
In this article, we will learn how to set up and configure Azure Data Explorer based data processing capability on Azure Synapse.
Introduction
Data can vary in terms of volume, schema, and nature of data. Data can be densely related, highly relational, geographical in nature, time-series oriented, very simplistic in a structure like key-valuea pairs, etc. Cloud has elevated the constraints around scale with virtually unlimited capacities available at one’s disposal in an on-demand fashion. Depending on the nature of data, one needs to employ a data repository that is suited to handle the corresponding type of data so that it can be processed and consumed in an optimal manner. Relational data is typically hosted on RDBMS, densely related data is hosted on Graph databases, highly time-series oriented data is hosted on time-series databases, and there are many such categories of database and services which cater to a particular class of data.
On the Azure cloud platform, a variety of databases are offered like Azure SQL, Azure Database for PostgreSQL, and a few others. For data originating from logs and sources like IoT, where the data is in the form of free text or typically JSON based semi-structured payloads, a data management and processing system that is suited to this kind of data is required. Azure’s primary offering to deal with this type of data is Azure Data Explorer. In the modern Data Lake paradigm, data is gathered on the data lake using Azure Data Lake Storage and massive amounts of data are analyzed using Azure’s data warehouse offering – Azure Synapse Analytics service. This service recently introduced Azure Data Explorer capabilities to facilitate processing and analytics of this data on Azure Synapse.
Unique features of Azure Data Explorer
While we know that Azure Data Explorer is Azure’s offering to process free-text and semi-structured in an ad-hoc analysis fashion, it is important to understand the unique features of this service that make it optimal for this type of data.
- Data Collection – Azure Data Explorer supports a variety of data pipeline frameworks and data sources that deliver or generate data in semi-structured or free-text formats. Examples of such systems or frameworks are Kafka streaming, Azure Data Lake Storage, Azure Event Hub Logs, etc.
- Data Modeling – Relational data, as well as analytical data, is typically modeled in the form of normalized tables or dimensions and facts. But log based data or free-text data is not generally modeled likewise. Azure Data Explorer has native features that facilitate data consumption without the need to model the data in a sophisticated way, as it intrinsically organizes the data in a way that is suited for ad-hoc consumption.
- Data Consumption – As this tool is intended to be used in a self-service manner by analysts and power-users, it is expected that it should support data access in a query language that does not require a lot of programming or technical skills. Kusto Query Language (KQL) is a user-friendly language that has similarities with SQL and Excel like formula formation.
- Data Processing Performance – Azure Data Explorer is a distributed system that can handle massive amounts of data at a cloud scale. Compute and Storage can scale independently as it integrates with services like Azure Data Lake Storage for using it as the storage layer and the compute layer can be used natively or with services like Synapse. It had features to auto-optimize data, eliminating the need for continuous query optimization using techniques like indexing and other related mechanisms.
Azure Data Explorer Pool Architecture
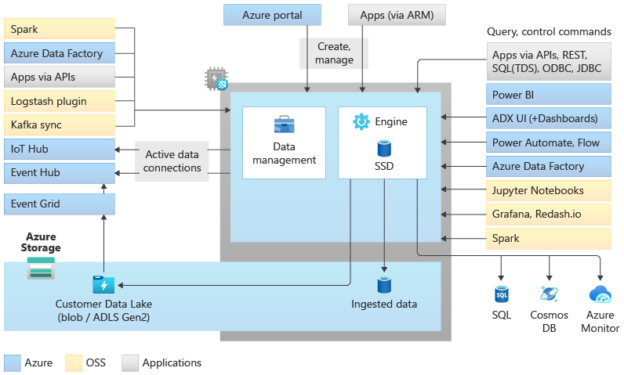
Shown below is the official architecture diagram of Azure Data Explorer pools in Azure Synapse. In Synapse, there are three different pools – Serverless SQL Pool, Dedicated SQL Pool and Apache Spark pool. To enable Data Explorer related capabilities with Azure Synapse, the Azure Data Explorer Pool has been launched in preview (as of the draft of this article).
Let’s analyze this architecture diagram briefly. The storage layer forms the bedrock of this architecture, where data is stored and/or sourced from data repositories like Azure Data Lake Storage, structured data sources like Azure SQL which can host semi-structured (JSON) data as well, no-SQL data sources like Azure Cosmos DB, and log collection repositories like Azure Monitor. While these are Azure native services, it also supports data ingestion from various other streaming and semi-structured or log based repositories like IoT Hub, Event Hub, Event Grid, Kafka, Logstash, Custom Application APIs, ETL data pipelines built with Azure Data Factory, Apache Spark and few others. On the other side, the data consumers from Data Explorer can be a variety of applications like custom apps, Power BI dashboards, Power Automate workflows, Azure Data Factory pipelines which can use it as a source as well as the destination, popular notebook-style editors like Jupyter notebooks, open-source charting tools like Grafana and many others. The two core aspects of the Azure Data Explorer pool are the management features and the engine configuration. We will look at it briefly in the next step.
Creating Azure Data Explorer Pool in Azure Synapse
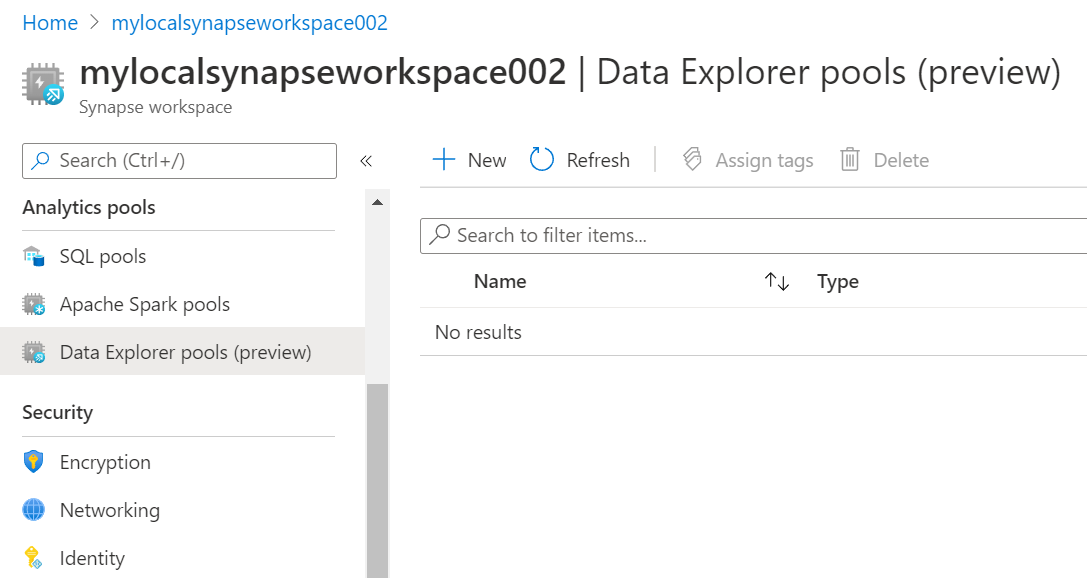
It is assumed that one already has an Azure account with an Azure Synapse instance created on it. This is necessary to have in place to proceed with the next step of this exercise. Navigate to the dashboard of the Azure Synapse instance and open the Azure Synapse Studio link to accent this console. Once we are on the console, navigate to the Analytics Pools section and there we would be able to find the Data Explorer pool as shown below.
Click on the New button to initiate the Data Explorer pool creation wizard, and it will open a new page as shown below. On the first page, we need to fill up basic details. We can start by assigning an appropriate name for this pool.
