
SQL Server temp tables are a special type of tables that are written to the TempDB database and act like regular tables, providing a suitable workplace for intermediate data processing before saving the result to a regular table, as it can live only for the age of the database connection.
SQL temp tables can be used to enhance stored procedures performance by shortening the transaction time, allowing you to prepare records that you will modify in the SQL Server temp table, then open a transaction and perform the changes.
There are four main types for the SQL temp tables:
a Local SQL Server temp table, which is named starting with a # symbol (e.g. #TempShipments), that can be referenced only by the current database session and discarded by its disconnection,
a Global SQL temp table, which is named starting with ## (e.g. ##TempShipments), that can be referenced by any process in the current database and discarded when the original database session that created that temp table disconnected or until the last statement that was referencing the temp table has stopped using it, as anyone who has access to the system TempDB database when that global SQL temp table is created will be able to use that table,
a Persistent SQL Server temp table which is named starting with a TempDB prefix such as TempDB.DBO.TempShipments
and a Table Variable that starts with an @ prefix (e.g. @TempShipments)
The SQL Server Database Engine can distinguish between the same SQL temporary tables created while executing the same stored procedure many times simultaneously by appending a system-generated numeric suffix to the SQL Server temp table name. This is why the local SQL temp table name can’t exceed 116 characters.
Although both SQL Server temp tables and table variables are stored in the TempDB database, there are many differences between them such as:
SQL temp tables are created using CREATE TABLE T-SQL statement, but table variables are created using DECLARE @name Table T-SQL statement.
You can ALTER the SQL Server temp tables after creating it, but table variables don’t support any DDL statement like ALTER statement.
SQL temp tables can’t be used in User Defined Functions, but table variables can be.
SQL Server temporary tables honor explicit transactions defined by the user, but table variables can’t participate in such transactions.
SQL temp tables support adding clustered and non-clustered indexes after the SQL Server temp table creation and implicitly by defining Primary key constraint or Unique Key constraint during the tables creation, but table variables support only adding such indexes implicitly by defining Primary key constraint or Unique key constraint during tables creation.
SQL temp tables can be dropped explicitly, but table variables can’t be dropped explicitly, taking into consideration that both types are dropped automatically when the session in which they are created is disconnected.
SQL Server temp tables can be local temporal tables at the level of the batch or stored procedure in which the table declared or global temporal tables where it can be called outside the batch or stored procedure scope, but table variables can be called only within the batch or stored procedure in which it is declared.
In addition to that, SQL Server column level statistics are generated automatically against SQL temp tables, helping the SQL Server Query Optimizer to generate the best execution plan, gaining the best performance when querying that SQL Server temp table. But you should take into consideration that modifying SQL temp tables many times in your code may lead to statistics getting out of date. This would require manually updating for these statistics, or enabling Trace Flag 2371. In this article, we will see how we can benefit from the ability to add clustered and non-clustered indexes in the SQL Server temp tables.
Defining PRIMARY KEY and UNIQUE KEY constraints during SQL temp table creation will enable SQL Server Query Optimizer to always be able to use these indexes. Even so, these indexes prevent inserting non-unique values to these columns, which is not the best case in all scenarios, that may require non-unique values. In this case, it is better to explicitly define a clustered or non-clustered index that could be configured as a non-unique index. Adding indexes to the SQL temp tables will enhance its performance if the index is chosen correctly, otherwise, it can cause performance degradation. Also, not every SQL Server temp table needs adding indexes, as it depends on many things such as the way that this SQL temp table will be called, joined with other huge tables or if it will be part of a complex stored procedure.
Let’s start our demo, in which we will test the performance of filling and retrieving data from SQL Server temp tables that contain 100k records, without any index, with a non-clustered index, and with a clustered index. We will concentrate in checking the time consumed by each case and the generated execution plan. To evaluate the consumed time, we will declare @StartTime variable before each execution, set its value to GETDATE () and at the end of each execution, we will print the date difference (in ms) between the current time and the start time.
The below script will create the previously mentioned three SQL temp tables; temp table without an index, temp table with a non-clustered index and temp table with clustered index and fill it with 100k records from the CountryInfo test table then retrieve these records from the tables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
USE SQLShackDemo GO set nocount on go DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNoIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNoIndex SELECT TOP 100000 * FROM [dbo].[CountryInfo] SELECT * FROM #TempWithNoIndex WHERE CountyCode='JFK' PRINT '#TempWithNoIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNoIndex GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNonClusterIndex SELECT TOP 100000 * FROM [dbo].[CountryInfo] CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndex ([CountyCode],[RowVersion]); SELECT * FROM #TempWithNonClusterIndex WHERE CountyCode='JFK' PRINT '#TempWithNonClusterIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndex GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndex ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndex ([CountyCode],[RowVersion]); INSERT INTO #TempWithClusterIndex SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo] SELECT * FROM #TempWithClusterIndex WHERE CountyCode='JFK' PRINT '#TempWithClusterIndex' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndex GO |
Executing the previous script, the result will show us that in our case, adding a non-clustered index is worse than having the table without index by 1.2 times in our case, but adding a clustered index will enhance the overall performance by one time in our case as in the below timing comparison in ms:
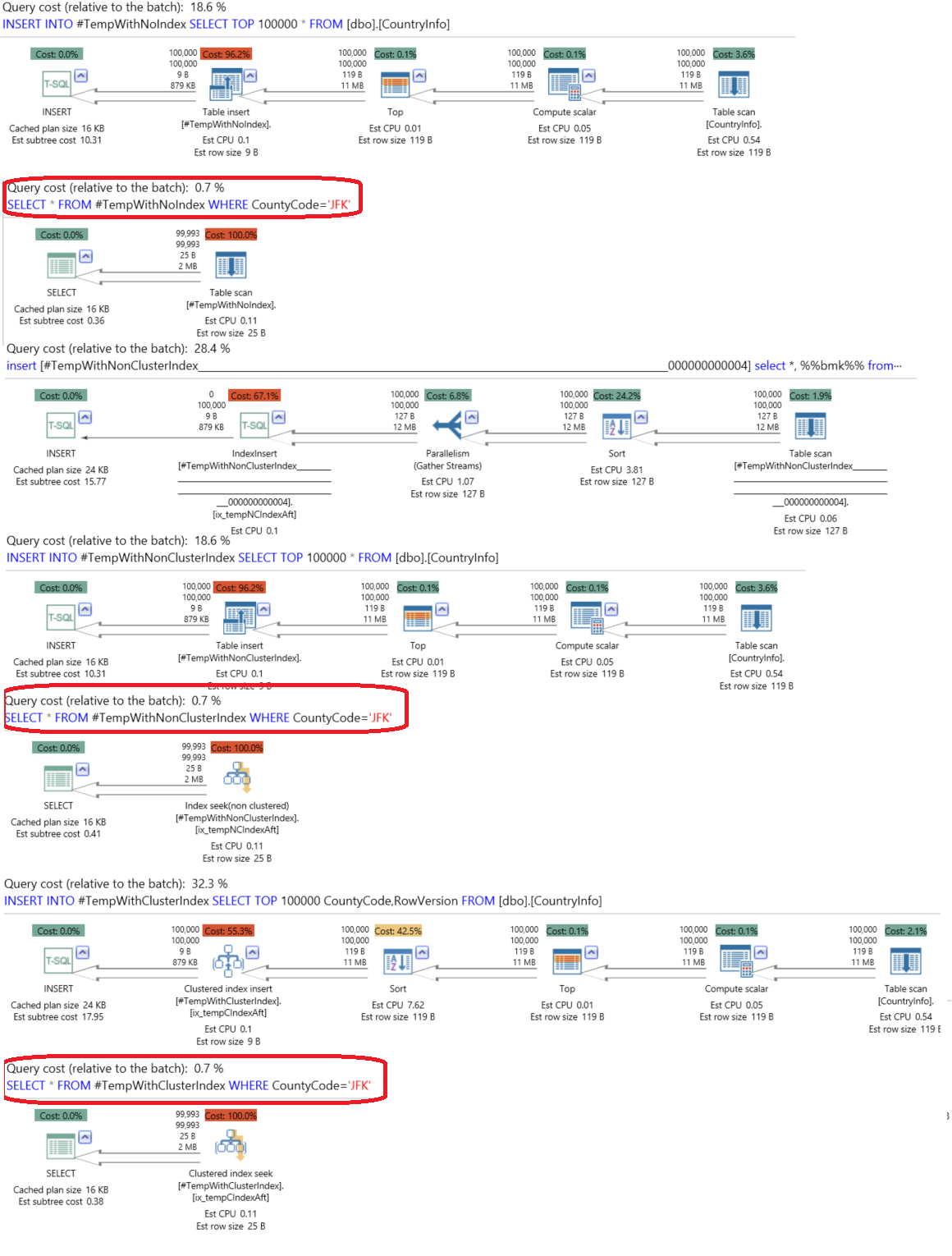
Checking the generated execution plan using the ApexSQL Plan application after the execution, we will see that, as we don’t have joins with huge tables or complex queries, the data retrieval from the three tables consume the same resources (1%) and differ in the operator that is used to retrieve the data; Table Scan in the case of the temp table without index, Index Seek in the case of temp table with non-clustered index and Clustered Index Seek in the case of temp table with clustered index.
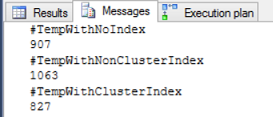
Also you can derive from the execution plan, that the table with non-clustered index took the largest time (1063 ms) and resources (47% of the overall execution) during the table insertion process opposite to the table with clustered index insertion that took less time (827 ms) and resources (32 % of the overall execution):
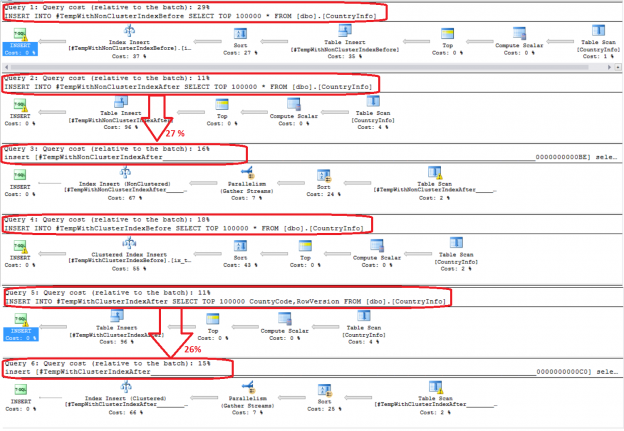
In the previous script we created a non-clustered index after filling the temp table and the clustered index before filling the temp table. But is it different when we create the index before or after filling the temp table? To answer this question let’s perform the following test in which we will check the consumed time in all cases; adding a non-clustered index before filling the temp table, adding a non-clustered index after filling the temp table, adding a clustered index before filling the temp table and adding a clustered index after filling the temp table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
USE SQLShackDemo GO set nocount on GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndexBefore ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE NONCLUSTERED INDEX ix_tempNCIndexBef ON #TempWithNonClusterIndexBefore ([CountyCode],[RowVersion]); INSERT INTO #TempWithNonClusterIndexBefore SELECT TOP 100000 * FROM [dbo].[CountryInfo] PRINT '#TempWithNonClusterIndexBefore' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndexBefore GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithNonClusterIndexAfter ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithNonClusterIndexAfter SELECT TOP 100000 * FROM [dbo].[CountryInfo] CREATE NONCLUSTERED INDEX ix_tempNCIndexAft ON #TempWithNonClusterIndexAfter ([CountyCode],[RowVersion]); PRINT '#TempWithNonClusterIndexAfter' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithNonClusterIndexAfter GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndexBefore ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) CREATE CLUSTERED INDEX ix_tempCIndexBef ON #TempWithClusterIndexBefore ([CountyCode],[RowVersion]); INSERT INTO #TempWithClusterIndexBefore SELECT TOP 100000 * FROM [dbo].[CountryInfo] PRINT '#TempWithClusterIndexBefore' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndexBefore GO DECLARE @StartTime AS DATETIME = GETDATE() CREATE TABLE #TempWithClusterIndexAfter ([CountyCode] NVARCHAR(100),[RowVersion] DateTime) INSERT INTO #TempWithClusterIndexAfter SELECT TOP 100000 CountyCode,RowVersion FROM [dbo].[CountryInfo] CREATE CLUSTERED INDEX ix_tempCIndexAft ON #TempWithClusterIndexAfter ([CountyCode],[RowVersion]); PRINT '#TempWithClusterIndexAfter' PRINT DATEDIFF(ms,@StartTime,GETDATE()) DROP TABLE #TempWithClusterIndexAfter GO |
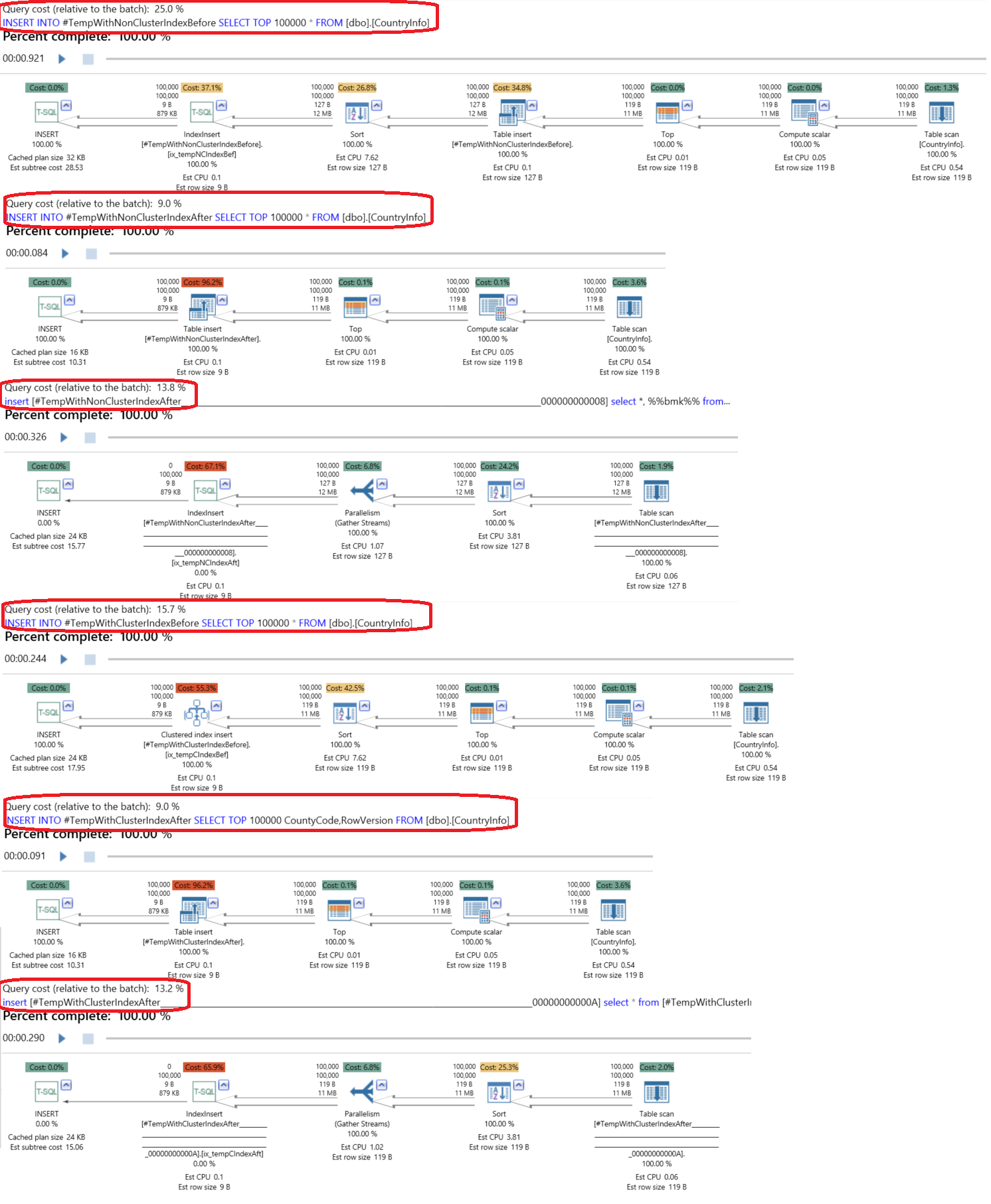
It is clear from the result generated from executing the previous script that it is better to create the non-clustered index after filling the table, as that is 1.2% faster, and create the clustered index before filling the table, as that is 2.5% faster, due to the mechanism that is used to fill the tables and create the indexes:

Checking the execution plan, the result will show us that creating the clustered index before the insertion consumes 15.7% of the overall execution, where creating it after the insertion will consume 22% of the overall execution. On the other hand, creating the non-clustered indexes after the insertion consumes 23% of the resources compared with the 25% percent that is consumed by creating it before the insertion process:
Conclusion
In SQL Server, SQL temp tables, that are stored in the TempDB database, are widely used to provide a suitable place for the intermediate data processing before saving the result to a base table. It also used to shorten the duration of long running transactions with minimum base table locking by taking the data, processing it and finally opening a transaction to perform the change on the base table. This approach is applicable to add non-clustered and clustered indexes to the SQL Server temp tables, which both can enhance the performance of retrieving data from these tables if the indexes are chosen correctly.

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021