
Data compression is required to reduce database storage size as well as improving performance for the existing data. SQL Server 2008 introduced Data compression as an enterprise version feature. Further to this, SQL Server 2016 SP1 and above supports data compression using the standard edition as well.
As per Microsoft docs, SQL Server 2017 and Azure SQL Database support row and page compression for rowstore tables and indexes, and supports columnstore and columnstore archival compression for columnstore tables and indexes.
We used to analyze the objects using the stored procedure sp_estimate_data_compression_savings. This procedure gives the estimated object size of the object after the specified compression. Until SQL Server 2017, we can estimate indexes, indexed views, heaps using this procedure.
In my previous article, Columnstore Index Enhancements in SQL Server 2019 – Part 1, we learned Columnstore index stats update in clone databases. SQL Server 2019 also provides enhancement to sp_estimate_data_compression_savings. In this article, we will explore the benefit out of it.
Syntax for sp_estimate_data_compression_savings is as below:
|
1 2 3 4 5 6 7 |
sp_estimate_data_compression_savings [ @schema_name = ] 'schema_name' , [ @object_name = ] 'object_name' , [@index_id = ] index_id , [@partition_number = ] partition_number , [@data_compression = ] 'data_compression' [;] |
- @schema_name: Schema of the object(table,index)
- @object_name: Name of the table or indexed views
- @index_id: we need to specify the ID of the index. If there is no index on the table, we can specify 0 or NULL
- @partition_number: it is the partition number of the object. If there is no index, we need to specify NULL in this value as well
- @data_compression: we can specify NONE, ROW, PAGE, COLUMNSTORE, or COLUMNSTORE_ARCHIVE in SQL Server 2019
When we create the columnstore index, we specify the data compression method to apply. There are two kinds of data compression applied to the columnstore index.
- COLUMNSTORE: It is the default compression option is the default and specifies to compress data with the columnstore compression
- COLUMNSTORE_ARCHIVE: we can compress data further by using this option. This is useful to compress data that is used very less frequent. This type of compression takes extra system resources in terms of CPU and Memory
Until SQL Server 2017, sp_estimate_data_compression_savings works for row or page store data compression. This actually takes a sampling of the source object pages and creates them in the tempdb using the specified compression. Now we have two objects- source and the sampling object in tempdb. Both the objects are compared to calculate the estimated size of the object after compression.
In SQL Server 2019, this procedure works differently for the columnstore a columnstore_archive data compression options. It actually creates a new columnstore index with the specified data compression state columnstore or columnstore_archive. Therefore, in SQL Server 2019, we compare with an equivalent columnstore object. The type of the source object defines the destination columnstore index. The below table shows the mapping between source and reference object if data compression state is columnstore or columnstore_archive.
| Source | Reference |
| Heap or Clustered index or clustered columnstore index | Clustered columnstore index |
| Non-clustered index or non clustered columnstore index | Non-clustered columnstore index |
Likewise, if the source object is a columnstore index, we can use below reference table
| Source | Reference |
| clustered columnstore index | Heap |
| non clustered columnstore index | Non-clustered index |
Before we move further, let me give an overview of the important columns in the output of the stored procedure
- object_name: Object (table, index name)
- size_with_current_compression_setting: This column represents current size of the table, index
- size_with_requested_compression_setting: This column shows the estimated size of the table, index, with the data compression specified
- sample_size_with_current_compression_setting: this column shows the size of the current sample compression
- sample_size_with_requested_compression_setting (KB): this represents the size of the sample created using the specified compression option
Now let us perform the demonstration. For this purpose, we will be using the StockItemTransactions table in the WideWorldImporters database in SQL Server 2019.
Firstly, verify the Compatibility level of the database with the below steps:
Right click on database name -> Properties -> Options
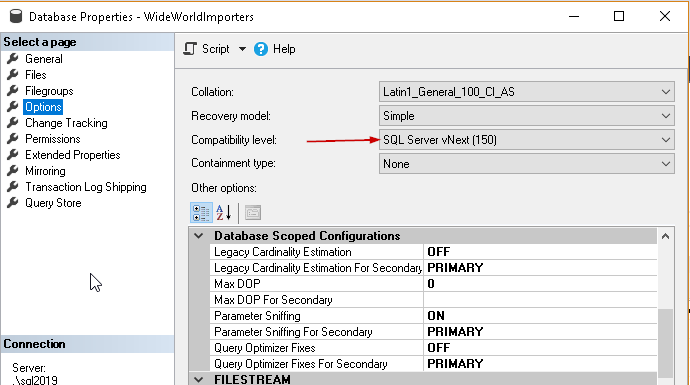
We can see here that compatibility level is set to SQL Server 2019 (150). if the compatibility level is other than 150 change it using the drop-down value or from below query.
|
1 2 3 4 |
USE [master] GO ALTER DATABASE [WideWorldImporters] SET COMPATIBILITY_LEVEL = 150 GO |
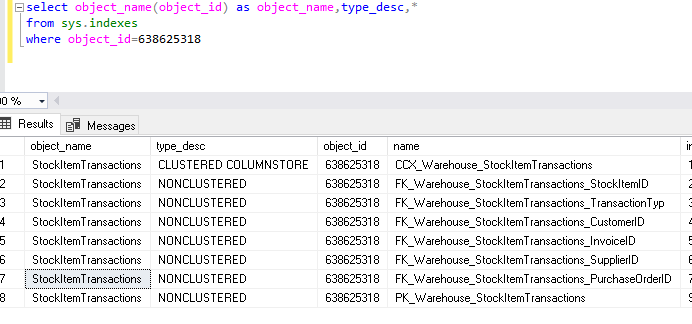
Below indexes exist on the StockItemTransactions table of WideworldImporters database. We can see the list of indexes using below query.
|
1 2 3 4 |
select object_name(object_id) as object_name,type_desc,* from sys.indexes Where object_id=638625318 --object id of StockItemTransactions table |
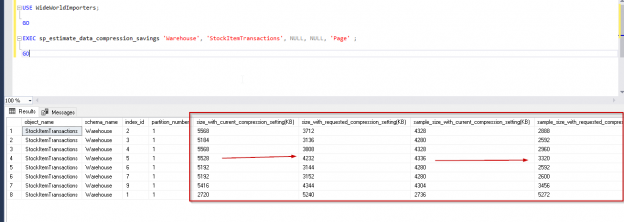
Let us examine all options using the sp_estimate_data_compression_saving procedure.
- Using ‘None‘ parameter in data_compression: this shows data if we no data compression is enabled
|
1 2 3 4 5 6 7 8 |
USE WideWorldImporters; GO EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'NONE' ; GO |
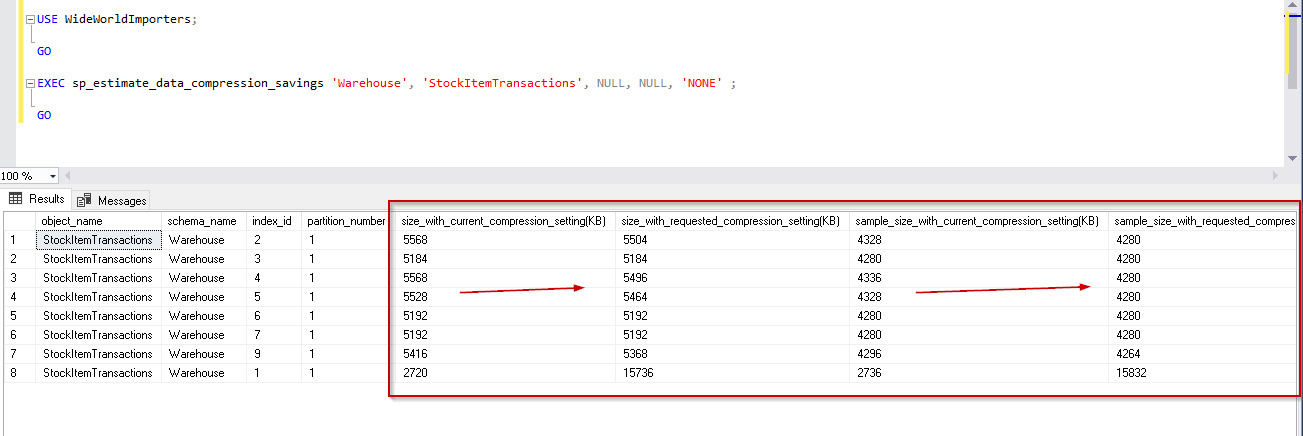
- Using ‘Row‘ parameter in data_compression: this shows data if we no data compression is enabled
|
1 2 3 4 5 6 7 |