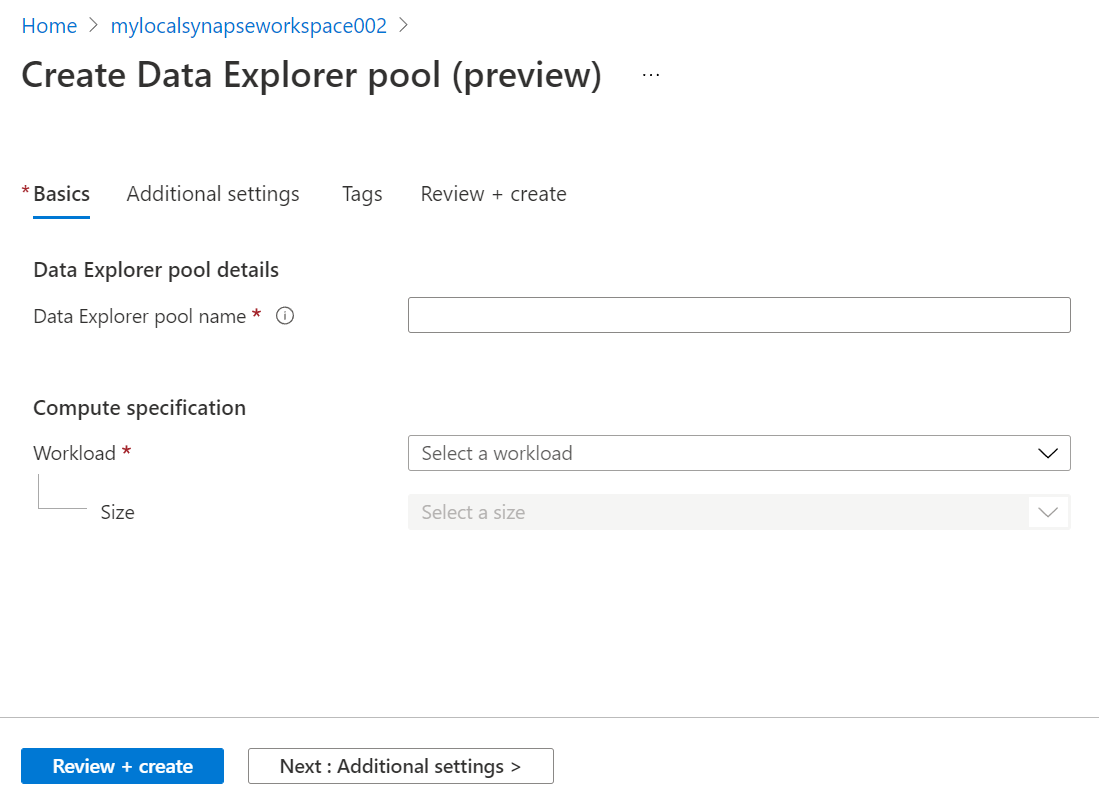
The Compute specification determines the kind of workloads that we intend to run on this pool and accordingly the kind of resources we want to allocate for this instance. There are two selections available here – Storage optimized, and Compute-optimized. Storage optimized would have higher capacity core configurations, while compute-optimized category will have granular level core configuration. For this exercise, we do not need a very high-capacity core configuration, so we can continue with the smallest core configuration i.e., 2 cores.
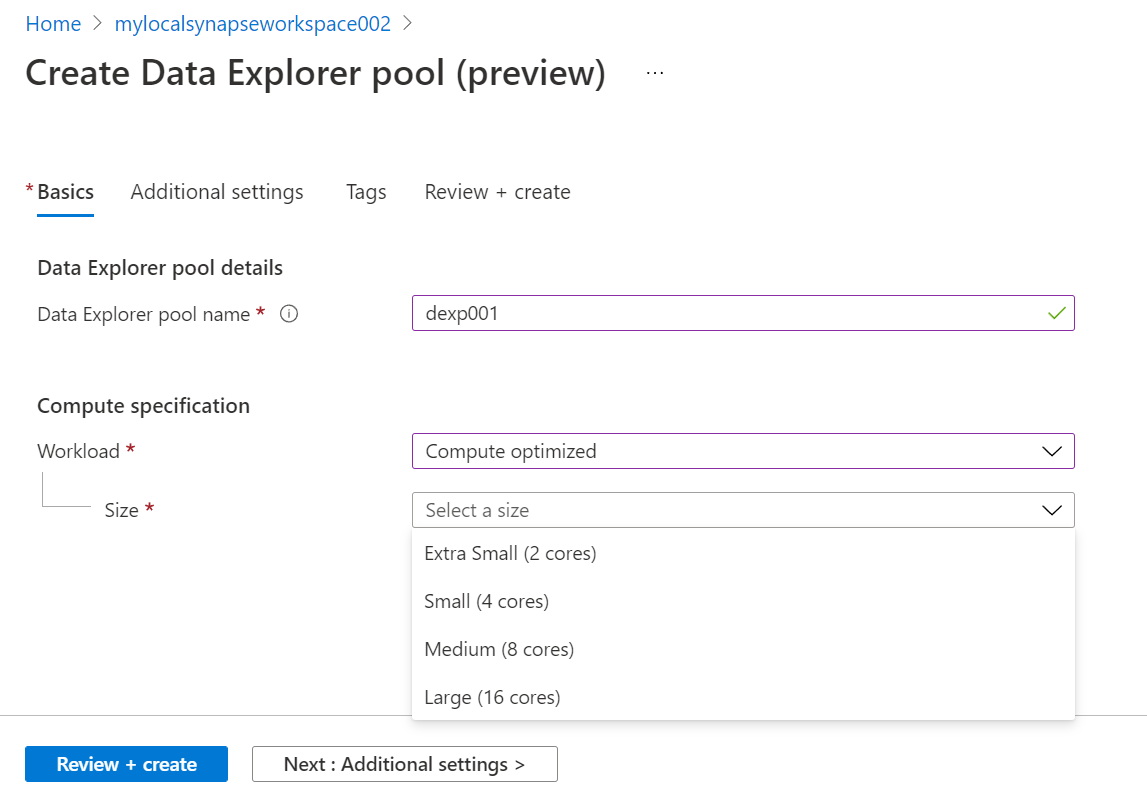
