
Introduction
In most cases, we will use clustered and non-clustered indexes to help a query go faster, but these kinds of indexes have their own limitations and cannot be used for fast text lookup. For instance, a LIKE operator will lead SQL Server to scan the whole table in order to pick up values that meet the expression next to this operator. This means it won’t be fast in every case, even if an index is created for considered column.
Microsoft SQL Server comes up with an answer to part of this issue with a Full-Text Search feature. This feature lets users and application run character-based lookups efficiently by creating a particular type of index referred to as a Full-Text Index. This index can be built on the top of one or more columns for a particular table. These columns can be of following data types:
- char,
- varchar,
- nchar,
- nvarchar,
- text,
- ntext,
- image,
- xml,
- varbinary(max)
- FILESTREAM
The building and usage of Full-Text indexes is always performed in a specific language context like English or French.
In the following sections, we will first take some time to understand overview how a Full-Text Search feature works. In this part, we will define some concepts and use them to understand how a Full-Text Index is built and maintained. We’ll even go through an illustrative example. Once we are done with theoretical aspects, we’ll then focus on some practical aspects in order to use and maintain this feature: we will see how to create a Full-Text indexed table, how to list out which tables have a Full-Text index and on which columns and much more
Concepts
Definitions
Now that we know what the purpose of Full-Text Search feature is, let’s invest some time in the understanding of how it works. This will help us manage this feature.
Notice that, already at SQL Server installation, we can tell that this feature is special as the installer defines a daemon service called “fdhost.exe”. This process will be referred in following as the “filter daemon host“.
It is started by a service launcher called MSSQLFDLauncher for security concerns. It will exchange data with SQL Server service (sqlservr.exe) via shared memory or a named pipe. Fdhost.exe process will access, filter and tokenize user data in order to actually build Full-Text indexes. It’s also called to analyze Full-Text queries, including word breaking and stemming (see below for more info).
This means that the entire Full-Text Search feature is spread across these two processes: fdhost.exe and sqlserv.exe and that some components of this feature interact with each other’s. Let’s review these components:
- User tables – (sqlserv.exe) – tables for which a full-text index exists.
- Full-Text gatherer – in sqlserv.exe – a thread responsible for scheduling and driving index population so as for monitoring.
- Thesaurus files – (sqlserv.exe)– files that contain synonyms of search terms.
- StopLists – in sqlserv.exe – objects that contain list of common words that can be ignored as they are not significant for a lookup (e.g. « and », « or », « but »)
- Query Processor thread – (sqlserv.exe)– thread that compiles and executes T-SQL queries and send Full-Text search to the Full-Text Engine twice: once at compilation and once during query execution. The query results is matched against the full-text index.
- Full-Text Engine – (sqlserv.exe)– can be seen as part of the Query Processor. It compiles and runs full-text queries and takes stoplists and thesaurus files into account before sending back results sets for these queries.
- Full-Text Indexer – (sqlserv.exe)– This thread builds the structure used to store index tokens.
- Filter Daemon Manager – (sqlserv.exe)– this thread monitors the status of the fdhost.exe daemon service.
- Protocol Handler Thread – (fdhost.exe) – this thread pulls data from memory for further processing and accesses data from a user table.
- Filters – (fdhost.exe) – they are specific by document type and allow the extraction of text data from various data types like varbinary, image or xml. They will be used, for instance, in order to remove any embedded formatting on the text of a MS Word document. You can run following query in order to get an overview of the filters defined by default:
123EXEC sp_help_fulltext_system_components 'filter';
- Word breakers and stemmers (fdhost.exe) – Each language has its set of word breakers. These components help to find the boundaries of each word in a sentence based on lexical rules of its associated language. So they help tokenizing sentences. Moreover, each word breaker is used in pair with a stemmer component. This component helps to find the root of a verb (its inflectional form) and conjugates verb, also based on language-specific rules. For instance, it will consider all these forms as being the same: “writing”, “wrote”, “writer” are all forms of the word “write”. Words identified by either of these components are inserted as keywords into a full-text index.
Architecture of a Full-Text Index
First of all, we have to know that any full-text index is stored into what Microsoft calls a “ full-text catalog”. It’s like a container for Full-Text indexes. Why did Microsoft define a logical container for Full-Text indexes? Simply because these indexes are usually split across multiple internal tables that are called full-text index fragments. These fragments are created as we insert or update records.
We can get back data about a Full-Text Index using dynamic management views and functions. One of these is the sys.dm_fts_index_keywords_by_document function. It returns a data set with the following columns:
- A hexadecimal representation of the keyword
- A human-readable representation of the keyword
- The identifier of the column subject to a Full-Text Index
- The identifier of the document or the row from which the current keyword has been indexed
- The number of times this keyword has been found in that document or row indicated by previous column
Here is a sample results set:

In that results set, we can see that for document with identifier “14536”, there are 3 occurrences of “%)” keyword.
This allows us to tell that a Full-Text index is an “inverted index” as it’s generated from a given data source and maps the results of this generation back to its data source. We can also notice that it computes statistics on the fly about the occurrence count. If we check Full-Text DMVs documentation, we’ll notice that these statistics can be obtained:
- by document,
- by property,
- by keywords.
This means that a Full-Text index is not really comparable to a normal index. But it’s not the only difference:
- We can define only one Full-Text index per table while we can define multiple ones for normal indexes.
- Adding data to a Full-Text index is referred to as population. In contrast to normal indexes, these populations are not part of a transaction. This means that even though the data has been inserted in a Full-Text indexed table, which happens once the transaction that inserts these data is committed, this does not necessarily mean that the Full-Text index has been updated. Full-Text index population is asynchronous.
- There is no grouping of normal indexes into an index catalog.
How a Full-Text Index is populated
As index population is asynchronous, what tells SQL Server it’s time to actually start a population? There is actually an option that is called “Change Tracking”, which can be configured by Full-Text Index and has several possible values:
- AUTO: asks SQL Server to track data changes for a table and automatically requestsindex population
- MANUAL: asks SQL Server to track data changes for a table but let user himself request for index population. This means that there could be hours or days before the Full-Text is updated
- OFF: means that SQL Server won’t track data changes and maintenance of this index is performed totally manually. On systems using this feature extensively, this mode could eventually require large maintenance windows as population would have to check read all the table.
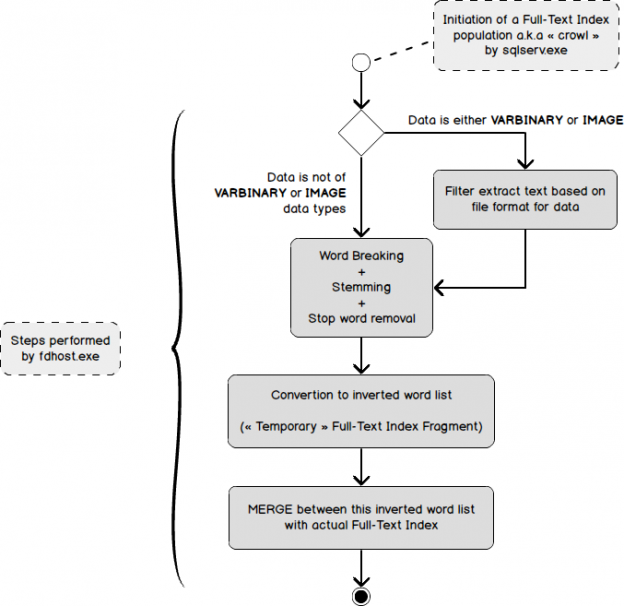
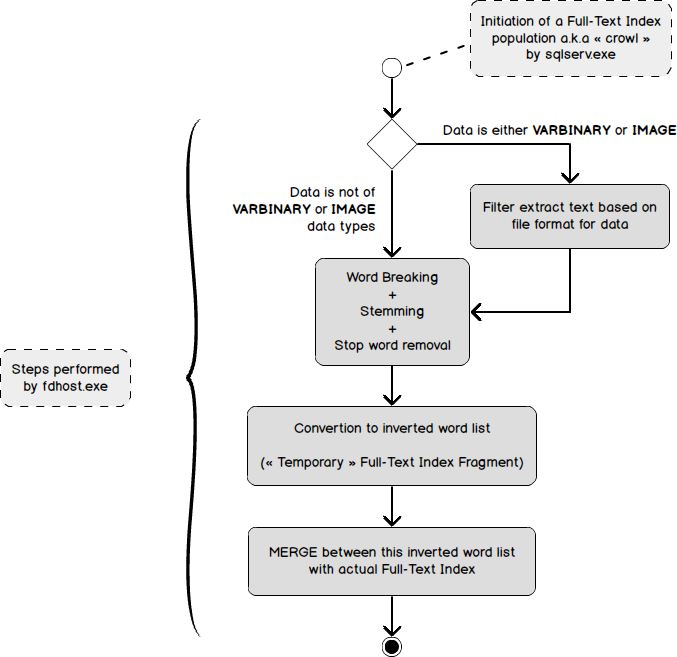
You will find below a diagram that summarizes the way a Full-Text Index has to be populated (for the first time or based on user activity) with only one new or updated record.
There is one important thing to notice: index population is initiated by sqlserv.exe and the population is actually performed by fdhost.exe. As discussed above, this population won’t happen every time a user created or changed a record in a Full-Text indexed table. Instead, when change tracking is in AUTO mode, it’s the Full-Text Gatherer thread (inside sqlserv.exe) that will tell fdhost.exe to start index population. This is part of the explanation why index population process is not synchronous with data modifications.
Full-Text Index population by example
Let’s say we have a table called MyDocs with two columns, one called DocId that uniquely identifies a record and one called Comments that contains a comment on the document in plain text, so it’s a VARCHAR column.
Let’s now assume this table has three records in as follows:
| DocId | Comments |
| 1 | Best book ever on Full-Text Index |
| 2 | Cool resource on indexes and tables |
| 3 | Cool workshop on Full-Text |
Now, let’s say that we already created a Full-Text Index on that table and SQL Server decided that it’s time to populate it.
It will first take care of the row with 1 as value for DocId column. It will tokenize the contents of Comments column and start to build an index fragment that maps the each token to this record like this:
| Keyword | DocId |
| best | 1 |
| book | 1 |
| ever | 1 |
| on | 1 |
| full-text | 1 |
| index | 1 |
It will then cut “full-text” into “full” and “text” and remove the “on” keyword as it’s a stop word we’ll have following keywords list:
| Keyword | DocId |
| best | 1 |
| book | 1 |
| ever | 1 |
| Full | 1 |
| full-text | 1 |
| index | 1 |
| Text | 1 |
Note: Notice that the index is build using alphabetical ordering
It will do the same with the second document so that the keywords list will be composed of: “cool” , “indexes”, “resources” and “tables”. It will then analyze the Comments column for the third document and build following keywords list: “cool”, “Full-Text”, “Full”, “Text” and “workshop”.
The results of the analysis for each document could lead to the creation of an index fragment. If we put them together, we have following list of keywords:
| Keyword | DocId | #Occurrences |
| best | 1 | 1 |
| book | 1 | 1 |
| Cool | 2,3 | 2 |
| ever | 1 | 1 |
| Full | 1,3 | 2 |
| full-text | 1,3 | 2 |
| index | 1 | 1 |
| Indexes | 2 | 1 |
| Resource | 2 | 1 |
| Tables | 2 | 1 |
| Text | 1,3 | 2 |
| Workshop | 3 | 1 |
The list above would be the actual data stored in our Full-Text index as the table was empty. You can check that this is actually what you get by running the code in the Appendix A of this article. But, it’s recommended to read all this article before going straight to this appendix!
How to create a table with Full-Text enabled
Let’s say we have a table called [dbo].[DM_OBJECT_FILE] already created using following statement.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE [dbo].[DM_OBJECT_FILE] ( [FILE_ID] [int] NOT NULL, [FILE_FIN] [int] NOT NULL, [FILE_TITLE] [Varchar] (255) , [OBJ_ID] [int] NOT NULL , [FILE_ATT] [smallint] NOT NULL, [FILE_PATH] [Varchar] (500) NULL, [FILE_EXT] [Varchar](50) NULL, [FILE_TXT] [varbinary] (max) NULL, [FILE_KEYWORDS] [Varchar] (1000) NULL, [FILE_STATUS] [smallint] NULL, [FILE_TXT_SIZE] [Int] default 0, [OBJ_FILE_IDX_DOCTYPE] [Varchar] (3) Null, CONSTRAINT [PK_DM_OBJECT_FILE] PRIMARY KEY CLUSTERED ([FILE_ID]) ) |
Each file imported into that table is uniquely identified by FILE_ID column, FILE_TXT column refers to the contents of this file and OBJ_FILE_IDX_DOCTYPE refers to the kind of document that is stored in the FILE_TXT column.
Now, we are willing to create a Full-Text Index on this table. This means that Full-Text feature should already be installed on our instance. To check whether it’s the case or not, we can use the following query:
|
1 2 3 4 5 6 7 8 |
SELECT CASE FULLTEXTSERVICEPROPERTY('IsFullTextInstalled') WHEN 1 THEN 'Full-Text installed.' ELSE 'Full-Text is NOT installed.' END ; |
If it appears that Full-Text is not installed, you should consider to install it first.
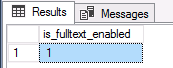
As soon as you are sure that Full-Text feature is installed, we should check that FullText search is enabled for the database where our table is stored. We can check it with the following statement:
|
1 2 3 4 5 |
SELECT is_fulltext_enabled FROM sys.databases WHERE database_id = DB_ID() |
We should get following output:
If we don’t, we should run following T-SQL statement:
|
1 2 3 |
exec sp_fulltext_database 'enable'; |
But this is not the end! We also want to check if there is already a full-text catalog, which is a virtual database object that does not belong to any filegroup and refers to a group of Full-Text indexes. To do so, we will run the following query:
|
1 2 3 4 |
select * FROM sys.fulltext_catalogs |
If this query did not return any row, then we have to create one or more fulltext catalogs and set one of them as default. To perform this action, we will use a statement based on CREATE FULLTEXT CATALOG as follows:
|
1 2 3 |
CREATE FULLTEXT CATALOG FullTextCatalog AS DEFAULT; |
Now, we are ready to create the Full-Text index on [dbo].[DM_OBJECT_FILE] table. To create such an index we have to have some information:
- What is the key index to be used in order to uniquely identify records?
- What columns should be part of the index? (Here: FILE_TXT column will be used)
- What type of document does the column represent and in which column this information is stored? (Here: OBJ_FILE_IDX_DOCTYPE column will be used)
- Which language is used in this column or is it preferable to be totally neutral regarding language interpretation?
- Do we enable change tracking and let the index update by itself or do we manage this part ourselves?
You will find below the create statement for a Full-Text Index on FILE_TXT column from table dbo.DM_OBJECT_FILE, with neutral language interpretation, automatic update and no stop list.
|
1 2 3 4 5 6 7 8 9 |
CREATE FULLTEXT INDEX ON dbo.DM_OBJECT_FILE ( FILE_TXT TYPE COLUMN OBJ_FILE_IDX_DOCTYPE LANGUAGE 0 ) KEY INDEX PK_DM_OBJECT_FILE WITH CHANGE_TRACKING = AUTO, STOPLIST=OFF ; |
How to change the configuration of a Full-Text Index
There is a T-SQL command called ALTER FULLTEXT INDEX that allows us to perform some operations on a Full-Text Index like:
- Enable or disable the index
- Enable or disable change tracking for Full-Text Index population. If it stays enabled, we can tell SQL Server whether to automatically schedule an index population based on user activity or to let us do it manually.
- Add, modify or edit the list of columns that should be part of the Full-Text Index.
- Control index population (only useful when we did not enabled change tracking in automated mode)
For further details, please refer to Microsoft’s documentation page.
How to use a Full-Text Index in queries
Once everything is in place, our Full-Text Index is created on our table and we can start using it with built-in functions. Following functions are predicate functions. This means that it returns a Boolean value that can be used in a WHERE clause.
| Function Name | Explanation | ||
| CONTAINS |
Searches for precise or fuzzy (less precise) matches to single words and phrases, words within a certain distance of one another, or weighted matches in SQL Server. Appropriate types of lookups:
Example usage:
| ||
| FREETEXT | Searches for values that match the meaning and not just the exact wording of the words in the search condition. This function will:
Example usage:
| ||
| CONTAINSTABLE | Same lookup as CONTAINS function except that it returns a table of rows with following columns:
Simple example usage: look for “blabla” or “huh”
| ||
| FREETEXTTABLE | Returns a table of zero, one, or more rows for those columns containing character-based data types for values that match the meaning, but not the exact wording, of the text in the specified column. Simple example usage: look for “blabla” or “huh”
|
Here is a comparison in terms of the number of results between CONTAINSTABLE and FREETEXTTABLE predicates using the example usage above.
Firstly, the results of CONTAINSTABLE:

Secondly, the results of FREETEXTTABLE:
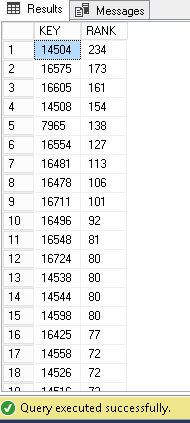
As we can see, for the first one, we get back only 13 rows and ranking value is not that high while the second returns 17 rows more and ranking values are higher. Furthermore, we can check that the ordering of keys is different: The key 16575 is at the fourth position in the first screen capture while it’s at the second position in the second one.
These predicate functions can be used extensively and are not limited to fixed lookups. Instead, there is extensive grammar functionality associated to its lookup parameter. On each documentation page for these functions, we will find the definition of a <contains_search_condition> in the function’s grammatical definition. If we look closely at this grammar, we can see that it’s very rich and we have to learn this in order to get the most power out of Full-Text Search feature!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
<contains_search_condition> ::= { <simple_term> | <prefix_term> | <generation_term> | <generic_proximity_term> | <custom_proximity_term> | <weighted_term> } | { ( <contains_search_condition> ) { { AND | & } | { AND NOT | &! } | { OR | | } } <contains_search_condition> [ ...n ] } <simple_term> ::= { word | "phrase" } <prefix term> ::= { "word*" | "phrase*" } <generation_term> ::= FORMSOF ( { INFLECTIONAL | THESAURUS } , <simple_term> [ ,...n ] ) <generic_proximity_term> ::= { <simple_term> | <prefix_term> } { { { NEAR | ~ } { <simple_term> | <prefix_term> } } [ ...n ] } <custom_proximity_term> ::= NEAR ( { { <simple_term> | <prefix_term> } [ ,…n ] | ( { <simple_term> | <prefix_term> } [ ,…n ] ) [, <maximum_distance> [, <match_order> ] ] } ) <maximum_distance> ::= { integer | MAX } <match_order> ::= { TRUE | FALSE } <weighted_term> ::= ISABOUT ( { { <simple_term> | <prefix_term> | <generation_term> | <proximity_term> } [ WEIGHT ( weight_value ) ] } [ ,...n ] ) |
Moreover, other functions returning a table have been added starting SQL Server 2012. These are:
Looking for information related to the Full-Text feature
How to get the list of supported languages
We can run following query in order to get back the list of supported languages and their language identifier:
|
1 2 3 4 5 |
SELECT * FROM sys.fulltext_languages ORDER BY lcid |
Here is a sample of the results set:
How to get the list of Full-Text indexes in a particular database
Let’s say we want to list out which tables and columns are used with the Full-Text feature. To do so, we can run the following query:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
SELECT SCHEMA_NAME(tbl.schema_id) as SchemaName, tbl.name AS TableName, FT_ctlg.name AS FullTextCatalogName, i.name AS UniqueIndexName, scols.name AS IndexedColumnName FROM sys.tables tbl INNER JOIN sys.fulltext_indexes FT_idx ON tbl.[object_id] = FT_idx.[object_id] INNER JOIN sys.fulltext_index_columns FT_idx_cols ON FT_idx_cols.[object_id] = tbl.[object_id] INNER JOIN sys.columns scols ON FT_idx_cols.column_id = scols.column_id AND FT_idx_cols.[object_id] = scols.[object_id] INNER JOIN sys.fulltext_catalogs FT_ctlg ON FT_idx.fulltext_catalog_id = FT_ctlg.fulltext_catalog_id INNER JOIN sys.indexes i ON FT_idx.unique_index_id = i.index_id AND FT_idx.[object_id] = i.[object_id]; |
Here is a sample results:

How to check the results of a Full-Text parsing
There are two ways to check how Full-Text feature parses a given text depending on the source of the text.
Source of the text is a String
If you want to check fast what keywords you would get for a particular string, you might want to use sys.dm_fts_parser built-in function.
Here is an example of call to that function.
- The first parameter is the string that has to be parsed.
- The second parameter is the language identifier. Here, it’s set to 0, which means it’s neutral.
- The hhird parameter is the identifier of the stoplist. Here no stoplist is used.
- The last parameter tells this function whether to be sensitive or not to accents. Here, we asked for insensitivity.
In other words, this function will take the information you would provide when creating a Full-Text Index.
|
1 2 3 4 5 6 7 8 |
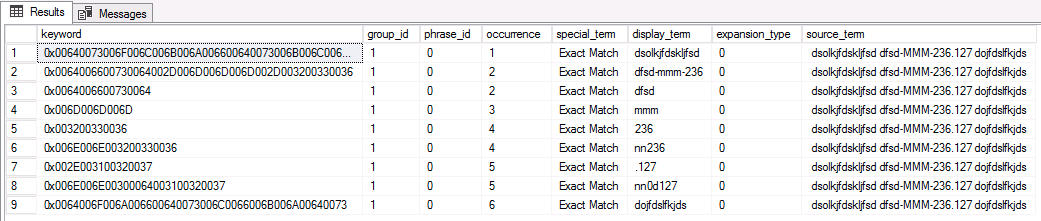
select * from sys.dm_fts_parser( '" dsolkjfdskljfsd dfsd-MMM-236.127 dojfdslfkjds"', 0, NULL, 0 ) ; |
Here are corresponding results. We can see that from this simple line, we get multiple keywords generated:
Source of the text is a Full-Text Index
If a table is already created with a Full-Text index, we would use another dynamic management function (DMF) called sys.dm_fts_index_keywords which takes as a parameter:
- The database identifier in which it should look at
- The object identifier in that database
It returns a dataset with a hexadecimal representation of the keyword, its corresponding form in the plain text, the identifier of the column in which the keyword has been found and finally the number of documents where this keyword can be found.
You will find below a T-SQL query to get back keywords found by Full-Text feature in our dbo.DM_OBJECT_FILE table so as its results set.
|
1 2 3 4 |
select * From sys.dm_fts_index_keywords(DB_ID(),OBJECT_ID('dbo.DM_OBJECT_FILE')) |

How to maintain Full-Text Indexes with change tracking in AUTO mode
If you are DBA, you can’t neglect the question of maintenance for these particular indexes that are Full-Text indexes. Except for large systems, I think there is no reason to set change tracking to another mode than AUTO. That’s the reason why we will just cover this mode.
Actually, it’s difficult to get good recommendations about the way we should do this. For example, I haven’t found a rule from Microsoft that says “if there is 10% fragmentation then reorganize, if it’s more than 30% then rebuild the index”, which is the common guideline for normal index maintenance.
After reading the paragraph above, there are questions that should emerge:
- How do we rebuild a full-text index?
- Can a Full-Text index be fragmented?
- If so, how could we get some details on this?
- Once we have details on this, how to determine when it’s necessary to take corrective actions?
How to reorganize or rebuild a particular Full-Text index?
There is no capability to reorganize or rebuild a given Full-Text index except by dropping and recreating it, using DROP FULLTEXT INDEX and CREATE FULLTEXT INDEX commands.
However, let’s remember that these indexes are grouped into a logical container called a Full-Text catalog. While we can’t rebuild or reorganize a particular index, we can do it on a Full-Text catalog using ALTER FULLTEXT CATALOG T-SQL command.
|
1 2 3 4 5 6 7 |
ALTER FULLTEXT CATALOG catalog_name { REBUILD [ WITH ACCENT_SENSITIVITY = { ON | OFF } ] | REORGANIZE | AS DEFAULT } |
Can a Full-Text index be fragmented?
The answer to this question is pretty obvious as we said that, by design, the Full-Text index is built using index fragments created during index population (or index crawl). This means that, yes, Full-Text indexes can suffer fragmentation and a high fragmentation will obviously have a direct impact on application performances.
How to check for Full-Text index fragmentation?
