
In this article, we will learn how we can create tables in the Azure Synapse Lake Database instance first and bind it with data later.
Introduction
In the previous articles, (TOC below), we started with the concept of Lake House and learned the Azure Synapse Analytics ecosystem including Azure Synapse Lake Database. We created a Lake Database instance, created a new table on this instance, hosted data on the Azure Data Lake Storage account, and configured the tables to point to data hosted on the data lake. Then we learned how to configure and customize the schema of these tables and model relationships between these tables as required. This is one type of use-case where we have data in advance and tables on Azure Synapse are created to provide a frame to the datasets to consume it in a structured manner.
The other type of use-case is where the tables need to be created based on a specific domain and the data would arrive on the hosting location typically a data lake thereafter. These introduce two challenges – one is to model tables as per the needs of a specific domain and the other is to bind these tables to data when the data arrives. We will address these challenges in this article.
Creating tables from templates in Azure Synapse Lake Database
It is assumed that one has already created an Azure Synapse Lake Database instance as explained in the previous set of articles on the same subject. The order that we must follow in this case requires the creation of tables first. Typically, data modelers who have expertise in a specific domain can create data models of the relevant domain. Data Lake is a hosting location where data of various types and various domains is gathered in a common logical location. So organically there is a need to create data models of various domains. A gallery of data models which contains tables that relate to specific domains and sub-domains can prove to be very handy as it would reduce too much dependency on a data modeler to kick-start any data processing on the data stored in a data lake. While this is not a replacement or alternative for data modelers, but at least it reduces the bottleneck to kick-start any work and instead provides a jump start for analysts and developers to start their work while data modelers figure out the best model.
Azure Synapse Lake Database provides a mechanism to create tables from a pre-defined set of templates. To create our table using one such template, navigate to the Lake Database instance and click on the + sign as shown below, and select the menu item From template as shown below.

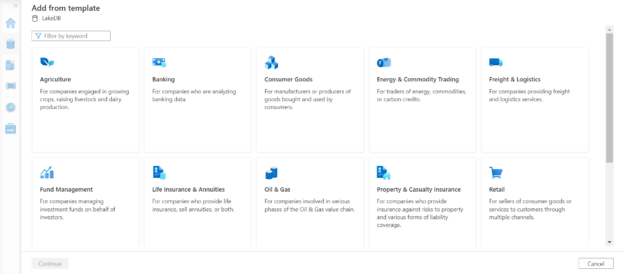
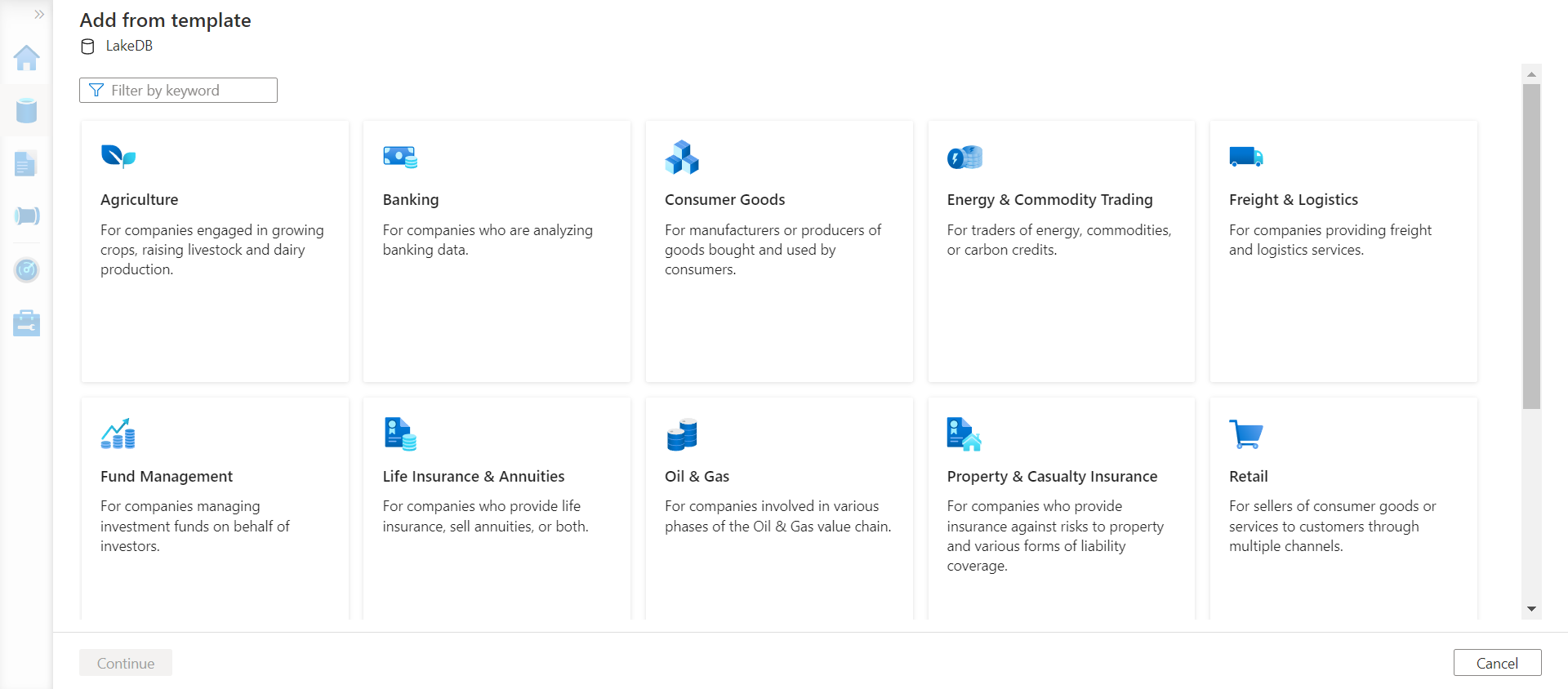
This option would open a new gallery of templates that are classified by domains like Agriculture, Banking, Consumer Goods, Energy and Commodity Trading, Freight and Logistics, Fund Management, Life Insurance and Annuities, Oil and Gas, Property and Casualty Insurance, Retail, and many more as shown below.
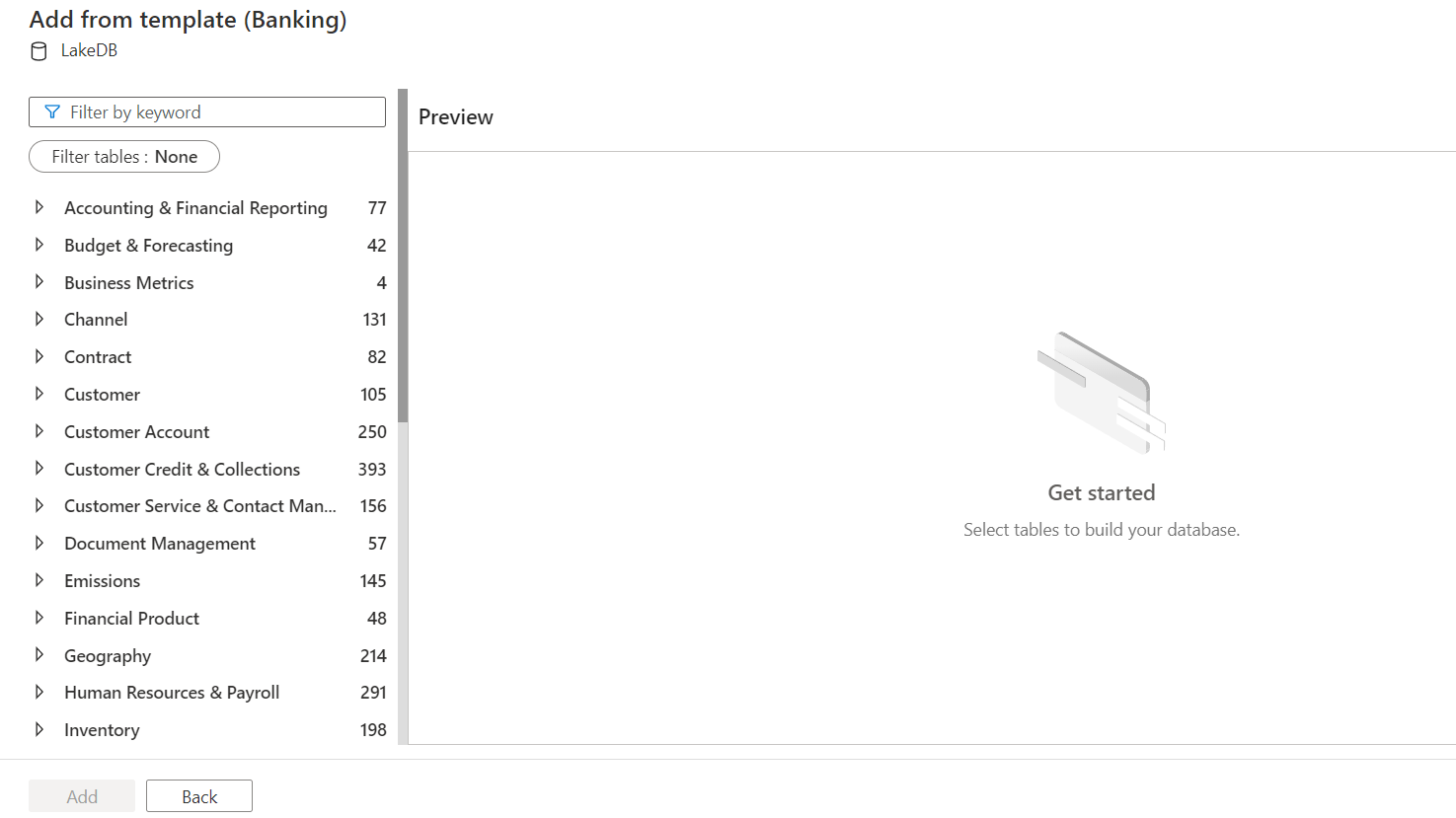
These are high-level domains and each of these can have many sub-domains. Let’s say we intend to create a Ledger table in which we will store ledger related data. This pertains to the banking domain, so click on Banking and it will offer the following set of sub-domains shown below. The number against each sub-domain shows the number of table definitions contained in it. Let’s select Accounting and Financial Reporting as Ledger is relevant to this sub-domain.
