
In the previous articles of this series (see below for the full index of articles), we went through the internal structure of SQL Server tables and indexes, listed a number of guidelines that help in designing a proper index, discussed the operations that can be performed on SQL Server indexes and finally showed how to design and create a SQL Server Clustered index to speed up data retrieval operations. In this article, we will see how to design an effective Non-clustered index that will improve the performance of frequently used queries that are not covered with a Clustered index and, in doing so, enhance the overall system performance.
Non-clustered index structure overview
A Non-clustered index is built using the same 8K-page B-tree structure that is used to build a Clustered index, except that the data and the Non-clustered index are stored separately. A Non-clustered index is different from a Clustered index in that, the underlying table rows will not be stored and sorted based on the Non-clustered key, and the leaf level nodes of the Non-clustered index are made of index pages instead of data pages. The index pages of the Non-clustered index contain Non-clustered index key values with pointers to the storage location of these rows in the underlying heap table or the Clustered index.
If a Non-Clustered index is built over a heap table or view (read more about SQL Server indexed views, that have no Clustered index) the leaf level nodes of that index hold the index key values and Row ID (RID) pointers to the location of the rows in the heap table. The RID consists of the file identifier, the data page number, and the number of rows on that data page. On the other hand, if a Non-clustered index is created over a Clustered table, the leaf level nodes of that index contain Non-clustered index key values and clustering keys for the base table, that are the locations of the rows in the Clustered index data pages. If a Non-clustered index is built over a non-unique Clustered index, the leaf level nodes of the Non-clustered index will hold additional uniqueifier values of the data rows, that is added by the SQL Server Engine to ensure uniqueness of the Clustered index.
When submitting a query that searches for specific rows based on Non-clustered index key values, the SQL Server Query Optimizer will search for that key value in the Non-clustered index pages and use the row locator value to locate the requested row in the underlying table, then retrieve the requested records directly from the data storage location, speeding up the data retrieval process, as the Non-clustered index holds a full description for the data exact location in underlying table, based on the index key values.
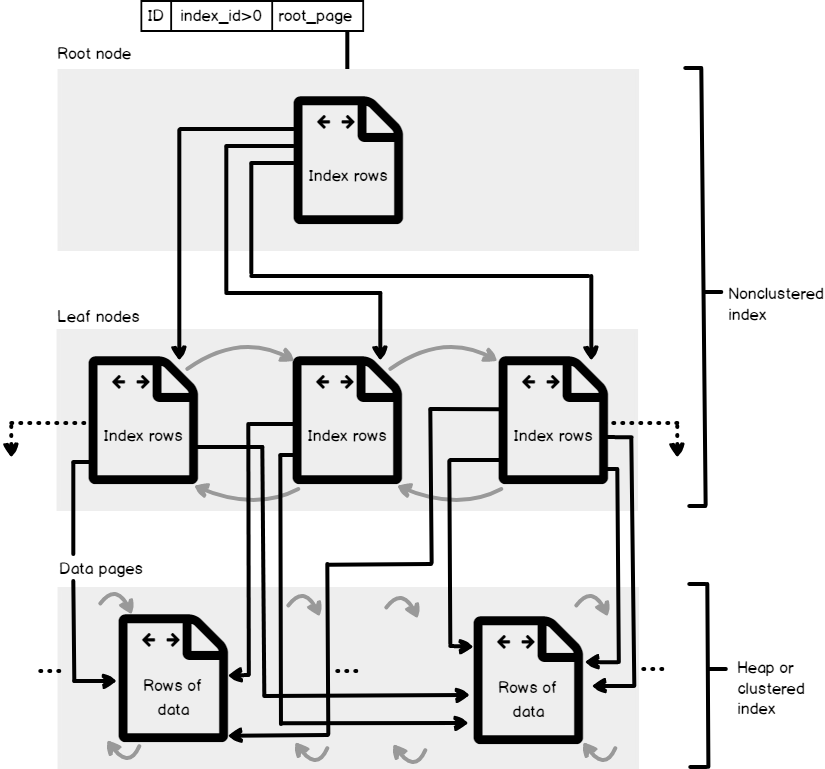
The below figure, from Microsoft Books Online, shows the structure of a Non-clustered index that is built over a Clustered or heap table as described previously. SQL Server allows us to create multiple Non-clustered indexes, up to 999 Non-clustered indexes, on each table, with index IDs values assigned to each index starting from 2 for each partition used by the index, as you can find in the sys.partitions table. Depending on the data type of the columns participating in Non-clustered index key, a SQL Server Non-clustered index will have one or more allocation units that are used to store and manage the index data. Minimally, each Non-clustered index will have the IN_ROW_DATA allocation unit to store the index data. Other special types of allocation units can be also used to store the Non-clustered index data, such as the LOB_DATA allocation unit that is used to store the large object data (LOB) and ROW_OVERFLOW_DATA allocation unit that is used to store the columns with variable length exceeds the 8,060-byte size limit of the row.
