
With the latest versions of Azure SQL database, Microsoft has introduced a number of new mechanisms to help users and administrators better optimize their workload.
Automatic index management and Adaptive query processing provide us with the possibility to rely on the built-in intelligence mechanism that can automatically tune and improve the performance of our workload.
With minimal effort, we can setup and configure automatic index management feature that dynamically adapts our database schema to our workload. And with adaptive query processing introduced originally with SQL Server 2017 we can rely on the engine to identify queries that can be improved during the current or next execution.
Automatic index management
Automatic index management is an Azure SQL Server and Azure SQL database level option; you can configure it either on your whole logical server or only on a single database.
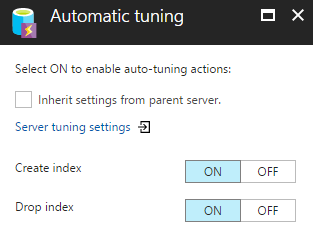
To enable the setting on your logical Azure SQL Server you would need to access the Automatic tuning menu under the Support + Troubleshooting category. The same option can be found in each Azure SQL database under the same menu.
The available options are Create index and Drop index, which are initially set to OFF and inherited from your logical server configuration.
Once the feature is enabled the built-in intelligence mechanism will dynamically adapt to our database schema.
The allowed schema changes are CREATE INDEX and DROP INDEX; No other schema changes can be automatically performed.
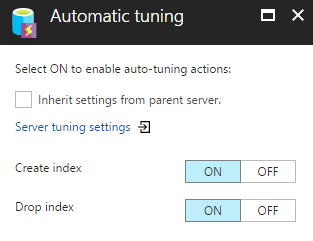
The Create index option will automatically create new indexes that are recommended and found suitable for our workload. Although the addition of indexes provides a great performance benefit where we access our data with read operations they may cause a slowdown to the queries that update data. It is required to approach creating an additional index with caution, wide indexes that include many columns or duplicate indexes are very common occurrences.
During the normal usage and lifecycle of the database, the data and workload type may change resulting in unused indexes that would provide no benefits, but slow down the performance of our database.
The Drop index option will automatically find and remove indexes that provide no benefits.
Relying on the two automatic options together will help us achieve a more optimal set of indexes. Such settings would be the minimal necessary that will optimize our read workload without causing the negative impact on the data update queries.
The Automatic index creation is a great solution for a wide variety of unpredictable heavy read workloads.
In addition, we do have the possibility to monitor the actions that have been performed automatically and, in the case of a need, to revert them by removing a newly created index or restoring an index that was dropped 1.
Adaptive query processing
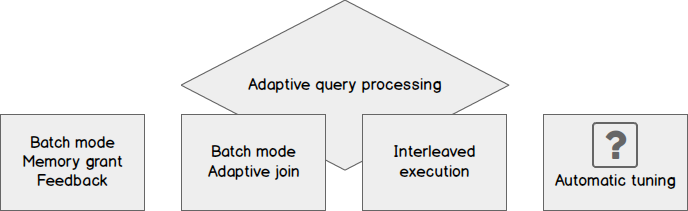
Adaptive query processing in SQL databases was first introduced with SQL Server 2017 and it is now made available within Microsoft Azure for the Azure SQL Databases.
In order to enable the adaptive query processing it is required to alter the compatibility level of our database to ‘140’ as follows:
|
1 2 3 |
ALTER DATABASE [AdventureWorksLT] SET COMPATIBILITY_LEVEL = 140; |
As of now the three available query processing features that are available are batch mode memory grant feedback, batch mode adaptive join, and interleaved execution. Probably within the future we would see Automatic Tuning focused on SQL plan choice regressions implemented within Azure SQL Databases as well.
Batch mode memory grant feedback is a mechanism to locate incorrectly sized memory grant sizes for query plans. Within each query plan, SQL Server will include the minimum required memory that is needed for the execution and what would be the optimal memory grant size to have all query data fit into memory. On some occasions, this size is incorrectly calculated and may result either in excessive or insufficient grants.
Excessive grants are such that result in wasted memory and insufficient grants will cause expensive spills to disk slowing the query processing. Batch mode memory grant feedback recalculates the required memory that is required for problematic query and updates the already cached plan.
For queries with excessive grants that have memory grants more than two (2) times than memory that was actually used, the memory grant will be re-calculated and the cached plan will be updated. For queries with insufficiently size memory grants the batch mode memory grant feedback will be triggered to recalculate the memory grant and update the cached plan.
When the plan is reused by identical query it will use the revised memory grant size, acquiring the needed memory resources.
Batch mode adaptive joins is an operator that will dynamically switch either between hash join or nested loop join. The strategy which join method will be used is decided until after the first input is scanned.
Depending on a threshold set by the Adaptive join if the first input is small enough it can dynamically switch to a nested loop join. The threshold is calculated for each statement depending on the input data.
If the first input row count is above the threshold set by the Adaptive join operator no switch will occur and the query will continue using the hash join.
Workloads that have frequent variations between large and small inputs would benefit the most, as batch mode adaptive joins work for both the initial and all consecutive executions of the statement. The consecutive executions will be adaptive as well based on the compiled adaptive join threshold. You can now revise your workload where JOIN hints are used and test if the adaptive join improves both large and small inputs.
The cached plan will be recompiled 2 as usual when schema change occurs or when the plan is not optimal.
Note that the adaptive join operator can only be viewed when using SQL Server Management Studio 17 3.
Interleaved execution is mechanism to help fight cardinality issues caused by Multi-Statement-Table-Valued-Functions (MSTVF). Up until now, the SQL Server compiler was not able to use any table statistics on the tables from within the MSTVF and fixed cardinality value of ‘100’ in SQL Server 2016 and SQL Server 2014 was used. Older versions used a value of ‘1’.
Starting with SQL Server 2017 and Azure SQL databases with compatibility mode of ‘140’, during the optimization phase of a query, when the compiler faces a candidate for interleaved execution, (MSTVF) it will pause and then execute the query subtree for the Multi-Statement-Table-Valued-Functions and finally capture the correct and real cardinality estimation and resume with the previously paused operations.
As of now, within the CTP2.1 release of SQL Server 2017, the interleaved execution mechanism has limitations that MSTVF should be performing only read-only operations and should not be used with a CROSS APPLY operator.

View all posts by Kaloyan Kosev
- Performance tuning for Azure SQL Databases - July 21, 2017
- Deep dive into SQL Server Extended events – The Event Pairing target - May 30, 2017
- Deep dive into the Extended Events – Histogram target - May 24, 2017