This article provides an overview of MySQL Cluster in a simple understandable manner suitable for both database beginners and professionals.
Read more »
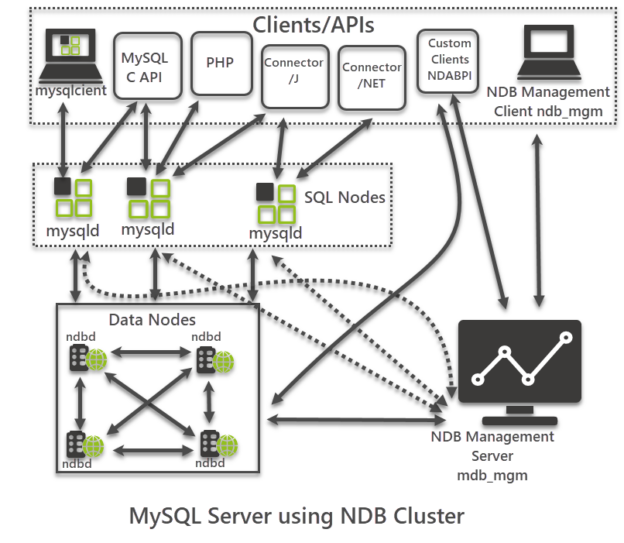
This article provides an overview of MySQL Cluster in a simple understandable manner suitable for both database beginners and professionals.
Read more »
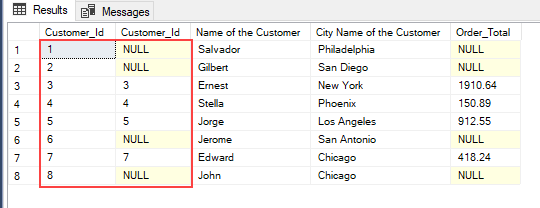
In this SQL cheat sheet, we’ll look at sample SQL queries that can help you learn basic T-SQL queries as quickly as possible.
Read more »
This article will explore the use of the CROSSTAB function in PostgreSQL.
Read more »
In this article, we will learn how to create PostgreSQL stored procedures using PSQL.
Read more »
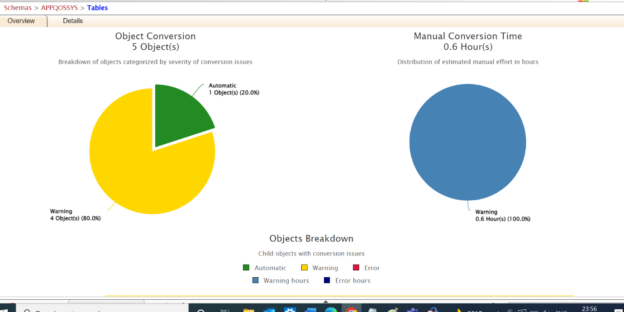
Data Modernization has become important nowadays. Organizations are looking into options to migrate their on-premises database to a cloud and some other heterogeneous databases. In this article, we will see the strategy and options to migrate the Oracle database to the Azure SQL database. We will be leveraging the SSMA tool for migrating the database.
Read more »
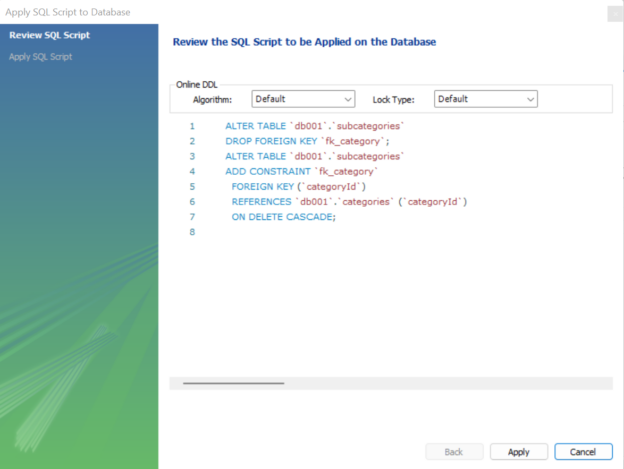
In this article, we will learn how to work with MySQL foreign keys with a few examples.
Read more »
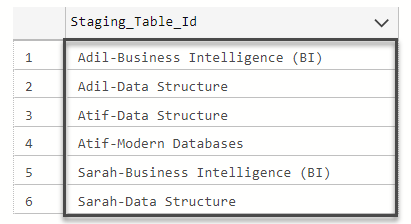
This article talks about the commonly used scenarios of SQL Select Distinct in an easily understandable format equally suitable for beginners and professionals.
Read more »
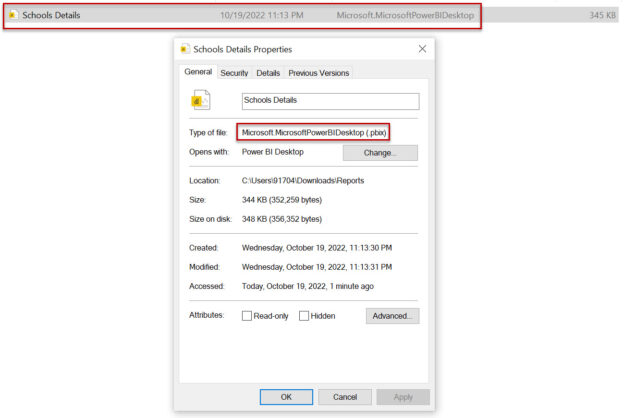
Microsoft Power BI is a very popular data visualization tool. In this article, we will discuss the most frequently asked Power BI Interview Questions and Answers.
Read more »
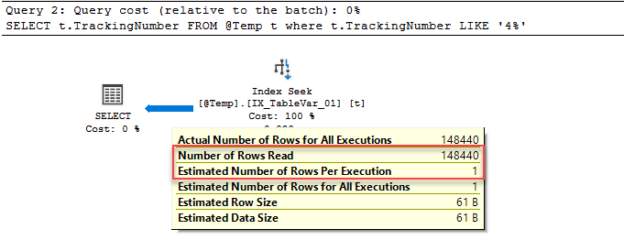
In this article, we are going to make a SQL practice exercise that will help to prepare for the final round of technical interviews of the SQL jobs.
Read more »
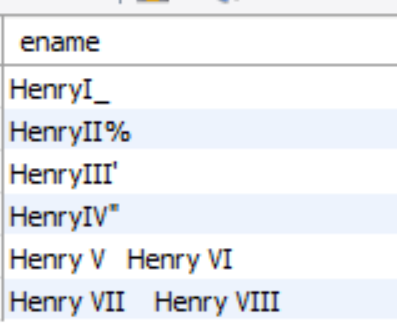
This article will provide an introduction to SQL escape characters for using special characters and their characteristics.
Read more »
This article will make you learn the Postgres Coalesce command with examples.
Read more »
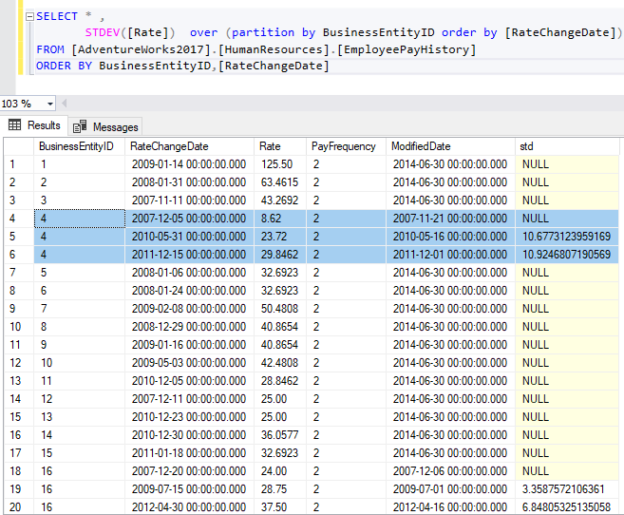
This article will show the SQL standard deviation function with several examples.
Read more »
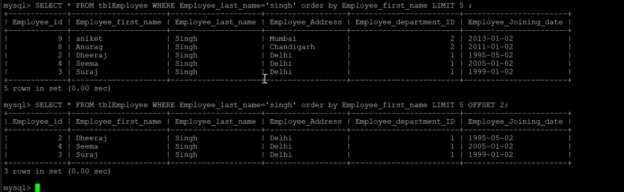
Today, I am going to explain how to use the SQL LIMIT clause to limit output values. We all know RDBMS systems are one of the popular ways to store, protect, access, and analyze data in a structured way. We can store enormous sizes of data and then further can access them with the help of SQL language to get our desired output to analyze it. SQL stands for Structured Query Language which is used to perform activities like creating, modifying, and accessing data from the databases hosted on RDBMS systems like SQL Server or MySQL, etc. This article will explain one of the SQL query statements LIMIT which we use to limit the number of records returned in the output result.
Read more »
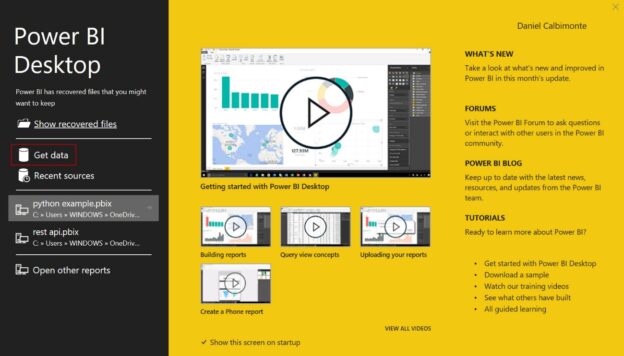
In this article, we will learn how to create Power BI Reports. This article is created for newbies to start the Power BI world with a simple example. We will connect to SQL Server, show how to transform data from SQL Server in Power BI, and then we will create some reports, and play with the options available in Power BI.
Read more »

If you are working on SQL programming or learning SQL or how to write queries and looking to test your knowledge or prepare for any SQL interview, the below article can help you.
Read more »
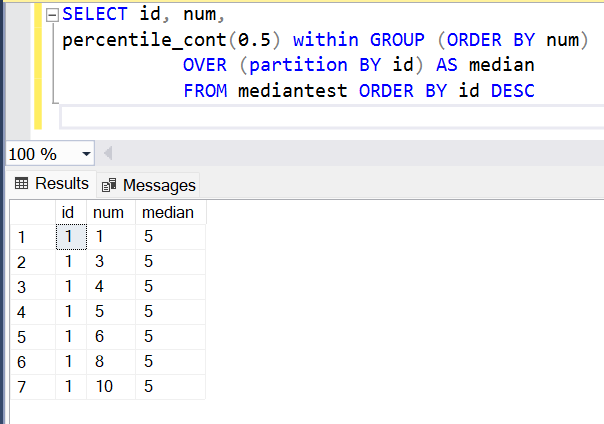
In this article, we will learn how to implement the median functionality and wrap it into a SQL median function
Read more »

SQL Server provides various dates and time functions for different needs. In this article, we will focus on SQL subtract date functions with various examples.
Read more »
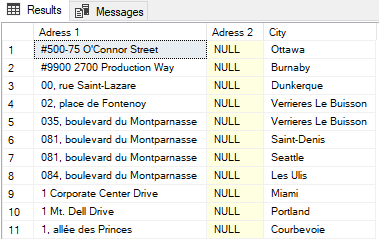
In this article, we are going to learn some best practices that help to write more efficient SQL queries.
Queries are used to communicate with the databases and perform the database operations. Such as, we use the queries to update data on a database or retrieve data from the database. Because of these functions of queries, they are used extensively by people who also interact with databases. In addition to performing accurate database operations, a query also needs to be performance, fast and readable. At least knowing some practices when we write a query will help fulfill these criteria and improve the writing of more efficient queries.
Read more »
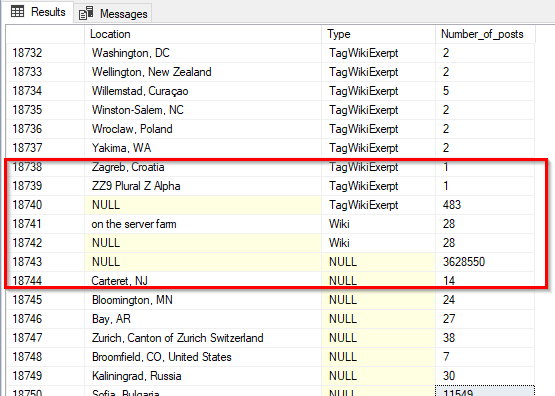
This article briefly explains the SQL group by clause, when it should be used, and what we should consider when using it.
Read more »

This article will explain the difference between SQL and MySQL. Many people get confused between several database terms like SQL, MySQL, SQL Server, or other SQL-related phrases. If you are a database professional, then you should be aware of the difference between SQL and MySQL or other phrases which have SQL words included like PostgreSQL, Cloud SQL, TSQL, etc. Most of these terms are divided between a query language and database software like TSQL and SQL are query languages whereas MySQL, SQL Server, and PostgreSQL are database software.
Read more »
This article is a SQL Server Tutorial. If you want to learn how to install and start with SQL Server from 0, this is the place to start. We will teach you to install SQL Server, start your first queries, and explain the basics to start with SQL Server Integration Services (SSIS), SQL Server Reporting Services (SSRS), SQL Server Analysis Services (SSAS), Data Quality Services (DQS), Master Data Services (MDS) and Azure and more.
Read more »
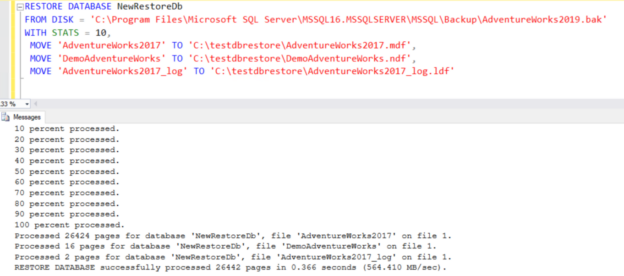
This article explores the RESTORE FILELISTONLY command in SQL Server with examples.
Performing a database backup is an integral part of a DBA’s job. Backups are taken to ensure that data can be recovered in an emergency. There are different restore mechanisms, and the SQL Server DBA needs to understand them to make the right decision in each situation.
Read more »
This article will show how to get data from Azure SQL in the Serverless Python app.
Read more »
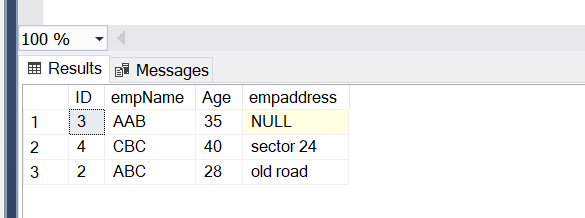
This article aims to explain the WHERE, GROUP By, and HAVING clauses in detail. Also, we will see the difference between WHERE and HAVING with examples.
Read more »
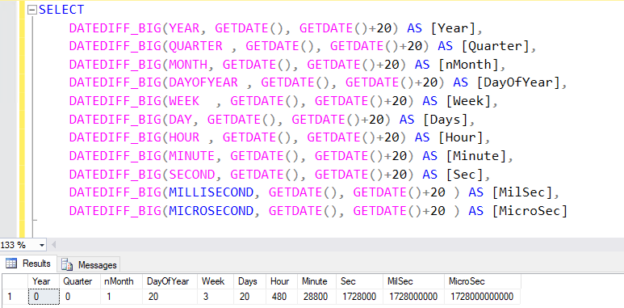
This article explores SQL Server functions to add or subtract dates in SQL Server.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy