
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of both SQL Server tables and indexes, the main guidelines that you can follow to design a proper index, the list of operations that can be performed on the SQL Server indexes, and finally how to design effective Clustered and Non-clustered indexes that the SQL Server Query Optimizer will always take benefits from, in speeding up the data retrieval process, which is the main goal of creating an index. In this article, we will go through the different types of SQL Server indexes, above and beyond Clustered and Non-clustered indexes classification, and when to use them.
Unique index
A Unique index is used to maintain the data integrity of the columns on which it is created, by ensuring that there are no duplicate values in the index key, and the table rows, on which that index is created. This ensures data will be unique based on the index key, depending on the characteristics of the data that is stored in the index key column or list of columns. If the Unique index key consists of one column, SQL Server will guarantee that each value in the index key is unique. On the other hand, if the Unique index key consists of multiple columns, each combination of values in that index key should be unique. You can define both the Clustered and Non-clustered indexes to be unique, as long as the data in these index keys are unique.
A Unique index will be created automatically when you define a PRIMARY KEY or UNIQUE KEY constraints on the specified columns. In all cases, creating a Unique index on the unique data, instead of creating a non-unique index on the same data, is highly recommended, as it will help the SQL Server Query Optimizer to generate the most efficient execution plan based on the additional useful information provided by that index.
Assume that we need to create the below table, using the CREATE TABLE T-SQL statement below, without specifying any CREATE INDEX statement, as shown below:
|
1 2 3 4 5 |
CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) CONSTRAINT UQ_Name UNIQUE, ADDRESS NVARCHAR(MAX) ) |
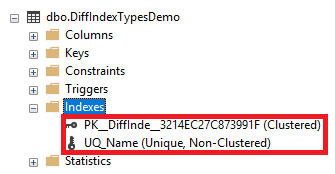
You will see that a Unique Clustered index will be created automatically on the ID column of that table, to enforce the PRIMARY KEY constraint, and a Unique Non-clustered index will be created automatically on the Name column to enforce the UNIQUE constraint, as shown below:
Take into consideration that the index that is created automatically to enforce any constraint cannot be dropped using a DROP INDEX T-SQL statement. If we try to drop the Unique index created previously to enforce the UNIQUE constraint using the DROP INDEX T-SQL statement below:
|
1 |
DROP INDEX UQ_Name ON DiffIndexTypesDemo |
the statement will fail, showing that we cannot explicitly drop any index that is created automatically to enforce a constraint, as shown in the error message below:

To drop that index, we should drop the constraint that created the index, using the ALTER TABLE…DROP CONSTRAINT T-SQL statement below:
|
1 |
ALTER TABLE DiffIndexTypesDemo DROP CONSTRAINT UQ_Name |
The Unique index can be also created manually, away from the constraint, by specifying the UNIQUE keyword in the Clustered or Non-Clustered index creation statement, as in the CREATE INDEX T-SQL statement below:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (NAME) |
The previous CREATE INDEX statement can be used to create a Unique Non-Clustered index on the Name column, as shown below:
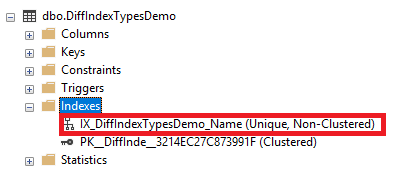
A Unique index is used to enforce the uniqueness of the index key values. For example, the previous index is used to make sure that no duplicate value for the Name column is available in that table. If we try to execute the below INSERT INTO statement that inserts two new records with the same Name values into that table:
|
1 2 |
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Amman'), ('John', 'Zarqa') |
The statement will fail, showing that it is not allowed to insert duplicate values for the Name column, that is enforced by the created Unique index, providing the prevented duplicate values, as shown in the error message below:

If we try to drop the Unique index, using the DROP INDEX T-SQL statement below:
|
1 |
DROP INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo |
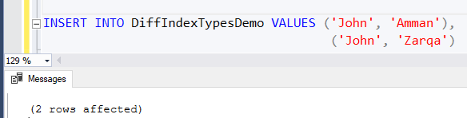
then execute the same INSERT INTO statement, you will see that the duplicate Name values will be inserted successfully, having no constraint or index that enforce the uniqueness of that column values, as shown clearly below:
Now, if we try to create the Unique index again on that table, the CREATE INDEX statement will fail, as the table already have duplicate values in the Name column as shown below:

Neither will using the IGNORE_DUP_KEY index creation option will not work with the UNIQUE index. If we try to enable that option, while creating the Unique index, in order to ignore the existing duplicate values, the statement will fail again, showing that we cannot create a Unique index with duplicate index key values available in the table, as shown in the error message below:

To be able to create the Unique index on the Name column, we should delete or update the duplicate values. In our case, we will update the second duplicate name using the UPDATE statement below:
|
1 2 3 |
SELECT * FROM DiffIndexTypesDemo UPDATE DiffIndexTypesDemo SET Name='Jack' where ID=4 SELECT * FROM DiffIndexTypesDemo |
With the table rows before and after the UPDATE operation is shown below:
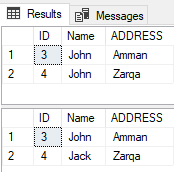
Trying to create the Unique index after resolving the duplicate issue, the Unique index will be created successfully as shown below:

We can include another column in the Unique index key to enforce the uniqueness of the combination of the two columns, rather than enforcing it on the Name column only. The below CREATE INDEX will be used to create a unique index that enforces the uniqueness of the ID and Name columns combination:
|
1 |
CREATE UNIQUE NONCLUSTERED INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (ID,NAME) |
If we try to run the below INSERT INTO statement, that inserts two records with the same name, the records will be inserted successfully, as the ID column is IDENTITY column that will assign different values for each inserted row from the below:
Filtered index
A Filtered index is an optimized Non-Clustered index, introduced in SQL Server 2008, that uses a filter predicate to improve the performance of queries that retrieve a well-defined subset of rows from the table, by indexing the only portion of the table rows. The smaller size of the Filtered index, that consumes a small amount of the disk space compared with the full-table index size, and the more accurate filtered statistics, that cover the filtered index rows with only minimal maintenance cost, help in improving the performance of the queries by generating a more optimal execution plan.
An example of well-defined subsets of data, that can benefit from Filtered index performance gains is the Sparse columns with a large number of NULL values.
For more information about the Sparse columns, check Optimize NULL values storage consumption using SQL Server Sparse Columns.
If your queries are retrieving data from non-NULL rows, you can improve the query performance by creating a Filtered index that covers the rows with non-NULL values. Other examples of the well-defined subsets of data, that can benefit from a Filtered index are the columns that contain a distinct range of values or heterogeneous categorized data. To understand it practically, let us drop the previously created testing table and create a new one using the T-SQL script below:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS NVARCHAR(MAX) ) GO |
After creating the table, we will fill it with 10,100 records; providing only 100 values of the Name column value and 10K rows with NULL values for that column, using the INSERT INTO T-SQL statements below:
|
1 2 3 4 |
INSERT INTO DiffIndexTypesDemo VALUES ('John', 'Ramtha') GO 100 INSERT INTO DiffIndexTypesDemo VALUES (NULL, 'Zarqa') GO 10000 |
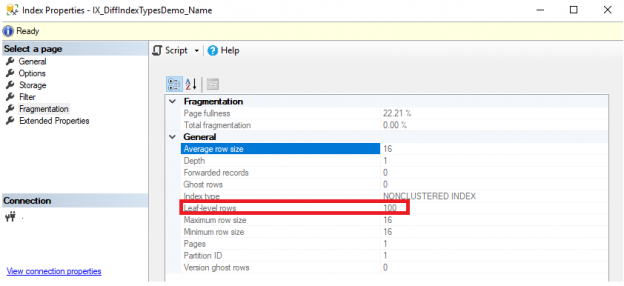
The Name column on the previous table can be considered a Sparse column, with about 99% of the data being NULL values. Before planning to create the index, we should understand the queries that are retrieving data from that table. Having all the queries search for the rows with non-NULL values for the Name column, then it will be beneficial to create a Filtered index on the Name column, that will be smaller and cost less to maintain as it contains less than 1% of the column’s values, compared with a full-table index that contains all values for the Name column. The following CREATE INDEX T-SQL command is used to create a Filtered index on the Name column, by providing a filtered predicate, as shown below:
|
1 |
CREATE INDEX IX_DiffIndexTypesDemo_Name ON DiffIndexTypesDemo (Name) WHERE NAME IS NOT NULL |
You can check the number of records included in that index from the Fragmentation tab of the index properties window shown below:
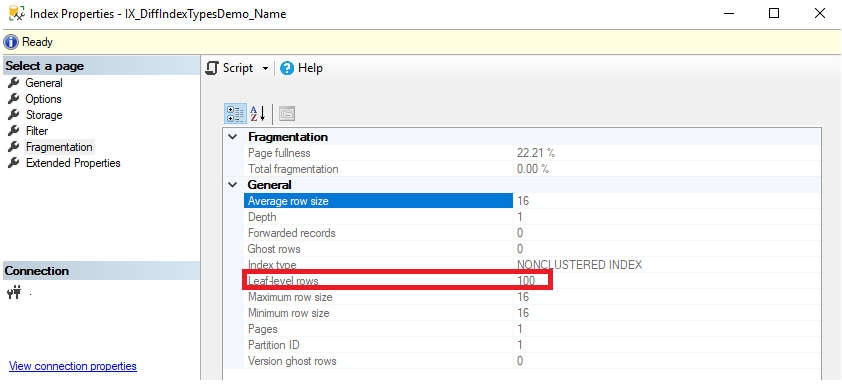
The following query, that retrieves non-NULL values of the Name column, will obviously benefit from the Filtered index:
|
1 2 3 4 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT Name FROM [dbo].[DiffIndexTypesDemo] WHERE NAME ='John' |
Which is clear from the generated execution plan, IO and Time statistics below. You will see that the SQL Server will retrieve the requested data in no time by seeking the Filtered index, as shown below:
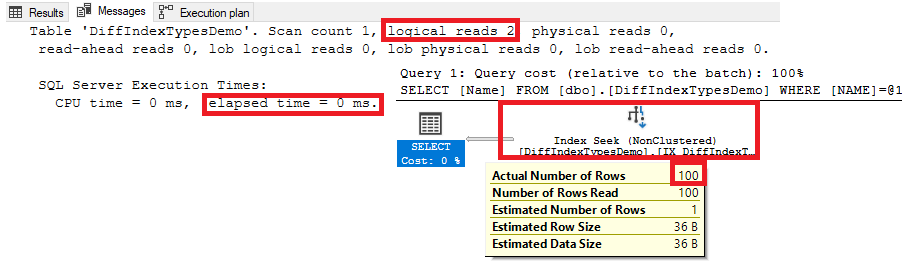
It is recommended to include the smallest number of columns in the Filtered index that is absolutely required to cover the query. The column that is used in the Filtered index predicate can be added as a key or non-key column in the Filtered index if the query uses the same condition used in the Filtered index predicate and the query does not return that column with the query result. Otherwise, the column should be added as a key column in the Filtered index.
Take into consideration that the WHERE clause of the Filtered index will accept simple comparison operators only. If you need a filter expression that references multiple tables or has a complex predicate, you should create a view.
For more information about the indexes views, check SQL Server indexed views.
On the other hand, If the Filtered index includes most of the rows in the table, it is recommended to use a full-table index instead of a Filtered index, as the Filtered index maintenance will be more expensive than the full-table index in this situation. The Filtered index creation depends mainly on your understanding for the data and the submitted queries and will not be found in the SQL Server missing indexes suggestions, except when using the Database Engine Tuning Advisor tool that can help in suggesting IS NOT NULL Filtered index.
Spatial index
Geometry and Geography spatial data types were introduced the first time in SQL Server 2008. The geometry data type is used to store geometric planner data such as point, lines, and polygons, where the geography data type is used to represent geographic objects on an area on the Earth’s surface, such as GPS latitude and longitude coordinates.
A Spatial index is a special type of index, created on the columns that store spatial data, to improve the performance of the operations performed on the spatial columns, by reducing the number of objects on which relatively costly spatial operations need to be applied. Take into consideration that creating Spatial indexes require the table to have a clustered PRIMARY KEY.
Assume that we have recreated the previous table by changing the Address column data type to be geometry spatial, as shown below:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS geometry ) GO |
Now, we can easily create a Spatial index on the created table, as it meets the two requirements for creating a Spatial index; there is a column with spatial data type and a Clustered PRIMARY KEY on that table.
A Spatial index can be created on the geometry column using CREATE SPATIAL INDEX T-SQL command by providing the Spatial index name, the name of the table on which the index will be created, the spatial column, the tessellation schema and the bounding box.
The below CREATE SPATIAL INDEX T-SQL statement is used to create a Spatial index on the demo table using the default tessellation schema with a specific bounding box. The bounding box is numeric four-tuple values that define the four coordinates of the bounding box: the x-min and y-min coordinates of the lower, left corner, and the x-max and y-max coordinates of the upper right corner.
|
1 2 3 |
CREATE SPATIAL INDEX SIX_DiffIndexTypesDemo_Address ON DiffIndexTypesDemo(Address) WITH ( BOUNDING_BOX = ( 0, 0, 500, 200 ) ); |
XML index
An XML index is a special type of index that is created on XML binary large objects (BLOBs) in the XML data type columns, to enhance the performance of the queries that are retrieving data from that table, by indexing all tags, values, and paths over the XML instances in that column.
There are two types of XML indexes; the Primary XML index and the Secondary XML index, with the ability to create up to 249 XML index on each table. The Primary XML index is the first Clustered XML index created on the table, with the clustered key consists of the clustering of the user table and an XML node identifier. After creating the Primary XML index, different types of Secondary XML indexes can be created on the table, such as PATH, VALU, and PROPERTY, to improve the performance of the submitted queries, depending on the type of there queries.
The Secondary VALUE XML index represents the node value and path of the primary XML index. The Secondary PATH XML index built on the path values and the node values in the primary XML index, allowing efficient seeks when searching for paths. The Secondary PROPERTY XML index contains the base table Primary Key, the path and the node value of the Primary XML index.
Let us redesign the previous table by changing the Address column data type to be XML, as shown below:
|
1 2 3 4 5 6 7 8 |
DROP TABLE DiffIndexTypesDemo GO CREATE TABLE DiffIndexTypesDemo ( ID INT IDENTITY (1,1) PRIMARY KEY, Name Varchar(50) , ADDRESS XML ) GO |
In order to enhance the performance of the queries that retrieve XML values, we will create a Primary XML index on the Address column, using the CREATE PRIMARY XML INDEX T-SQL statement below:
|
1 2 3 |
CREATE PRIMARY XML INDEX PXML_DiffIndexTypesDemo_Address ON DiffIndexTypesDemo (Address); GO |
Then create a PATH Secondary XML index on that column using the CREATE XML INDEX T-SQK statement shown below:
|
1 2 3 4 |
CREATE XML INDEX ISXML_DiffIndexTypesDemo_Address_Path ON DiffIndexTypesDemo (Address) USING XML INDEX PXML_DiffIndexTypesDemo_Address FOR PATH; GO |
Other index special types
Columnstore index: The Columnstore index is a feature in which the data will be physically organized in columnar data format, unlike traditional row-store technology, with the row-wise format, that is used for storing, managing and retrieving large data using a columnar data format. A Columnstore index works well for data warehousing workloads that perform bulk loads and read-only queries, achieving up to 7x data compression over the uncompressed data size.
For more information about Columnstore index, check How to Create a Clustered Columnstore Index on a Memory-Optimized Table.
Full-text index: This is a special type of token-based functional index, that is built and maintained by the SQL Server Full-Text Engine, to enhance the performance of character string data search. For more information about the Full-Text search, check Full-Text Index Population.
Hash index: This is a special type of index used in Memory-Optimized tables, to access the data through an in-memory hash table, consuming a fixed amount of memory, specified by the bucket count.
For more information about Memory-Optimized tables, check In-Memory OLTP Enhancements in SQL Server 2016.
Stay tuned for the next article, in which we will discuss how to enhance the performance of queries by using the appropriate type of index.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021