
In the previous article, on tracking database file storage usage How to track SQL Server database space usage with built-in functions and DMVs, I introduced some ideas and calculations for figuring out when your database is going to run out of headroom on the file system – hopefully in time to get an order in the works to increase that space!
In the meantime, though, you know it will be smart to do all you can to minimize the storage footprint of your database. SQL Server data compression, available in Enterprise versions, is one such approach. The idea is simple: Find repetitive sections of data in a table and store unique information just per row or page or column store index. Modern compression algorithms can reduce the on-disk footprint by 40-60% or even more, depending on the type of data.
Compressing your SQL Server data is a simple way to cram more into your limited disk space. In this article, I’ll start off by showing you how you can find out what tables and indexes are not compressed. This will give you vital insight into what to prioritize when you get to work on those space hogs!
Before we get started, let me answer a question you may be asking about performance. Compressed tables use extra CPU cycles to compress/decompress their contents. However, you will need less I/O to read and write those tables, since they now occupy (much) less space on disk. Unless you are severely CPU-bound – in which case you have bigger problems – compression may well enhance your system throughput by reducing I/O.
What tables and indexes are not compressed?
Two handy DMVs will give us this information. Here is a query that will extract a neat overview of compression opportunities:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT DISTINCT s.name, t.name, i.name, i.type, i.index_id, p.partition_number, p.rows FROM sys.tables t LEFT JOIN sys.indexes i ON t.object_id = i.object_id JOIN sys.schemas s ON t.schema_id = s.schema_id LEFT JOIN sys.partitions p ON i.index_id = p.index_id AND t.object_id = p.object_id WHERE t.type = 'U' AND p.data_compression_desc = 'NONE' ORDER BY p.rows desc |
Running this against the AdventureWorks database, you might get a result set like this:
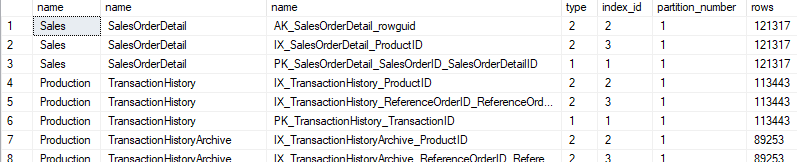
Without even considering the contents of these tables, you can see that the SalesOrderDetail table is the largest. It may be a good candidate for compression. By the way, the type column indicates the type of the index. 1 is for clustered indexes. 2 means a non-clustered index. 0 (not shown in this example) is a heap. Recall that a table is either a heap or a clustered index.
How much space will I save?
SQL Server provides an easy-to-use stored procedure to estimate the savings compression can give you. Since there are two types of compression, ROW and PAGE, let’s try both:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
EXEC sp_estimate_data_compression_savings @schema_name = 'Sales', @object_name = 'SalesOrderDetail', @index_id = NULL, @partition_number = NULL, @data_compression = 'ROW' EXEC sp_estimate_data_compression_savings @schema_name = 'Sales', @object_name = 'SalesOrderDetail', @index_id = NULL, @partition_number = NULL, @data_compression = 'PAGE' |
These calls yielded the results:
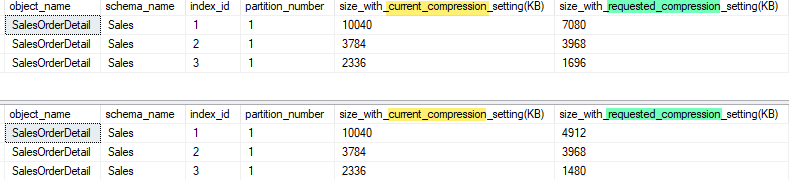
I highlighted the columns showing the current compression level (none) and the requested compression (ROW first, then PAGE). Clearly, PAGE compression is the best option for index ids 1 and 3. Index id 2 does not seem to benefit so much. Referring to the earlier results, you can see that indexes 1 and 3 are the primary key and a non-clustered index. Index two, as the name implies, is an “Alternate Key” on a row GUID. GUIDs are not very compressible (nor should they be! If they were, that would imply lots of repeated characters, which would be very bad GUIDs indeed!) so it’s not worth trying.
OK! Let’s get things compressed!
Once you know what to compress, the actual action is easy:
|
1 2 3 4 5 6 7 8 9 10 |
ALTER INDEX PK_SalesOrderDetail_SalesOrderID_SalesOrderDetailID ON Sales.SalesOrderDetail REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE); ALTER INDEX IX_SalesOrderDetail_ProductID ON Sales.SalesOrderDetail REBUILD PARTITION = ALL WITH (DATA_COMPRESSION = PAGE); |
We’ll compress the two candidates we found. The actual run time of the compression operation is dependent on the size of the tables and indexes, of course. For a large table, expect to wait a bit! Also, note that I specified “PARTITION = ALL”. For AdventureWorks, all tables are in a single partition, so this is fine, though I could have written “PARTITION = 1” with the same result. Imagine, though, that you have very large tables that are partitioned. In such a case, it may be prudent to compress one partition at a time, rather than hogging the system while you compress all partitions at once.
My tables are compressed, so what about the file system space?
Say you’ve gone through the exercise of compressing everything that looks worth the effort. That may mean that your partitions (or the PRIMARY partition if your tables are not partitioned) are now only half-full. Harking back to the previous article, you may wonder if you can now get file system space back. The answer, as always, is – “It depends.”
If your tables have simply been growing at the end of their clustered indexes (or if they are heaps), then I’d raise “It depends” to “quite possible”. If your tables have seen lots of inserts in the middle, updates, or deletes, then maybe not. When you compress a number of tables in a partition, SQL will not defragment the partition. That may mean that the partitions have no space to give up. If that occurs, the only remedy is to copy the partition to another filegroup, table by table, then delete the original file.
You can see if there is any space to give back with a fairly simple query:
|
1 2 3 4 5 6 7 8 9 |
SELECT name, s.used / 128.0 AS SpaceUsedInMB, size / 128.0 - s.used / 128.0 AS AvailableSpaceInMB FROM sys.database_files CROSS APPLY (SELECT CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)) s(used) WHERE FILEPROPERTY(name, 'SpaceUsed') IS NOT NULL; |
After compressing the two indexes above, I get the result:

So, there is some space available for growth. If I wanted to reclaim some of it, I can use the command:
|
1 2 |
DBCC SHRINKFILE (N'AdventureWorks2014_Data', 202) |
This will shrink the data file for the database, giving back some storage to the file system. I’ve created a little stored procedure that does a bit more. It looks at all the files for a given database, then shrinks those that:
- Are large enough to bother with
- Have more than a given amount of free space
- Are on a specific drive (for databases spread across multiple drives)
It first builds a table of candidate files, then processes the files, issuing a DBCC command to shrink those that pass the tests. Consider this proc to be a work in progress. Use it, borrow from it, enhance it or ignore it! I’ve included it at the end of this article
Summary
Compression is a great way to get more mileage out of your database. It’s not hard to find candidate tables and even easier to actually compress them. Plus, as a bonus, your system will the do
the same work with less I/O!
Previous articles in this series:
- How to track SQL Server database space usage with built-in functions and DMVs
- Discovering database specific information using built-in functions and dynamic management views (DMVs)
- Discovering SQL server instance information using system views
- Discovering more SQL Server information using the built-in dynamic management views (DMVs)
See more
Consider these free tools for SQL Server that improve database developer productivity.
References
Shrink Files Stored Procedure
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
IF object_id(N'tempdb..#shrink', N'P') IS NOT NULL DROP PROC #shrink go CREATE PROC #shrink @freepct float = 10.0, @drive char(1) = 'I', @minsize int = 10, @debug bit = 1 AS BEGIN SET NOCOUNT ON; DECLARE @files TABLE (fn sysname primary key, used float, free float); INSERT INTO @files (fn, used, free) SELECT name, s.used/128.0 AS SpaceUsedInMB, (size/128.0) - (s.used/128.0) AS AvailableSpaceInMB FROM sys.database_files CROSS APPLY (SELECT CAST(FILEPROPERTY(name, 'SpaceUsed') AS INT)) s(used) WHERE LEFT(physical_name, 1) = @drive AND FILEPROPERTY(name, 'SpaceUsed') IS NOT NULL; DECLARE cur CURSOR LOCAL READ_ONLY FAST_FORWARD FORWARD_ONLY FOR SELECT fn, used, free FROM @files WHERE free + used > @minsize AND free/used >= @freepct/100 DECLARE @fn sysname, @used float, @free float; OPEN cur WHILE 1 = 1 BEGIN FETCH NEXT FROM cur INTO @fn, @used, @free IF @@FETCH_STATUS <> 0 BREAK DECLARE @newsize int = @used + @used*@freepct/100 DECLARE @stmt nvarchar(255) = N' DBCC SHRINKFILE (N''' + @fn + ''', ' + cast(@newsize AS varchar(10)) + ') ' RAISERROR(@stmt, 0, 0) WITH NOWAIT;; IF @debug = 0 EXEC sp_executesql @stmt = @stmt END CLOSE cur DEALLOCATE cur END |

Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook "Getting Started With Python" and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight
View all posts by Gerald Britton
- Snapshot Isolation in SQL Server - August 5, 2019
- Shrinking your database using DBCC SHRINKFILE - August 16, 2018
- Partial stored procedures in SQL Server - June 8, 2018