Microsoft provides a set of management tables or views that we can query in order to get an overview of Full-Text index fragmentation. These are:
- sys.fulltext_catalogs in order to get the list of Full-Text Catalogs
- sys.fulltext_indexes in order to get the list of Full-Text Indexes
- sys.fulltext_index_fragments in order to get the list of index fragments
We can combine data from these management objects in order to get back an overview of:
- Which indexes are in which Full-Text Catalog?
- How much space is consumed by a Full-Text Index?
- On which object a Full-Text Index in based?
- How important the fragmentation is (in size (Mb) and percent)
This can be performed using the following query, which is an adaptation of the one published by Geoff Patterson on StackExchange:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
WITH FragmentationDetails AS ( SELECT table_id, COUNT(*) AS FragmentsCount, CONVERT(DECIMAL(9,2), SUM(data_size/(1024.*1024.))) AS IndexSizeMb, CONVERT(DECIMAL(9,2), MAX(data_size/(1024.*1024.))) AS largest_fragment_mb FROM sys.fulltext_index_fragments GROUP BY table_id ) SELECT DB_NAME() AS DatabaseName, ftc.fulltext_catalog_id AS CatalogId, ftc.[name] AS CatalogName, fti.change_tracking_state AS ChangeTrackingState, fti.object_id AS BaseObjectId, QUOTENAME(OBJECT_SCHEMA_NAME(fti.object_id)) + '.' + QUOTENAME(OBJECT_NAME(fti.object_id)) AS BaseObjectName, f.IndexSizeMb AS IndexSizeMb, f.FragmentsCount AS FragmentsCount, f.largest_fragment_mb AS IndexLargestFragmentMb, f.IndexSizeMb - f.largest_fragment_mb AS IndexFragmentationSpaceMb, CASE WHEN f.IndexSizeMb = 0 THEN 0 ELSE 100.0 * (f.IndexSizeMb - f.largest_fragment_mb) / f.IndexSizeMb END AS IndexFragmentationPct FROM sys.fulltext_catalogs ftc JOIN sys.fulltext_indexes fti ON fti.fulltext_catalog_id = ftc.fulltext_catalog_id JOIN FragmentationDetails f ON f.table_id = fti.object_id ; |
Here is a sample result. For image readability, rows have been split into two sets:

When do we need to take corrective actions?
I haven’t seen any recommendations about this on Microsoft’s documentation website but here are the results of my searches:
- Based on the researches of Geoff Patterson, he defined that a Full-Text Index needs to be rebuilt starting at 10% of fragmentation.
- In his blog post, Barry Kind suggests to reorganize the Full-Text catalog when 30 to 50 fragments per table are reached.
There are some tests that have to be done in order to find the right set of criteria but they won’t be covered by this article.
Next article in this series:
Appendix A – code to create testing.MyDocs table
You will find below the T-SQL instructions that will allow you to check the results we announced in section Full-Text Index population by example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
create schema testing; DROP TABLE testing.MyDocs; create table testing.MyDocs ( DocId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_MyDocs PRIMARY KEY, Comments VARCHAR(MAX) ); insert into testing.MyDocs (comments) values ('Best book ever on Full-Text Index'), ('Cool resource on indexes and tables'), ('Cool workshop on Full-Text') ; CREATE FULLTEXT INDEX ON testing.MyDocs( Comments LANGUAGE 1033 /* English */ ) KEY INDEX PK_MyDocs ; select * From sys.dm_fts_index_keywords_by_document(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs')) --where document_id = 3 ; select * From sys.dm_fts_index_keywords(DB_ID(DB_NAME()),OBJECT_ID('testing.MyDocs')) -- cleanups DROP TABLE testing.MyDocs DROP SCHEMA testing; |

I'm one of the rare guys out there who started to work as a DBA immediately after his graduation. So, I work at the university hospital of Liege since 2011. Initially involved in Oracle Database administration (which are still under my charge), I had the opportunity to learn and manage SQL Server instances in 2013. Since 2013, I've learned a lot about SQL Server in administration and development.
I like the job of DBA because you need to have a general knowledge in every field of IT. That's the reason why I won't stop learning (and share) the products of my learnings.
View all posts by Jefferson Elias
- How to perform a performance test against a SQL Server instance - September 14, 2018
- Concurrency problems – theory and experimentation in SQL Server - July 24, 2018
- How to link two SQL Server instances with Kerberos - July 5, 2018