Non-clustered index design considerations
The main goal of creating a Non-clustered index is to improve query performance by speeding up the data retrieval process. Although SQL Server allows us to create multiple Non-clustered indexes, up to 999 Non-clustered on each table that can cover our queries, any index added to the table will negatively impact data modification performance on that table. This is due to the fact that, when you modify a key column in the underlying table, the Non-clustered indexes should be adjusted appropriately as well.
When designing a Non-clustered index, you should consider the type of the workload performed on your database or table by compromising between the benefits taken from creating a new index and the data modification overhead that will be caused by this index creation. It is recommended to create a minumu of narrow indexes, with a minimum number of columns participating in the index key, on the heavily updated table. A table that has a large number of rows with a low data modification requirement can heavily benefit from more Non-clustered indexes with composite index keys, that contain more than one column in the index key, that cover all columns in the query to improve the data retrieval performance.
When the index contains all columns required by the query, the SQL Server Query Optimizer will retrieve all column values from the index itself, without the need to perform lookup operations to retrieve the rest of columns in the underlying table or the Clustered index, reducing the costly disk I/O operations. In addition, if the Non-clustered index is built over a Clustered table, the columns that participate in the Clustered index will be appended automatically to the end of each Non-clustered index on that Clustered table, without the need to include these columns to the Non-clustered index key or non-key columns to cover the queries.
Rather than creating a Non-clustered index with a wide key, large columns that are used to cover the query can be included to the Non-clustered index as non-key columns, up to 1023 non-key columns, using the INCLUDE clause of the CREATE INDEX T-SQL statement, that is introduced in SQL Server 2005 version, with a minimum of one key column. The INCLUDE feature extends the functionality of the Non-clustered index, by allowing us to cover more queries by adding the columns as non-key columns to be stored and sorted only in the leaf level of the index, without considering that columns values in the root and intermediate levels of the Non-clustered index. In this case, the SQL Server Query Optimizer will locate all required columns from that index, without the need for any extra lookups. Using the included columns can help to avoid exceeding the Non-clustered size limit of 900 bytes and 16 columns in the index key, as the SQL Server Database Engine will not consider the columns in the Non-clustered index non-key when calculating the size and number of columns of the index key. In addition, SQL Server allows us to include the columns with data types that are not allowed in the index key, such as VARCHAR(MAX), NVARCHAR(MAX), text, ntext and image, as Non-clustered index non-key columns. For more information about including columns to the Non-clustered index key, review SQL Server non-clustered indexes with included columns.
With all these capabilities provided by SQL Server, it is highly recommended to avoid adding too many key or non-key columns to the Non-clustered index that are not required by the queries. This is due to the large disk space that is required to store that index and the large number of pages required to store the index data, because adding too many columns to the index will result with fewer number of rows that can be fit in each data page, increasing the I/O overhead and reducing the caching efficiency. You can also imagine the data modification overhead resulted from such large indexes.
The candidate columns for the Non-clustered index key are the ones that are frequently involved in the GROUP BY clause or in the JOIN or WHERE conditions, that will cover the submitted queries and return exact match values, rather than returning a large set of data. The semi-unique columns that have a large number of distinct values are good candidates also as Non-clustered index key columns. For the column that has few numbers of distinct values, such as the Gender column, you can take benefits from creating a filtered index, as we will see in the next article.
Non-clustered index implementation
At this point, we are familiar with Non-clustered index structure and the guidelines that should be followed when designing a Non-clustered index. Now we will learn how to implement a Non-clustered index.
When you create a UNIQUE constraint, a unique Non-clustered index will be created automatically to enforce that constraint. Non-clustered indexes can be created independently of the constraints using the SQL Server Management Studio New Index dialog box or using the CREATE INDEX T-SQL command. To be able to create a Non-clustered index, you should be a member of the sysadmin fixed server role or the db_ddladmin and db_owner fixed database roles.
Let us create a new heap table to be used in our demo, using the CREATE TABLE T-SQL statement below:
|
1 2 3 4 5 6 7 8 9 10 |
USE SQLShackDemo GO CREATE TABLE NonClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, StudentName NVARCHAR(50) NULL, STDBirthDate DATETIME NULL, STDPhone VARCHAR(20) NULL, STDAddress NVARCHAR(MAX) NULL ) |
Non-clustered indexes can be created using SSMS by expanding the Tables folder under your database. To accomplish this, expand the table on which you plan to create the Non-clustered index on, then right-click on the Indexes node under your table and choose to create the Non-Clustered Index type from the New Index option, as shown below:
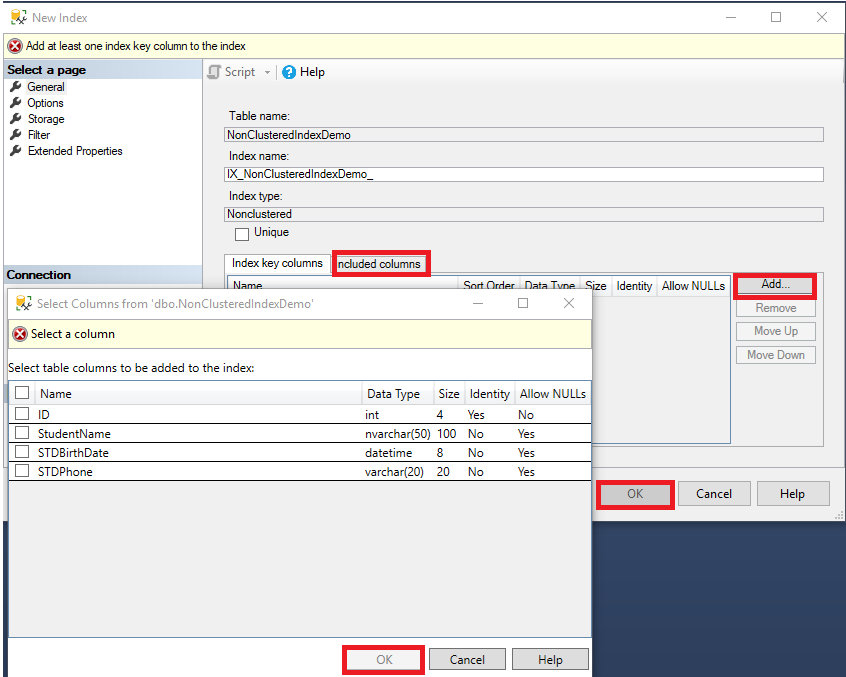
In the opened New Index window, you will see that both the name of the table, on which the index will be created, and the “Non-Clustered” type of the index is filled automatically, with no option to change it. What is required from your side is to provide a suggested name for that index, following a specific naming convention, if the index key values will be unique or not, the column or list of columns that will participate in that index key, and finally the list of columns that will be included to the Non-clustered index as non-key columns, by clicking on the Add button, as shown below:
The Options tab of the New Index dialog box allows you also to set the different index creation options that control the index creation performance, which is described deeply in the previous article, as shown below:
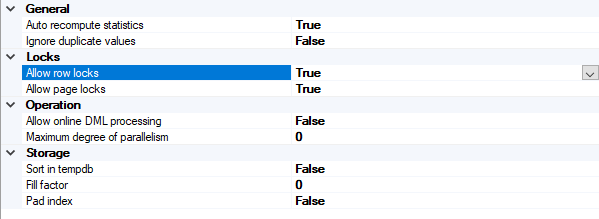
Another way to create the Non-clustered index using SSMS is using the Table Designer. Browse the table on which the index will be created then right-clicking on that table and choose the Design option as shown below:
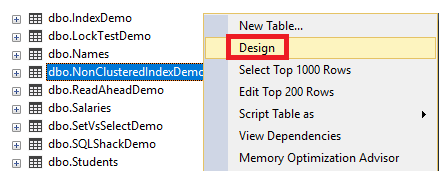
From the opened Table Designer window, right-click anywhere and choose the Indexes/Keys… option to open the index creation dialog box, as shown below:
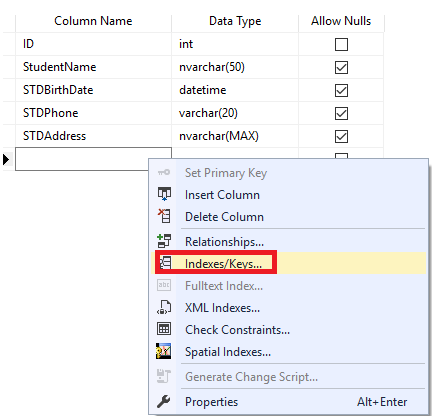
On the opened window, click on the Add bottom to add a new Non-clustered index. Set the Create As Clustered option to “No”, provide a name for the index, if the key values of the Non-clustered index will be unique or not, the column or columns that will participate in the index key, with the required order, as clear below:
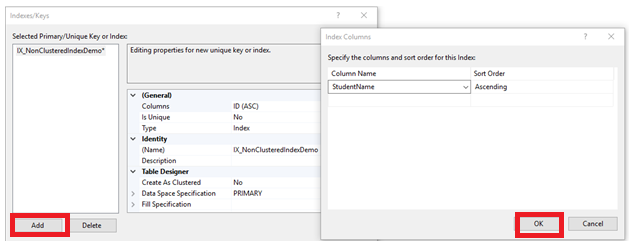
From the same window, expand the Fill Specifications in order to specify the non-key columns that will be included in the Non-clustered index and the different index creation options, as shown below:
A Non-clustered index can be also created using the CREATE NONCLUSTERED INDEX command, by providing the name of the index, the name of the table on which the index will be created, the index key uniqueness and the column or list of columns that will participate in the index key and the non-key columns, optionally, in the INCLUDE clause, as in the command below:
|
1 2 3 |
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexDemo_StudentName ON NonClusteredIndexDemo (StudentName) WITH (ONLINE = ON , FILLFACTOR=90) |
By default, the CREATE INDEX T-SQL statement will create a Non-clustered index if the type of the index is not specified. Consider setting the specified index creation options in the previous CREATE INDEX statement that affect the performance of the index creation process. The ONLINE option allows concurrent users access to the underlying table or the Clustered index data during the Non-clustered index creation process, where the FILLFACTOR option is used to set the percentage of free space that will be left in the leaf level nodes of the Non-clustered index during the index creation, in order to minimize the page split and fragmentation performance issues.
