
This article will show how to create an Azure Data Explorer cluster, and then configure it to be used with the Azure Synapse Analytics instance.
Introduction
In my previous article, Ingesting data into Azure Synapse Data Explorer Pool, we learned how to create an Azure Data Explorer pool in Synapse, as well as how to populate it with data hosted on Azure Data Lake Storage. The way this setup works is that it requires data to be populated in the Data Explorer pool created on Synapse. There can be use-cases where one already has an existing Azure Data Explorer cluster serving the users with data populated on it. If one wants to use this data in Azure Synapse and for this, if one must move the entire data from the cluster to the Azure Data Explorer pool, it would not be an efficient or an easy approach at all. Fortunately, one does not mandatorily need to perform this type of data migration from one cluster to another pool. Azure Synapse Analytics offers a mechanism where one can use external data sources with Azure Synapse.
Creating Azure Data Explorer Cluster
In the previous series of articles, we have covered how to create an Azure Synapse Analytics instance with different types of pools, the latest one being Azure Data Explorer pools. So here we would assume that one already has created an instance of Synapse and have access to Azure Synapse Studio to operate this instance.
For those who are new to Azure Data Explorer, we will first learn how to create an Azure Data Explorer cluster, which is near identical to the Synapse Data Explorer pool. Once we create this cluster, we would be able to get the cluster endpoint, using which we will look at how to register this instance with Azure Synapse to use the data from this cluster in Synapse.
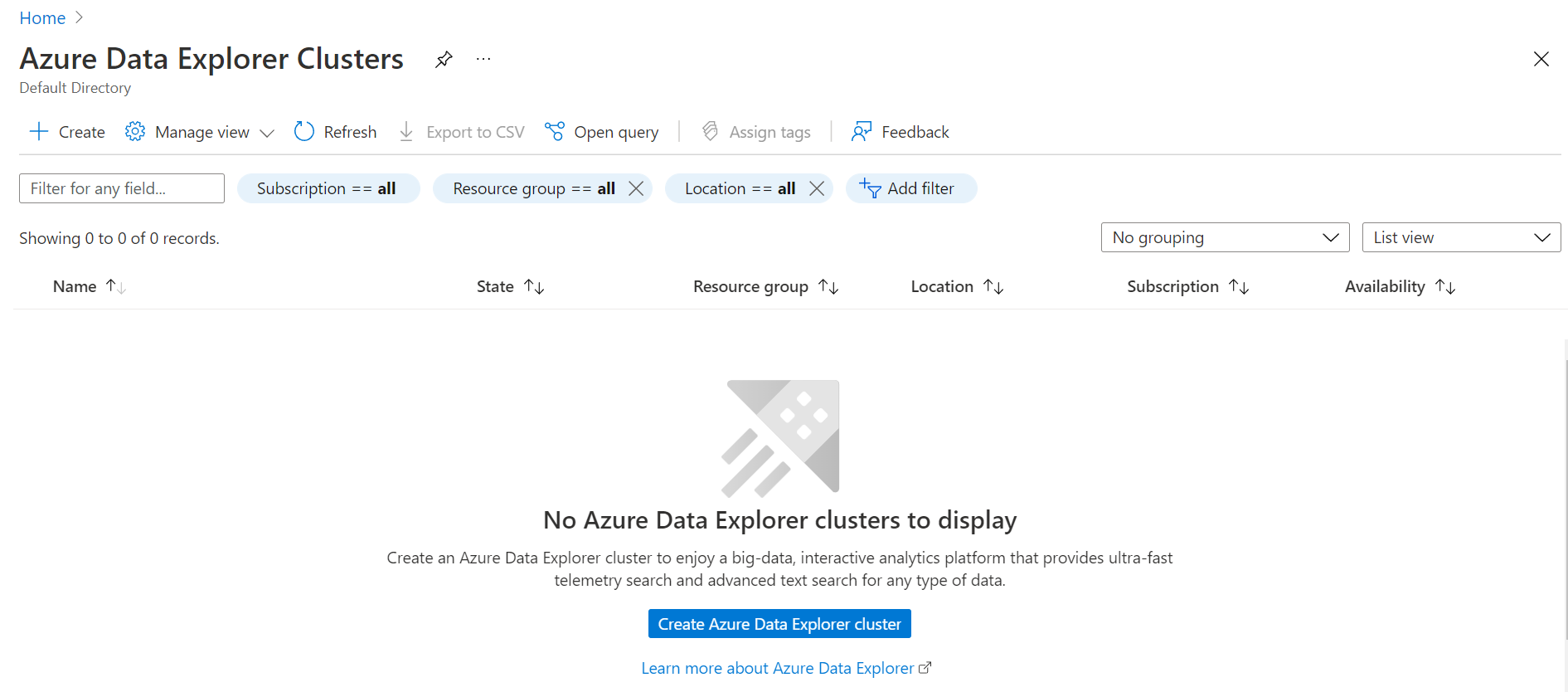
Assuming one has an Azure cloud account with required privileges to administer Azure Data Explorer Cluster, navigate to the dashboard of this service and it would look as shown below if one does not have any clusters in existence. We can start the creation of a new cluster by clicking on the button titled “Create Azure Data Explorer cluster”.
