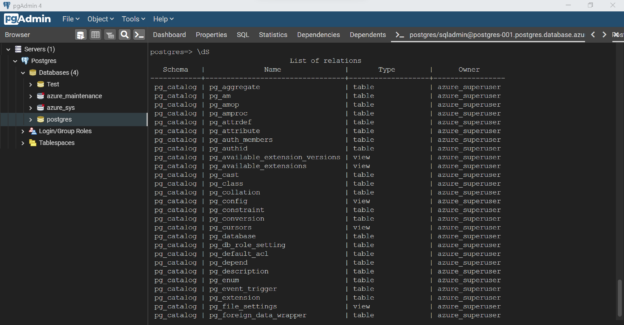
In this article, we will learn how to query the data as well as database objects hosted in an instance of Azure Database for PostgreSQL using psql and export the results of the query to a file.
Read more »
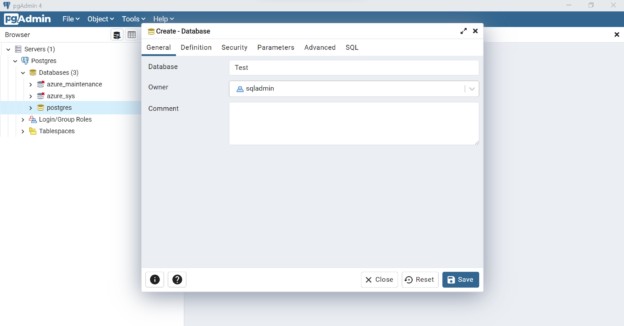
In this article, we will take a basic walkthrough of the psql environment and learn the commands to get acquainted with this tool.
Read more »
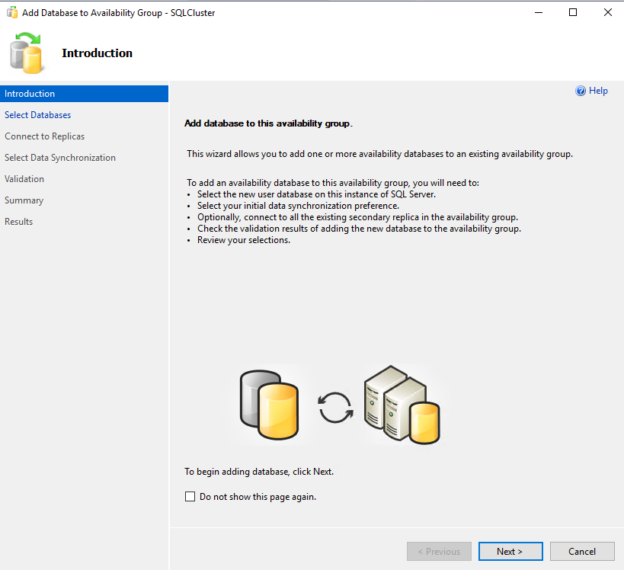
In this article, we will learn how to add a SQL database to an existing Alwayson availability group. Alwayson availability group is high availability and disaster recovery solution of Microsoft SQL Server. The database must meet the following prerequisites to be a part of an availability group.
Read more »
In SQL Server there are several kinds of SQL partitions. However, in general, we can say that a partition is a way to divide a table (sometimes a view) into smaller pieces for performance purposes. In this article, we will explain what partition does mean for a table partition and SSAS. We will also provide some guidance to automate the partition process.
