
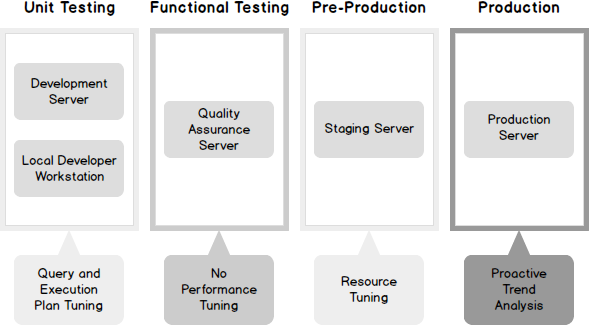
It is a common misconception that you need real production data, or production like data, to effectively tune queries in SQL Server. I am going to explain how you can compile the same execution plans as what your production environment would compile, so that you can tune them in a non-production environment, gaining these benefits.
- Keep sensitive data in production, such as personally identifiable information (PII).
- Save space by not duplicating any of the production data in lower environments.
- Save server resources by keeping development machines small.
- Speed up development machine provisioning by restoring smaller databases.
Methods for tuning the execution plans is out of scope for this post. This post covers the configuration of your non-production server and cloning of your production databases.
Which method to use and when
A lot of common tuning methodologies rely upon resource usages such as physical/logical reads/writes and elapsed time. There is a lot of validity to those methods. This post is going to focus on a different way of tuning but I am not putting down the usage based methods nor am I offering you an improvement or replacement. There are a time and a place for both tuning methods.
Usage based tuning methods, which require that you execute the queries and measure their behavior, are best suited to a staging environment. A staging environment would be locked down to a similar degree as your production environment and would be refreshed regularly with actual production data. I have seen many IT shops handle this by restoring last night’s production backup to the staging environment each morning.
I advocate that 80% of your query performance problems can be dealt with from the execution plan alone. Execution plan tuning can be and should be, accomplished as far left as your development environment. Execution plans compiled in the development environment are usually very different than the ones generated in the production environment. This is the problem that will be solved in this post.
Faking out your hardware
The first step in spoofing the production environment is to convince the query optimizer that the hardware you are working with in development is equivalent to the hardware that you have in production. To do that, use DBCC OPTIMIZER_WHATIF.
DBCC OPTIMIZER_WHATIF is an undocumented DBCC command which tells a single session to act as if the machine running SQL Server has different physical or virtual properties. It is session scoped, which is great. It means that you can have several different developers working on the same development server while spoofing different hardware. This becomes useful when consolidating the execution plan tuning onto a multi-tenanted development server. I will talk more about this in the next section.
How it works
|
1 2 3 4 5 6 7 |
-- TF to enable help to undocumented commands DBCC TRACEON (2588) WITH NO_INFOMSGS -- DBCC help DBCC HELP ('OPTIMIZER_WHATIF') WITH NO_INFOMSGS dbcc OPTIMIZER_WHATIF ({property/cost_number | property_name} [, {integer_value | string_value} ]) |
By using trace flag 2588 and DBCC HELP, the syntax of the undocumented command can be viewed. DBCC OPTIMIZER_WHATIF accepts a simple key / value pair as parameters.
|
1 2 3 4 5 6 |
-- TF to send output results to console DBCC TRACEON(3604) WITH NO_INFOMSGS -- Current and valid values DBCC OPTIMIZER_WHATIF(0) WITH NO_INFOMSGS; |
Using trace flag 3604 and passing in 0 as the only parameter into DBCC OPTIMIZER_WHATIF displays the possible keys and current values.
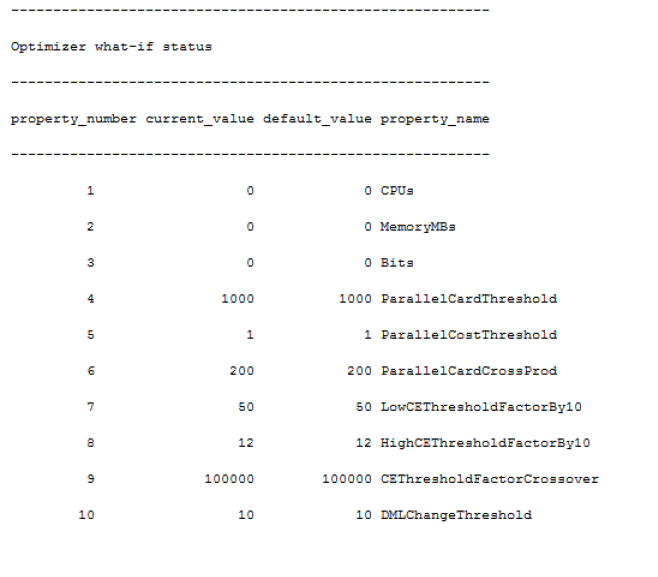
The three parameters that are most important are; CPUs, MemoryMBs, and Bits. As you can imagine, CPUs sets the number of cores that SQL Server believes it has and MemoryMBs sets the perceived memory. Bits sets the platform to 32 or 64 bit but this option is likely going to become less relevant as time goes on and 32-bit SQL Servers fall out of existence.
There are some functional examples of the impact of DBCC OPTIMIZER_WHATIF on an execution plan in this article.
What to expect
Spoofing the hardware is the first half of the battle. These settings directly impact the decisions that the query optimizer makes during compilation. The CPUs option will impact the query’s potential for parallelism. When a plan is compiled, the optimizer only chooses whether the plan will be parallel or not. It does not determine the number of cores which will be used, that occurs at runtime. This means that the CPUs parameter is only important when one server has only a single core and the other has multiple cores. If both already have two or more cores, then a parallel plan will be an option in both cases.
The MemoryMBs option, has a much larger impact on the execution plan generated. This option impacts the size of the memory grants available in the execution plan which, in turn, affects the use of operators such as table spools.
Faking out the optimizer
The second, and most important, step is to fake out the optimizer. This is accomplished by matching the database schema to the production environment and pulling down all the statistics from production into the development environment. The optimizer uses these two components to make the decisions necessary during execution plan compilation.
Schema and statistics
Matching the schema between the production database and the development database is important for comparing apples to apples. There are many objects which impact the query plans outside of the table structure itself. Indexes are, of course, very important but also options and objects such as SCHEMABINDING and FOREIGN KEYs have a significant impact on the plan generated.
Naturally, it is important to tune queries after the schema has been changed but before the change is released into production. With that being said, for new development, you want to tune the state production will be in when you release, not the current state. Drift from the production schema is acceptable, assuming it was intentional.
The production statistics are the truly critical pieces of the puzzle, however. SQL Server statistics are comprised of the statistics header, density vector, and the histogram. DBCC SHOW_STATISTICS is used to display the details of a statistic.
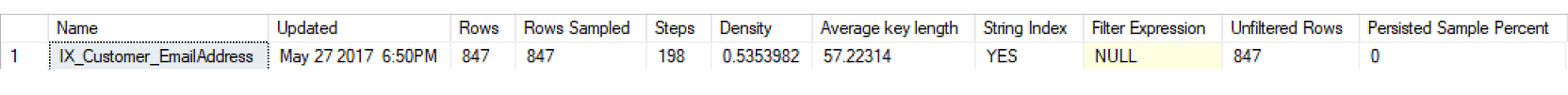

When an execution plan is compiled, information from the statistics from each table and/or index involved in the query is used, such as the row counts from the statistics header, the selectivity information from the density vector, and bucketized statistics from the histogram.
DBCC CLONEDATABASE
The entire database schema, with all of the statistics, can be scripted out using the SQL Server Management Studio Generate Script Wizard. A simpler, and my preferred, method for creating an exact copy of the database, but without any data, is to use DBCC CLONEDATABASE.
|
1 2 3 4 |
USE Master DBCC CLONEDATABASE ('AdventureWorks2014','AdventureWorks2014_clone') |
DBCC CLONEDATABASE will generate a clone of the database and place it on the same instance with a different name.
DBCC CLONEDATABASE was first released in SQL Server 2014 SP2 and SQL Server 2016 SP1.
This clone will be in READ_ONLY mode by default. READ_ONLY mode protects the production statistics from being updated or deleted but prevents new indexes being created to test out different tuning scenarios and prevents you from deploying schema changes to be tuned. For that reason, I prefer to set the database back into READ_WRITE mode and disable AUTO_UPDATE_STATISTICS.
|
1 2 3 4 |
ALTER DATABASE AdventureWorks2014_clone SET READ_WRITE ALTER DATABASE AdventureWorks2014_clone SET AUTO_UPDATE_STATISTICS OFF |
Once the database is in the desired state, backup it up and restore it to the development server. Since there are minimal resources required to compile execution plans, and the databases do not contain any data. It is convenient to maintain a single development server, with minimal resources, where many production clones can be stock piled for tuning. This would be an efficient means of server consolidation.
Bringing it all together
With a cloned copy of the production database and access to DBCC OPTIMIZER_WHATIF, any query can be compiled by retrieving the estimated execution plan or running the query while collecting the actual execution plan.
The plan, retrieved in this manner, will be identical to the plan which would have been or has been generated in the production environment. At this point, begin execution plan tuning. Query modifications can be tested by generating a new plan. Confidence can be had that the new plan generated will be the same once the query modifications are deployed into the production environment.
Caveats and limitations
As mentioned above, this method can surface about 80% of your query problems. Resource based tuning is still important in a production-like environment because of the below factors.
- New tables and indexes have not yet existed in production yet. Therefore, there are no production statistics to copy down and tune based on.
- Modifying an existing index will invalidate the statistics which makes tuning it the same as a new index.
- Locking, blocking, and other concurrency factors are not in play with this method since no query is actually being executed.

Derik thanks our #sqlfamily for plugging the gaps in his knowledge over the years and actively continues the cycle of learning by sharing his knowledge with all and volunteering as a PASS User Group leader.
View all posts by Derik Hammer
- SQL query performance tuning tips for non-production environments - September 12, 2017
- Synchronizing SQL Server Instance Objects in an Availability Group - September 8, 2017
- Measuring Availability Group synchronization lag - August 9, 2016