
Description
Keeping track of our SQL Server Agent jobs is a very effective way to control scheduling, failures, and understand when undesired conditions may be manifesting themselves. This is a brief journey towards a solution that provides us far greater insight into our jobs, schedules, and executions than we can glean from SQL Server by default.
Introduction
When we consider SQL Server performance metrics for use by database professionals, a long list comes to mind:
- Waits
- CPU
- Memory utilization (buffer cache, plan cache, server memory)
- Contention (locks, deadlocks, blocking)
- I/O (reads, writes by database/file/object)
- Many, many more…
A metric often overlooked is job performance. The alert we most often respond to is a failed job. When a backup, warehouse load, or maintenance task fails, we are alerted and know that some response is needed to ensure we understand why and how it failed.
Job failures are not always avoidable, but our goal is to prevent systemic or catastrophic failures. If we discover that an important ETL process is taking 23 hours to complete per day, then it is obvious we need to revisit the job, the work it performs, and rearchitect it to be more efficient. At that time, though, it is too late. We need to keep our important data flowing, but at the same time ensure that the long-running process doesn’t slow to the point of being ineffective, or fail.
Our goal is to take job-related metadata and run statistics from MSDB and compile them into a simple but useful store of reporting data that can be trended, monitored, and reported on as needed.
What Are the Benefits of Job Performance Tracking?
The immediate benefits of tracking this sort of data are obvious in that we can keep an eye out for very long-running jobs and (hopefully) catch a problematic situation before it becomes a 2 am wake-up call!
There are additional insights we can glean from this data that can make it even more useful, such as:
-
Locate short-running jobs that run unusually fast, indicating that they are not performing the expected workload. For example, if the full database backup of a 10TB database completes in 5, we know something is very wrong. Especially if the average runtime of this job is typically 2 hours!

- Trend job runtime and predict how long jobs will take in the future. This allows us to predict when we may need to evaluate the efficiency of current processes before they become problematic.
- Track individual job steps to focus on larger jobs and which parts might need attention.
- Aggregate job performance across a sharded or multi-server environment to determine overall efficiency.
- Improve our ability to schedule new jobs, by being able to easily view job scheduling data on a server.
- Allow us to better plan server downtime by reviewing job scheduling and runtime data. This provides us with information on what jobs could be missed (or need to be run later) in the event that a server is brought down. This could also be useful after an unexpected outage, allowing us to review any missed or failed jobs en masse.
With some creativity, other uses can be concocted for this data, including tracking SSIS package execution, replication performance, backups, index maintenance, ETL processes, warehouse data loads, and more!
Why Doesn’t Everyone Do This?
As with many alerting, monitoring, or trending processes, we often don’t see a need for them until something breaks and a need arises. Until a job or related process fails, the need to pay attention to runtimes may not be realized.
To make matters more difficult, SQL Server does not provide a spectacular way to monitor and trend job progress and results over time. SQL Server Agent contains a GUI that can show us details on recent job outcomes, as well as the ability to monitor jobs in progress:
From the SQL Server Agent menu, we can click on Job Activity Monitor in order to view the up-to-the-minute status of each job. From the jobs menu, the history for all or any subset of jobs can be viewed, as well as for any single job:
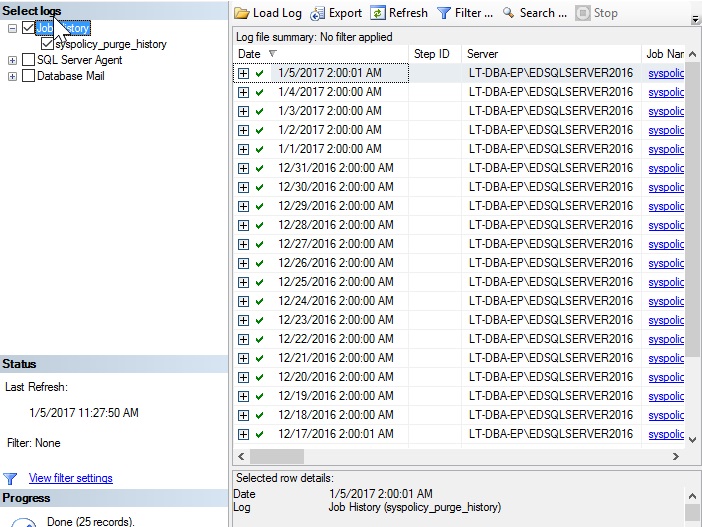
This information is useful, but its utility is limited in a number of ways:
- Job history is stored in MSDB for a limited amount of time, based on a server’s configuration. Metrics about previous job runs may be removed once past a set retention period.
- There are few ways to trend or view any metrics over a period of time.
- Viewing the combined job history for multiple servers is not intuitive.
- We have little ability to customize how this data is presented to us.
An alternative to navigating job history data via the GUI is to use a handful of views within MSDB, each of which provides data on job configuration, job schedules, and job history:
- MSDB.dbo.sysjobs: Provides a list of all jobs on the local SQL Server, along with relevant metadata.
- MSDB.dbo.sysschedules: Contains all job schedules defined on the local server, along with their details.
- MSDB.dbo.sysjobhistory: Contains a row for each job and job step that is executed on the local server.
- MSDB.dbo.sysjobschedules: Contains a row per job/schedule relationship.
- MSDB.dbo.sysjobactivity: Contains details on recent job activity, including accurate future runtimes.
These views provide valuable information but are not easy to read and consume. While Microsoft provides documentation on their purpose and contents, many of the data types are suboptimal, and the mixed contents of sysjobhistory are not intuitive.
For example, dates and times are stored as integers. 03:15:05 is stored as 31505 and 9/23/2016 is 20160923. Job run duration is stored as an integer in the format HHMMSS, such that 85 seconds would appear as 125 (one minute and twenty-five seconds). Job schedules are stored using numeric constants to represent how often they run, run time, and run intervals.
Given the unintuitive interface for pulling job history data, it’s often seen as not worth the time to pull, convert, and present the data unless absolutely needed. Alternatively, enterprise job scheduler software can be purchased that will manage SQL Server Agent jobs. While convenient, software costs money and not all companies can or want to spend resources on this sort of software.
Building a Job Performance Tracking Solution
Given the constraints presented thus far, we can choose to build our own solution for collecting and storing job performance metrics. Once collected, reporting on them becomes a simple matter of defining what we want to see and writing some simpler queries to crunch our data appropriately.
The steps we will follow to create a self-sufficient solution to the problem presented above are:
- Create new tables that will store job performance metrics.
- Create a stored procedure to collect job metrics and store them in the tables above.
- Clean up old data, as prescribed by whatever retention rules we deem necessary.
- Schedule a job to regularly collect our job performance data.
- Create reports that consume this data and return useful results (see the next section).
As we build this solution, feel free to consider ways of customizing it. Add or remove columns or tables that you don’t think are important to your needs and adjust processes to fit the data you need. The beauty of any hand-built process is the ability to have complete control over customization and implementation!
Tables
We’ll create four tables to store data pertinent to our metrics. Two will be dimension tables that include basic information about jobs and schedules. The other two will contain job and job step execution results. These tables are structured like warehouse tables in order to facilitate easier consumption by reporting products or processes, though you are free to name & structure based on whatever standards you typically follow.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE dbo.dim_sql_agent_job ( dim_sql_agent_job_Id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_dim_sql_agent_job PRIMARY KEY CLUSTERED, Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL, Sql_Agent_Job_Name NVARCHAR(128) NOT NULL, Job_Create_Datetime DATETIME NOT NULL, Job_Last_Modified_Datetime DATETIME NOT NULL, Is_Enabled BIT NOT NULL, Is_Deleted BIT NOT NULL ); CREATE NONCLUSTERED INDEX IX_dim_sql_agent_job_Sql_Agent_Job_Id ON dbo.dim_sql_agent_job (Sql_Agent_Job_Id); |
This table stores a row per Agent job, with the Sql_Agent_Job_Id being pulled directly from MSDB.dbo.sysjobs. Since this is a GUID, we choose to create a surrogate key to represent the clustered primary key on the table to help improve performance when writing to this table.
Persisting this data allows for retention of job data, even if a job is disabled or deleted on the server. This can be useful for understanding how a job previously performed, or how a new and old version of a process compare.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE dbo.dim_sql_agent_schedule ( Schedule_Id INT NOT NULL CONSTRAINT PK_fact_sql_agent_job_schedule PRIMARY KEY CLUSTERED, Schedule_Name NVARCHAR(128) NOT NULL, Is_Enabled BIT NOT NULL, Is_Deleted BIT NOT NULL, Schedule_Start_Date DATE NOT NULL, Schedule_End_Date DATE NOT NULL, Schedule_Occurrence VARCHAR(25) NOT NULL, Schedule_Occurrence_Detail VARCHAR(256) NULL, Schedule_Frequency VARCHAR(256) NULL, Schedule_Created_Datetime DATETIME NOT NULL, Schedule_Last_Modified_Datetime DATETIME NOT NULL ); CREATE NONCLUSTERED INDEX IX_dim_sql_agent_schedule_Schedule_Last_Modified_Datetime ON dbo.dim_sql_agent_schedule (Schedule_Last_Modified_Datetime); |
Similar to the previous dimension table, this one stores a row per schedule, as found in MSDB.dbo.sysschedules, with schedule_id being the unique identifier per schedule. This data is somewhat optional in that we do not need schedule details in order to understand when jobs run, for how long, and their results, but the added information is useful for understanding what schedules are used, and for what jobs.
If desired, we could also create a linking table that illustrates the relationships between jobs and schedules, allowing us to understand when jobs are supposed to run, which schedules they run under, and predict future job schedules. This information is also not needed in order to fully comprehend job history but could be useful for predicting the best times for planned maintenance, outages, or to effectively schedule new jobs. Data for this task can be pulled from MSDB.dbo.sysjobschedules and is a linking table that contains a single row per job-schedule pairing (a one-to-many relationship). We can easily create a small table to store and maintain this data:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE dbo.fact_sql_agent_schedule_assignment ( fact_sql_agent_schedule_assignment_id INT NOT NULL IDENTITY(1,1) CONSTRAINT PK_fact_sql_agent_schedule_assignment PRIMARY KEY CLUSTERED, Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL, Schedule_Id INT NOT NULL, Next_Run_Datetime DATETIME NULL ); CREATE NONCLUSTERED INDEX IX_fact_sql_agent_schedule_assignment_Sql_Agent_Job_Id ON dbo.fact_sql_agent_schedule_assignment (Sql_Agent_Job_Id); |
A surrogate key is used as a more reliable clustered index, but a combination of job_id and schedule_id would also work. Next_Run_Datetime is optional, but could be handy under some circumstances. Note that the accuracy of this column will be based on how frequently this data is updated. If the job runs more often than the collection of our job performance data, then this column will not always be up-to-date.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE TABLE dbo.fact_job_run_time ( Sql_Agent_Job_Run_Instance_Id INT NOT NULL CONSTRAINT PK_fact_job_run_time PRIMARY KEY CLUSTERED, Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL, Job_Start_Datetime DATETIME NOT NULL, Job_End_Datetime AS DATEADD(SECOND, job_duration_seconds, Job_Start_Datetime) PERSISTED, Job_Duration_Seconds INT NOT NULL, Job_Status VARCHAR(8) NOT NULL ); CREATE NONCLUSTERED INDEX IX_fact_job_run_time_job_start_time ON dbo.fact_job_run_time (Job_Start_Datetime); CREATE NONCLUSTERED INDEX IX_fact_job_run_time_Sql_Agent_Job_Id ON dbo.fact_job_run_time (Sql_Agent_Job_Id); |
Now we can introduce the table where job run statistics will be stored. Each row represents a single job run for a given job_id, when it started, its duration, and its completion status. The end time is a computed column, as we can determine it easily once the start time and duration are known. The status will contain a friendly string indicating the job result: Failure, Success, Retry, or Canceled. Note that the schedule that triggered the job is not referenced here. As a result, schedule data is not required for this to work but is nice to have in general.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
CREATE TABLE dbo.fact_step_job_run_time ( Sql_Agent_Job_Run_Instance_Id INT NOT NULL CONSTRAINT PK_fact_step_job_run_time PRIMARY KEY CLUSTERED, Sql_Agent_Job_Id UNIQUEIDENTIFIER NOT NULL, Sql_Agent_Job_Step_Id INT NOT NULL, Job_Step_Start_Datetime DATETIME NOT NULL, Job_Step_End_Datetime AS DATEADD(SECOND, Job_Step_Duration_seconds, Job_Step_Start_Datetime) PERSISTED, Job_Step_Duration_seconds INT NOT NULL, Job_Step_Status VARCHAR(8) NOT NULL ); CREATE NONCLUSTERED INDEX IX_fact_step_job_run_time_Sql_Agent_Job_Id_Sql_Agent_Job_Step_Id ON dbo.fact_step_job_run_time (Sql_Agent_Job_Id, Sql_Agent_Job_Step_Id); CREATE NONCLUSTERED INDEX IX_fact_step_job_run_time_job_step_start_time ON dbo.fact_step_job_run_time (Job_Step_Start_Datetime); |
This table is similar to our last one, and stores the metrics for individual job steps. Completed job data is omitted from this data as it is stored in the other table. In addition, steps in progress are not recorded—only those that have completed. Depending on your use-case, there could be value in combining job and job step data into a single table, much like how MSDB.dbo.sysjobhistory stores it. Here, we choose to separate them as we may not always want individual step data, and having to carve this out from a larger data set could be a nuisance in terms of report/script development and performance.
Metrics Collection Stored Procedure
Now that we have built a number of custom tables to store our job performance data, the next step is to create a process that pulls the data from MSDB, transforms it into a more user-friendly form, and stores it in those tables. We will manage the gathering of data for each table separately, allowing for easier customization and testing of our code.
|
1 2 3 4 5 6 |
CREATE PROCEDURE dbo.usp_get_job_execution_metrics AS BEGIN SET NOCOUNT ON; |
The name is arbitrary, but this seems descriptive enough. No parameters are used by the stored procedure as I intentionally want to keep this as simple as possible. If you have a need to pass in additional configuration or timing options, doing so should be relatively easy.
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @Schedule_Data_Last_Modify_Datetime DATETIME; SELECT @Schedule_Data_Last_Modify_Datetime = MAX(dim_sql_agent_schedule.Schedule_Last_Modified_Datetime) FROM dbo.dim_sql_agent_schedule; IF @Schedule_Data_Last_Modify_Datetime IS NULL BEGIN SELECT @Schedule_Data_Last_Modify_Datetime = '1/1/1900'; END |
We’ll collect job schedules first as this data is relatively small & simple. The TSQL above allows us to find the date/time of the last change in our data set and only collect modifications that have occurred since then. If no data exists, then we set our last modify date/time to a very old date, in order to ensure we collect everything on the first job run.
With this housekeeping out of the way, we can proceed to collect all schedule data from the local SQL Server. A MERGE statement is used for convenience, as it allows us to insert and update rows appropriately all at once. While this TSQL looks long, it’s messiness is primarily due to the need for us to convert integer identifiers in MSDB.dbo.sysschedules into more readable data types. These conversions are not pretty, and there are many ways to accomplish this, but by fixing our data now, we make using it later much, much easier.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 |
MERGE INTO dbo.dim_sql_agent_schedule AS SCHEDULE_TARGET USING ( SELECT sysschedules.schedule_id, sysschedules.name AS Schedule_Name, sysschedules.enabled AS Is_Enabled, 0 AS Is_Deleted, CAST(SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 5, 2) + '/' + SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 7, 2) + '/' + SUBSTRING(CAST(sysschedules.active_start_date AS VARCHAR(MAX)), 1, 4) AS DATE) AS Schedule_Start_Date, CAST(SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 5, 2) + '/' + SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 7, 2) + '/' + SUBSTRING(CAST(sysschedules.active_end_date AS VARCHAR(MAX)), 1, 4) AS DATE) AS Schedule_End_Date, CASE sysschedules.freq_type WHEN 1 THEN 'Once' WHEN 4 THEN 'Daily' WHEN 8 THEN 'Weekly' WHEN 16 THEN 'Monthly' WHEN 32 THEN 'Monthly (relative)' WHEN 64 THEN 'At Agent Startup' WHEN 128 THEN 'When CPU(s) idle' END AS Schedule_Occurrence, CASE sysschedules.freq_type WHEN 1 THEN 'Once' WHEN 4 THEN 'Every ' + CONVERT(VARCHAR, sysschedules.freq_interval) + ' day(s)' WHEN 8 THEN 'Every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' weeks(s) on ' + LEFT( CASE WHEN sysschedules.freq_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END , LEN( CASE WHEN sysschedules.freq_interval & 1 = 1 THEN 'Sunday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 2 = 2 THEN 'Monday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 4 = 4 THEN 'Tuesday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 8 = 8 THEN 'Wednesday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 16 = 16 THEN 'Thursday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 32 = 32 THEN 'Friday, ' ELSE '' END + CASE WHEN sysschedules.freq_interval & 64 = 64 THEN 'Saturday, ' ELSE '' END) - 1) WHEN 16 THEN 'Day ' + CONVERT(VARCHAR, sysschedules.freq_interval) + ' of every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' month(s)' WHEN 32 THEN 'The ' + CASE sysschedules.freq_relative_interval WHEN 1 THEN 'First' WHEN 2 THEN 'Second' WHEN 4 THEN 'Third' WHEN 8 THEN 'Fourth' WHEN 16 THEN 'Last' END + CASE sysschedules.freq_interval WHEN 1 THEN ' Sunday' WHEN 2 THEN ' Monday' WHEN 3 THEN ' Tuesday' WHEN 4 THEN ' Wednesday' WHEN 5 THEN ' Thursday' WHEN 6 THEN ' Friday' WHEN 7 THEN ' Saturday' WHEN 8 THEN ' Day' WHEN 9 THEN ' Weekday' WHEN 10 THEN ' Weekend Day' END + ' of every ' + CONVERT(VARCHAR, sysschedules.freq_recurrence_factor) + ' month(s)' END AS Schedule_Occurrence_Detail, CASE sysschedules.freq_subday_type WHEN 1 THEN 'Occurs once at ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') WHEN 2 THEN 'Occurs every ' + CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Seconds(s) between ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':') WHEN 4 THEN 'Occurs every ' + CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Minute(s) between ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':') WHEN 8 THEN 'Occurs every ' + CONVERT(VARCHAR, sysschedules.freq_subday_interval) + ' Hour(s) between ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_start_time), 6), 5, 0, ':'), 3, 0, ':') + ' and ' + STUFF(STUFF(RIGHT('000000' + CONVERT(VARCHAR(8), sysschedules.active_end_time), 6), 5, 0, ':'), 3, 0, ':') END AS Schedule_Frequency, sysschedules.date_created AS Schedule_Created_Datetime, sysschedules.date_modified AS Schedule_Last_Modified_Datetime FROM msdb.dbo.sysschedules WHERE sysschedules.date_modified > @Schedule_Data_Last_Modify_Datetime) AS SCHEDULE_SOURCE ON (SCHEDULE_SOURCE.schedule_id = SCHEDULE_TARGET.schedule_id) WHEN NOT MATCHED BY TARGET THEN INSERT (Schedule_Id, Schedule_Name, Is_Enabled, Is_Deleted, Schedule_Start_Date, Schedule_End_Date, Schedule_Occurrence, Schedule_Occurrence_Detail, Schedule_Frequency, Schedule_Created_Datetime, Schedule_Last_Modified_Datetime) VALUES ( SCHEDULE_SOURCE.Schedule_Id, SCHEDULE_SOURCE.Schedule_Name, SCHEDULE_SOURCE.Is_Enabled, SCHEDULE_SOURCE.Is_Deleted, SCHEDULE_SOURCE.Schedule_Start_Date, SCHEDULE_SOURCE.Schedule_End_Date, SCHEDULE_SOURCE.Schedule_Occurrence, SCHEDULE_SOURCE.Schedule_Occurrence_Detail, SCHEDULE_SOURCE.Schedule_Frequency, SCHEDULE_SOURCE.Schedule_Created_Datetime, SCHEDULE_SOURCE.Schedule_Last_Modified_Datetime) WHEN MATCHED THEN UPDATE SET Schedule_Name = SCHEDULE_SOURCE.Schedule_Name, Is_Enabled = SCHEDULE_SOURCE.Is_Enabled, Is_Deleted = SCHEDULE_SOURCE.Is_Deleted, Schedule_Start_Date = SCHEDULE_SOURCE.Schedule_Start_Date, Schedule_End_Date = SCHEDULE_SOURCE.Schedule_End_Date, Schedule_Occurrence = SCHEDULE_SOURCE.Schedule_Occurrence, Schedule_Occurrence_Detail = SCHEDULE_SOURCE.Schedule_Occurrence_Detail, Schedule_Frequency = SCHEDULE_SOURCE.Schedule_Frequency, Schedule_Created_Datetime = SCHEDULE_SOURCE.Schedule_Created_Datetime, Schedule_Last_Modified_Datetime = SCHEDULE_SOURCE.Schedule_Last_Modified_Datetime; |
Essentially, this code collects all schedule data for those modified since our last modified date/time and either inserts rows for new schedules or updates for those that already exist. All of the case statements are used to convert the schedule frequency, interval, intervals, and recurrence into strings that can be easily consumed by reports or metrics collection processes. The integers are easy to use for system processing, but not easy for humans to consume. Our primary goal here is to create a simple data store that is easy to use by anyone, even if the user is not someone terribly familiar with the underlying MSDB data.
An additional segment of code can be added to manage whether a schedule is deleted or not. This is optional, but a nice way to maintain some schedule history on those that had previously been used, but have been deleted:
|
1 2 3 4 5 6 7 8 9 |
UPDATE dim_sql_agent_schedule SET Is_Enabled = 0, Is_Deleted = 1 FROM dbo.dim_sql_agent_schedule LEFT JOIN msdb.dbo.sysschedules ON sysschedules.schedule_id = dim_sql_agent_schedule.Schedule_Id WHERE sysschedules.schedule_id IS NULL; |
For any schedule not found on the server, the Is_Enabled and Is_Deleted bits are set appropriately.
With schedule data in hand, we can now pull job data, allowing us to maintain a full list of all SQL Server Agent jobs. Comparatively, job data is far simpler than schedules, as there is no date/time data or other temporal information encoded in suboptimal data types. To start off, we’ll collect the most recent job data update from our data set:
|
1 2 3 4 5 6 7 8 9 10 |
DECLARE @Job_Data_Last_Modify_Datetime DATETIME; SELECT @Job_Data_Last_Modify_Datetime = MAX(dim_sql_agent_job.Job_Last_Modified_Datetime) FROM dbo.dim_sql_agent_job; IF @Job_Data_Last_Modify_Datetime IS NULL BEGIN SELECT @Job_Data_Last_Modify_Datetime = '1/1/1900'; END |
As with schedules, this cuts down the data set we collect from MSDB to only include jobs that were created or updated since the last collection time. With that complete, we can use a MERGE statement to pull in jobs data from MSDB.dbo.sysjobs.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
MERGE INTO dbo.dim_sql_agent_job AS JOB_TARGET USING ( SELECT sysjobs.job_id AS Sql_Agent_Job_Id, sysjobs.name AS Sql_Agent_Job_Name, sysjobs.date_created AS Job_Create_Datetime, sysjobs.date_modified AS Job_Last_Modified_Datetime, sysjobs.enabled AS Is_Enabled, 0 AS Is_Deleted FROM msdb.dbo.sysjobs WHERE sysjobs.date_modified > @Job_Data_Last_Modify_Datetime) AS JOB_SOURCE ON (JOB_SOURCE.Sql_Agent_Job_Id = JOB_TARGET.Sql_Agent_Job_Id) WHEN NOT MATCHED BY TARGET THEN INSERT (Sql_Agent_Job_Id, Sql_Agent_Job_Name, Job_Create_Datetime, Job_Last_Modified_Datetime, Is_Enabled, Is_Deleted) VALUES ( JOB_SOURCE.Sql_Agent_Job_Id, JOB_SOURCE.Sql_Agent_Job_Name, JOB_SOURCE.Job_Create_Datetime, JOB_SOURCE.Job_Last_Modified_Datetime, JOB_SOURCE.Is_Enabled, JOB_SOURCE.Is_Deleted) WHEN MATCHED THEN UPDATE SET Sql_Agent_Job_Id = JOB_SOURCE.Sql_Agent_Job_Id, Sql_Agent_Job_Name = JOB_SOURCE.Sql_Agent_Job_Name, Job_Create_Datetime = JOB_SOURCE.Job_Create_Datetime, Job_Last_Modified_Datetime = JOB_SOURCE.Job_Last_Modified_Datetime, Is_Enabled = JOB_SOURCE.Is_Enabled, Is_Deleted = JOB_SOURCE.Is_Deleted; |
When a job is not found in our data, it is inserted, and when it is found, it is updated. Lastly, we check for deleted jobs and update as appropriate, similar to with schedules:
|
1 2 3 4 5 6 7 8 9 |
UPDATE dim_sql_agent_job SET Is_Enabled = 0, Is_Deleted = 1 FROM dbo.dim_sql_agent_job LEFT JOIN msdb.dbo.sysjobs ON sysjobs.Job_Id = dim_sql_agent_job.Sql_Agent_Job_Id WHERE sysjobs.Job_Id IS NULL; |
Job associations can be tracked by pulling directly from MSDB.dbo.sysjobschedules, but the next run date is not updated constantly. There is a delay in SQL Server before a background process runs and updates this data. If you need up-to-the-minute accuracy, then use MSDB.dbo.sysjobactivity, which is updated as jobs execute and complete. As a bonus, the date/time columns are actually stored in DATETIME data types!
The following script pulls the assignment details first, and then joins back to pull the next run date/time:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
MERGE INTO dbo.fact_sql_agent_schedule_assignment AS JOB_ASSIGNMENT_TARGET USING ( SELECT sysjobschedules.schedule_id, sysjobschedules.job_id FROM msdb.dbo.sysjobschedules) AS JOB_ASSIGNMENT_SOURCE ON (JOB_ASSIGNMENT_SOURCE.job_id = JOB_ASSIGNMENT_TARGET.Sql_Agent_Job_Id AND JOB_ASSIGNMENT_SOURCE.schedule_id = JOB_ASSIGNMENT_TARGET.schedule_id) WHEN NOT MATCHED BY TARGET THEN INSERT (Sql_Agent_Job_Id, Schedule_Id) VALUES ( JOB_ASSIGNMENT_SOURCE.job_id, JOB_ASSIGNMENT_SOURCE.schedule_id) WHEN NOT MATCHED BY SOURCE THEN DELETE; WITH CTE_LAST_RUN_TIME AS ( SELECT sysjobactivity.job_id, MIN(sysjobactivity.next_scheduled_run_date) AS Next_Run_Datetime FROM msdb.dbo.sysjobactivity WHERE sysjobactivity.next_scheduled_run_date > CURRENT_TIMESTAMP GROUP BY sysjobactivity.job_id) UPDATE fact_sql_agent_schedule_assignment SET Next_Run_Datetime = CTE_LAST_RUN_TIME.Next_Run_Datetime FROM CTE_LAST_RUN_TIME INNER JOIN dbo.fact_sql_agent_schedule_assignment ON CTE_LAST_RUN_TIME.job_id = fact_sql_agent_schedule_assignment.Sql_Agent_Job_Id; |
The primary difference in this MERGE statement is that we will delete any associations that do not exist as there is little benefit in maintaining old relationships. The next run time is the same for all assigned schedules, in case more than one exists on a job. This keeps our data as simple as possible for future use.
The next two blocks of TSQL comprise the bulk of our stored procedure and encompass the actual job duration metrics collection.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
WITH CTE_NORMALIZE_DATETIME_DATA AS ( SELECT sysjobhistory.instance_id AS Sql_Agent_Job_Run_Instance_Id, sysjobhistory.job_id AS Sql_Agent_Job_Id, CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS Run_Date_VARCHAR, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS Run_Time_VARCHAR, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS Run_Duration_VARCHAR, sysjobhistory.run_status AS Run_Status FROM msdb.dbo.sysjobhistory WHERE sysjobhistory.instance_id NOT IN (SELECT fact_job_run_time.Sql_Agent_Job_Run_Instance_Id FROM dbo.fact_job_run_time) AND sysjobhistory.step_id = 0) INSERT INTO dbo.fact_job_run_time (Sql_Agent_Job_Run_Instance_Id, Sql_Agent_Job_Id, Job_Start_Datetime, Job_Duration_Seconds, Job_Status) SELECT CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Run_Instance_Id, CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Id, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 1, 4) AS DATETIME) + CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.Run_Time_VARCHAR, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS Job_Start_Datetime, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 1, 2) AS INT) * 3600 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 3, 2) AS INT) * 60 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 5, 2) AS INT) AS Job_Duration_Seconds, CASE CTE_NORMALIZE_DATETIME_DATA.Run_Status WHEN 0 THEN 'Failure' WHEN 1 THEN 'Success' WHEN 2 THEN 'Retry' WHEN 3 THEN 'Canceled' ELSE 'Unknown' END AS Job_Status FROM CTE_NORMALIZE_DATETIME_DATA; |
A common table expression (CTE) is used to reformat the date/time/duration data, and then the subsequent INSERT INTO…SELECT statement finishes the formatting and places the data into our tables.
To put the data types used in MSDB.dbo.sysjobhistory into perspective:
- Run_status is an integer that indicates 0 (failure), 1 (success), 2 (retry), and 3 (canceled).
- Run_date is an integer representation of the YYYMMDD date of the job execution.
- Run_time is an integer representation of the HHMMSS time of the job execution
- Run_duration is the amount of time the job ran for, formatted as HHMMSS.
Since integers are used for dates, times, and duration, there is the possibility that the number of digits will vary depending on the time of the day. For example, a time of “20001” would indicate 8:00:01 pm with no need for a leading zero. This added complexity ensures some necessary gnarly string manipulation in order to be certain that the resulting numbers are valid DATETIME values, rather than INT or VARCHAR representations.
This TSQL pulls exclusively those rows with step_id = 0, which indicates overall job completion. Any job steps numbered 1 or higher correspond to each job step within a job, which are tracked in a separate fact table, as indicated below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
WITH CTE_NORMALIZE_DATETIME_DATA AS ( SELECT sysjobhistory.instance_id AS Sql_Agent_Job_Run_Instance_Id, sysjobhistory.job_id AS Sql_Agent_Job_Id, sysjobhistory.step_id AS Sql_Agent_Job_Step_Id, CAST(sysjobhistory.run_date AS VARCHAR(MAX)) AS Run_Date_VARCHAR, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_time AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_time AS VARCHAR(MAX)) AS Run_Time_VARCHAR, REPLICATE('0', 6 - LEN(CAST(sysjobhistory.run_duration AS VARCHAR(MAX)))) + CAST(sysjobhistory.run_duration AS VARCHAR(MAX)) AS Run_Duration_VARCHAR, sysjobhistory.run_status AS Run_Status FROM msdb.dbo.sysjobhistory WHERE sysjobhistory.instance_id NOT IN (SELECT fact_step_job_run_time.Sql_Agent_Job_Run_Instance_Id FROM dbo.fact_step_job_run_time) AND sysjobhistory.step_id <> 0) INSERT INTO dbo.fact_step_job_run_time (Sql_Agent_Job_Run_Instance_Id, Sql_Agent_Job_Id, Sql_Agent_Job_Step_Id, Job_Step_Start_Datetime, Job_Step_Duration_seconds, Job_Step_Status) SELECT CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Run_Instance_Id, CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Id, CTE_NORMALIZE_DATETIME_DATA.Sql_Agent_Job_Step_Id, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 5, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 7, 2) + '/' + SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Date_VARCHAR, 1, 4) AS DATETIME) + CAST(STUFF(STUFF(CTE_NORMALIZE_DATETIME_DATA.Run_Time_VARCHAR, 5, 0, ':'), 3, 0, ':') AS DATETIME) AS Job_Step_Start_Datetime, CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 1, 2) AS INT) * 3600 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 3, 2) AS INT) * 60 + CAST(SUBSTRING(CTE_NORMALIZE_DATETIME_DATA.Run_Duration_VARCHAR, 5, 2) AS INT) AS Job_Step_Duration_seconds, CASE CTE_NORMALIZE_DATETIME_DATA.Run_Status WHEN 0 THEN 'Failure' WHEN 1 THEN 'Success' WHEN 2 THEN 'Retry' WHEN 3 THEN 'Canceled' ELSE 'Unknown' END AS Job_Step_Status FROM CTE_NORMALIZE_DATETIME_DATA; |
This final segment of TSQL is almost identical to the previous job completion metrics collection script, except here we gather all rows in which the step_id is greater than zero. This intentionally omits overall job duration metrics and only includes individual step completion. Some notes on job step data:
- Step names and details are not included. If this is something you’d like to collect & save, they are easy to add.
- If a job fails and exits before all steps complete, then any subsequent steps will not appear in the results for that execution as the job never actually reached them in the step list. In other words, if a step never executes, it will not be represented in this data.
-
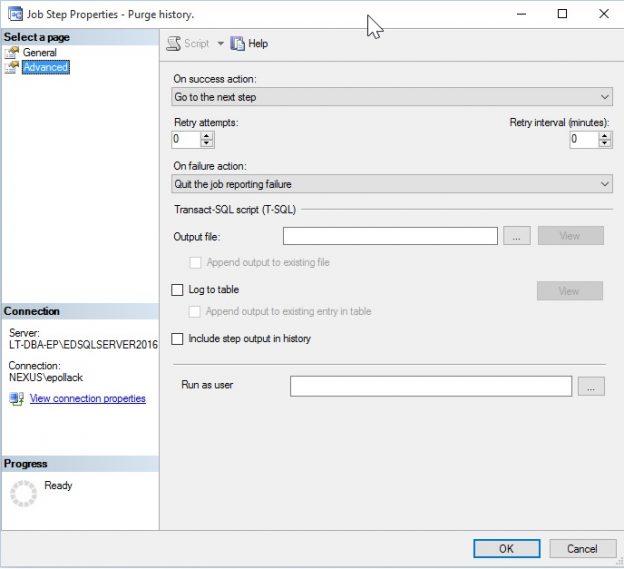
A job can succeed even if a step fails, depending on the logic used in the advanced job step configuration:
“On failure action” can be adjusted to continue through the job and post success, later on, assuming underlying issues are resolved or are deemed unimportant by this branching logic.
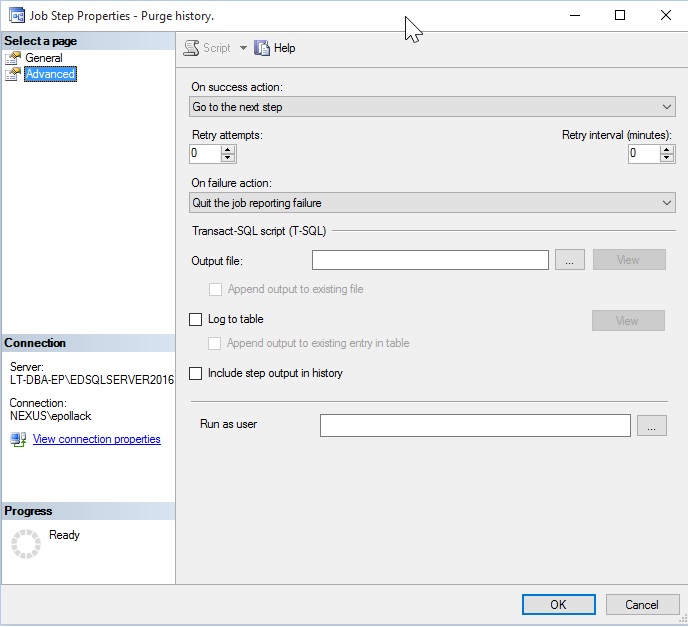
At this point, we have a complete script that can be executed anytime in order to collect job execution statistics. All of the underlying work can be broken into five distinct sections: one for each table. From here, we need to figure out what to do with this data in order to make the best use of it!
Cleanup
As with any data collection process, we want to clean up or archive old data to ensure that we are not storing data so old that it has become irrelevant and overly space-consuming. Only two tables contain data that can accumulate heavily over time: Fact_Job_Run_Time and: Fact_Job_Step_Run_Time. Cleaning up data from these tables is as simple as choosing a cutoff period of some sort and enforcing it, either in the job that collects this data or in a more generalized process elsewhere on your server.
The following TSQL removes all job execution data older than a year:
|
1 2 3 4 5 6 7 8 9 |
DELETE fact_job_run_time FROM dbo.fact_job_run_time WHERE fact_job_run_time.Job_Start_Datetime < DATEADD(YEAR, -1, CURRENT_TIMESTAMP); DELETE fact_step_job_run_time FROM dbo.fact_step_job_run_time WHERE fact_step_job_run_time.Job_Step_Start_Datetime < DATEADD(YEAR, -1, CURRENT_TIMESTAMP); |
Alternatively, we could limit data storage by the number of rows per job, per job step, or via any other convention that matches your business needs. If this data is to be crunched into more generic metrics per server, such as average duration per day or number of failures per month, then it may be possible to hang onto far less than a year of detail data.
It is important to distinguish between detail data, as stored in these tables and reporting data, that can be gleaned from these tables or stored elsewhere as needed. We’ll discuss reporting later in this article in order to create some examples of what we can do with job performance metrics.
Customization
A process such as this begs for customization. Some of the tables shown here, such as job-schedule pairings or job step runtimes may or may not be important to you. There may be columns, such as job status, that you do not need. Alternatively, MSDB may have some columns in its tables that I did not include that may be useful to you.
The collection procedures and reporting scripts created here are very flexible—feel free to customize as you see fit. The general process is the same:
- Collect detailed job execution data.
- Store collected data in separate fact tables.
- Create further aggregation/number crunching as needed and store results in new tables.
- Generate reports off of the crunched data in order to satisfy trending/monitoring needs.
I have provided many ideas for customization throughout this article. If you find any creative or interesting uses for this data that are not outlined here, feel free to contact me and let me know! I enjoy seeing how processes such as this are changed over time to solve new, complex, or unexpected challenges.
Conclusion
Collecting, aggregating, and reporting on job performance metrics is not something that we often consider when planning how to monitor our SQL Servers. Despite it being less obvious than CPU, memory, or contention metrics, these stats can be critical in an environment where SQL Server Agent jobs are relied upon in order to know when jobs run far too long or to see the trending of performance over time.
Consider what metrics are needed in your environment, customize to get those details, and make the best use of the data collected. This sort of information allows us to identify and solve performance problems before they result in failures or timeouts, and can likewise avoid the emergencies and dreaded late-night wake-up calls that often follow.
Tracking-Job-Performance-in-SQL-Server_1-1.zip
In his free time, Ed enjoys video games, sci-fi & fantasy, traveling, and being as big of a geek as his friends will tolerate.
View all posts by Ed Pollack
- SQL Server Database Metrics - October 2, 2019
- Using SQL Server Database Metrics to Predict Application Problems - September 27, 2019
- SQL Injection: Detection and prevention - August 30, 2019