Read more »
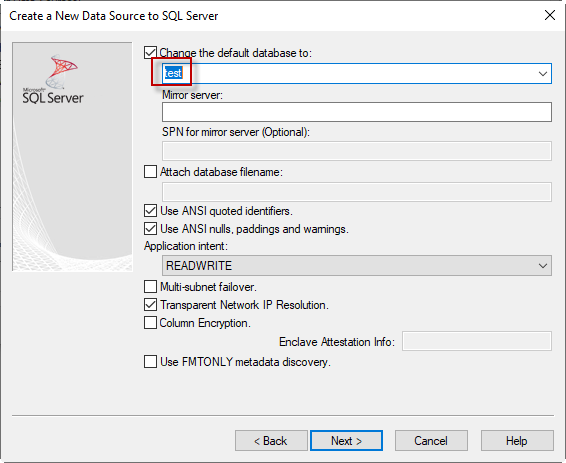
In previous articles, we learn how to configure PostgreSQL ODBC drivers, how to configure ODBC drivers for Azure Database for MySQL, the differences between OLE DB, ODBC, and ADO.net, how to configure Linked Servers using ODBC DRIVER. This time we will use the ODBC Drivers to connect in SSIS.
Read more »
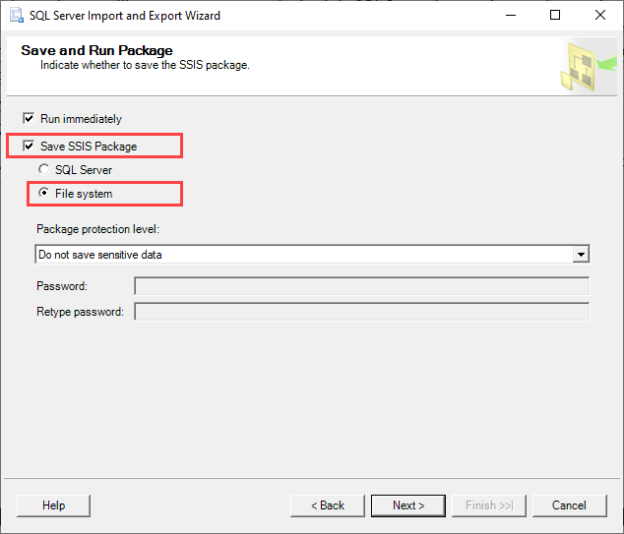
In this article, we will learn how we can backup and restore the SQL Database in CentOS. This article is the third article on the topic Manage SQL Server on CentOS. In my previous article, we learned how to copy data SQL database between windows 10 and CentOS Linux using SQL Server management studio.
Read more »
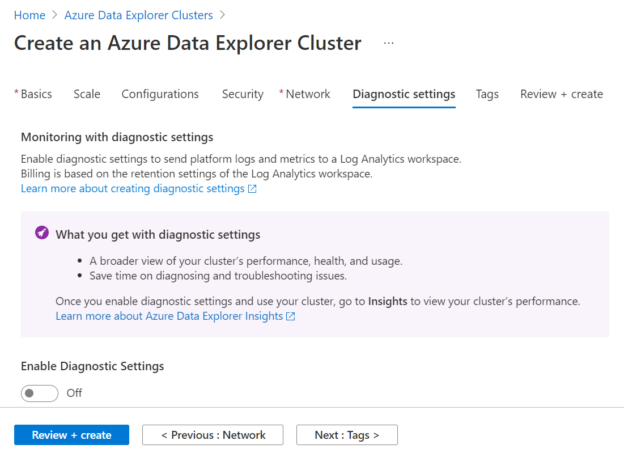
This article will show how to create an Azure Data Explorer cluster, and then configure it to be used with the Azure Synapse Analytics instance.
Read more »
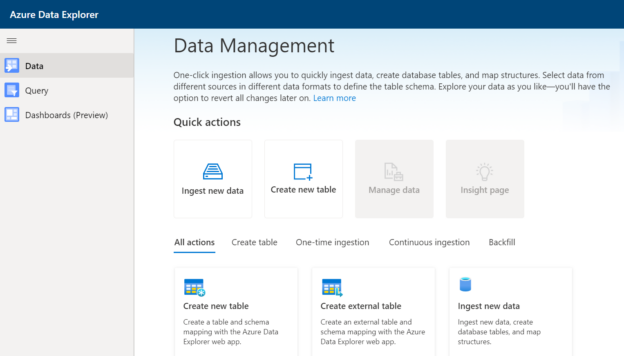
In this article, we will learn how to configure a newly created Data Explorer pool in Azure Synapse followed by data ingestion into the same pool.
