
Introduction
In a previous article entitled Hands on Full-Text Search in SQL Server, we had an overview on the Full-Text feature as it’s implemented in SQL Server. We saw how to create Full-Text indexes and that they were stored inside a container called a Full-Text catalog. We’ve also seen that, by design, this kind of index will generate a fragmentation.
As a DBA, we should consider the maintenance of these indexes as well as classical indexes. The purpose of this article is to design a stored procedure that will be highly parameterizable and will take care of such maintenance.
Problem formalization
Problem summary
We have a set of Full-Text enabled databases in which one or more Full-Text indexes are defined. As we know that Full-Text indexes will fragment, so we need to design a solution to maintain these indexes.
We desire that this solution takes all these indexes into account, no matter the database. We want to parameter the solution as much as possible so that we can easily change its behavior without changing the code.
Available options
As it’s well explained by Geoff Patterson in his stack exchange ticket entitled “Guidelines for full-text index maintenance”, there are two possible ways to maintain Full-Text indexes:
-
Using DROP/CREATE pattern (we’ll call it index rebuild): we first drop the index than create it again.
This will remove fragmentation but there are a few cons to this solution:- The application will fail to query these indexes during the operation.
- It will take resources to read the entire table in order to create the index
- If there are unexpected cases faced by the solution, the CREATE statement might fail and we’d eventually be called on our cell phone at 2 AM…
-
Using the REBUILD or REORGANIZE options of the ALTER FULLTEXT CATALOG statement. The advantage of this statement should let users query full-text indexes while running, but there is a price: depending on the amount of data that has to be treated, it can take some time to complete and hence introduce some undesired events including:
- Blocking or deadlocks.
- Transaction Log full error
According to Microsoft’s documentation about the ALTER FULLTEXT CATALOG statement, the REORGANIZE option should be used as regular maintenance task as it will merge all the fragments created over time for an each Full-Text index to a single “container” (but it’s also a fragment). This operation is called a master merge. It’s represented in the figure below:
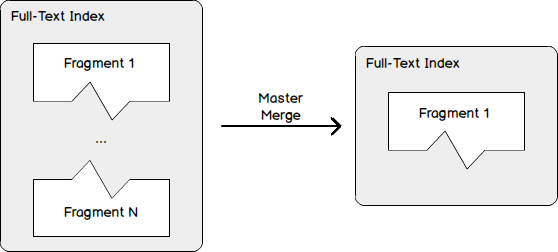
At the same time, this option will optimize internal index and catalog structures.
Preferences between reorganization and rebuild for classical index also applies to Full-Text catalog. It’s highly preferable to perform reorganizations vs rebuilds because a Full-Text index rebuild will actually read base tables for all the indexes it contains and build a replacement catalog structure. This operation should be taken as last resort, when we made a change catalog option, to the configuration of the Full-Text Search feature like adding stop words, or whenever there is a doubt about the consistency of these indexes.
No matter the chosen option, the solution designed in this article to maintain our Full-Text indexes might be run:
- regularly, like every night or every week, depending on user activity
- at a low usage period, so that the impact on user experience is minimal.
High-level solution design
We will implement a stored procedure that will be able to perform either an index rebuild or catalog reorganization. We will call this stored procedure Maintenance.FullTextIndexOptimize. It will have a parameter called @MaintenanceMode that can be set to either ‘INDEX’ or ‘CATALOG’ in order to choose the way we want to maintain our Full-Text indexes. The default value for this parameter will be ‘CATALOG’.
Plus, we could be able to run our procedure exclusively against a particular database, and for this reason why we will define a parameter called @DatabaseName defaulting to NULL, which means that all user databases have to be considered.
There is one more thing to discuss before diving into the implementation of this stored procedure: what will be the conditions that will make our stored procedure rebuild an index or reorganize a catalog?
Unfortunately, recommendations from Microsoft about the subject are not easy to find, so we will take the guidelines from Geoff Patterson as basis for our work. These guidelines are about the first option, index rebuild. He says he made experiments running the exact same query using CONTAINSTABLE against a table that was populated over time and not defragmented. He empirically defined that if a Full-Text index suffers of 10% of fragmentation or more, it should be rebuilt for this query to keep an execution time below 500ms.
For that reason, we will define a parameter to our stored procedure that we will call @FragmentationPctThresh4IndexRebuild that will be set to 10 by default.
When we consider the size as a ratio, there is always the possible case when these 10% represents a lot of data. For that reason, we will also define a fixed length threshold that we will call @FragmentationMinSizeMb4IndexRebuild. It will empirically be set to 50.
Moreover, we could have a 90% fragmented index of 1 kb. Is it OK to let it remain like that or should we absolutely rebuild it? To me, it’s not that important and that’s the reason why the Maintenance.FullTextIndexOptimize stored procedure will also have a parameter called @MinIndexSizeMb. This parameter will tell the stored procedure not to rebuild indexes with size below its value, which will be 1 by default.
While Geoff Patterson’s guidelines could be enough, there is another recommendation in this StackExchange question from another senior DBA, Kin, who says that he reorganizes his catalog whenever there are indexes with 30 to 50 fragments. That’s also a good point as we could imagine an index with low fragmentation ratio but high number of fragments. For that reason, we will add our last threshold parameter to the Maintenance.FullTextIndexOptimize stored procedure: @FragmentsCountThresh4IndexRebuild that will be set to 30 by default.
To sum up, here are the cases when a Full-Text index should be considered for rebuild:
- When its size is above 1Mb and is 10% or more fragmented
- When its size is above 1Mb and has a fragmented space of 50Mb or more.
- When its size is above 1Mb and the index has 30 or more index fragments
This ends up the definition for thresholds to use for Full-Text index rebuild option. We can now consider Full-Text catalog reorganization. We will keep it simple and say that whenever an index could be marked for the rebuild, this reorganization should occur.
Now, these specific parameters are well defined, we can add more general parameters, which are:
- @UseParameterTable, a BIT parameter that tells the stored procedure, when set to 1, to read in a hard-coded parameter table. This option is let for future improvement and won’t be implemented at the moment.
- @WithLog, also a BIT parameter that tells the stored procedure, when set to 1, to log execution in a logging table.
- @ReportOnly, still a BIT parameter to tells the stored procedure, when set to 1, to only return a report with the list of indexes or catalogs and the action that has to be done. It will be used extensively during development and can be used for monitoring.
- @Debug, which tells the stored procedure to display debug messages. A value of 0 means no debug message should be shown, a value of 1 will display debug messages and a value of 2 will display all the debug messages when @Debug is set to 1 plus the text of dynamic queries created and used during execution.
Now we have discussed about all the parameters that are used to define the Maintenance.FullTextIndexOptimize stored procedure, we can finally have a look at its interface:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
ALTER PROCEDURE [Maintenance].[FullTextIndexOptimize] ( @MaintenanceMode VARCHAR(16) = 'CATALOG', @DatabaseName VARCHAR(256) = NULL, @FragmentationPctThresh4IndexRebuild INT = 10, @FragmentationMinSizeMb4IndexRebuild INT = 50, @FragmentsCountThresh4IndexRebuild INT = 30, @MinIndexSizeMb FLOAT = 1.0, @UseParameterTable BIT = 0, @WithLog BIT = 1, @ReportOnly BIT = 0, @Debug SMALLINT = 0 ) |
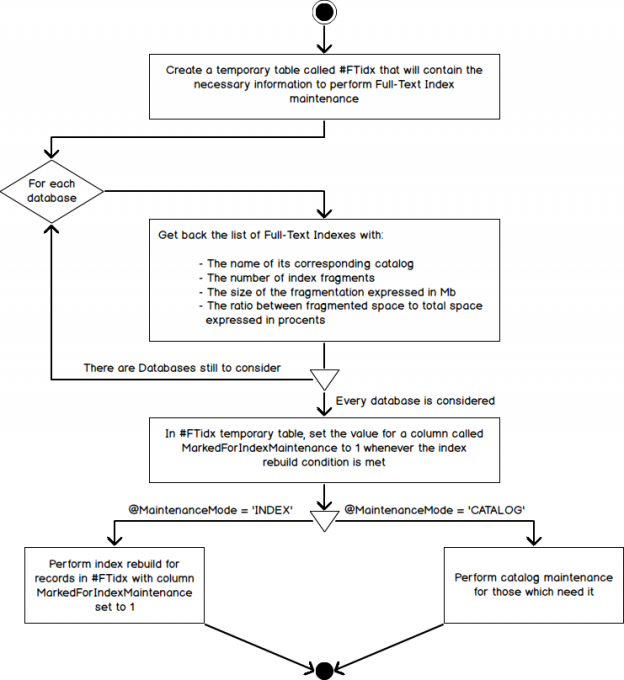
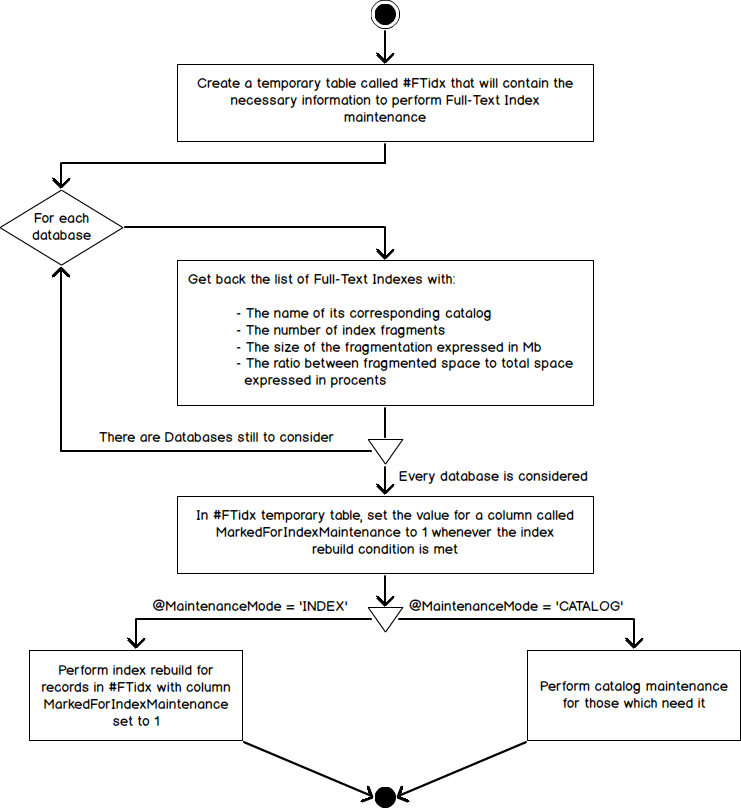
Here is the high-level algorithm that we will use to implement the body of our stored procedure:
Solution implementation
In this section, we will review some key elements in the implementation such as its dependencies, the structure of temporary tables we will use and some queries we will use.
An ZIP archive containing all resources to perform Full-Text Index maintenance can be found at the end of this article.
Dependencies
In order to implement the [Maintenance].[FullTextIndexOptimize] stored procedure, we will take advantage of following database objects:
- [Common].[RunQueryAcrossDatabases] – a stored procedure that takes a T-SQL statement and execute it against a set of databases. It has a parameter @DbName_equals that we can use when use set a value to the @DatabaseName parameter of our FullTextIndexOptimize. It will be used in order to execute the T-SQL query that gets back Full-Text indexes details.
- [Common].[CommandExecute] and its related table [Common].[CommandLog] – an adapted version of Ola Hallengren’s stored procedure and table with the same name. It will be used to execute and optionally log the action taken against either an index or a catalog.
Temporary tables
For holding data related to Full-Text index
The temporary table used to store data related to Full-Test indexes is called #FTidx and has been slightly discussed previously. Each record of this table will correspond to a Full-Text index and contain:
- The name of its corresponding catalog
- The number of index fragments
- The size of the fragmentation expressed in Mb
- The ratio between fragmented space to total space expressed in percentage.
- Whether a maintenance should be performed or not on that index
- Whether the maintenance for that index succeeded or not
- If the maintenance did not succeed, the error message that the FullTextIndexOptimize stored procedure got back during execution.
This means that the table has following creation statement:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
CREATE TABLE #FTidx ( EntryId INT IDENTITY(1,1) NOT NULL PRIMARY KEY, DatabaseName VARCHAR(256) NOT NULL, CatalogId INT NOT NULL, CatalogName VARCHAR(256) NOT NULL, BaseObjectId INT, BaseObjectName VARCHAR(1024), BaseIndexId INT, TotalSizeMb FLOAT NOT NULL, FragmentsCount INT, LargestFragmentSizeMb FLOAT, FragmentationSpaceMb FLOAT, FragmentationPct FLOAT, MarkedForIndexMaintenance BIT DEFAULT 0, StatementForDrop AS 'USE ' + QUOTENAME(DatabaseName) + ';' + CHAR(13) + CHAR(10) + 'DROP FULLTEXT INDEX ON ' + BaseObjectName + ';', MaintenanceOutcome VARCHAR(32), MaintenanceLog VARCHAR(MAX) ); |
For holding data related to Full-Text catalogs
While first this temporary table will be created no matter the value of the @MaintenanceMode parameter, the following table will only exist whenever the value for this parameter is CATALOG.
It will store information about catalogs we can find in #FTidx temporary table. For each one, we will have the following columns:
- MarkedForCatalogMaintenance, which set to 1 means we need to reorganize catalog
- MaintenanceOutcome to tell whether the maintenance was successful or not
- MaintenanceLog to keep track of error messages when the catalog maintenance did not succeed.
Its creation statement is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
CREATE #FTcatalog ( RecordId INT IDENTITY(1,1) NOT NULL PRIMARY KEY, DatabaseName VARCHAR(256) NOT NULL, CatalogName VARCHAR(256) NOT NULL, CatalogId INT, BaseObjectsCount INT, IndexesNeedingMaintenance INT, TotalSizeMb FLOAT, TotalFragmentsCount INT, TotalFragmentationSpaceMb FLOAT, MarkedForCatalogMaintenance BIT DEFAULT 0, MaintenanceOutcome VARCHAR(32), MaintenanceLog VARCHAR(MAX) ); |
Query to get back Full-Text index details
We will use an adapted version of the query discussed in the article “Hands on Full-Text Search in SQL Server”. As you may notice, this query will insert results into #FTidx temporary table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
WITH FragmentationDetails AS ( SELECT table_id, COUNT(*) AS FragmentsCount, CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS IndexSizeMb, CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mb FROM sys.fulltext_index_fragments GROUP BY table_id ) INSERT INTO #FTidx ( DatabaseName, CatalogId, CatalogName, BaseObjectId, BaseObjectName, BaseIndexId, TotalSizeMb, FragmentsCount, LargestFragmentSizeMb, FragmentationSpaceMb, FragmentationPct ) SELECT DB_NAME() AS DatabaseName, ftc.fulltext_catalog_id AS CatalogId, ftc.[name] AS CatalogName, fti.object_id AS BaseObjectId, QUOTENAME(OBJECT_SCHEMA_NAME(fti.object_id)) + '.' + QUOTENAME(OBJECT_NAME(fti.object_id)) AS BaseObjectName, unique_index_id, f.IndexSizeMb AS IndexSizeMb, f.FragmentsCount AS FragmentsCount, f.largest_fragment_mb AS IndexLargestFragmentMb, f.IndexSizeMb - f.largest_fragment_mb AS IndexFragmentationSpaceMb, CASE WHEN f.IndexSizeMb = 0 THEN 0 ELSE 100.0 * (f.IndexSizeMb - f.largest_fragment_mb) / f.IndexSizeMb END AS IndexFragmentationPct FROM sys.fulltext_catalogs ftc JOIN sys.fulltext_indexes fti ON fti.fulltext_catalog_id = ftc.fulltext_catalog_id JOIN FragmentationDetails f ON f.table_id = fti.object_id ; |
This body of this query will be put in a variable called @tsql in the stored procedure then executed with [Common].[RunQueryAcrossDatabases] stored procedure discussed above.
Generating CREATE FULLTEXT INDEX statements
Now we have a query that allows us to get back information about existing Full-Text indexes into a temporary table called #FTidx, we could start a WHILE loop on the records of that table and try to generate the creation statement for each of them.
If we take a look at the grammatical definition of the CREATE FULLTEXT INDEX statement, we can see what data we need to extract from database:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE FULLTEXT INDEX ON table_name [ ( { column_name [ TYPE COLUMN type_column_name ] [ LANGUAGE language_term ] [ STATISTICAL_SEMANTICS ] } [ ,...n] ) ] KEY INDEX index_name [ ON <catalog_filegroup_option> ] [ WITH [ ( ] <with_option> [ ,...n] [ ) ] ] [;] |
Amongst them, include:
- The name of the table on which the index is built
- The list of columns with some information. For instance, the language used in particular column.
- The name of the primary key index of the table
- The name of the Full-Text catalog
Note
In the version we will review now, some of the options of the CREATE FULLTEXT INDEX will remain to its default value like FILEGROUP settings. Feel free to modify the proposed solution if you need it.
So, now we know what we need to look for, let’s build a query that generates the statement to recreate a Full-Text index. The first part of the statement is pretty straight forwards as we already have everything stored in #FTidx temporary table:
|
1 2 3 4 5 6 7 |
SET @Statement4Create = 'USE ' + QUOTENAME(@CurDbName) + ';' + @LineFeed + 'CREATE FULLTEXT INDEX ON ' + @CurObjectName + '(' + @LineFeed ; |
Where @CurDbName and @CurObjectName variables are set with the values from a record of #FTidx.
Now, we have to get back the list of columns which are used in a given index. To do so, we will query a set of system views and tables:
- sys.fulltext_index_columns
- sys.columns (twice: once for the column on which the Full-Text index is based and once for the column that tells SQL Server what kind of document is stored in the first column)
We will use a dynamic version of following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
--USE <YourDb>; DECLARE @tsql NVARCHAR(MAX); DECLARE @LineFeed CHAR(2) = CHAR(13) + CHAR(10); SELECT @tsql = CASE WHEN LEN(@tsql) = 0 OR @tsql IS NULL THEN '' ELSE @tsql + ',' + @LineFeed END + ' ' + c.Name + ' TYPE COLUMN ' + refc.name + ' ' + ' Language ' + CONVERT(VARCHAR(10),language_id)+' ' + CASE WHEN fic.statistical_semantics = 1 THEN 'STATISTICAL_SEMANTICS ' ELSE '' END FROM sys.fulltext_index_columns fic INNER JOIN sys.columns as c ON c.object_id = fic.object_id AND c.column_id = fic.column_id INNER JOIN sys.columns as refc ON refc.object_id = fic.object_id AND refc.column_id = fic.type_column_id WHERE fic.object_id = @CurObjectId -- SELECT @tsql |
Here is a sample results for a given @CurObjectId:

Once it’s done for all columns, we can close the parenthesis and get back information about which key index has to be used and some options about the Full-Text index. We do so use a modified version of following script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
--USE <YourDb>; DECLARE @tsql NVARCHAR(MAX); DECLARE @LineFeed CHAR(2) = CHAR(13) + CHAR(10); SELECT @tsql = 'KEY INDEX ' + idx.Name + @LineFeed + 'ON ' + QUOTENAME(@CatalogName) + @LineFeed + 'WITH CHANGE_TRACKING ' + fi.change_tracking_state_desc + @LineFeed + ';' + @LineFeed FROM sys.indexes idx JOIN sys.fulltext_indexes fi ON idx.object_id = fi.object_id WHERE idx.object_id = @ObjectId AND index_id = @IndexId ; SELECT @tsql ; |
And here is a sample of generated text:

Putting everything together, we’ll get a statement like following one:
|
1 2 3 4 5 6 7 8 9 |
USE [Test_FT_Maintenance]; CREATE FULLTEXT INDEX ON [dbo].[DM_OBJECT]( OBJ_CONTENT TYPE COLUMN OBJ_IDX_DOCTYPE Language 0 ) KEY INDEX PK_DM_OBJECT ON [DM_FT] WITH CHANGE_TRACKING AUTO ; |
Scheduling the maintenance with SQL Server Agent
Now we have a stored procedure that can be run for maintaining our Full-Text indexes for all our databases, it’s time to schedule it. And what’s best suited for that than the famous SQL Server Agent… Here are the steps you can follow to generate a SQL Server Agent Job called “[Maintenance] FullTextIndexOptimize”:
- Connect to a SQL Server instance
-
Go down to SQL Server Agent node, right-click and follow the path depicted in next screen capture:

-
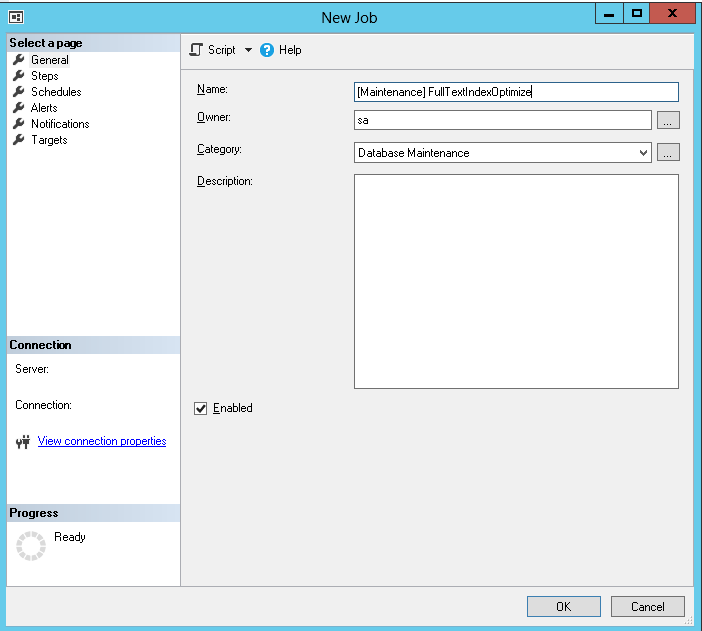
Fill in general information then go to Steps
-
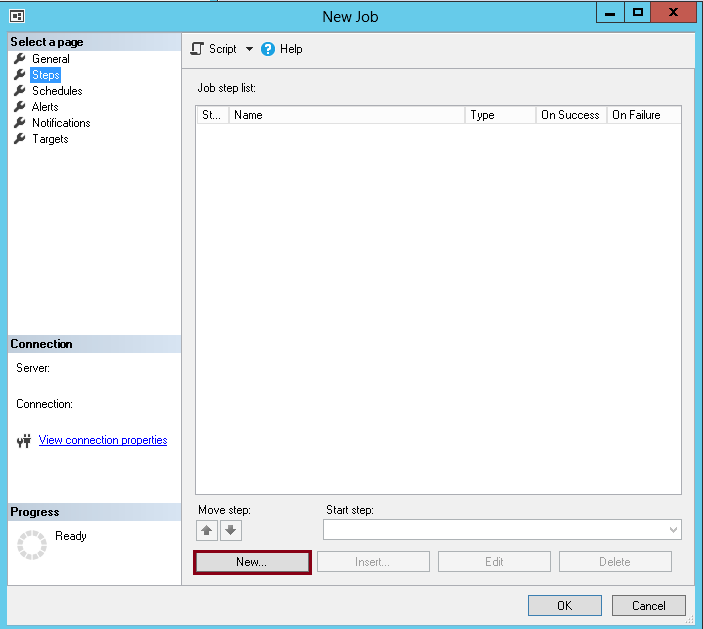
In Steps page, click on “New” button
-
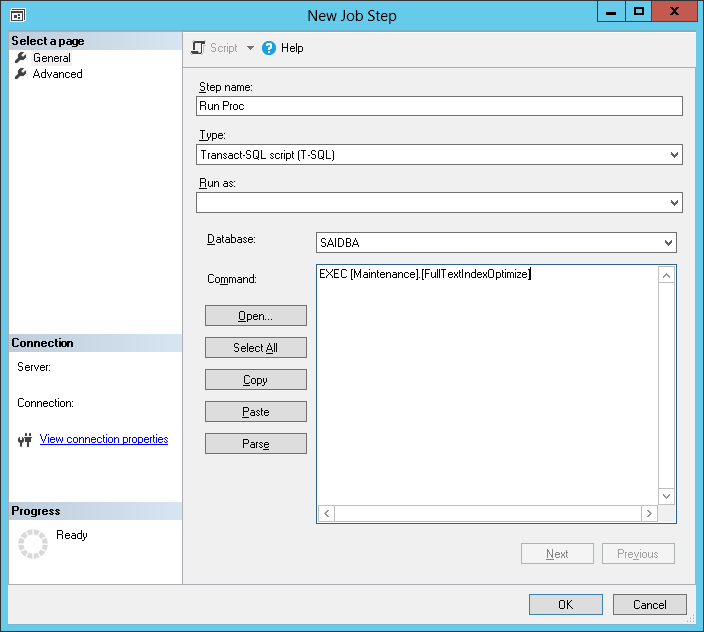
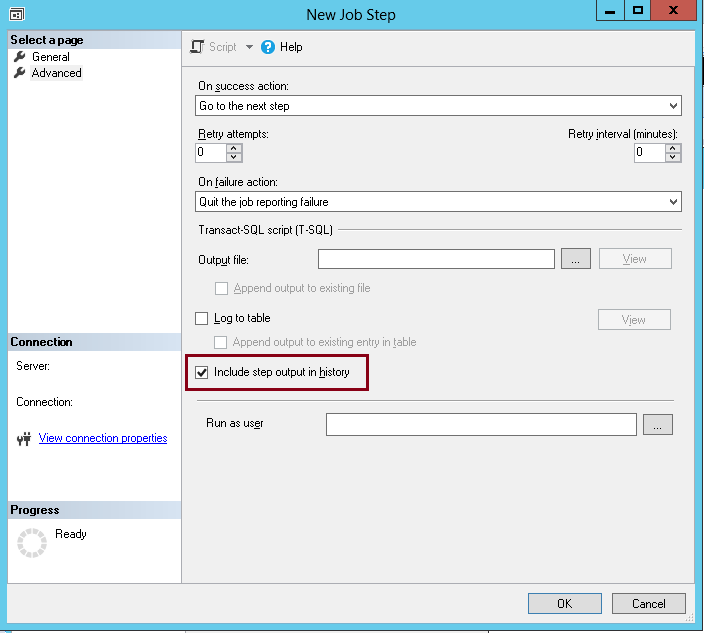
Fill fields in Task creation dialog. Don’t forget to select the “Include step output in history”. Once it’s done, click on the “OK” button
- Add a schedule according to your prerequisites
-
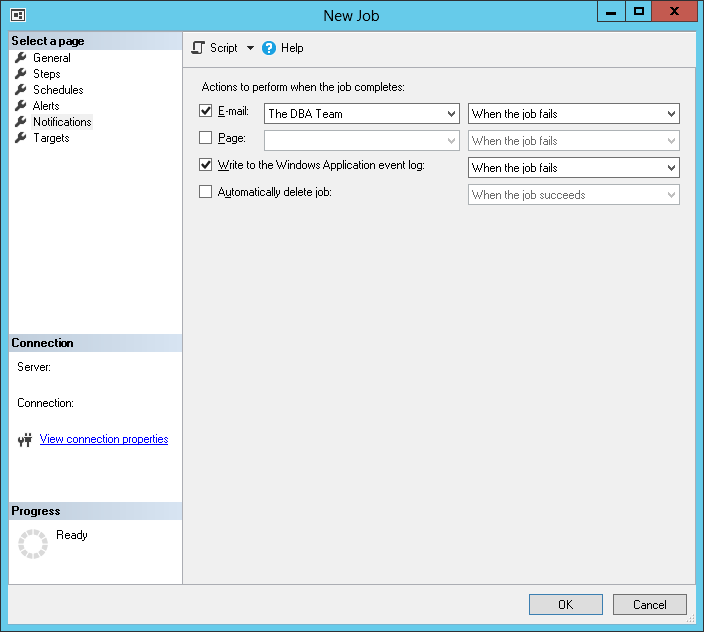
Don’t forget to setup notifications for this job
- Click OK and you are done
Previous article in this series
Downloads

I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018