
In the previous articles of this series (see bottom for a full index), we described, in detail, the structure of SQL Server tables and indexes, the basics and guidelines that help us in designing a proper index and finally the list of operations that can be performed on the SQL Server indexes. In this article, we will see how we could design an effective clustered index that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of building an index.
Clustered index structure overview
In a Clustered table, a SQL Server clustered index is used to store the data rows sorted based on the clustered index key values. SQL Server allows us to create only one Clustered index per each table, as the data can be sorted in the table using one order criteria. In the heap tables, the absence of the clustered index means that the data is not sorted in the underlying table.
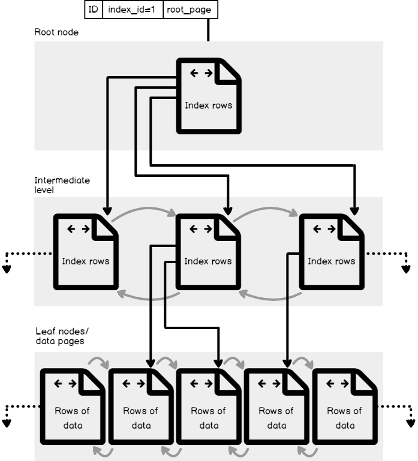
The clustered index is organized as 8KB pages using the B-tree structure, to enable the SQL Server Engine to find the requested rows associated with the index key values quickly. Each page in the index B-tree structure is considered as an index node. The top-level node is called the Root node and the bottom level nodes are called the Leaf nodes, where the table data pages are stored and sorted based on the index key values. All nodes that are located between the root and the leaf nodes are called the Intermediate level nodes. All pages located in the root and intermediate levels contain the sorted index key values with a pointer to the next intermediate level node or the data page in the index leaf level. In addition to sorting the data in the index pages based on the index key values, the pages itself will be sorted and linked in a doubly-linked list within the index. Any new value inserted into that index will follow the index key ordering sequence among the existing rows.
A SQL Server clustered index contains one or more allocation units that are used to store and manage the stored data depending on the data types of the key columns in that index, with the IN_ROW_DATA allocation unit available in all clustered indexes. The LOB_DATA allocation unit will be used in the clustered index that has large object data (LOB) and ROW_OVERFLOW_DATA allocation unit for the variable length columns that exceed the 8,060-byte size limit of the row. The figure shown below from Microsoft Books Online summarizes the described structure of the clustered index in a single partition, that will always have an index_id value equal to 1 in the sys.partitions table:
Clustered index design considerations
The clustered index can be beneficial for the queries that read large result sets of ordered sequential data. In this case, the SQL Server Engine will locate the row with the first requested value using the clustered index, and continue sequentially to retrieve the rest of rows that are physically adjacent within the index pages with the correct order, without consuming the SQL Server Engine time and resources in sorting the data that is already sorted in the clustered index, affecting the overall query performance positively. For example, if the query returns all rows with ID value large than 950, the SQL Server Engine will use the clustered index to locate the row with ID value equal to 950 and continue retrieving the rest of rows sequentially.
The characteristics of the best clustering keys can be summarized in few points that are followed by most of the designers:
- Short: Although SQL Server allows us to add up to 16 columns to the clustered index key, with maximum key size of 900 bytes, the typical clustered index key is much smaller than what is allowed, with as few columns as possible. The wide Clustered index key will also affect all non-clustered indexes built over that clustered index, as the clustered index key will be used as a lookup key for all the non-clustered indexes pointing to it.
- Static: It is recommended to choose the columns that are not changed frequently in the clustered index key. Changing the clustered index key values means that the whole row will be moved to the new proper page to keep the data values in the correct order.
- Increasing: Using an increasing column, such as the IDENTITY column, as a clustered index key will help in improving the INSERT process, that will directly insert the new values at the logical end of the table. This highly recommended choice will help in reducing the amount of memory required for the page buffers, minimize the need to split the page into two pages to fit the newly inserted values and the fragmentation occurrence, that required rebuilding or reorganizing the index again.
- Unique: It is recommended to declare the clustered index key column or combination of columns as unique to improve the queries performance. Otherwise, SQL Server will automatically add a uniqueifier column to enforce the clustered index key uniqueness.
- Accessed frequently: This is due to the fact that the rows will be stored in the clustered index in a sorted order based on that index key that is used to access the data.
- Used in the ORDER BY clause: In this case, no need for the SQL Server Engine to sort the data in order to display it, as the rows are already sorted based on the index key used in the ORDER BY clause.
Clustered index key appropriate data types
When designing a clustered index, you should consider that some data types are generally better than other data types to be used as clustering keys. For instance, the columns with SMALLINT, INT and BIGINT data types are the best choices as clustered index keys, especially when used in conjunction with the IDENTITY constraint, that enforces their values to increase sequentially. In addition, the IDENTITY integer values are narrow, due to its small size, unique, if you enforce the column uniqueness with a constraint, and static, as they are generated automatically by the system and not visible to the users.
Although the GUIDs values, that are stored in the uniqueidentifier columns, are commonly used as clustered index key, there are some challenges that accompany that design. The main challenge that affects the clustered index key sorting performance is the nature of the GUID value that is larger than the integer data types, with 16 bytes size, and that it is generated in random manner, different from the IDENTITY integer values that are increasing continuously. The large size and randomness generation of the GUID values will always lead to the page splitting and index fragmentation problems, which negatively affect the clustered index usage performance.
The Character data types can be also used, but not recommended, as clustered index keys. This is due to the limited sorting performance of the character data types, the large size, non-increasing values, non-static values that often tend to change in the business applications and not compared as binary values during the sorting process, as the characters comparison mechanism depends on the used collation. Even though the Date data types are not unique, it has a small size and provides good sorting performance, especially for the queries that search for data ranges.
Clustered index implementation
When you create a PRIMARY KEY constraint on a table, a unique clustered index will be created automatically on the column or columns that participate in that constraint to enforce the PRIMARY KEY constraint, given the same name as the constraint name, unless you already defined a clustered index on the same table. SQL Server allows you to specify the type of the index that will be created automatically when you create a UNIQUE constraint to be clustered index, if there is no clustered index created on that table, due to the fact that, only one clustered index can be created per each table. You can also create the clustered index independently from the constraints if a non-clustered index is used to enforce the PRIMARY KEY constraint.
A clustered index can be created using SQL Server Management Studio or using CREATE CLUSTERED INDEX T-SQL command. To be able to create a clustered index, the user should be a member of db_owner and db_ddladmin fixed database roles or member of sysadmin fixed server role.
Let us create a new table to be used in our demo, in which the PRIMARY KEY constraint will use a non-clustered index to enforce it, using the CREATE TABLE T-SQL statement below:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE SQLShackDemo GO CREATE TABLE ClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, GUID uniqueidentifier NOT NULL, EmployeeName NVARCHAR(200) NOT NULL, BirthDate DATETIME NOT NULL, EmployeeAddress NVARCHAR(MAX), CONSTRAINT PK_ClusteredIndexDemo_GUID PRIMARY KEY NONCLUSTERED (GUID) ) |
Having no clustered index defined in the previous table, we can create a clustered index using the SQL Server Management Studio by browsing the table on which we need to create the clustered index on, then right-click on the Indexes node under that table and from the New Index option choose the clustered index type, as shown below:
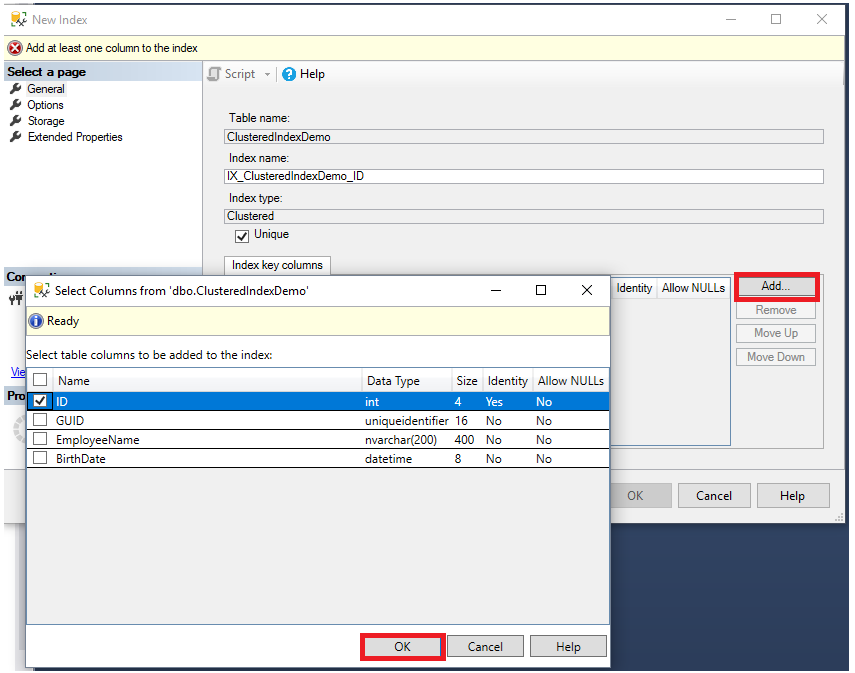
From the displayed New Index dialog box, the name of the table on which the index will be created, and the type of the index will be filled automatically. You need to provide the name of the index, following your company naming convention, the uniqueness of that index key values and from the Add button you can choose the column or list of columns that will participate in that index key, as shown below:
You can also perform the same task from the Table Designer, by right-clicking on the table on which the index will be created and choose Design option as below:
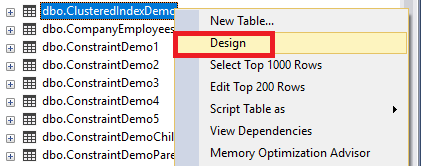
On the displayed Table Designer window, right-click on the empty space and choose Indexes/Keys option shown below:
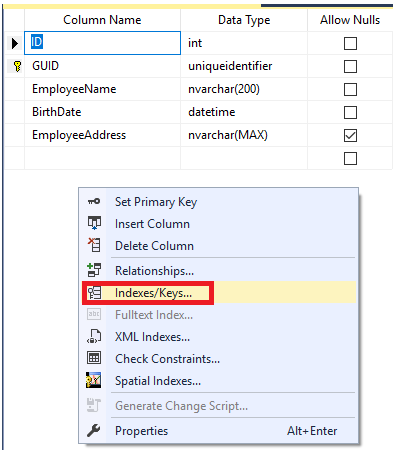
From the appeared dialog box, click on the Add bottom to add a new clustered index, by setting Create As Clustered to Yes, Specify the index name, the clustered index key uniqueness and the list of columns, with the proper sorting order, that will be included in the clustered index key, as shown below:
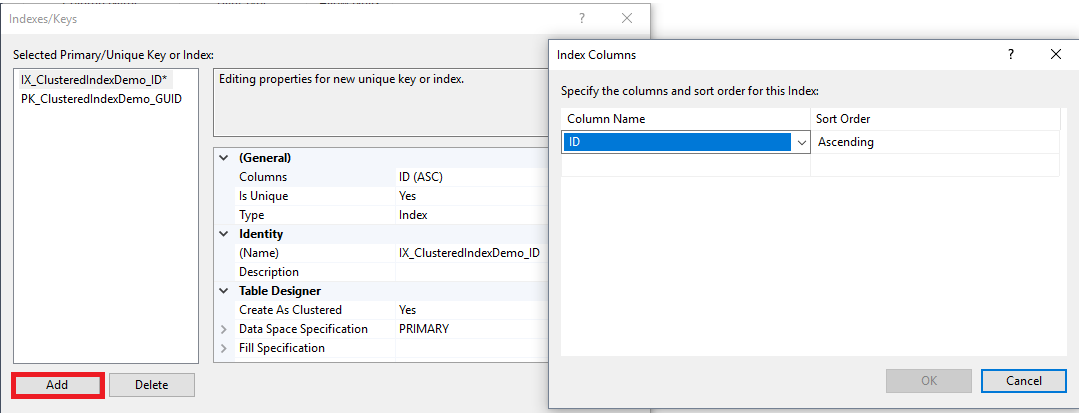
The clustered index can be also created using the CREATE CLUSTERED INDEX T-SQL command, by specifying the index name, the name of the table on which the index will be created, the clustered index key values uniqueness and the list of columns that will be included to the clustered index key, as shown below:
|
1 2 3 4 5 |
CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( ID ASC ) WITH( SORT_IN_TEMPDB = ON, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Consider taking benefits from the list of index creation options specified in the previous CREATE INDEX statement, especially when creating a clustered index on large tables, in order to improve the performance of the index creation process.
Performance comparison
To proceed with the demo, let us fill the created table with 100K records, using ApexSQL Generate, as shown below:
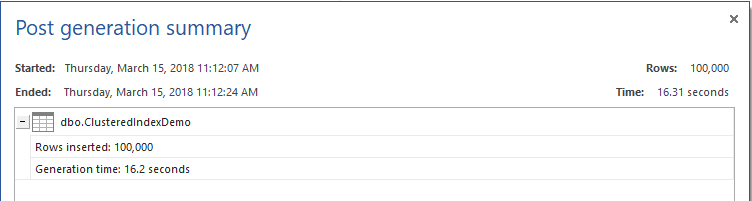
Until this point, the table is filled and sorted based on the ID column. If we execute the below SELECT query that searches based on the ID column and check the TIME and IO statistics generated by executing the query:
|
1 2 3 4 5 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE ID>1000 and [EmployeeAddress] LIKE '%Hillcrest%' |
The generated statistics will show that 1075 logical read operations are performed to retrieve the requested data, 203ms consumed from the CPU time and 255ms taken to execute the query, as shown below:

If we drop the clustered index and create a new one using the GUID column:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( GUID ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
And execute the below SELECT statement that searches based on the GUID column values:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE GUID <> 'CB2F45A0-185F-9884-88EB-B7C497AB61EA' and [EmployeeAddress] LIKE '%Hillcrest%' |
The generated Time and IO statistics will show that 1196 logical read operations are performed to retrieve the requested data based on the GUID column values, 2018ms consumed from the CPU time and 276ms taken to execute the query. All counters show that using the GUID column as clustered index key is worse than using the ID column, as shown below:

|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( EmployeeName ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
Then execute the below SELECT statement that searches based on the EmployeeName column values:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE [EmployeeName] <> 'Gianna' and [EmployeeAddress] LIKE '%Hillcrest%' |
You will see from the generated Time and IO statistics that, 1287 logical read operations are performed to retrieve the requested data based on the EmployeeName values, 2018ms consumed from the CPU time and 289ms taken to execute the query. All counters again indicate that using the EmployeeName character column as clustered index key is worse than using the ID and the GUID columns, as shown below:

If we drop the clustered index and create a new one using the BirthDate datetime column:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( BirthDate ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
And execute the below SELECT statement that searches based on the BirthDate column values:
|
1 2 |
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE BirthDate BETWEEN '1950-01-01' AND '1950-12-31' AND [EmployeeAddress] like '%Hillcrest%' |
The Time and IO statistics generated after executing the query will show that only 7 logical read operations are performed to retrieve the requested data based on the BirthDate range values, 0ms consumed from the CPU time and 47ms taken to execute the query. It is clear from the result that, using the BirthDate Datetime column as clustered index key is the best choice when searching based on date range, as shown below:

Finally, if you try to drop the clustered index and create a new one using the EmployeeAddress character column:
|
1 2 3 4 5 6 7 |
DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( EmployeeAddress ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
The CREATE INDEX statement will fail, showing that the NVARCHAR(MAX) data type is not allowed as a clustered index key, as shown in the error message below:

As you can from the previous results, a clustered index that is designed properly can reduce the I/O and CPU resources consumption amount, therefore improving the queries and overall system performance. The SQL Server Query Optimizer decides to use the clustered index to retrieve the requested data, as it is more efficient, much faster and fewer resources consumer than scanning the whole table, in addition to having the data sorted in the index pages.
Take into consideration that, when you create a clustered index on a table, all non-clustered indexes created on that heap table will be rebuilt to replace the row identifier (RID) with the clustered index key. So that, it is better always to start with creating the clustered index then proceed with creating the non-clustered index over it.
In this article, we tried to cover all aspects of the clustered index design subject. In the next article of this series, we will discuss how to design an effective and optimal Non-clustered index. Stay tuned!Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021