Read more »
In the previous article, Getting started with Azure SQL, we learned the basics to create an Azure SQL database.
Read more »
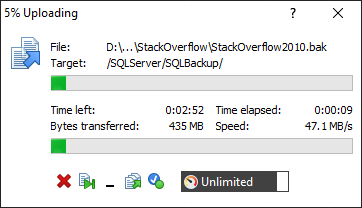
In this article, we will learn how we can backup and restore the SQL Database in CentOS. This article is the second article on the topic Manage SQL Server on CentOS. In my previous article, Install SQL Server on CentOS, we learned how we could install and create a SQL Database in CentOS.
Read more »
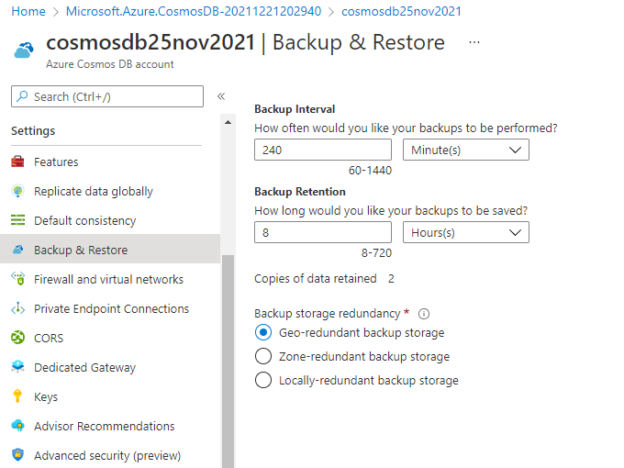
This article will explore backup options available in the Azure Cosmos DB service. Backups are very important to safeguard our data in case of data corruption, data deletion, system failure, or any unforeseen circumstances like DR. We have planned, configured, and managed it for our on-prem databases whether it is SQL Server, Oracle, DB2, or system files on various machines. DBAs and Infrastructure admins have ensured to keep a backup of all these systems to safeguard their data. Similarly, we must also secure our data hosted in a cloud environment for any services whether it is Azure VMs, Azure SQL, Cosmos Db accounts, or any other services. Today we will talk about backup options available to secure cosmos DB databases and their contents.
Read more »
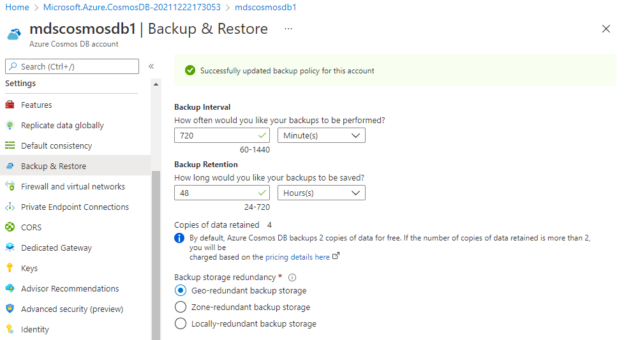
This article will talk about the periodic backup policy of the Azure Cosmos DB service offered by Azure cloud. I have already explained the backup options available for Cosmos DB in my last article. I would recommend you read it by accessing the attached link “Understanding Azure Cosmos DB backups” to understand the backup policies of Azure Cosmos DB. Today, I am going to explain one of the backup options Periodic backup, and steps about how to configure it for a cosmos DB account.
Read more »
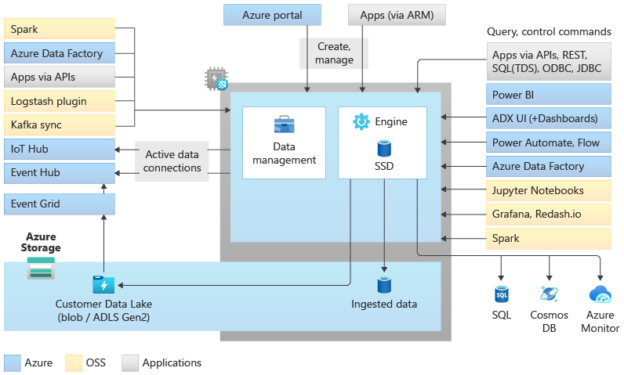
In this article, we will learn how to set up and configure Azure Data Explorer based data processing capability on Azure Synapse.
Read more »
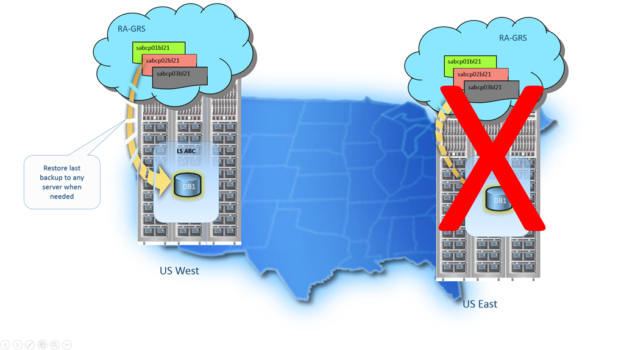
This article explains Azure SQL Database Geo Restore using geo-replicated backups for disaster recovery.
Read more »
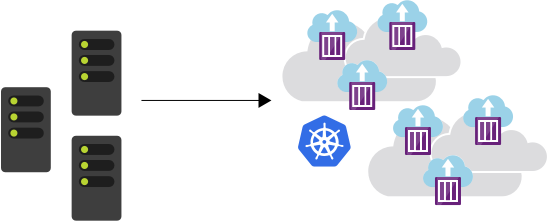
This article deploys a SQL Server container using Azure Kubernetes Services (AKS).
Read more »
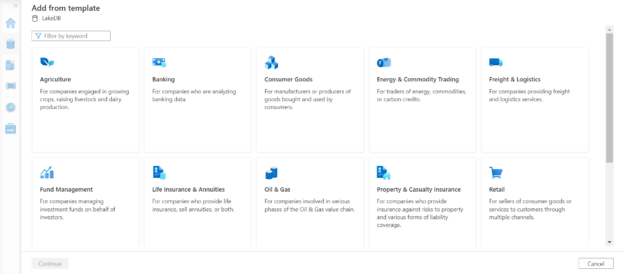
In this article, we will learn how we can create tables in the Azure Synapse Lake Database instance first and bind it with data later.
Read more »
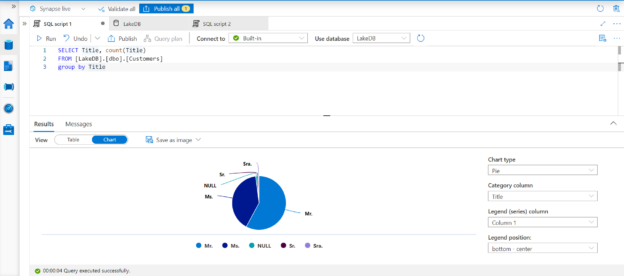
In this article, we will learn how to configure properties and relationships in Azure Synapse Lake Database.
Read more »
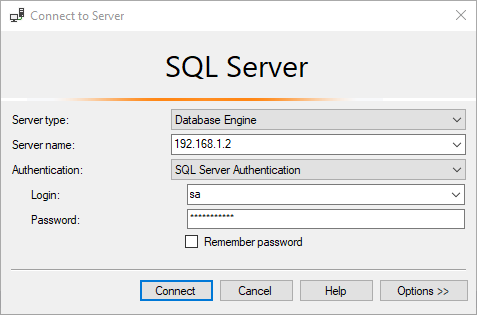
In this article, we will understand how we can manage a SQL Database in CentOS 8.0. This article is the first article on the topic Manage SQL Server on CentOS.
Read more »
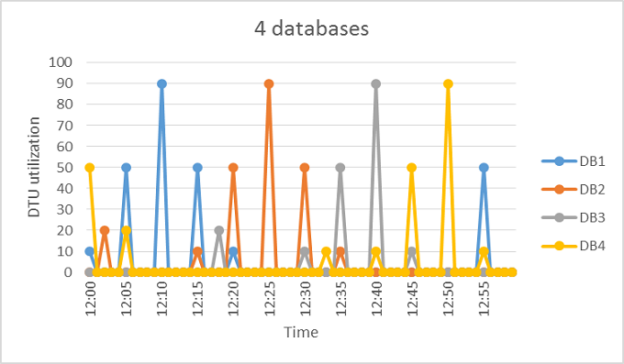
This article gives an overview and deployment steps for SQL Elastic Pool for Azure SQL database.
Read more »
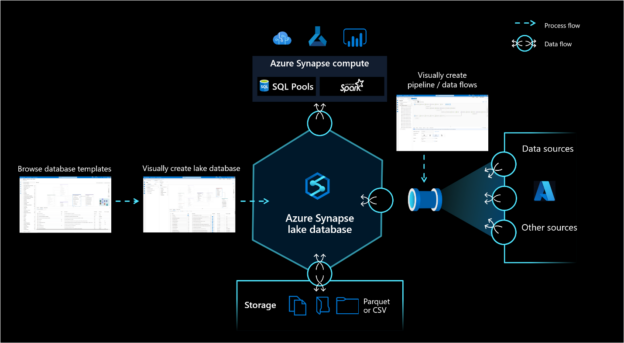
This article will get you started with Azure Synapse Lake Database and Lake tables.
Read more »
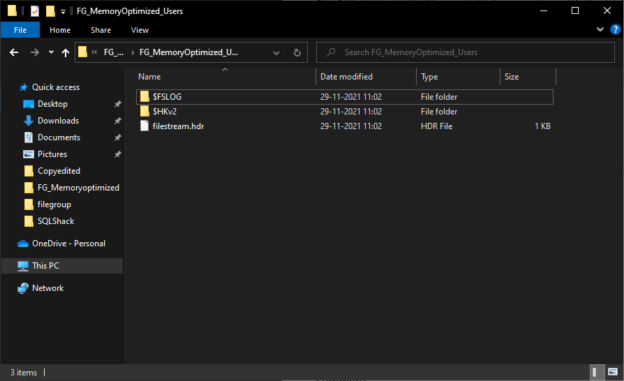
This article explains how to manage a memory-optimized filegroup of SQL Database. The memory-optimized filegroup contains the memory-optimized tables and table variables. I have written two articles that explain how we can migrate the disk-based tables to memory-optimized tables. Now, we will learn how to add memory-optimized filegroups in a SQL database. I will cover the following topics in the article.
Read more »
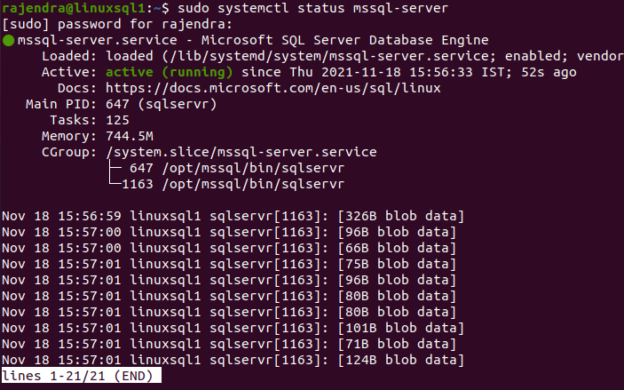
This article explores the process for rebuilding system databases – Master, MSDB, and Model for SQL Server on Linux and Windows.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy