In this article, we will explore ‘ Clustered columnstore online index build and rebuild’ feature of SQL Server 2019 including comparing execution plans, offline builds and more
Read more »
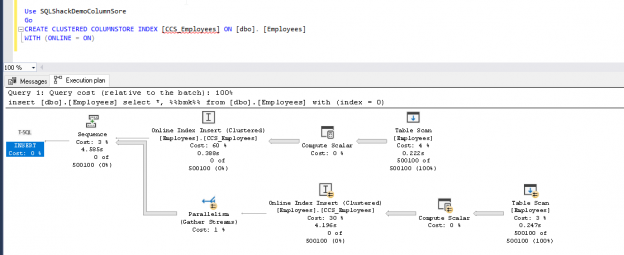
In this article, we will explore ‘ Clustered columnstore online index build and rebuild’ feature of SQL Server 2019 including comparing execution plans, offline builds and more
Read more »
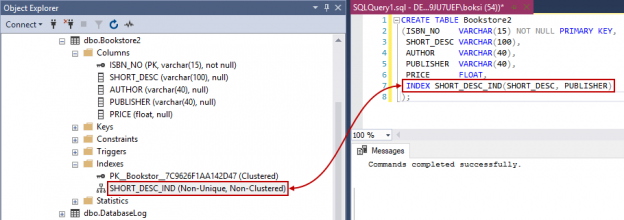
A SQL index is used to retrieve data from a database very fast. Indexing a table or view is, without a doubt, one of the best ways to improve the performance of queries and applications.
A SQL index is a quick lookup table for finding records users need to search frequently. An index is small, fast, and optimized for quick lookups. It is very useful for connecting the relational tables and searching large tables.
Read more »
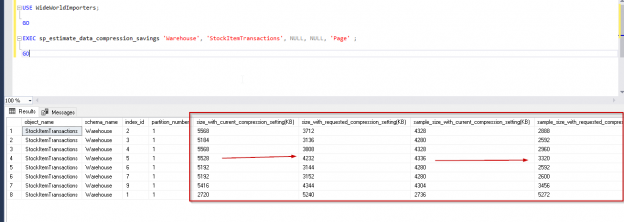
Data compression is required to reduce database storage size as well as improving performance for the existing data. SQL Server 2008 introduced Data compression as an enterprise version feature. Further to this, SQL Server 2016 SP1 and above supports data compression using the standard edition as well.
Read more »
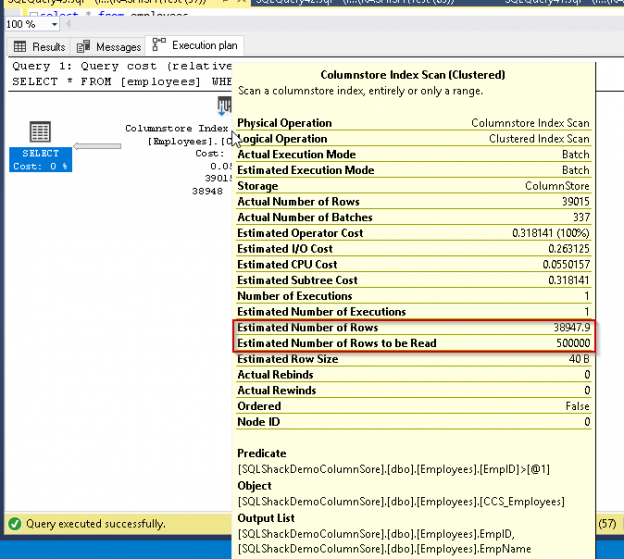
SQL Server was launched in 1993 on WinNT and it completed its 25-year anniversary recently. SQL Server has come a long way since its first release. At the same time, Microsoft announced a preview version of SQL Server 2019. SQL Server 2019 provides the ability to extend its support to big data, Apache Spark, Hadoop distributed file system (HDFS) and provides enhancements to database performance, security, new features, and enhancements to SQL Server on Linux.
Read more »
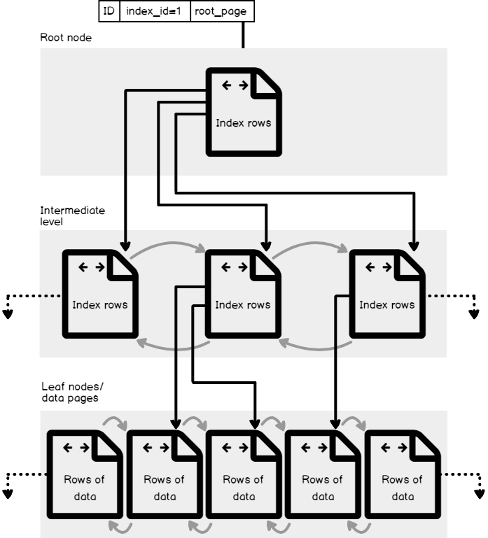
In this series, we will dive deeply in the SQL Server Indexing field, starting from the surface by understanding the internal structure of the SQL Server tables and indexes, going deeper by describing the guidelines and best practices that we can follow to design the most efficient index and what operations can be performed on the created indexes. Having these knowledges about the SQL Server indexes, we have all the tools that help us in testing the lower part of the ocean and dive deeper with the two main types of the SQL Server Indexes; the Clustered and Non-Clustered, and the other types of indexes that can be customized to serve us improving your environment. After that, the adventure becomes more interesting when learning how to use this knowledge to tune the performance of our queries and touch the bottom of the ocean. In our way back to the surface, and before celebrating our achievements, we will collect statistical information about these indexes and use this information to maintain the indexes to take benefits from it continuously and gain the best application performance.
Read more »
A Heap table is a table in which, the data rows are not stored in any particular order within each data page. In addition, there is no particular order to control the data page sequence, that is not linked in a linked list. This is due to the fact that the heap table contains no clustered index.
Read more »
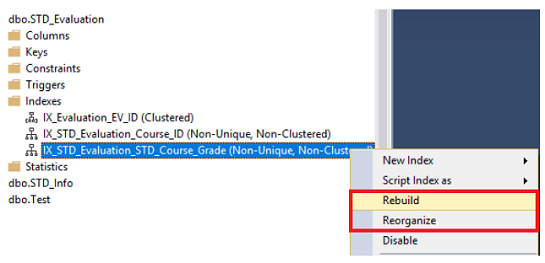
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of SQL Server tables and indexes, the guidelines that you can follow in order to design a proper index, the list of operations that can be performed on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes (above and beyond Clustered and Non-clustered indexes classification), how to tune the performance of the inefficient queries using different types of SQL Server Indexes and finally, how to gather statistical information about index structure and the index usage. In this article, the last article in this series, we will discuss how to benefit from the previously gathered index information in maintaining SQL Server indexes.
Read more »
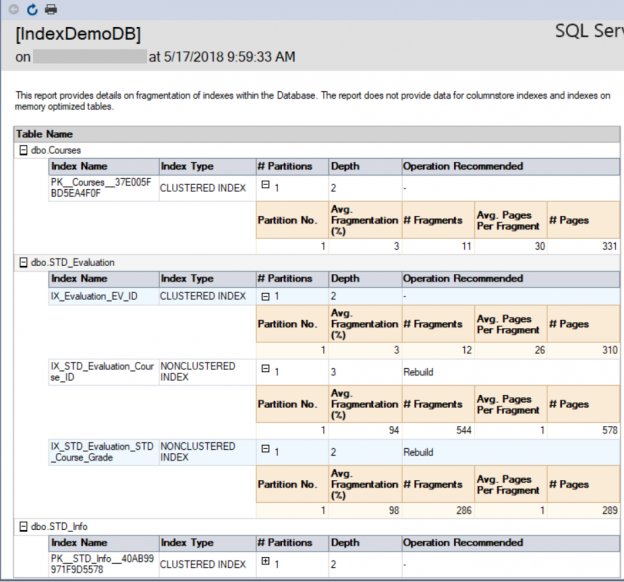
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both the SQL Server tables and indexes, the best practices that you can follow in order to design a proper index, list of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification and finally how to tune the performance of the bad queries using the different types of SQL Server Indexes. In this article, we will discuss how to gather statistical information about the index structure and the index usage information.
Read more »
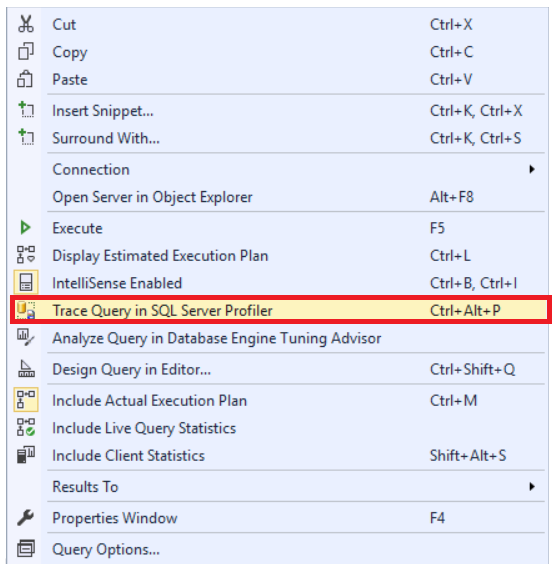
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of the SQL Server tables and indexes, the best practices to follow when designing a proper index, the group of operations that you can perform on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes and finally the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification. In this article, we will discuss how to tune the performance of the bad queries using SQL Server Indexes.
Read more »
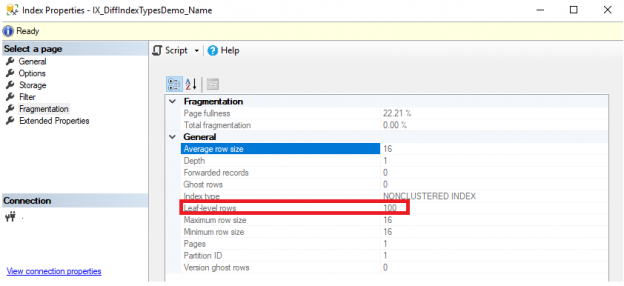
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both SQL Server tables and indexes, the main guidelines that you can follow to design a proper index, the list of operations that can be performed on the SQL Server indexes, and finally how to design effective Clustered and Non-clustered indexes that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of creating an index. In this article, we will go through the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification, and when to use them.
Read more »
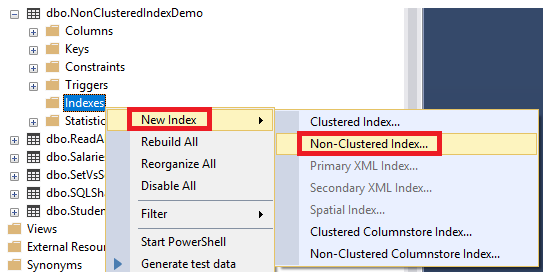
In the previous articles of this series (see below for the full index of articles), we went through the internal structure of SQL Server tables and indexes, listed a number of guidelines that help in designing a proper index, discussed the operations that can be performed on SQL Server indexes and finally showed how to design and create a SQL Server Clustered index to speed up data retrieval operations. In this article, we will see how to design an effective Non-clustered index that will improve the performance of frequently used queries that are not covered with a Clustered index and, in doing so, enhance the overall system performance.
Read more »
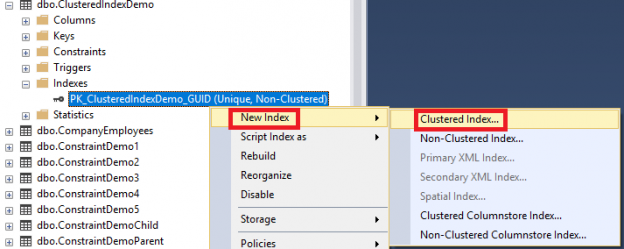
In the previous articles of this series (see bottom for a full index), we described, in detail, the structure of SQL Server tables and indexes, the basics and guidelines that help us in designing a proper index and finally the list of operations that can be performed on the SQL Server indexes. In this article, we will see how we could design an effective clustered index that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of building an index.
Read more »
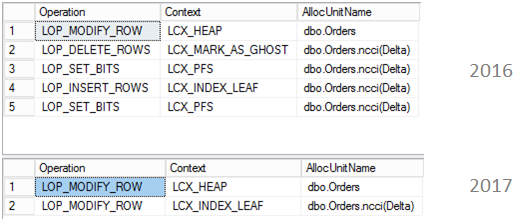
In this post, I continue the exploration of SQL Server 2017 and we will look at the nonclustered columnstore index updates.
Columnstore index has some internal structures to support updates. In 2014 it was a Delta Store – to accept newly inserted rows (when there will be enough rows in delta store, server compresses it and switches to Columnstore row groups) and a Deleted Bitmap to handle deleted rows. In 2016 there are more internal structures, Mapping Index for a clustered Columnstore index to maintain secondary nonclustered indexes and a deleted buffer to speed up deletes from a nonclustered Columnstore index.
Updates were always split into insert + delete. But that is now changed, if a row locates in a delta store, now inplace updates are possible. Another change is that it is now possible to have a per row (narrow) plan instead of per index (wide) plan.
Let’s make some experiments.
Read more »
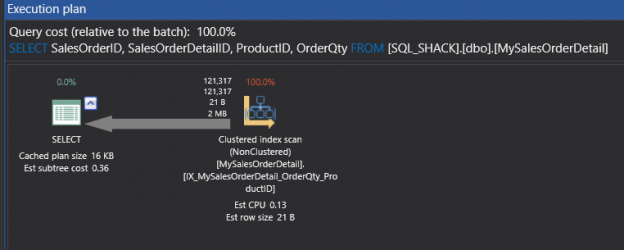
Now that we understand what Clustered Index Scan and Clustered Index Seek are, how they occur, and how to eliminate table scans in my previous article SQL Server Query Execution Plans for beginners – Clustered Index Operators, the next topic would be looking at Non-Clustered Indexes
Read more »
In the previous articles of this series, we described the structure of the SQL Server tables and indexes, the main concepts that are used to describe the index and the basics and guidelines that are used to design the proper index. In this article, we will go through the operations that can be performed on the SQL Server indexes.
Before creating an index, it is better to follow the index design guidelines and best practices that are described in the previous article, to determine the columns that will participate in the index, the type of the created index, the suitable index options, such as the FillFactor or Sort in TempDB, and the storage location of that index.
Read more »
SQL Server indexes are essentially copies of the data that already exist in the table, ordered and filtered in different ways to improve the performance of executed queries. Seeks, scans and lookups operators are used to access SQL Server indexes.
Read more »
In the previous article of this series, SQL Server Index Structure and Concepts, we described, in detail, the anatomy of QL Server indexes, the B-Tree structure, the properties of the indexes, the main types of indexes and the advantages of using the indexes for performance tuning.
Read more »
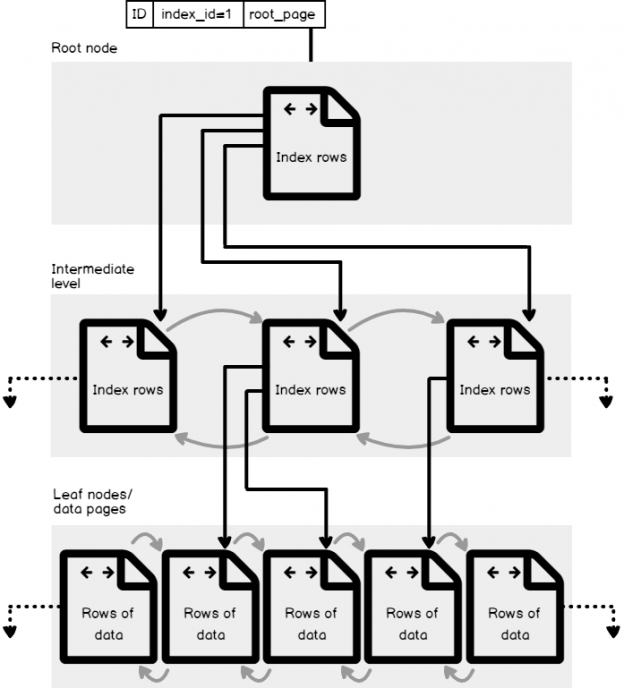
In my previous article, SQL Server Table Structure Overview, we described, in detail, the difference between Heap table structure, in which the data pages are not sorted in any ordering criteria and the pages itself are not sorted or linked between each other, and Clustered tables, in which the data is sorted within the data pages and the pages will be also linked in a double linked list, based on the index key. In this article, we will go through the structure of the SQL Server index, itself.
Read more »
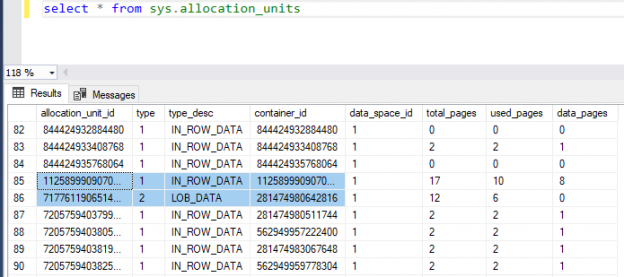
Microsoft SQL Server is a relational database management systems (RDBMS) that, at its fundamental level, stores the data in tables. The tables are the database objects that behave as containers for the data, in which the data will be logically organized in rows and columns format. Each row is considered as an entity that is described by the columns that hold the attributes of the entity. For example, the customers table contains one row for each customer, and each customer is described by the table columns that hold the customer information, such as the CustomerName and CustomerAddress. The table rows have no predefined order, so that, to display the data in a specific order, you would need to specify the order that the rows will be returned in. Tables can be also used as a security boundary/mechanism, where database users can be granted permissions at the table level.
Read more »
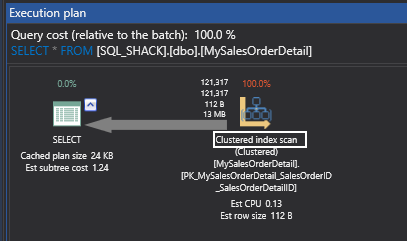
We have discussed how to created estimated execution plans and actual execution plans in various formats in my previous article SQL Server Query Execution Plan for beginners – Types and Options.
In this article we will continue discussing the various execution plan operators related to clustered indexes, and what they do, when do they appear and what happens when they do.
Read more »
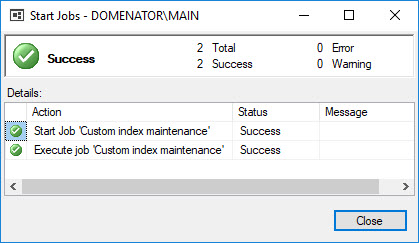
This is the third article in Ola Hallengren’s SQL Server Maintenance Solution series. The article will cover the IndexOptimize stored procedure in more detail, along with the index optimization jobs created by Ola Hallengren’s scripts.
Read more »
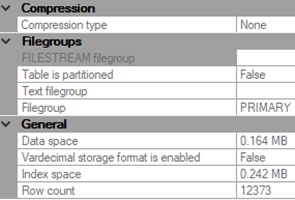
We recently inherited a database environment where we’re facing significant data growth with limits on the sizes we can allow our databases to grow. Since we maintain multiple development, QA and production environments and these environments must be sized appropriately. We set a few standards about tables that exceed certain sizes – rows, data or both, or have certain growth patterns and our standards force compression at thresholds we set for our different environments (including using page, row, or clustered columnstore index compression) We’re looking for how we can get information about data and compression in tables and options we have so that we can quickly determine candidates that don’t currently match our best practices design we’ve set for our environments.
Read more »
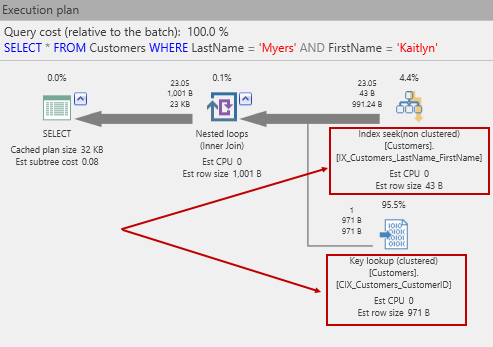
Without a doubt, few technologies in SQL Server cause as much confusion and the spread of misinformation as indexes. This article looks at some of the most asked questions and a few that should be asked but often are not. We’ll be using SQL Server 2016 for the examples and a tool, for SQL Server query execution plan analysis, ApexSQL Plan, to explore the effects of indexes on a typical business problem: A table of customers.
Read more »
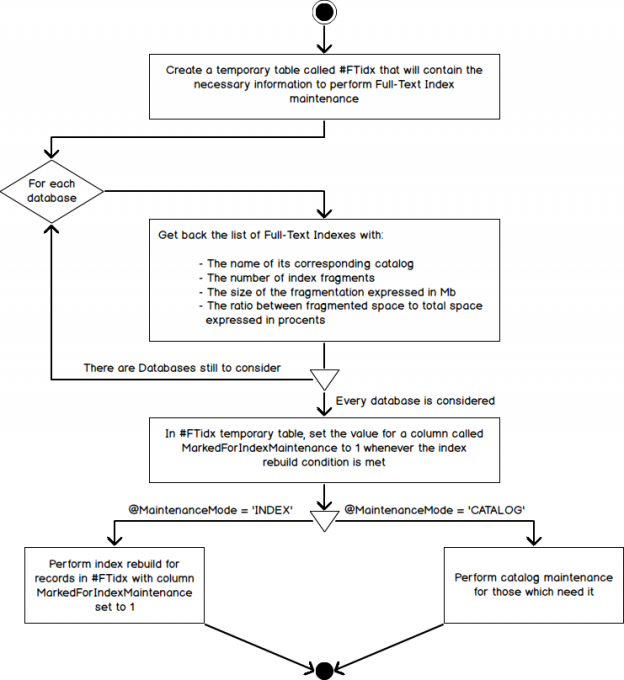
In a previous article entitled Hands on Full-Text Search in SQL Server, we had an overview on the Full-Text feature as it’s implemented in SQL Server. We saw how to create Full-Text indexes and that they were stored inside a container called a Full-Text catalog. We’ve also seen that, by design, this kind of index will generate a fragmentation.
Read more »
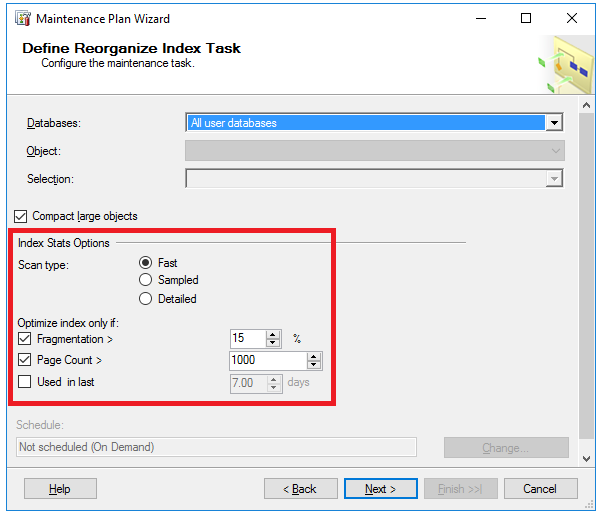
SQL Server Maintenance Plans is a SQL Server Management Studio built-in feature that helps in creating a workflow of variant database administration tasks, which can be run automatically using a predefined schedule or manually triggered by the user.
SQL Server Maintenance Plans allow you to use typical database maintenance tasks or customize your own task using a T-SQL script that runs on the local server or group of SQL Servers, providing more flexibility to the database administration tasks.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy