
Introduction
Without a doubt, few technologies in SQL Server cause as much confusion and the spread of misinformation as indexes. This article looks at some of the most asked questions and a few that should be asked but often are not. We’ll be using SQL Server 2016 for the examples and a tool, for SQL Server query execution plan analysis, ApexSQL Plan, to explore the effects of indexes on a typical business problem: A table of customers.
Question 1: What is an index?
Once upon a time, the most common examples of where indexes are used were dictionaries and telephone books. In today’s connected society with available online resources that would have been dismissed as little as twenty years ago as pure fantasy, it’s entirely possible that you have never held either one in your hands! So, let’s look at an online resource: The list of endangered species maintained by the World Wildlife Fund on their website at www.worldwildlife.org. The list begins like this:
It continues and has two pages as of this writing. A quick glance at the list tells you that the species are arranged alphabetically by their common name. Imagine though, that you are a biologist and are used to using the Latin names. How would you find the entry for the Thunnus and Katsuwonus species? Well, you’d need to read right to the very end of the list, since that has the common name tuna (like the one in your sandwich!) and is the last one in the alphabetical list by common name. “Fine!” you think. It’s not so hard to read through two pages to find what I’m looking for.
Now, imagine that this list holds all the known species in the world (about 8.7 million) similarly arranged. Reading through that list to find a species by its Latin name would not be much fun for you and would need a lot of I/O on a computer. In a database, I/O is often (if not always) the single greatest bottleneck.
If we can reduce the I/O required to find the information we want, we can effectively give the bottle a bigger neck.
This reduction will also lead to secondary benefits, such as reduced CPU time, waits, cache use and more.
The goal of an index on a database table then is to reduce I/O. To understand how this works, we need to first look at a table that has no indexes.
Question 2: What does a table look like without indexes?
SQL Server keeps all data in all its files for all databases in 8K pages. There are at least two files for every database: one for the data, which has the default file type .mdf, and one for the log, which uses .ldf for the default file type. Each table in the database has one or more pages. To keep track of those pages, SQL Server uses a special set of pages, called IAM (for Index Allocation Map) pages. In spite of the word “Index” in the name, IAMs are used for non-indexed tables as well. These are called heaps.
A heap is pretty much like what its name implies: an unordered pile of stuff. That could be your dirty laundry, or leftover construction materials, or the mess left on the beach by a high tide or, as in this case, a bunch of pages for a table in SQL Server. Nothing is organized in any way, except the IAM pages, which are chained together so SQL Server can find all the data pages for the table. Graphically it looks a bit like this:
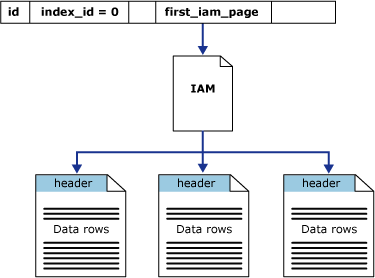
Source: ©Microsoft.com
All the data is there, but the only way to find anything is to read it starting at the beginning. For a very large table, this will be terribly inefficient. Let’s see what happens with just such a table.
We’ll start off by creating a table of customers. First, here’s the DDL for the customer table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE TABLE [dbo].[Customers]( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](255) NULL, [LastName] [nvarchar](255) NOT NULL, [Street] [nvarchar](255) NOT NULL, [StreetNumber] [nchar](10) NOT NULL, [Unit] [nchar](10) NULL, [City] [nvarchar](255) NOT NULL, [StateProvince] [nvarchar](255) NOT NULL, [ISO3_Country] [char](3) NOT NULL, [EmailAddress] [varchar](254) NULL, [HomePhone] [numeric](15, 0) NULL, [MobilePhone] [numeric](15, 0) NULL ) ON [PRIMARY] |
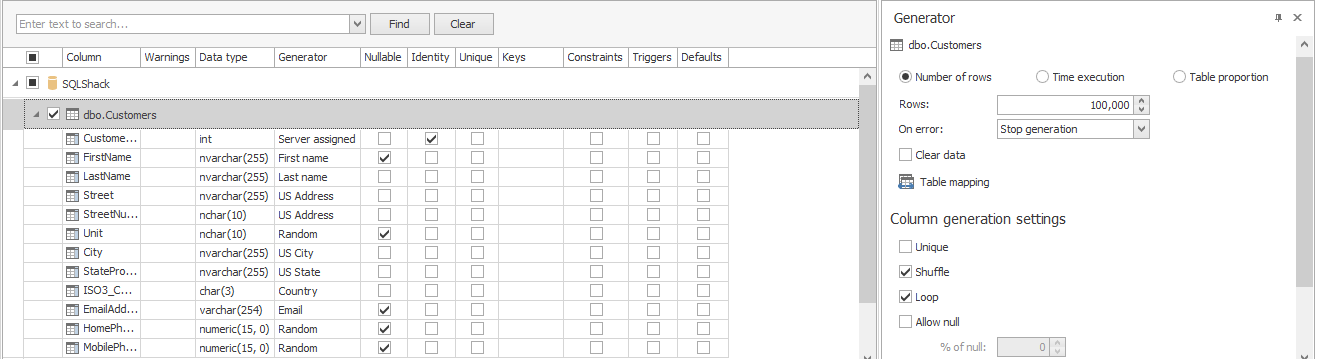
Next, let’s fill it up with data using ApexSQL Generate:
Now, let’s use ApexSQL Plan to explore this simple query:
|
1 2 3 |
SELECT * FROM Customers where CustomerID = 50000; |
When we view the estimated execution plan we see:
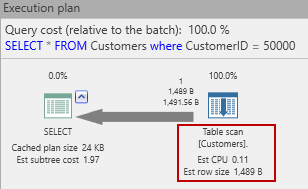
The main thing SQL Server will do is a table scan. That means it will read all the rows of this table until it finds one with a customer id of 50000. Interestingly, if we hover over the big right-to-left arrow in the estimated plan, we see this:

Estimated rows = 1! That’s because SQL Server expects just one customer with the matching id. There could be more (since at this point there’s nothing to prevent it) but there’s just no way to know for sure.
OK, now let’s run this query to see what we can learn. The most interesting thing to see is the I/O reads tab:

There are 2506 logical reads – one for every page in the table. Also, there is an equal number of read-ahead reads. These are physical reads that SQL Server does in anticipation of their being needed. So, how much of the table is that? This query tells us how many pages are used by this table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT t.NAME AS TableName, p.rows AS RowCounts, SUM(a.total_pages) AS TotalPages, SUM(a.used_pages) AS UsedPages, (SUM(a.total_pages) - SUM(a.used_pages)) AS UnusedPages FROM sys.tables t INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id WHERE t.NAME = 'Customers' AND t.is_ms_shipped = 0 AND i.OBJECT_ID > 255 GROUP BY t.Name, p.Rows ORDER BY t.Name |
And this query tells us:

That’s right! SQL Server had to read all but one of the pages used in the table! Perhaps you thought that it would find the matching row about half-way through? That would be the expected runtime, right? O(n/2)? But since SQL Server is doing read ahead operations, to minimize the number of read operations, it winds up reading all the data pages. (The other page contains metadata.)
If this table was part of a busy OLTP system and had millions of rows and thousands of simultaneous searches, this would put a nasty drag on system resources. Even if you could hold the whole table in the buffer pool, that would make those buffers unavailable for other queries. Either way, this will make for a sickly server. Appropriate indexing is the cure!
Question 3: What types of indexes are available in SQL Server?
SQL Server supports indexing for a variety of needs. Borrowing from the Microsoft documentation, these are available in SQL Server 2016:
| Type | Description |
| Clustered | A clustered index sorts and stores the data rows of the table or view in order based on the index key. This type of index is implemented as a B-tree structure that supports fast retrieval of the rows, based on their key values. |
| Nonclustered | A nonclustered index can be defined on a table or view with a clustered index or on a heap. Each row in the index contains the key value and a row locator. This locator points to the data row in the clustered index or heap having the key value. The rows in the index are stored in the order of the key values, but the data rows are not guaranteed to be in any particular order unless they are in a clustered index. |
| Unique | A unique index ensures that the key contains no duplicate values and therefore every row in the table or view is in some way unique. |
| Index with included columns | A nonclustered index that is extended to include nonkey columns in addition to the key columns. |
| Full-text | A special type of token-based functional index that is built and maintained by the Microsoft Full-Text Engine for SQL Server. It provides efficient support for sophisticated word searches in character string data. |
| Spatial | A spatial index provides the ability to perform certain operations more efficiently on spatial objects (spatial data) in a column of the geometry data type. The spatial index reduces the number of objects on which relatively costly spatial operations need to be applied. |
| Filtered | An optimized nonclustered index, especially suited to cover queries that select from a well-defined subset of data. It uses a filter predicate to index a portion of rows in the table. A well-designed filtered index can improve query performance, reduce index maintenance costs, and reduce index storage costs compared with full-table indexes. |
| XML | A shredded, and persisted, representation of the XML binary large objects (BLOBs) in the xml data type column. |
Source: ©2017 Microsoft
Full-text, Spatial and XML indexes are outside the scope of this article. We’ll concentrate on clustered and non-clustered indexes and look at some of their extensions including unique and filtered indexes and the usefulness of included columns. Although not mentioned above, we will also not be looking at columnstore indexes in this article, nor in-memory tables.
As described above, a clustered index affects how the data is actually stored. In a heap, the data rows are stored in no particular order. They are written wherever they fit while putting the minimum load on SQL Server resources, such as the buffer pool and the I/O subsystem. On the other hand, when you create a clustered index on a table, the organization of the data is changed so that it is now in order according to the keys specified. The entire index is organized as a B-tree (“B” stands for balanced), where the leaf nodes are the actual data pages and one or more levels of index nodes are built on top of the leaf nodes up to the single, root node. The result provides some guarantees regarding the asymptotic performance of the index. Most operations (search, insert and delete) operate in O (log n) where n is the number of entries in the index.
A nonclustered index shares the B-tree concept for the index nodes with the same performance guarantees. However, such indexes do not affect the organization of the data pages, which may be clustered or not. Some optional features of nonclustered indexes are:
- Unique indexes – where the index entries must be unique and SQL Server makes sure that they are
- Filtered indexes – which are indexes built with a WHERE clause to limit what gets included in the index
- Included columns – which can carry a subset of non-key columns as part of the index.
If you think through the implications of these descriptions, you should be able to see that a table is either a heap or a clustered index. Other implications are that since the leaf node of a clustered index is a data page, there is no need for included columns (since all columns are in the data page) or filtered indexes (since the clustered index is the whole table, by definition). A more subtle insight is this: Since B-Tree theory does not stipulate key uniqueness, a clustered index may have rows with duplicate keys. In that case, SQL Server will add a hidden uniqueifier (a 4-byte integer) to the index to enforce uniqueness.
Question 4: What happens when you create a clustered index?
As explained in the answer to question 3, above, when you create a clustered index, the order of the rows in the data pages is changed. Adding a clustered index to our working example, the command is a simple one:
|
1 2 3 4 |
CREATE CLUSTERED INDEX CIX_Customers_CustomerID ON dbo.Customers (CustomerID); |
We can view and run this in ApexSQL Plan. First, let’s see the estimated execution plan:
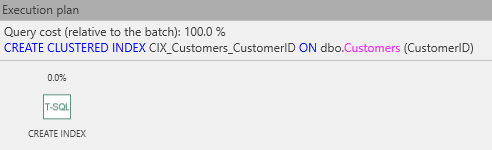

The estimated plan shows just an operation to create an index. That means that it is handled internally and/or SQL Server prefers not to expose the details. However, it is easy to deduce what must happen:
- Read all the pages of the table
- Sort the rows by the key specified
- Fill new pages with the sorted rows (up to the fill factor)
- Harden the new pages to persistent storage
- Free up the pages used by the data rows before the create index.
If we actually execute this, we should be able to see some of this action:

This is pretty much as expected! Reading from right-to-left, the table contents are read (table scan), 100,000 rows are sent for sorting, then the sorted data set is sent to an IndexInsert operation, which creates the index nodes. The parallelism operator indicates provision for a parallel IndexInsert operation, which can be run in many parallel streams depending on the number of available CPUs. Finally, the new rows are INSERTed into the table. We don’t see an operator for releasing the now-unused pages, but then that is a background operation that you will never see in an execution plan.
Now that we have a clustered index in place, will that affect our original query?
|
1 2 3 |
SELECT * FROM Customers where CustomerID = 50000; |
Now the estimated plan looks like this:
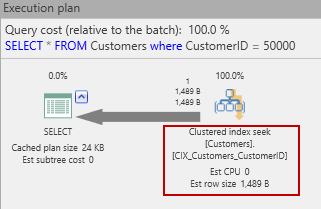
The original table scan has been replaced with a clustered index seek. Will that help reduce the I/O used to get that row? Let’s see!

That’s a huge difference! The original 2500 reads have been reduced to just three. Since we know that there is only one data page for this row (since the row has a total length < 8090 – a topic for a different article), we can infer that the other two I/Os are for pages containing the index nodes. We can confirm this with a simple query:
|
1 2 3 4 5 |
SELECT INDEXPROPERTY(OBJECT_ID('dbo.Customers'), 'CIX_Customers_CustomerID','IndexDepth') AS [Index Depth] |
Which returns:
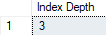
matching our expectations, and the I/O reads.
Graphically, our clustered index now has this structure:
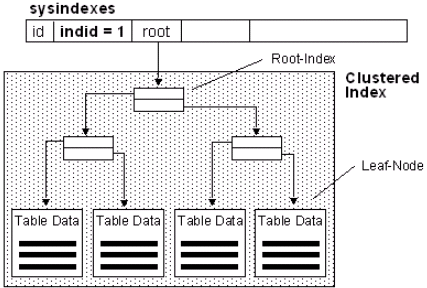
Source: ©Microsoft.com
Question 5: What about nonclustered indexes?
So far, we’ve only been looking for customers by their customer id. What if we wanted to look up a customer by name instead? Something like this, perhaps:
|
1 2 3 |
SELECT * FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
The estimated execution plan is now:
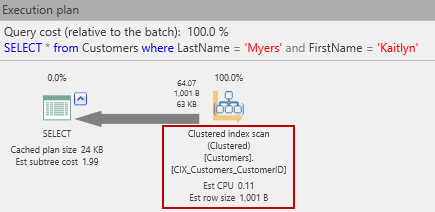
Oh no! We’re back to a scan operation. (This time, it’s a clustered index scan, since as mentioned before, a table is either a heap or a clustered index, and we just made the Customers table into the latter. But it get’s worse! The actual I/O reads have gone up!

That’s because SQL Server is now also using the index nodes as it scans the data pages. What can be done about this situation? Add a nonclustered index, of course!
Let’s use this DDL to create the index:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers (LastName, FirstName); |
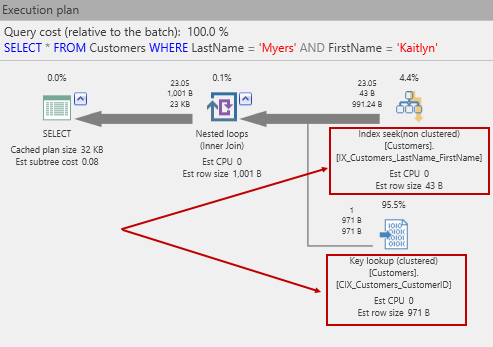
With that in place, let’s retry that SELECT. This time the plan looks like this:
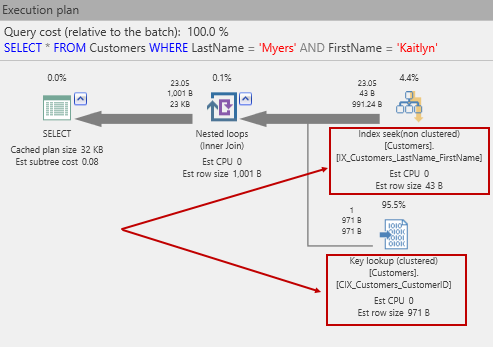
Now, we can see that the does an index seek, using the new index, followed by a key lookup. The key lookup is necessary since we’ve written:
|
1 2 3 |
SELECT * FROM Customers … |
and SQL Server has to go back to data pages to get the other columns in the row. The reason is a Key lookup because of how SQL Server builds nonclustered indexes. You would be forgiven for thinking that the nonclustered index contains a pointer to the pages containing the data row. Actually, that’s not how it works. Instead of a pointer (e.g. a sector number on disk), a nonclustered index keeps the clustered index key if there is a clustered index. Of course, before we got here, we put a clustered index on the Customers table! As a consequence, we get a key lookup. If you guessed that this means a separate lookup into the clustered index, you’d be right!
So, does the nonclustered index reduce our I/Os? Let’s do an Actual run and see:

As shown, there is a substantial reduction in I/O. Perhaps you were expecting just 3 reads as in the clustered index example we used before. However, there is no guarantee that there is just one Kaitlyn Myers in the table. Let’s check that:
|
1 2 3 4 |
SELECT COUNT(*) AS Kaitlyns FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
returns:

So, the I/O reads are actually quite realistic.
The name “nonclustered” stems from the simple fact that this type of index is not a clustered index. What it is, is a B-tree built atop a table (which may be clustered or a heap). So, if there is also a clustered index, the nonclustered index lives alongside the clustered index, and its entries point to the leaf level of that index – the data pages. A nonclustered index has a structure like this:
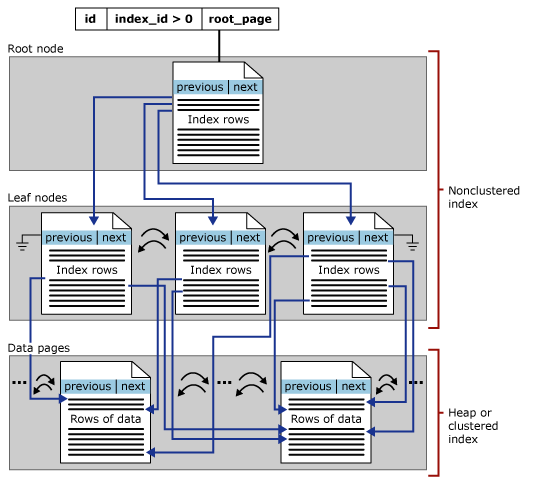
Source: ©Microsoft.com
Question 6: What about included columns? How can they help?
You saw that a query using a nonclustered index had to lookup other columns with a key lookup into the clustered index. What if you frequently queried just a subset of the other columns? What if you were often looking up the customer’s phone number? That’s where included columns come in. If I modify the nonclustered index like this:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers (LastName, FirstName) INCLUDE(HomePhone); |
then run this query:
|
1 2 3 4 |
SELECT HomePhone FROM Customers WHERE LastName = 'Myers' AND FirstName = 'Kaitlyn'; |
The execution plan changes to this:
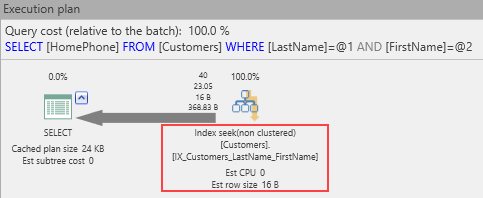
No more key lookup! The I/O reads are reduced as well:

So, we can see the positive benefit of included columns. This naturally raises the question, “Why not just add the included columns to the index in the first place?” To understand why, first consider this: While key columns are stored at all levels of the index, nonkey columns are stored only at the leaf level. Lest there be any confusion, although a nonclustered index points to the data pages, its leaves are part of the B-tree itself.
Why not put the included columns in the index keys? There are a few reasons:
- Storage cost. If the included columns are not needed for other types of searches, keeping them out of the key list makes for shorter index entries and a flatter B-tree. That results in less index I/O.
- SQL Server limits. Currently, you can have no more than 16 key columns in an index, and altogether those key columns cannot exceed the maximum index size of 900 bytes.
- Included columns can be data types that are not allowed as index columns. For example, nvarchar(max), varbinary(max), xml and others cannot be key columns but can be included columns.
When an index contains all the columns needed to satisfy a query, it is called a covering index. Including strategic columns in a nonclustered index can ensure that the most frequent queries can be satisfied entirely from the index without the need for key lookups into the clustered index.
Though we haven’t mentioned it, you can put a nonclustered index on a heap – that is a table without a clustered index. In that case, any lookups into the data pages are RID lookup. The “R” stands for Row and RID consists of a virtual address that includes the file number and page number of the data page and the row slot within the data page.
Question 7: What about primary keys (and keys in general)?
So far, we’ve avoided any discussion of primary keys. That’s not an accident. Too often clustered indexes and primary keys are conflated as if they are one and the same thing. They are not! That’s why we’ve left them until now. It’s best to get a solid idea about types of indexes before introducing keys.
To be a relation in the formal, relational algebraic sense of the word, a table (what most RDBMSs call relations) must have a key – some column or collection of columns that, taken together, uniquely identify a row in a table. However, a key is not an index. It may be (and usually is) supported by an index, but at its heart, a key is a constraint – a condition that the database must maintain to preserve referential integrity. You can see the difference by creating a primary key on the Customers table in the example we’re using:
|
1 2 3 4 |
ALTER TABLE dbo.Customers ADD CONSTRAINT PK_Customers_CustomerID PRIMARY KEY (CustomerID); |
Notice that the statement adds a constraint, not an index. It adds just such a constraint on the CustomerID column. Now, since we already have both a clustered index and a nonclustered index, this produces an interesting result. In SSMS Object Explorer, we now see three indexes!
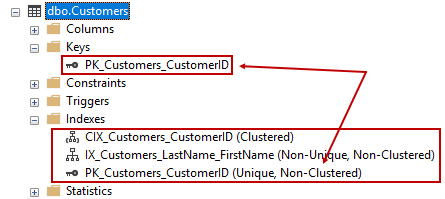
The new one has been created as a backing index to implement the constraint. Note that it is nonclustered. If you thought that primary keys have to be clustered indexes, think again. It is interesting that SQL Server did not recognize that there is already a covering clustered index and use that one. I suspect that building indexes the way we’re doing it here is good for instruction but not optimal for proper design, so the SQL Server development team has not yet worked on this edge case and may never do so.
Before we added the primary key constraint, it was possible and permissible to add new customers with the same customer IDs as existing customers. Go ahead, try it! Now that the PK is in place, though, that is no longer possible.
Although there can be only one primary key, there can be other keys, if other combinations of columns are truly unique. Creating them uses similar syntax:
|
1 2 3 4 5 |
ALTER TABLE dbo.Customers ADD CONSTRAINT AK_Customers_LastName_FirstName_HomePhone UNIQUE (LastName, FirstName, HomePhone); |
This operation creates a unique constraint and also adds a backing index:
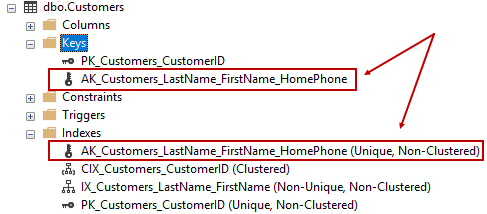
Primary keys are necessary to make a table conform to relational theory. In practice, they are highly useful (as are unique keys) for referential integrity and a good way to get the database to check your assumptions about incoming data.
Question 8: Should my primary key also be the clustered index key?
By default, SQL Server creates a clustered index when you create a new table with a primary key:
|
1 2 3 4 5 6 |
CREATE TABLE PrimaryKey (id INT IDENTITY PRIMARY KEY, name VARCHAR(50) ); |
This command creates a key backed by a clustered index (with a system-supplied name):
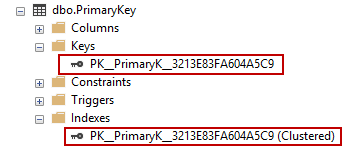
However, just because it’s the default action, that doesn’t mean its always the best choice. While a primary key needs to be backed by an index to implement the constraint, the index does not need to be clustered, as we saw above. Furthermore, the goals of primary keys and clustered indexes may not be the same.
Fundamentally, a primary key constraint enables SQL Server to maintain the important property that a table may not have duplicate rows. In fact, unique constraints do exactly the same thing. Because they are backed by indexes, keys are also helpful for searches, since
- There can be only one row for any given key
- The index allows for a seek operation to be used, which normally takes less I/O.
On the other hand, clustered indexes can provide a performance advantage when reading the table in index order. This allows SQL Server to better use read ahead reads, which are asymptotically faster than page-by-page reads. Also, a clustered index does not require uniqueness. If two or more rows have the same clustered index key, a uniqueifier is added to ensure that all rows in the index are unique.
Going back to our Customer table, this is a perfectly valid index/key setup:
|
1 2 3 4 5 6 7 8 |
CREATE CLUSTERED INDEX IX_Customers_LastName_FirstName ON dbo.Customers(LastName, FirstName); ALTER TABLE dbo.Customers ADD CONSTRAINT PK_Customers_CustomerID PRIMARY KEY NONCLUSTERED(CustomerID); |
Here, we’re assuming that most reads are done by last name, first name (the clustered index) and that most searches are done by CustomerID (the primary key). (SQL Server will add a uniquifier to the clustered index since it doesn’t know if there will be key collisions or not.) The point here is to carefully consider which arrangement is best for a new table. Consult with business users about how the table will be used. Remember that most reporting is sequential in nature. Choose your indexing accordingly, then test it. Use real workloads and see if actual usage is still a good match for the indexing scheme. If not, adjust it to suit.
Question 9: What are those “missing indexes” in an execution plan
Sometimes, a message will be included with the execution plan that an index is missing. For example, if I remove the indexes from the Customer table and try a search by CustomerID, the resulting plan looks like this:
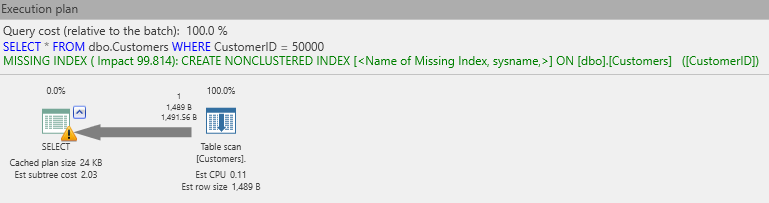
The text in green, above, is just such a message. Basically, SQL Server is saying that if there were an index on the CustomerID column, the cost of the overall query could be reduced by 99.8%! That would reduce the cost to almost nothing. Instead of a table scan, it could use an index seek operation.
The question then becomes, should you always implement a missing index? As is often the case, “it depends!” is the only true answer. Is this a once-a-year query that runs in 10 minutes without the index? Perhaps you can leave that missing index alone. Is it a query that gets executed thousands of times a second from a busy e-commerce server? Probably you should implement the recommendation! Don’t assume that mommy knows best! You need to think it through and understand the usage patterns and the cost of an index before you do anything. Come to think about it…
Question 10: Can I have too many indexes?
There is actually advice out in the wild stating that you should just index every column in your table so that no execution plan will ever have a missing index. Is this good advice? Once again, it depends.
Data warehouse databases often have a calendar table. That table will have a row for every date and columns for every conceivable use: MonthNumber, QuarterNumber, HalfYearNumber, MonthText, FullDateText, Is_Holiday, Is_BusinessDay, and many, many more. Such a table is static. Often the primary key (and clustered index) is an integer or date column with the date matching the other columns in the row. This table never (or rarely) changes. Also, it is not too big. (How many rows would you need for a century?) On such a table, indexing every column can make sense. You can have filtered indexes for the various flags, ascending and descending indexes, most of which will be nonclustered.
Now consider our Customer table. If we index every column, what happens when we insert a new customer?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
INSERT INTO [dbo].[Customers] ([FirstName] ,[LastName] ,[Street] ,[StreetNumber] ,[Unit] ,[City] ,[StateProvince] ,[ISO3_Country] ,[EmailAddress] ,[HomePhone] ,[MobilePhone]) VALUES ('Ford', 'Prefect', 'The Resraurant', '42', 'N/a', 'End of the Universe', 'Improbable', 'FPP', 'Ford@HeartOfGold.com', 2125551212, 3141592653 ) GO |
The actual execution plan for this is:
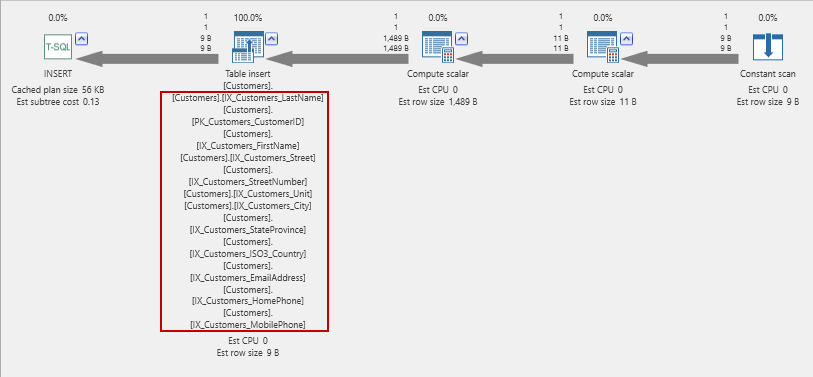
All those indexes must be maintained! This work can add up quickly, so unless you have a static table (such as a calendar table), indexing every column is usually a bad idea!
Summary
Properly indexing a SQL Server table is key to providing consistent, optimal performance. There are many things to consider when designing an index structure. Almost none of those considerations can be done without consulting the business users who understand the data and how it will be used, though it may well turn out that, after the new table has been in use for some time, that other indexing options will present themselves.
This article has attempted to answer some of the most important questions about indexing in general and specifically how it is done in SQL Server. We’re really only scratched the surface though. Each question answered here could be its own complete article and possibly a series of articles! Also, we’ve not addressed other types of indexes at all (e.g. XML indexes) nor have we looked at in-memory objects and how those change the picture for newer editions of SQL Server.
Please stay tuned for more in-depth articles on SQL Server indexing.

Gerald specializes in solving SQL Server query performance problems especially as they relate to Business Intelligence solutions. He is also a co-author of the eBook "Getting Started With Python" and an avid Python developer, Teacher, and Pluralsight author.
You can find him on LinkedIn, on Twitter at twitter.com/GeraldBritton or @GeraldBritton, and on Pluralsight
View all posts by Gerald Britton
- Snapshot Isolation in SQL Server - August 5, 2019
- Shrinking your database using DBCC SHRINKFILE - August 16, 2018
- Partial stored procedures in SQL Server - June 8, 2018