Click on the Next button to proceed with the next step which is Additional Settings. In this step, we need to select whether we intend to continue with the auto-scaling option as per the demand of the workloads, or we intend to provision a fixed capacity of resources. This can also have an impact on the cost depending upon the type of option we select and the type of workloads we will execute.
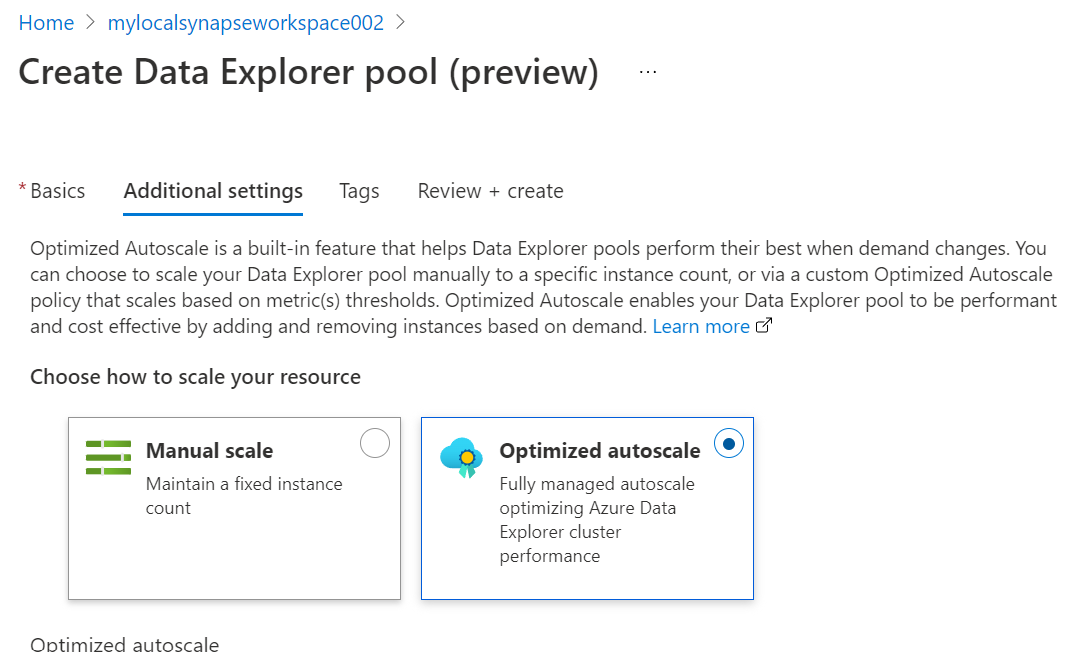
For now, we will continue with the optimized autoscale option. If we scroll down, we will find more options related to the optimized autoscale as shown below. By default, the streaming ingestion and purging option is disabled. One can optionally and selectively enable these options depending upon the data ingestion scenarios for their use case.
