

As a DBA, I am often asked why is something performing slow, what and why statistics need to be updated or what will cause them to be “off”. My initial question to clients when they pose these questions to me is what changed on your end? Did the data change significantly and did the rebuild or reorganize index job run? Before I get into the answers to these questions from my clients, let me give you some background. So, just to clarify, for most of my clients, I work as a remote part-time DBA, that being said, I manage their database from every aspect including setting up servers, backups/restore, troubleshooting, managing their index’s, etc. and again remotely. So normally, I have setup jobs that will manage their index’s ranging from a weekly rebuild or even sometimes I use one that I’ve designed that makes a choice to either rebuild or reorganize an index based on fragmentation level. The “general rule of thumb” is reorganizing the index for fragmentation from 5% to 29% and rebuild when 30% plus. Those are pretty standard numbers I did not make them up.

The Situation
Recently on a Monday, a client came to me with a Stored Procedure (sproc) that has always been very efficient and running without issue that was having major performance issues. The sproc normally took less than 20 seconds to run was taking up to an hour and then timing out. EEEEKKK! So as I stated above, I asked my 3 standard questions……. What changed on your end? Did the data change significantly and did the rebuild or reorganize index job run? The client of course told me nothing changed. Of course nothing changed, nothing ever does! So, I logged in to take a look around. Now first, I noticed that my job that makes a decision to rebuild or reorganize ran very early Sunday morning, so before the issues started. I then checked the fragmentation levels of the tables in the sproc and they ranged from 45-78% fragmented. Normally following our rebuild/reorganize they fall under the 5-18% range, so in less than 24 hours later, there was some significant fragmentation happening. Now let me remind you, the client said nothing changed. Do I believe them? Of course NOT!
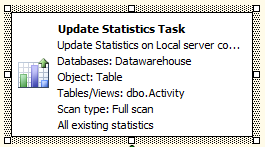
So my initial suggestion on Monday was let’s start with updating the stats in the event there was a major change in the data. By updates, I meant data either coming in or out of the database. I did not want to run the rebuild index job because it takes several hours and did not want to add that “extra drag” on the system just yet. The client promised me “no major data changes occurred. Something is wrong with the server”…I was not convinced…
Duplicating the Issue
So being that this is a production database, we have a protocol to follow that says we must test all changes in the test or staging environments. So we brought down a copy of production to the staging environment. When the developer ran the sproc in this environment, it was taking up to an hour to run then timing out. So great! We can duplicate the issue. I love when we can duplicate the issue because that means we can fix it! Now, being that we just duplicated the data, on a new server and still got the same issue, I had to convince her it was neither the server or a database issue and again insisted that we update stats in the staging environment as a test. They told me no, it has to be something else… Now I pride myself in my customer service skills, so I complied with the clients wishes despite my better judgement and continued on my search for the root cause of this issue. 2 days later, still coming up with nothing new, I again insisted on updating the statistics. Finally after an exhausting 2 days and a very frustrated customer, they agreed to let me update statistics.
The Results and my “I told you so” moment…
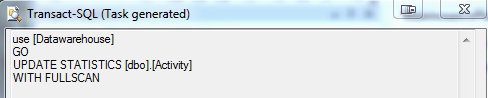
What I find is that many users whether they are developers or application end users is that they do not want to blame their data or their code for causes of problems but rather pass it off on the hardware, server, database or dba. This is unfortunate and frustrating for a DBA since we are there to help. So after 2 days of working with this developer and her sproc, the client finally agrees to let me update stats for the tables in question. Now, I don’t want to brag, however, first the update stats only ran for about 1 minute or so, then we ran the sproc and BAM!….it was back to running in about 20 seconds. Now this is where I start my explanation to the customer on the importance of index’s and statistics and trusting your DBA. Indexes are ever changings entities in the database based on data and data usage. I cannot express this enough. They need to be babysat consistently. Personally I like to create a report that checks fragmentation levels as well as index quality. I have shared this before so be sure to look it up. When data comes and goes index’s may or may not always be valid and the same goes for statistics. Statistics are updated when indexes are rebuilt. So that weekly job I mentioned earlier should normally control statistics getting out of control……..until like in this example, there was a major change in the data almost immediately after rebuilding of Index’s but not caused by the rebuilding of the index. And in this case, it was only about 18 hours, so the client could not believe data could change that significantly in that short amount of time. However, it was so significant it threw it off enough to cause major issues.
Updating Statistics
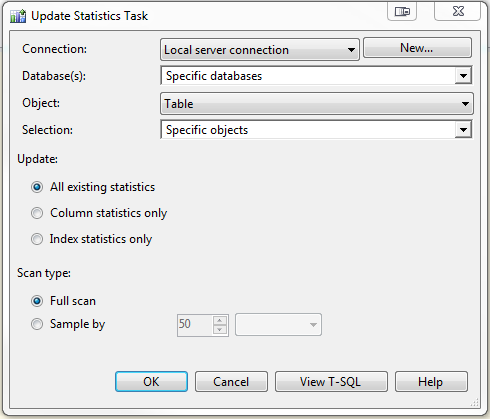 When you update stats, this ensures that your queries are complied with the most current stats. Rebuilding index’s will also update statistics and most likely in cases like described here, would of also solved this problem. There are varied opinions on this topic and many arguments may be stemmed from differing opinions however this is just my two cents on the topic. I find it way easier to evaluate index’s and fragmentation levels initially when someone has a very specific piece of code in this case a stored procedure or table that is causing issues.
When you update stats, this ensures that your queries are complied with the most current stats. Rebuilding index’s will also update statistics and most likely in cases like described here, would of also solved this problem. There are varied opinions on this topic and many arguments may be stemmed from differing opinions however this is just my two cents on the topic. I find it way easier to evaluate index’s and fragmentation levels initially when someone has a very specific piece of code in this case a stored procedure or table that is causing issues.
DBA’s are smart!
In this situation, all signs pointed to what I like to call “data inefficiency”. Because we had a target table, I felt that running update statistics was the quickest and most efficient solution. I did hide my initial eye roll because I wasn’t allowed to run it for 2 days and in the end, I was right when I finally ran it, but I was also glad that something so simple corrected our issue. Do not be afraid to try the simple things first, sometimes they just might work! And as always trust your DBA, we really do know what we are doing, I promise!

For the last 15 years has focused her technology experience within the world of database solutions and specifically with MS SQL Server. She has published numerous articles spotlighting SQL Server and is an expert in monitoring and reporting on SQL Server performance.
View all posts by Kimberly Killian
- How to automatically refresh a SQL Server database - October 4, 2017
- SQL Server Index vs Statistics a consultants woes…or rants - December 29, 2016
- How to Split a Comma Separated Value (CSV) file into SQL Server Columns - December 29, 2016