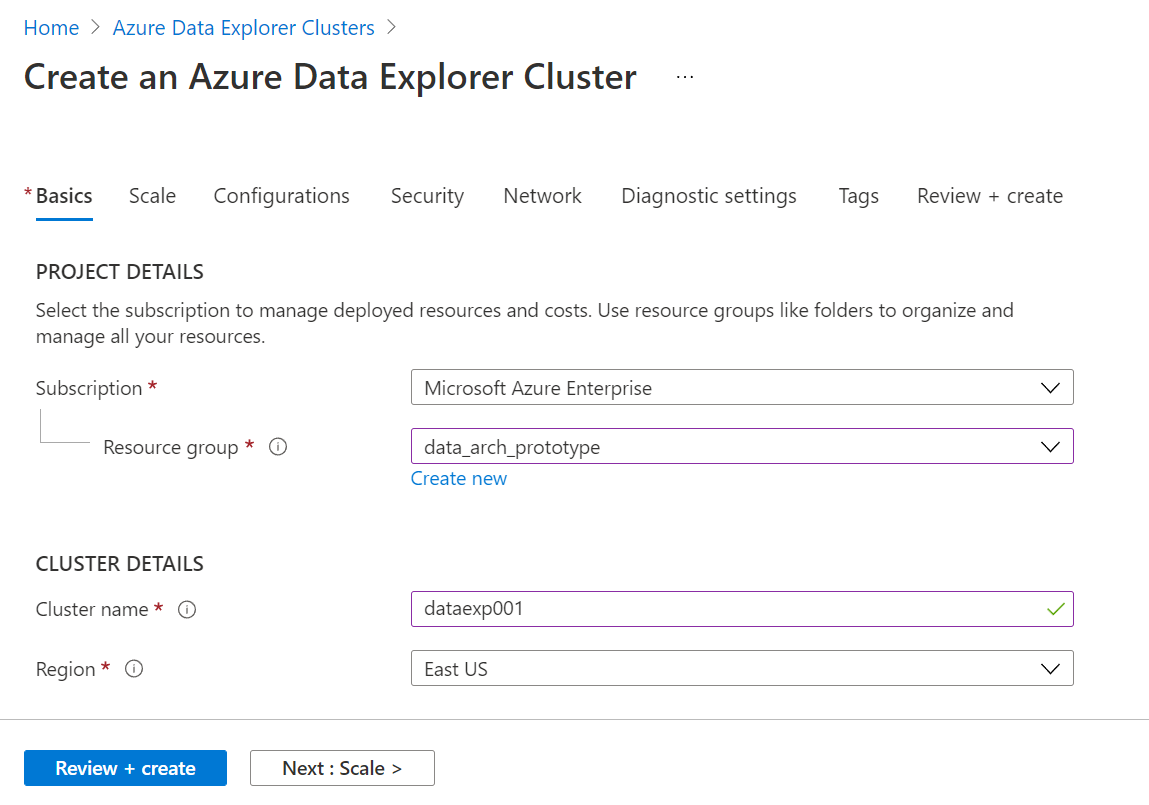
This would open an elaborate wizard to create the Azure Data Explorer cluster as seen below. The first step requires us to provide the basic details starting with subscription and resource group names. Then we need to provide a unique name for the cluster and the region in which the cluster should be created. Once done, scroll down to proceed with the next set of details.
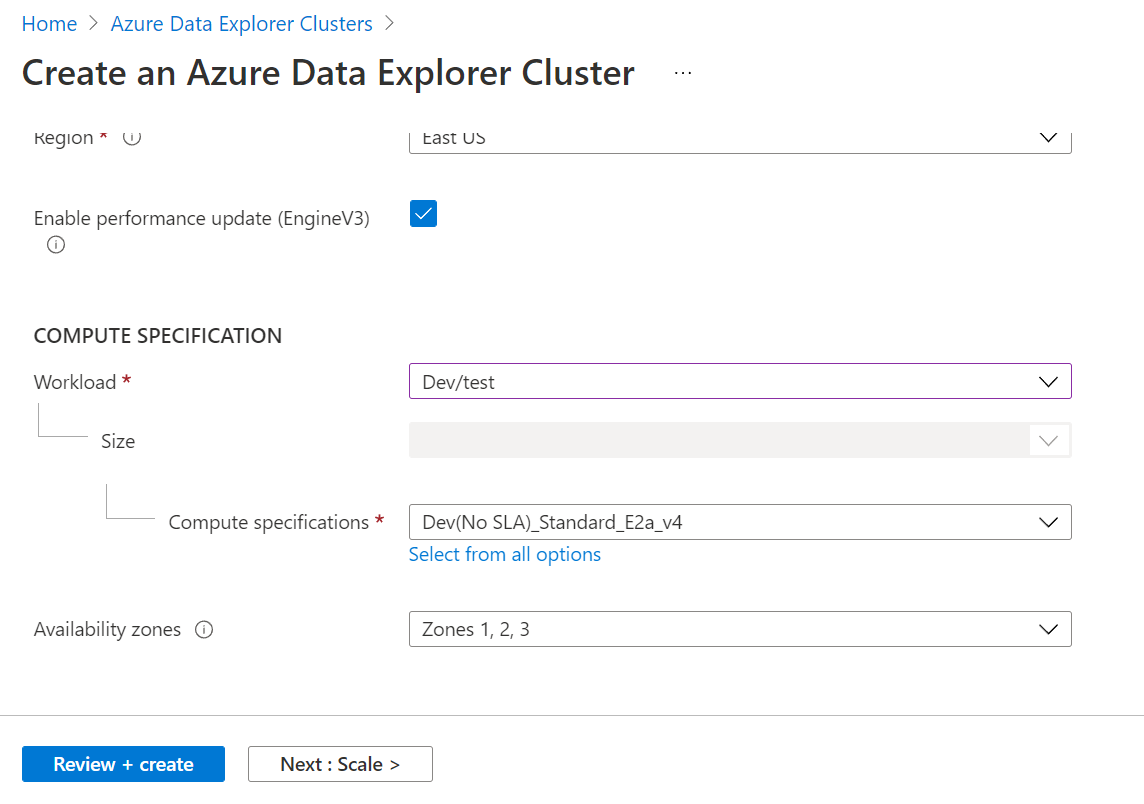
We need to select the compute specification which determines the type of configuration that we need for the workloads that will be executed on this cluster. For this exercise, we do not need any production scale configuration. So, we can simplify this and select the Dev/Test workload for this exercise.
In this next step, we need to select the scalability related options – Manual scale or Optimized autoscale. If one needs a varying degree of scaling as the workload resource requirements may be very volatile, the autoscale option would be optimal. In other cases, if one needs a fixed resource and fixed cost model to operate their workloads, in that case, the manual scale option would be a good starting point. For now, we will continue with the default option and continue with the manual option.
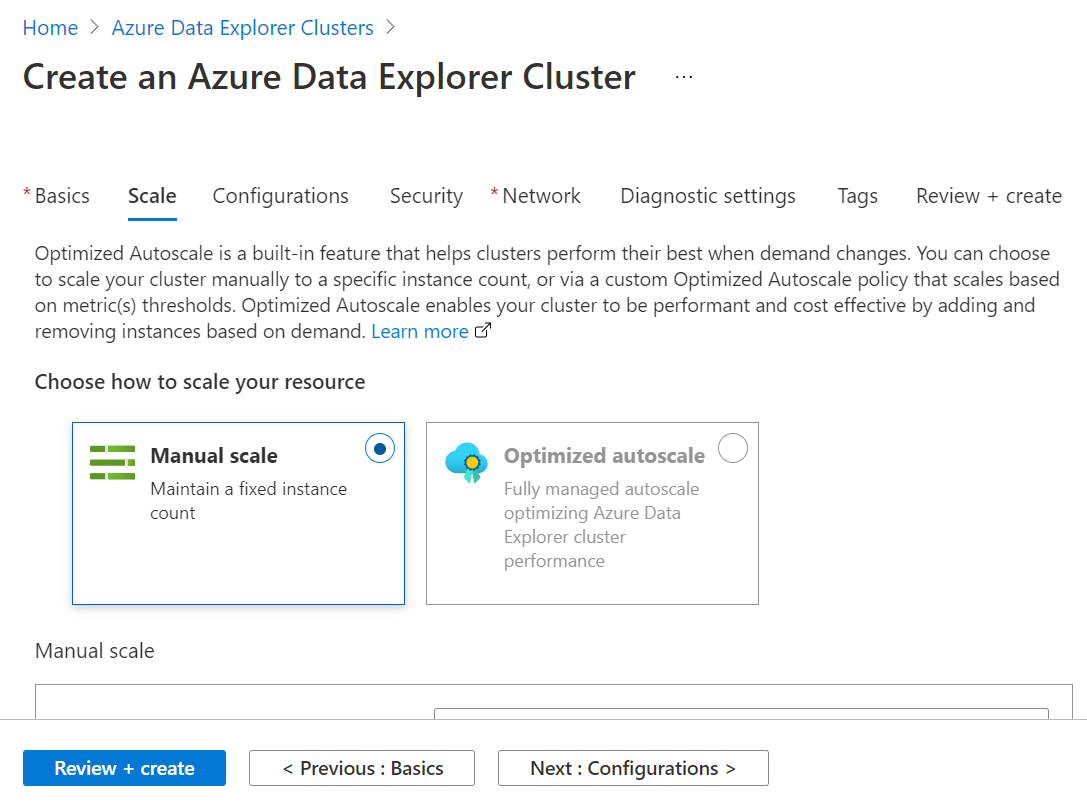
In the next step, we need to enable or disable certain settings in the configuration step. By default, the streaming-based ingestion and purging are disabled, and the auto-stop cluster option is enabled. These options are configured from a default base setup standpoint. For now, we do not need to change anything in these settings, and we can continue with the default values.
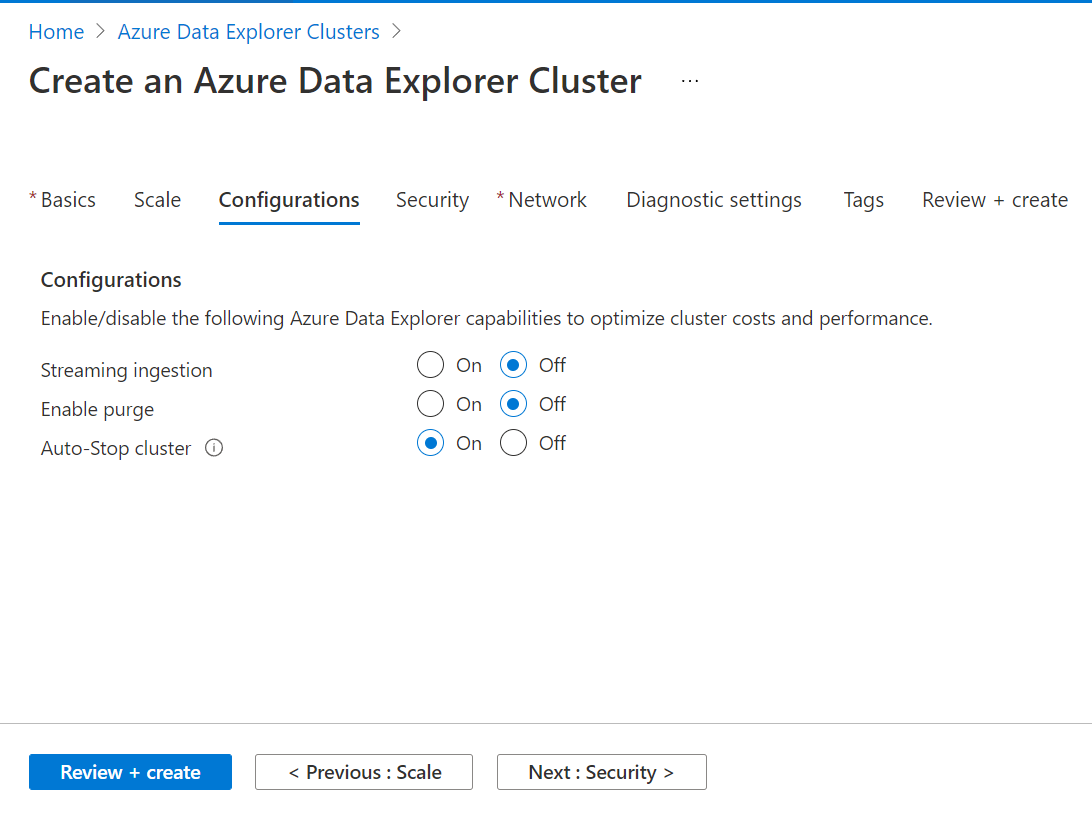
In the next step, we need to configure security-related settings on this step. By default, almost every service and data on the Azure cloud is encrypted. In case, one needs to strengthen the encryption level, one can opt for double encryption as well. This is not something that may be required by default for every use case, so it is disabled by default. We have an option to define tenants of this cluster who would use this cluster for consuming data. For now, we do not have any external tenants defined, but in the future, there may be tenants that may use this cluster. So, it would be optimal to select the “All Tenant” option here. System Identity and User Identity options are disabled by default. But one may want to enable it if one intends to use this cluster from another system like Synapse or another tenant as well. Complete the configuration of user and system identity and proceed to the next step.
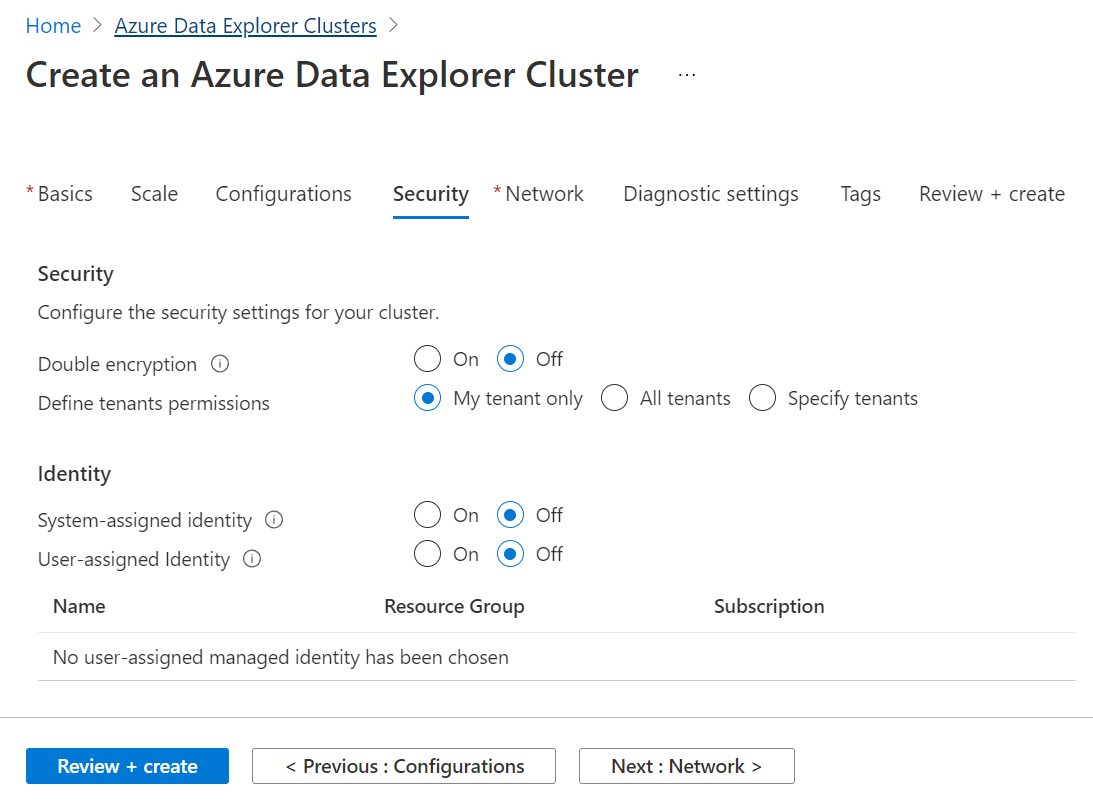
In the next step, we need to configure the network-related settings for this cluster. By default, this cluster is not created in the virtual network, but optionally one can enable this setting and specify the virtual network in which the cluster should be created.
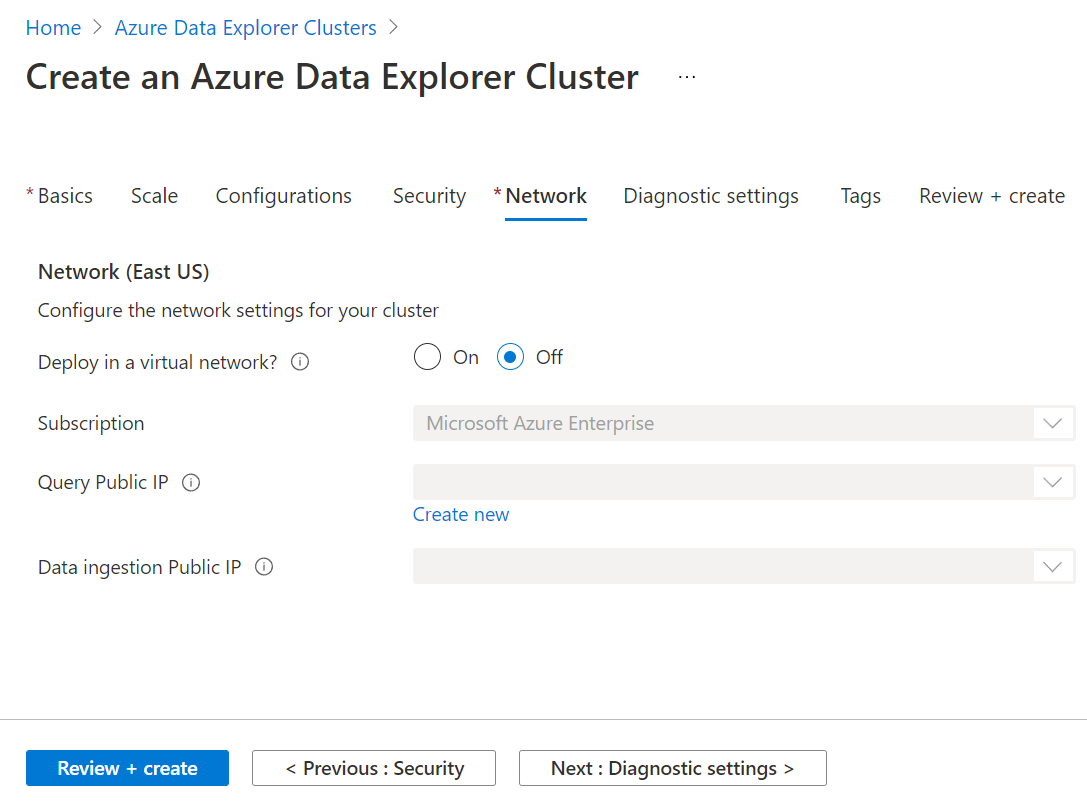
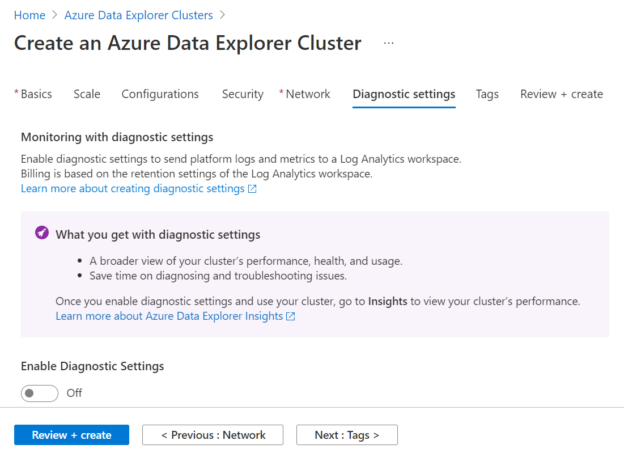
In the next step, we need to optionally specify whether we want to enable diagnostic settings for this cluster. Enabling this would result in the cluster transmitting performance-related data to Microsoft. Configure this setting as desired and then move to the next step.
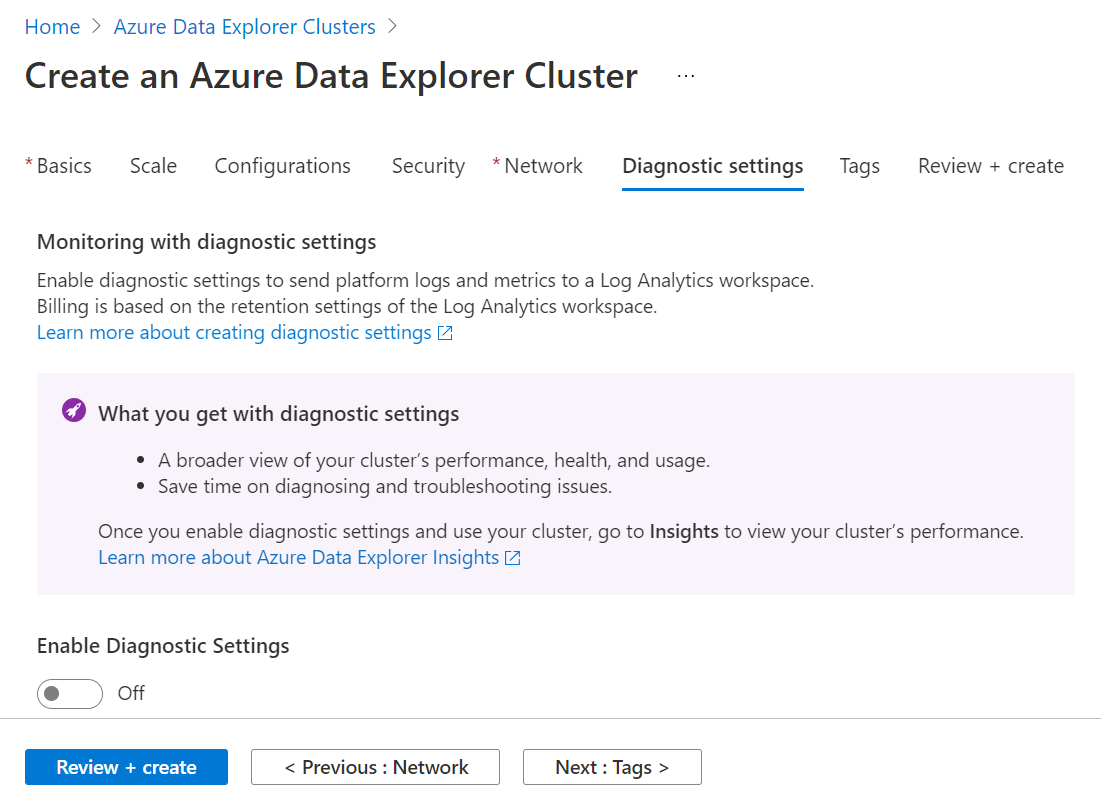
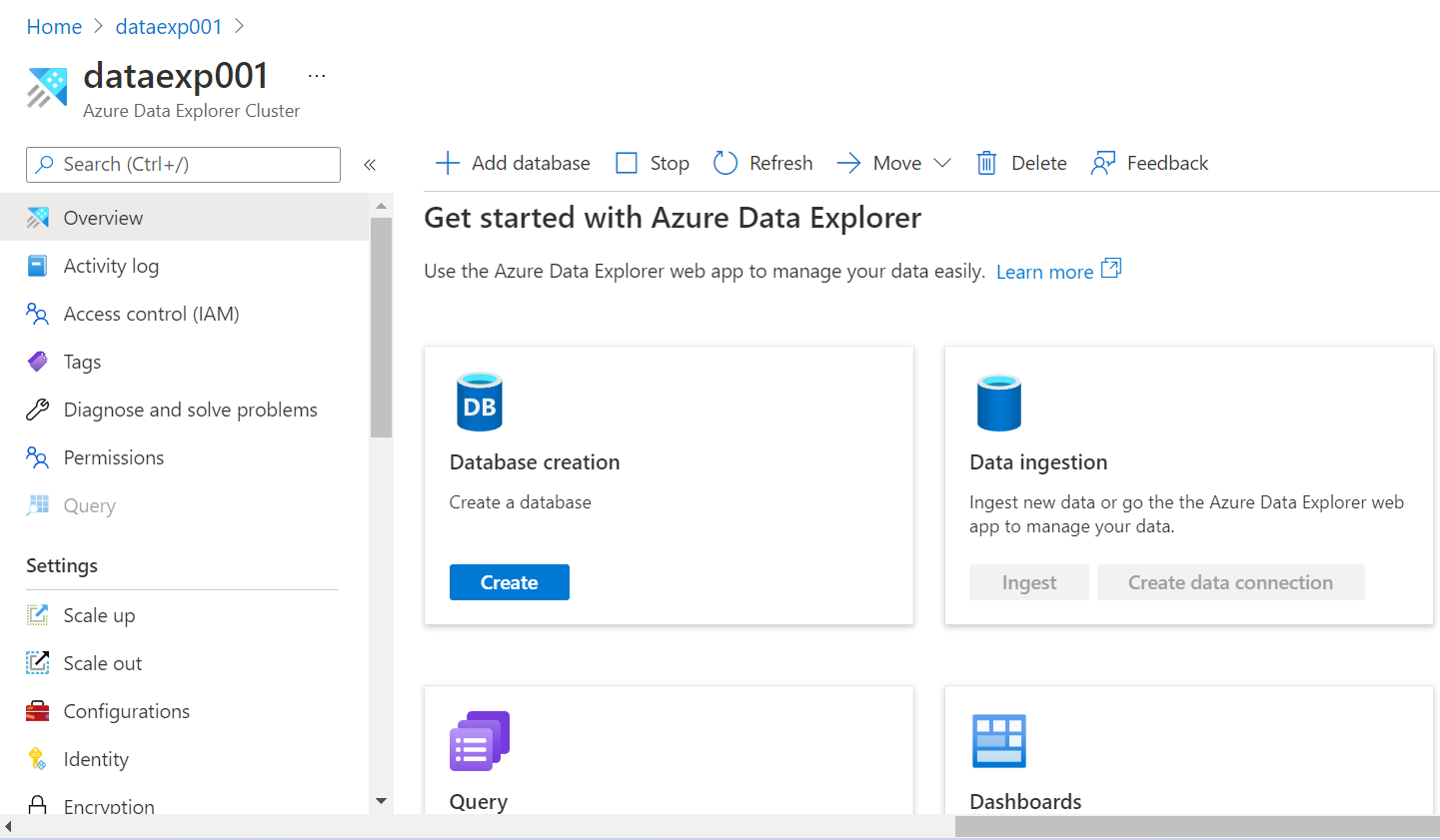
Now we need to optionally specify tags for this cluster if required. Then in the next step, we need to review the configuration that we have specified so far, and then we can click on the Create button to initiate the creation of this cluster. The cluster may take a few minutes to get created. Once the cluster gets created, navigate to this dashboard of this page and it would look as shown below after scrolling to the Getting Started section.
Once the cluster gets created, the first step is to create a database, and then create a table and other data objects in it. Once the database objects are in place, one can start data ingestion to populate these database objects. Once done, the cluster is ready to be accessed and/or registered with Azure Synapse.
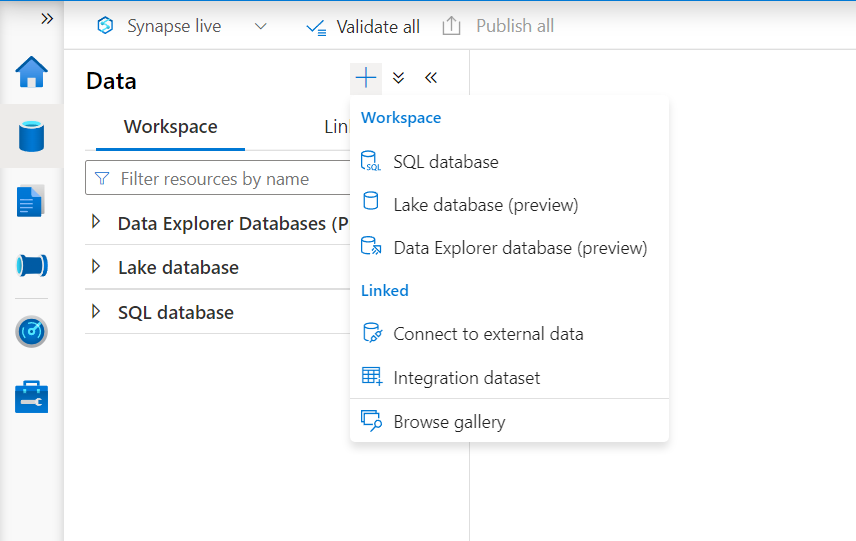
Before we start with the next step, it is assumed that an instance of Azure Synapse is already in place. Navigate to the Synapse Studio and click on the Data tab. Click on the plus sign and we would be able to see the options as seen below. Clicking on the data explorer database creates a new database in an existing data explorer pool. It is not the right option to integrate an external Azure Data Explorer cluster with Synapse. Instead, click on connect to external data option from the linked section as shown below.
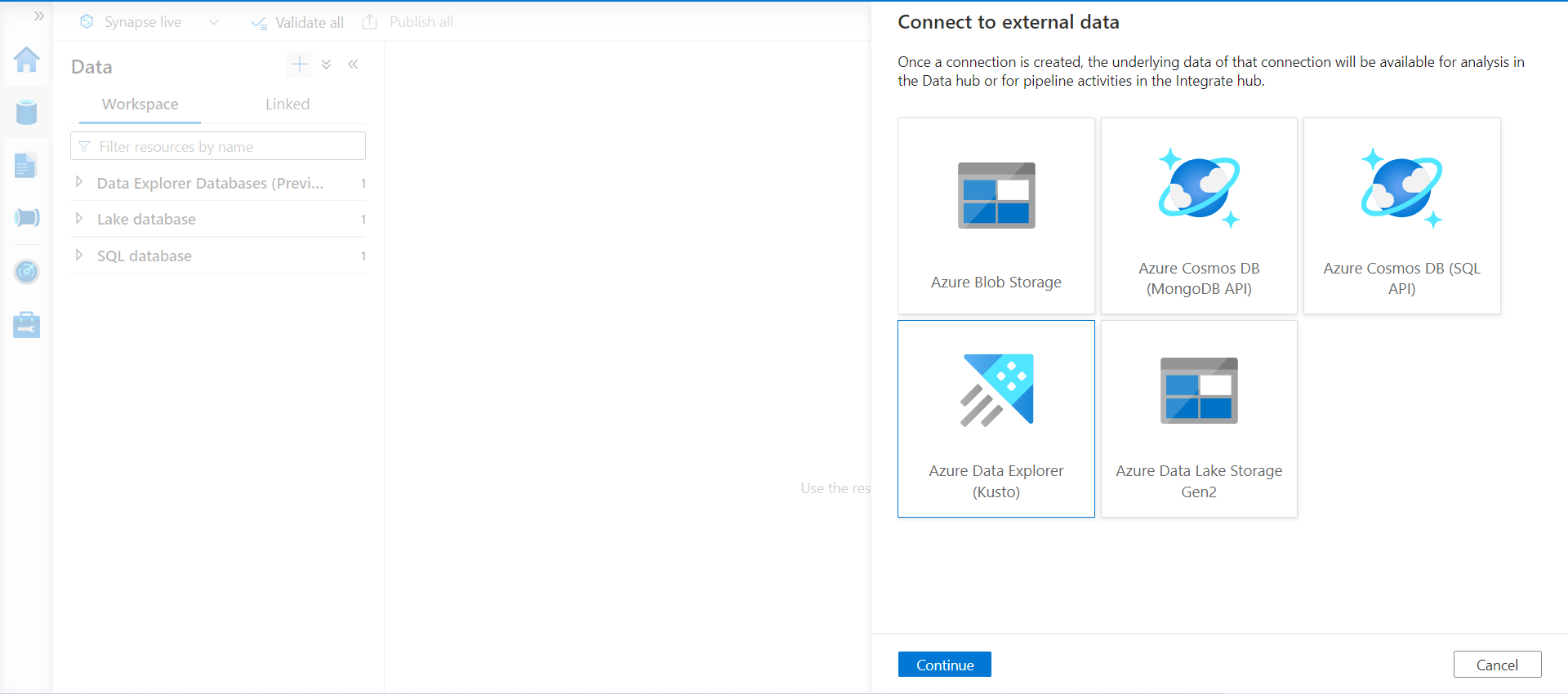
In the next step, we would be given the option to select one of the supported data sources. One of them is the Azure Data Explorer service, as shown below. Select the same and proceed to the next step.
This is the step where we can configure the registration and integration of the Azure Data Explorer cluster. Provide a new name for the linked service that would be created for the Azure Data Explorer service. Use the AutoResolvingIntegrationRuntime, and the authentication method as configured for the cluster, one should be able to find the cluster in the list of clusters. Provide the tenant id as well as the user or system managed identity name and credential and then click on the button to register the cluster. Provided the configuration values and security credentials are correctly configured, the Azure Data Explorer cluster would get registered, and one can start consuming the data from this cluster in Synapse using this linked service.
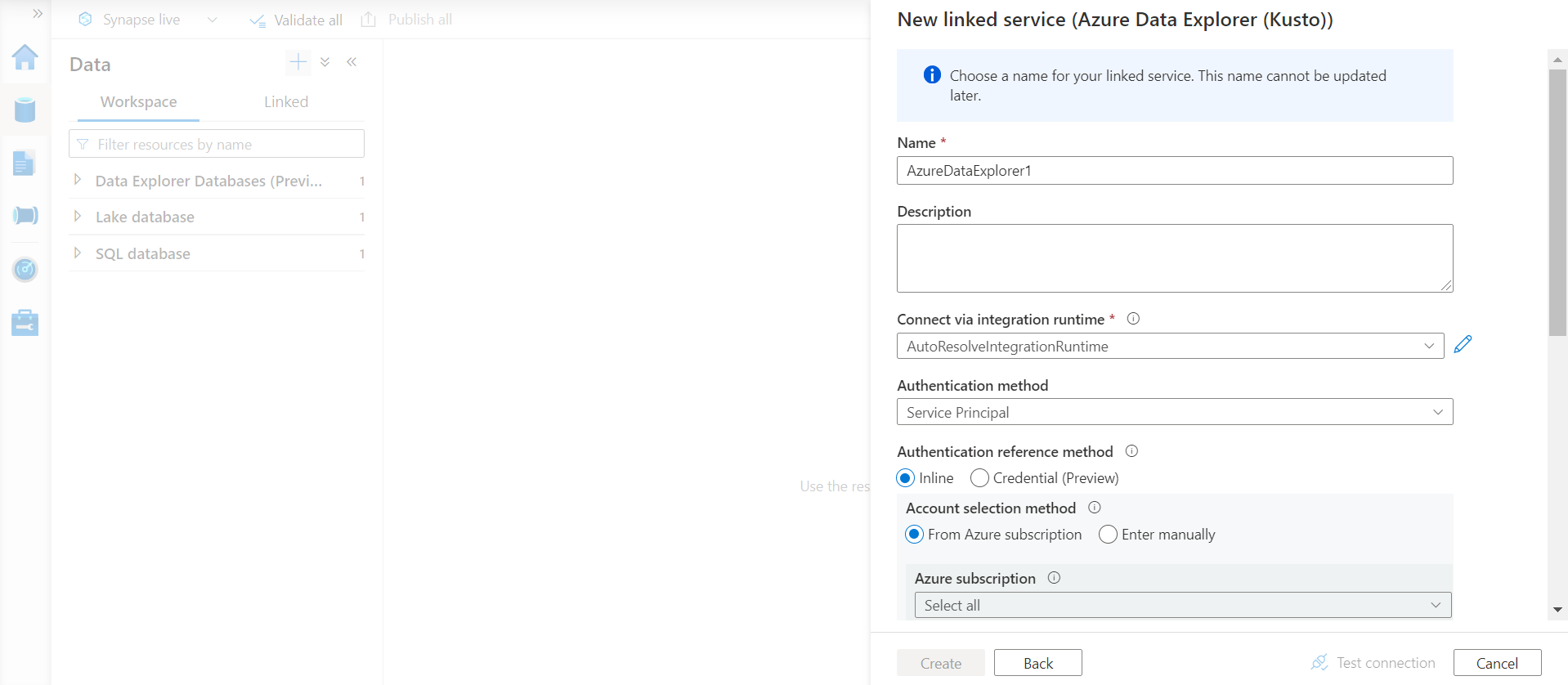
In this way, we can use an external Azure Data Explorer cluster with Azure Synapse Analytics service.
Conclusion
In this article, we learned how to create a new Azure Data Explorer cluster, create database objects and populate it with data from the dashboard interface, and then register it with Azure Synapse Analytics service as an external linked source to consume data from the cluster.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023