USE WideWorldImporters; GO EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'Row' ; GO |
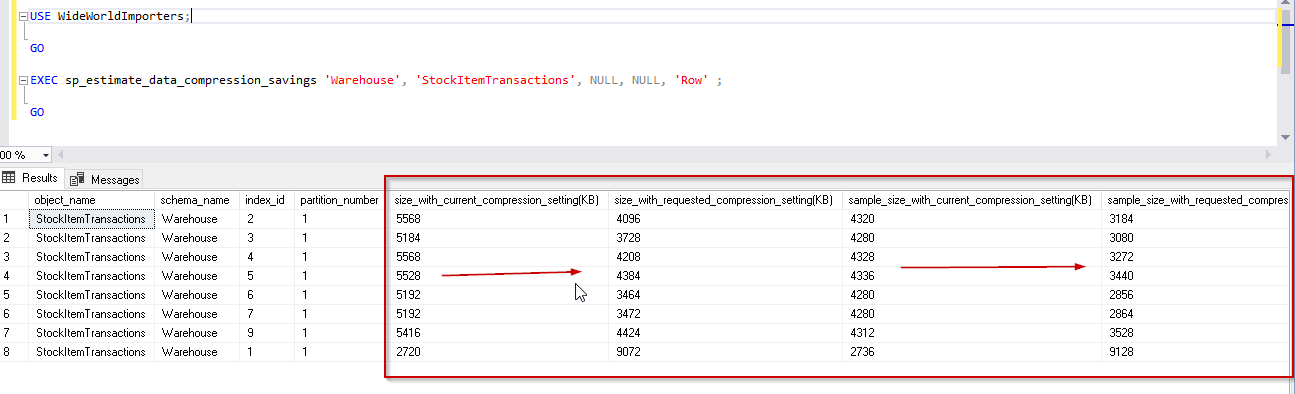
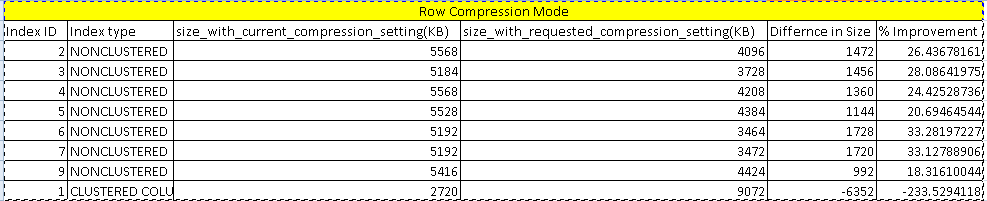
We can see in the image that with Row compression mode, data compression is around 26%. Here it shows a negative value for the clustered columnstore index because we cannot compress it with the row compression. For other indexes, you can notice the difference is index size with current compression setting and requested compression setting in KB.
- Using ‘Page‘ parameter in data_compression: This shows data if we compress data with page data compression
|
1 2 3 4 5 6 7 |
USE WideWorldImporters; GO EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'Page' ; GO |
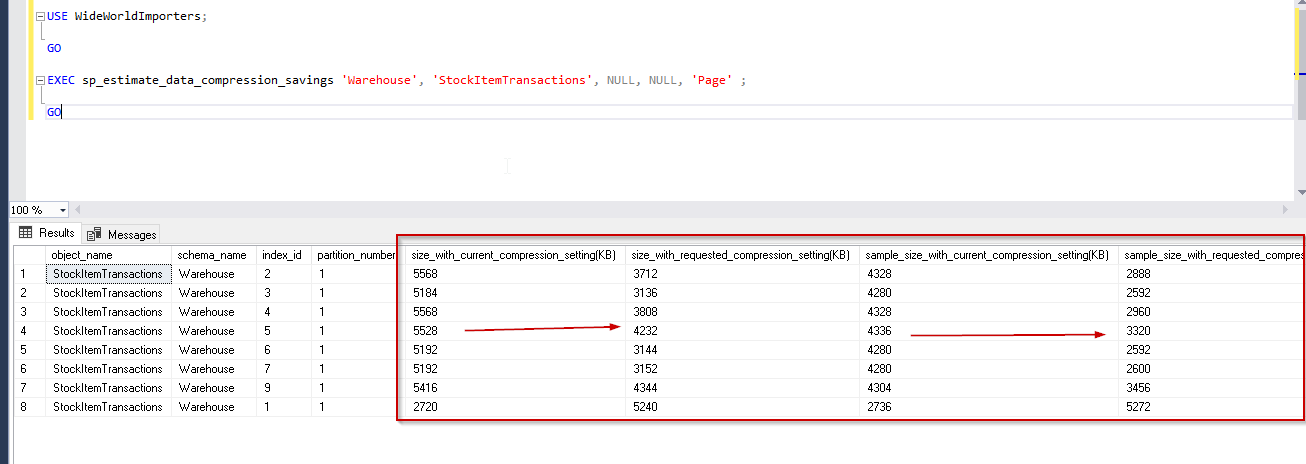
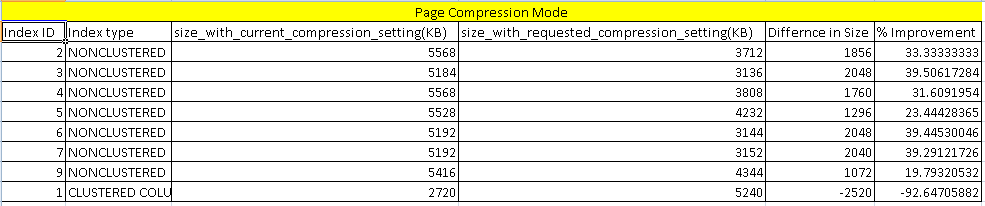
Previously we checked the benefit from the row compression mode. In the above comparison report, you can find an improvement or saving around 30% on average for the indexes. For the columnstore index as well, it shows -92%, which is better than the row compression.
- Using ‘ColumnStore‘ parameter in data_compression: This is newly added in SQL Server 2019 preview version
|
1 2 3 4 5 6 7 |
USE WideWorldImporters; GO EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'COLUMNSTORE' ; GO |
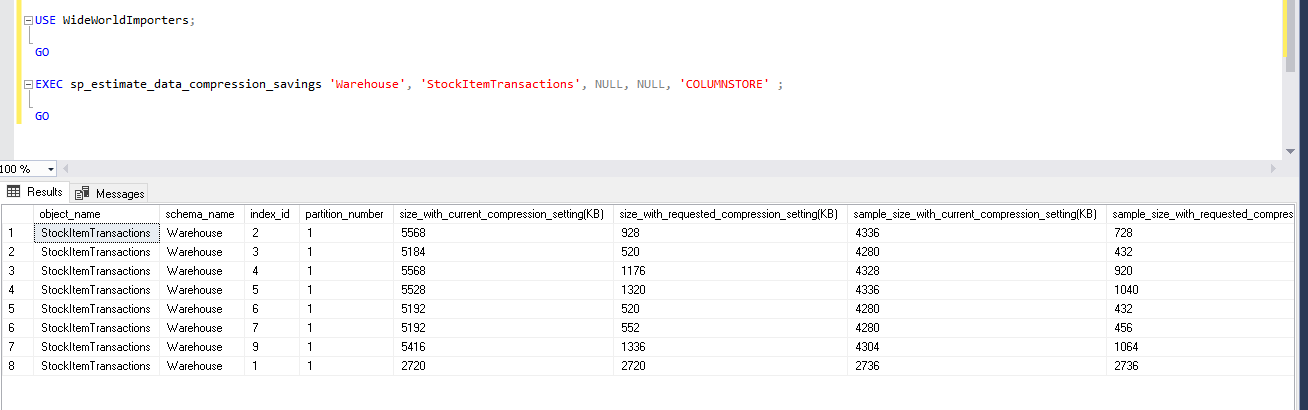
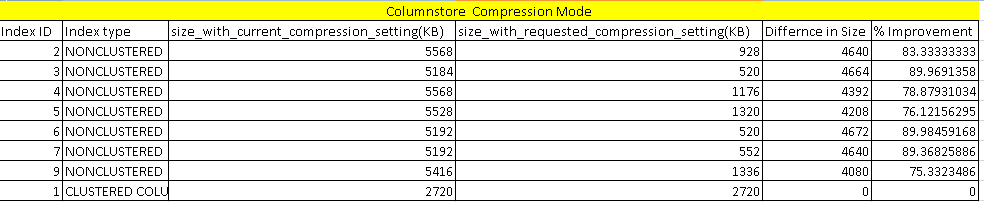
Now, let us view the data compression saving for the columnstore index. This is newly added in SQL Server 2019. We can see huge data compression around 70-80% for the indexes. It is helpful for the large databases of TB’s and PB’s. This is huge storage and cost-saving, especially for data warehouse databases. For a clustered columnstore index, it does not show any improvement because clustered columnstore index default compression mode is columnstore. Therefore, the index is already compressed using this mode.
- Using ‘ColumnStore_Archive’ parameter in data_compression: This is also a new enhancement in SQL Server 2019
|
1 2 3 4 5 6 7 |
USE WideWorldImporters; GO EXEC sp_estimate_data_compression_savings 'Warehouse', 'StockItemTransactions', NULL, NULL, 'COLUMNSTORE_ARCHIVE' ; GO |
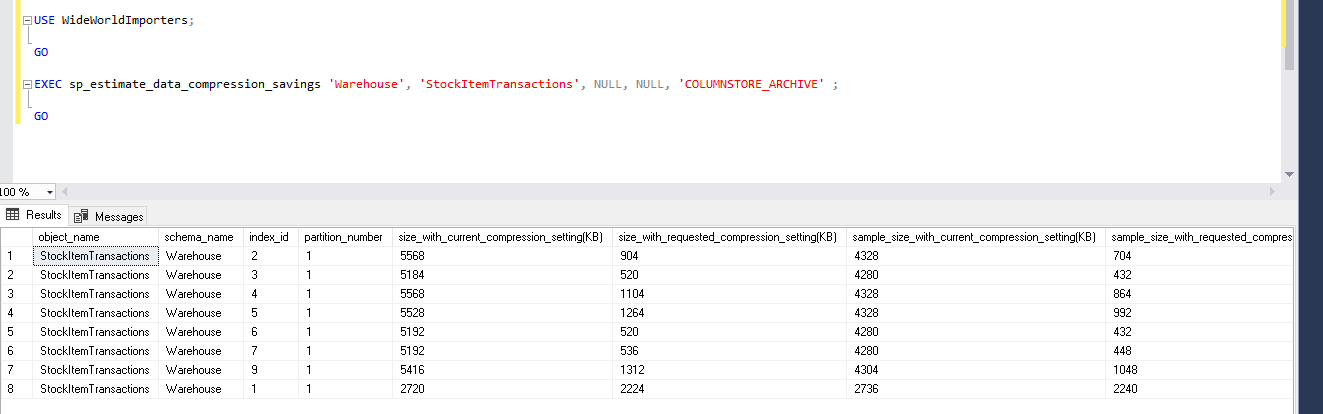
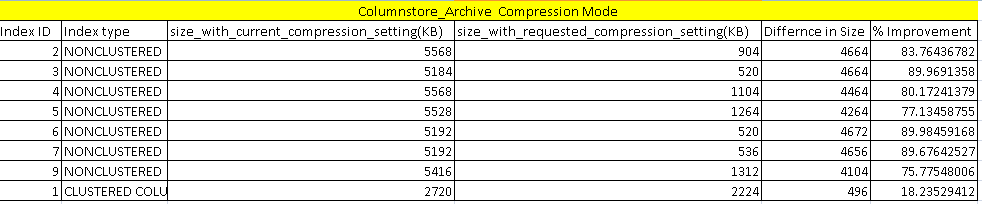
In ColumnStore_Archive compression mode, we can do more data compression that the columnstore compression mode. We can see here that improvement is around 80%. It further compresses the columnstore index by 18%. Columnstore index with archive compression can perform slowly as compared with the columnstore index. This also requires high CPU and Memory to access the data. You should compress data with this method only for old data with very less frequency of usage.
Conclusion
In SQL Server 2019, improvements to the procedure sp_estimate_data_compression_saving are helpful to estimate the data saving for columnstore indexes. You can explore this into your environment to get an overview. We will cover more on the columnstore index in SQL Server 2019 in future articles.
Table of contents
| Columnstore Index Enhancements – Index stats update in clone databases |
| Columnstore Index Enhancements – data compression, estimates and savings |
| Columnstore Index Enhancements – online and offline (re)builds |

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023