When we expand this sub-domain, we would find the Ledger table as shown below. We would be able to see the table definition as well as the fields that explains the purpose of this table.
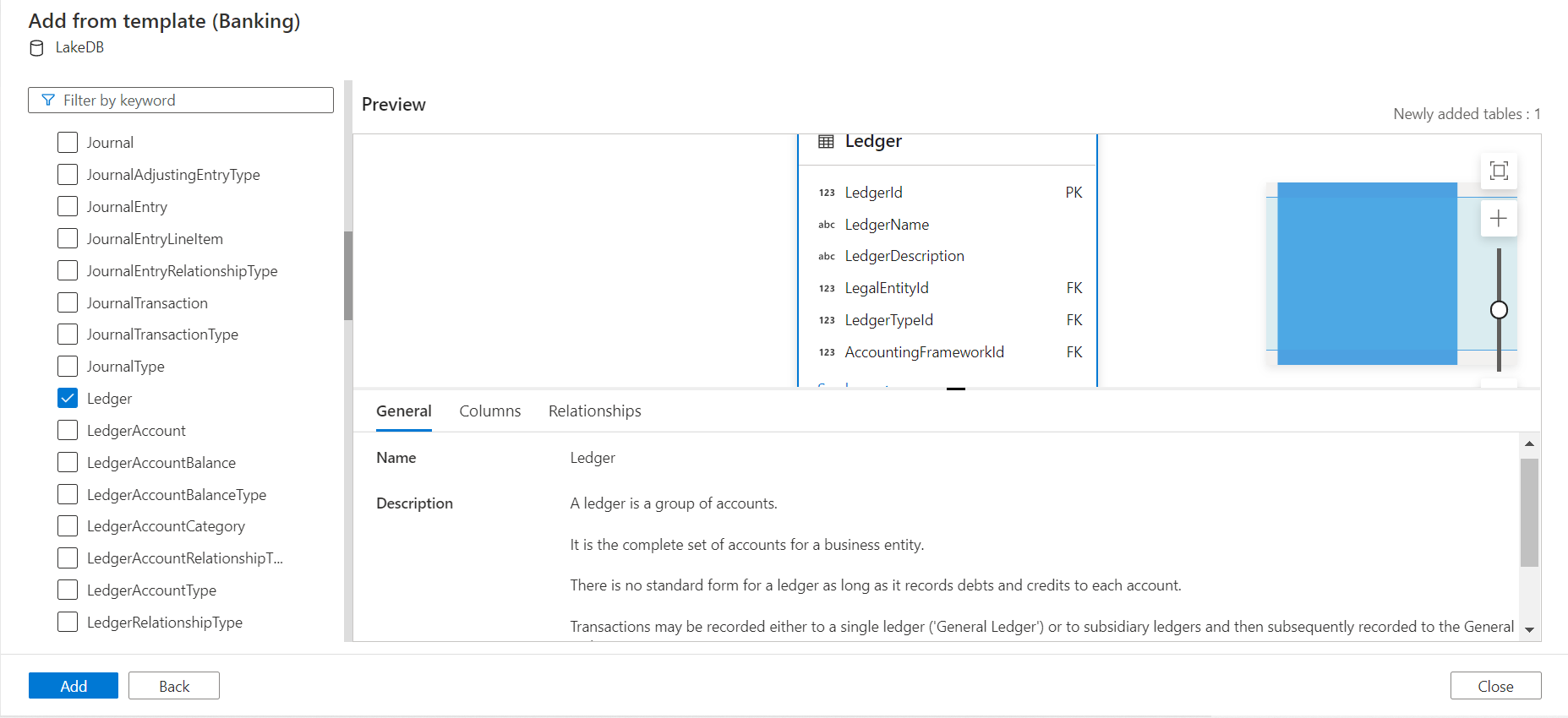
When we click on the Columns tab, we would be able to find the column definition as well as the description of the fields, which makes it easier for a technical person to understand the domain related aspects that are modeled into the table. We have the option to select or de-select any fields as required.
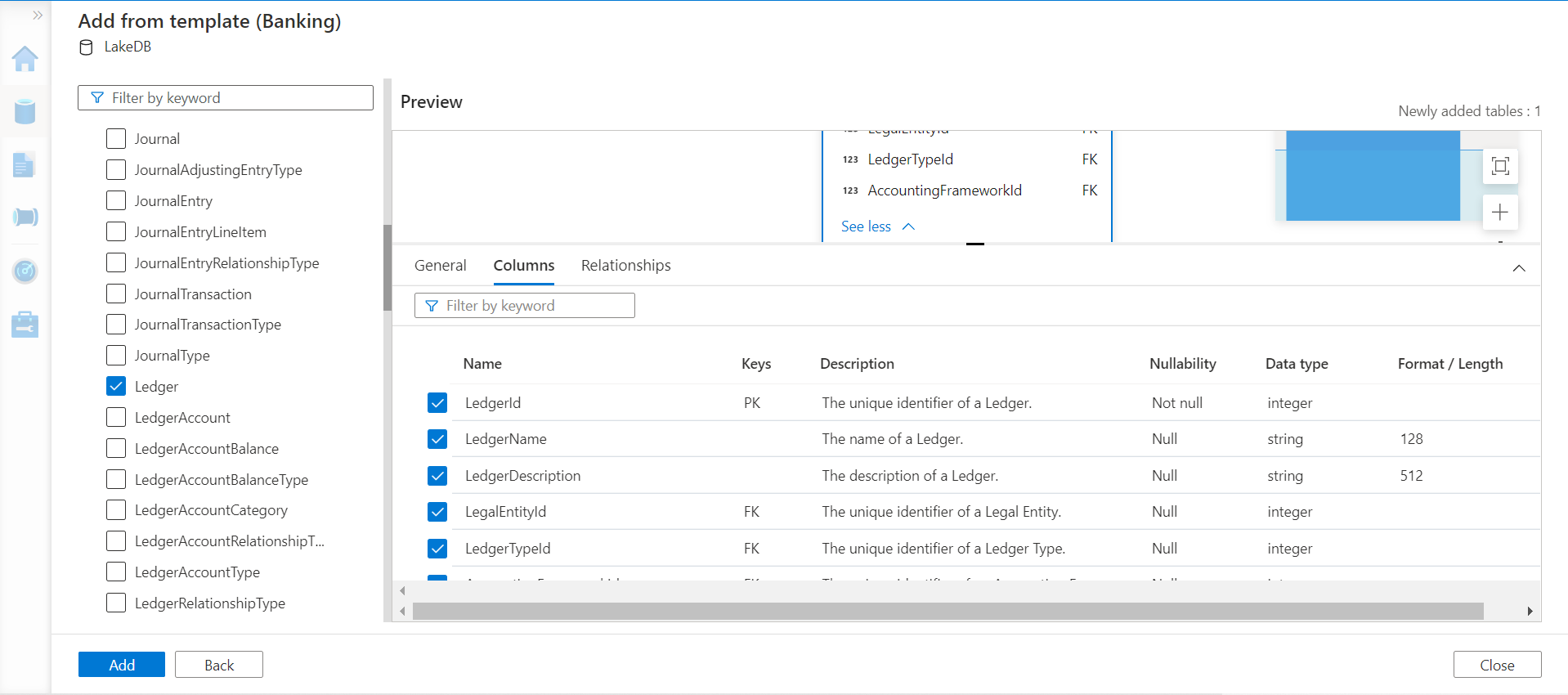
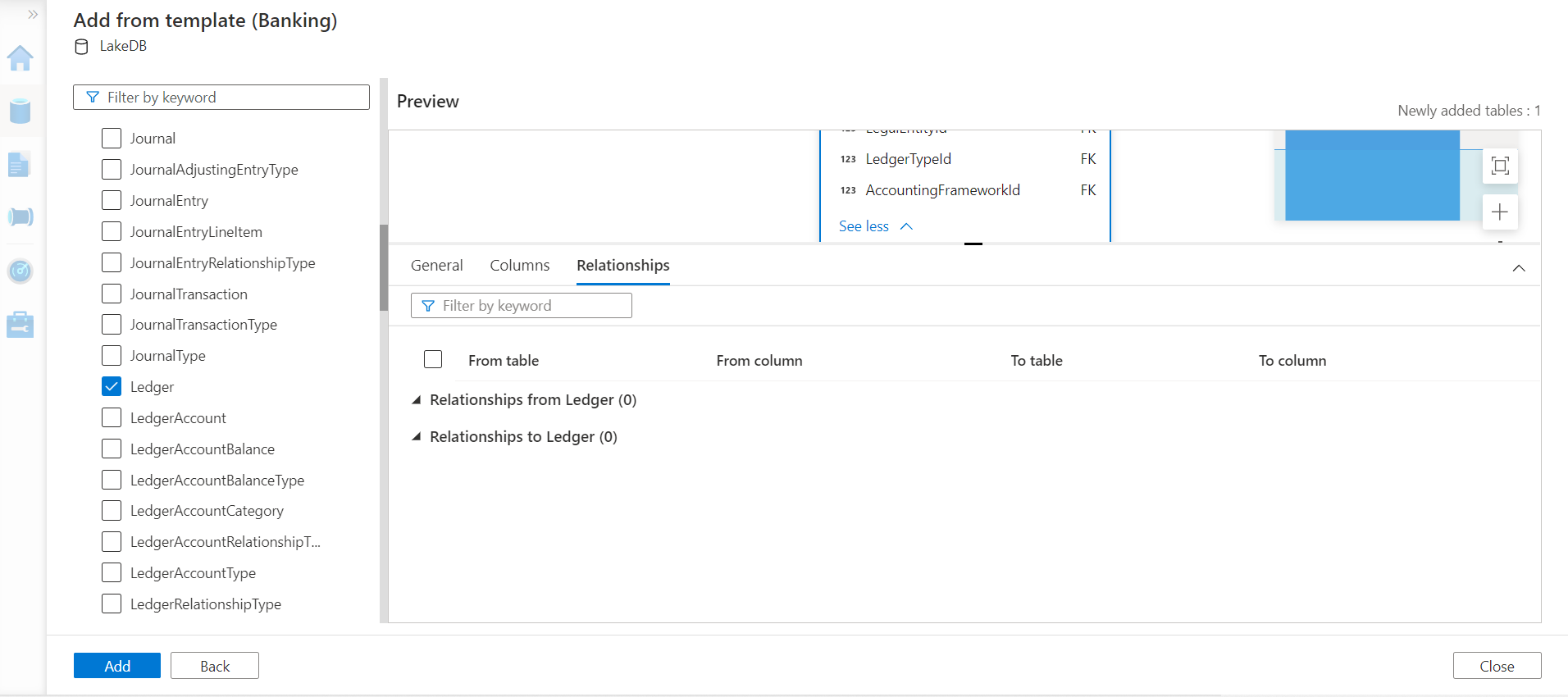
As we have seen in the previous article on Azure Synapse Lake Database, the Relationships tab tells us the inward and outward dependency of the table. Here this table seems to be independent, so we do not need to add any related tables for now. Click on the Add button to add the table to the instance.
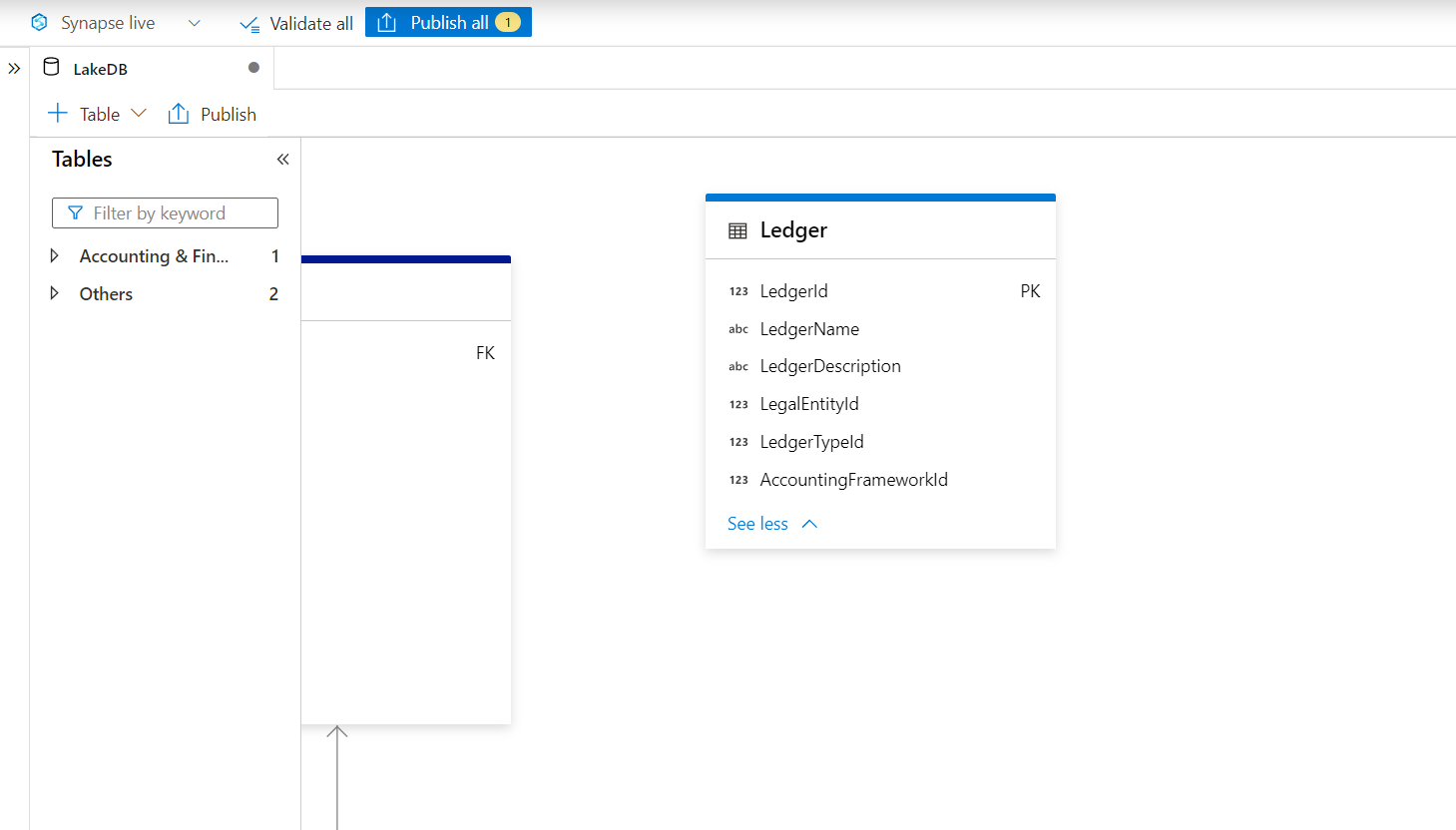
Once the table is added, it would look as shown below. This completes the first part of the exercise where we had to create the schema definition first before the data arrives.
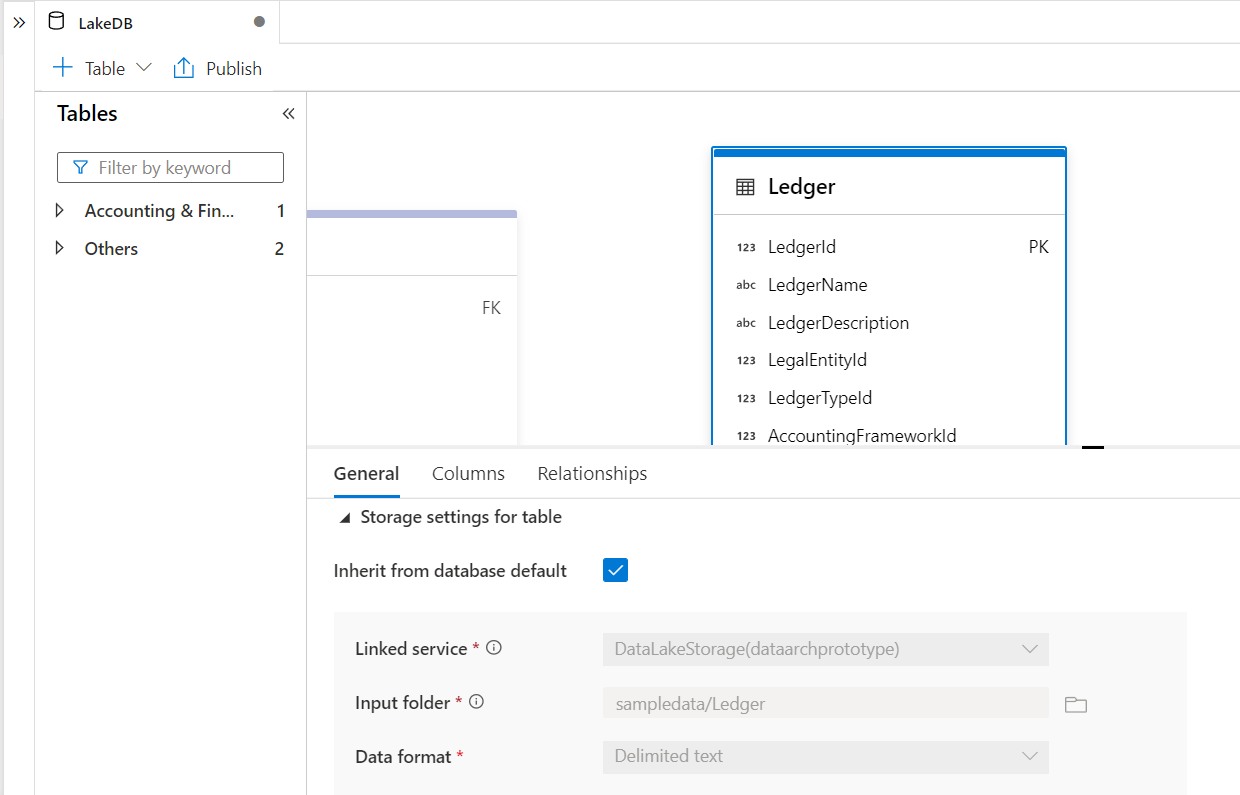
Click on the table as we would be able to view the general properties and storage related settings of this table. By default, as this table is created from a template, it would pick up the configuration of the database and would get stored on the Azure Data Lake Storage which is the configuration we have used for the Azure Synapse Lake Database instance. These storage settings cannot be changed. The input folder value shows the path from where the table expects to fetch data when a request is made to access data on this table. This path does not exist on the Azure Data Lake Storage for now.
The rest of the data formatting or parsing related properties can be modified as shown below. It is important to understand the settings that can be modified and cannot be modified for tables created from templates so that they are accurately configured when tables are created from templates.
Based on the fields in the ledged, we need some sample data now. This data may arrive from various data repositories but would need to have the same schema as defined in the table for the table to source data. To simulate this situation, we can create a CSV file with a few records in it. The fields would be parsed in the same ordinal position and order in which it is defined in the table. Shown below is a sample of a few records in the CSV file.
Navigate to the Azure Data Lake Storage account and create the path and folder that the table is expecting and upload the CSV file in this location as shown below. The name of the CSV file is not of much importance in this case.
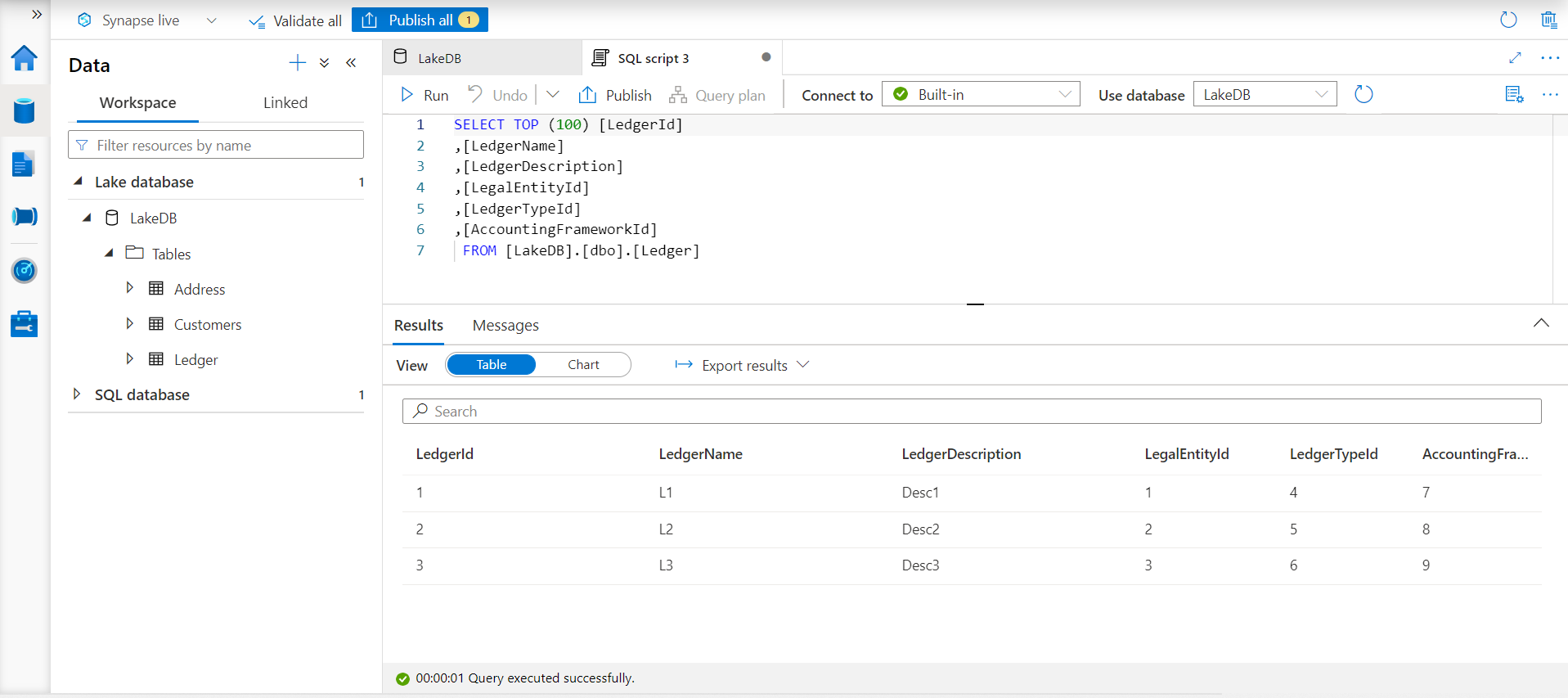
This completes the second half of our exercise, where the data would arrive after the schema has been defined in the Azure Synapse Lake Database. In practice, this data would be populated using data pipelines and data flows supported by Azure Synapse Analytics or Azure Data Factory. To test whether the approach and configuration work, navigate back to the Azure Synapse Lake Database instance and open the table. Using the actions ellipsis and select the option to SELECT top 100 rows. This would open a new screen as shown below. Click on the Run menu to execute the SQL script, and if everything works as expected, we should be able to see the same data in the results pane as shown below.
In this way, we can use templates in Azure Synapse Lake Database to jump-start the data modeling process and quickly source data using the defined data models.
Conclusion
In this article, we learned about two use-cases where data models are defined first and last. We explored the templates gallery in Azure Synapse Lake Database, created a table from it, and then bound it with data hosted on Azure Data Lake Storage.

She has a deep experience in designing data and analytics solutions and ensuring its stability, reliability, and performance. She is also certified in SQL Server and have passed certifications like 70-463: Implementing Data Warehouses with Microsoft SQL Server.
View all posts by Gauri Mahajan
- Oracle Substring function overview with examples - June 19, 2024
- Introduction to the SQL Standard Deviation function - April 21, 2023
- A quick overview of MySQL foreign key with examples - February 7, 2023