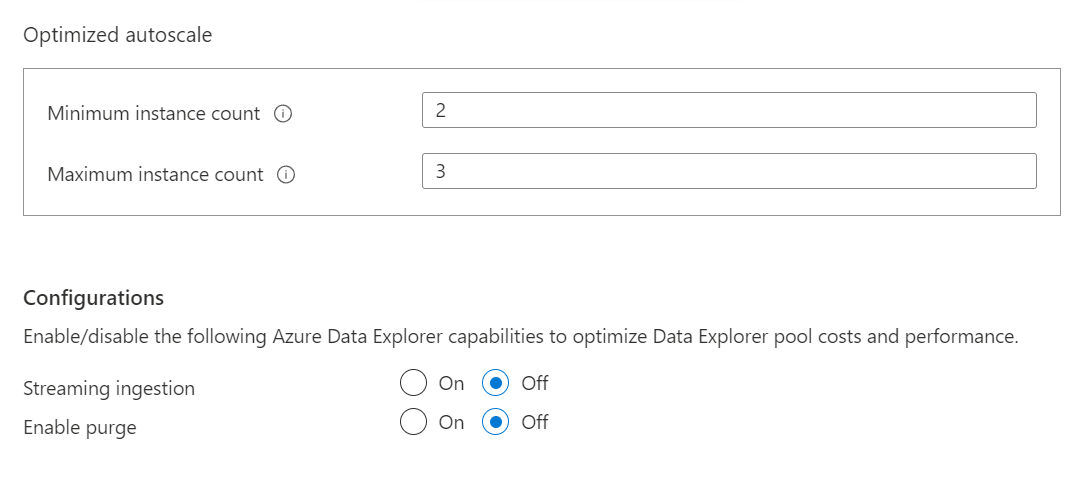
In the next step, one can optionally add any tags to this instance, which can be useful from an operations perspective. Finally, in the last step, we need to review the configuration and click on the Create button to create the pool. Once the pool gets created, navigate to the dashboard page of this pool as it would look as shown below.
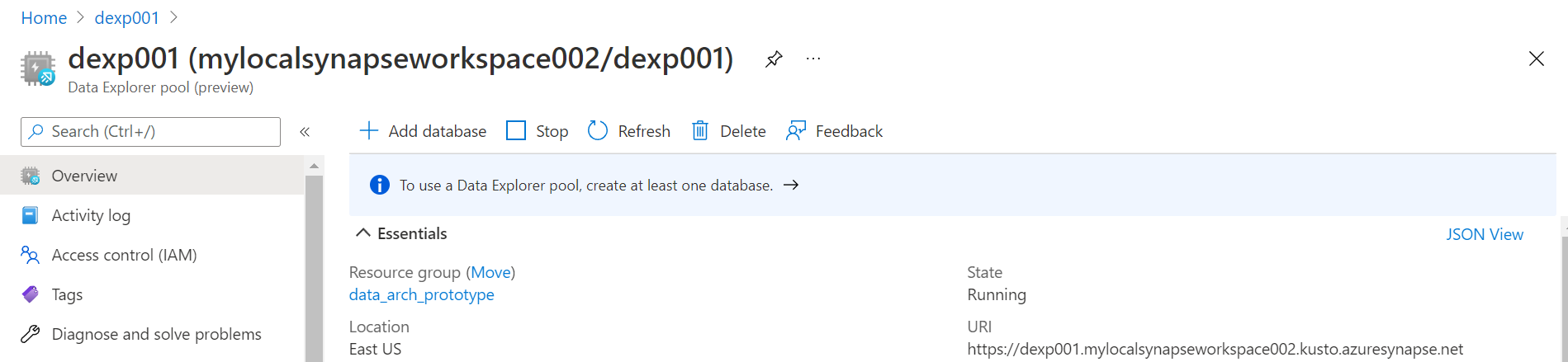
In this way, we can create an Azure Data Explorer pool on Azure Synapse and execute Azure Data Explorer related workloads on Azure Synapse.
Conclusion
In this article, we learned briefly about Azure Data Explorer, its capabilities, and its use for the relevant use-cases. Then we learned about the Azure Data Explorer pool which has been launched in Azure Synapse followed by a practical implementation of this pool.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023