Performance comparison
Before starting the performance comparison examples, we will fill the previously created table with 200K rows, using ApexSQL Generate, as shown below:
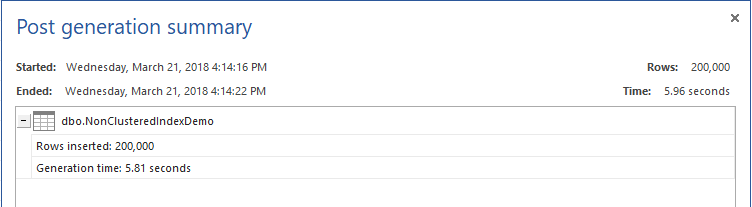
Non-clustered index over heap table
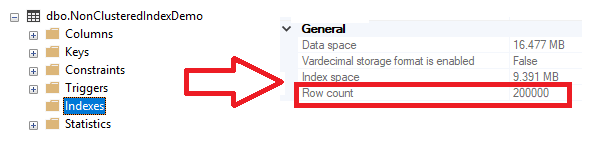
The NonClusteredIndexDemo heap table is ready now, filled with 200K rows and has no index created on that table, assuming that the previous CREATE INDEX statement is not executed, as shown below:
If we try to execute the SELECT statement below, after enabling the IO and TIME statistics and the actual execution plan on the query, as shown below:
|
1 2 3 4 5 |
SET STATISTICS TIME ON SET STATISTICS IO ON SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
The TIME and IO statistics show that 2109 logical read operations are performed, 47ms from the CPU time is consumed in 204ms of time to retrieve the requested data as shown in the snapshot below:

Checking the execution plan generated after executing the query, a Full Scan will be performed on that heap table in order to retrieve the requested data, as below:

If we create a Non-Clustered index over that heap table on the StudentName and STDAddress columns used in the WHERE clause, using the CREATE INDEX T-SQL statement below:
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
The CREATE INDEX statement will fail, as the STDAddress column, with datatype NVARCHAR(MAX), cannot be added to the Non-clustered index as a key column, as shown in the error message below:

If we try again to create a Non-Clustered index over that heap table on the StudentName only, using the CREATE INDEX T-SQL statement below:
|
1 2 3 |
CREATE NONCLUSTERED INDEX IX_NonClusteredIndexDemo_StudentName ON NonClusteredIndexDemo (StudentName) WITH (ONLINE = ON , FILLFACTOR=90) |
And execute the same SELECT statement, that searches based on the StudentName and STDAdderss columns:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
Checking the TIME and IO statistics, you will see that, 2109 logical read operations are performed, 47ms from the CPU time are consumed in 110ms of time to retrieve the requested data, which is somehow similar to the values generated after retrieving the data without an index, but little bit faster, as shown in the snapshot below:

The execution plan generated after executing the query will show that a Full table scan will be also performed on that table, without considering the created Non-clustered index, with a message indicating that there is a missing index that can enhance the performance of the query with about 72%. The script to create that index can be shown by right-clicking on the execution plan and choose the Missing Index Details option, as shown below:
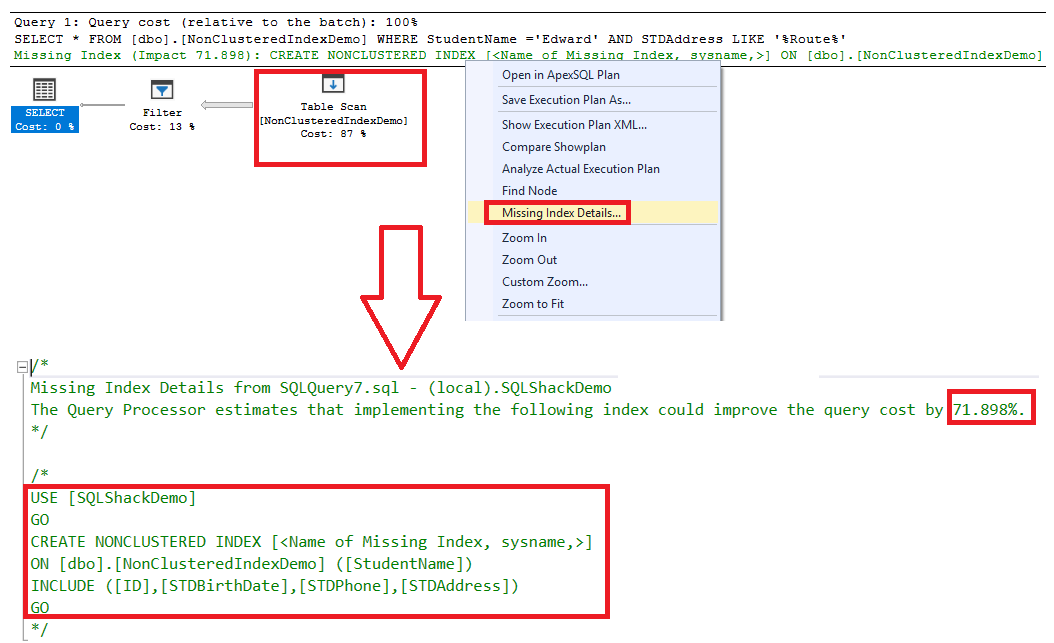
The previous missing index message includes all the columns requested by the query in the suggested index non-key columns. Let us move on gradually in the index creation process, by including only the ID and the STDAddress columns in the index non-key columns, using the CREATE INDEX T-SQL statement below:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
Then execute the same SELECT statement below:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
You will see from the TIME and IO statistics that, only 37 logical read operations are performed, 15ms from the CPU time is consumed in 76ms of time to retrieve the requested data, which is clearly better than the previous result generated by fully scanning the underlying table, as shown in the snapshot below:

The execution plan, generated after executing the query, also shows that an Index Seek operation is performed to retrieve the data directly from the Non-clustered index, without the need to scan the underlying table. The only issue that can be derived from the plan is that RID Lookup heavy and costly operation is performed to retrieve the rest of columns that are not available in the index from the heap table based on the ID of each row, consuming most of the planned weight, as shown below:
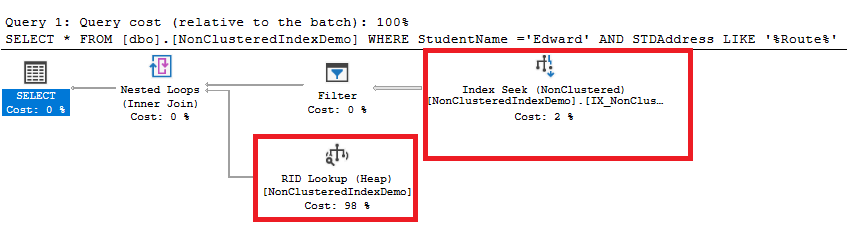
If we create the covering index that is suggested by the SQL Server and include all the query columns, using the CREATE INDEX … WITH DROP_EXISTING option to drop the old one:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
And execute the same SELECT statement:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
The TIME and IO statistics will show that only 20 logical read operations are performed, 0ms from the CPU time is consumed in 65ms of time to retrieve the requested data, which is clearly better than using a Non-clustered index that does not cover all requested columns, as shown in the snapshot below:

And the execution plan generated after executing the query shows that an Index Seek operation will be performed to retrieve the data from the Non-clustered index directly, without the need to visit the underlying heap table, as shown below

Non-clustered index over clustered table
In the previous scenario, we discussed building a Non-clustered index over a heap table. Now we will see how the query will behave when creating Non-clustered index over a Clustered table. Let us first drop the existing Non-clustered index before creating a Clustered index, to skip the Non-clustered indexes rebuild during the Clustered index creation process.
|
1 |
DROP INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] |
Now the table has no index. We will create a new Clustered index on the ID column to covert that table to a Clustered table that is sorted based on the ID column, using the CREATE INDEX statement below:
|
1 2 |
CREATE UNIQUE CLUSTERED INDEX IX_NonClusteredIndexDemo_ID ON NonClusteredIndexDemo(ID) WITH (ONLINE=ON, FILLFACTOR=90) |
If we execute the same SELECT statement that searches based on the StudentName and STDAddress columns values:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
You will see from the Time and IO statistics that, the query will run faster than reading from the heap table, as the data pages are linked and sorted now. Where 2330 logical read operations are performed, 47ms from the CPU time is consumed in 106ms of time to retrieve the requested data, as shown below:

The execution plan generated after executing the query shows that the SQL Server scans the Clustered index, which is a sorted copy of the table, to retrieve the data. You can see that SQL Server scans the whole table records, 200K rows, to get the requested data, but faster than the table scan as it is sorted, as shown below:
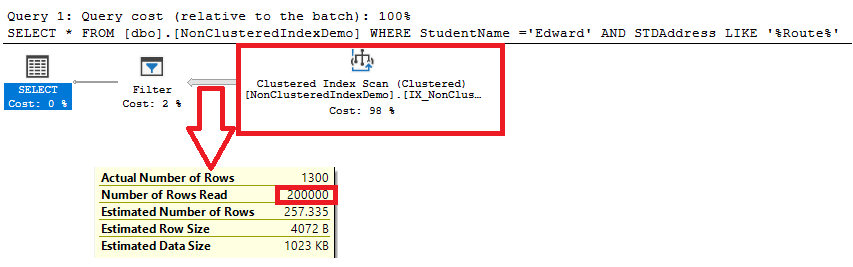
If we create a Non-clustered index on the StudentName column that partially covers the ID and STDAddress columns of the query, using the CREATE INDEX T-SQL statement below:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDAddress]) WITH (ONLINE=ON, FILLFACTOR=90) GO |
Then execute the previous SELECT statement below:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
The Time and IO statistics will show that only 84 logical read operations are performed, 15ms from the CPU time is consumed in 68ms of time to retrieve the requested data, which is clearly faster than using the Clustered index only, as shown below:

The generated execution plan also shows that an Index Seek operation will be performed to retrieve the data directly from the index, without the need to scan the Clustered index. As the Non-clustered index is not fully covering the query, the Key Lookup heavy and costly operation is performed to retrieve the rest of columns that are not available in the index from the Clustered index, based on the Clustered key of each row, consuming most of the planned weight, as shown below:
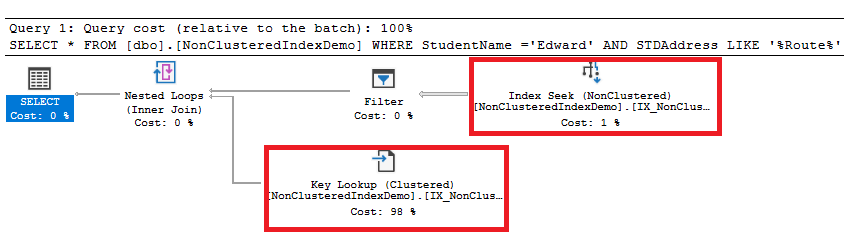
Creating a new Non-clustered index that covers all the query columns, using the CREATE INDEX … WITH DROP_EXISTING option to drop the old one:
|
1 2 3 4 5 6 7 |
USE [SQLShackDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH (DROP_EXISTING=ON, ONLINE=ON, FILLFACTOR=90) GO |
Then execute the previous SELECT statement:
|
1 2 |
SELECT * FROM [dbo].[NonClusteredIndexDemo] WHERE StudentName ='Edward' AND STDAddress LIKE '%Route%' |
You can see from the TIME and IO statistics that, only 18 logical read operations are performed, 0ms from the CPU time is consumed in 59ms of time to retrieve the requested data, that is obviously faster than using a Non-clustered index that does not cover all requested columns, as shown in the snapshot below:

From the generated execution plan, you can see that an Index Seek operation will be performed to retrieve all the data from the created Non-clustered index, without visiting the Clustered index, as shown below:

Data modification overhead
The Non-clustered is very useful in speeding up the data retrieval process, as we saw from the previous examples. On the other hand, each created index will add extra overhead to data modification operations. Let us check the index overhead on the data modification operations. Assume that we drop our testing table and create an empty heap copy of that table, using the script below:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
USE SQLShackDemo GO DROP TABLE NonClusteredIndexDemo GO CREATE TABLE NonClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, StudentName NVARCHAR(50) NULL, STDBirthDate DATETIME NULL, STDPhone VARCHAR(20) NULL, STDAddress NVARCHAR(MAX) NULL ) |
Then we will fill the heap table with 200K rows, using ApexSQL Generate. You will see that it will take 4.53 seconds to fill the table, as shown below:
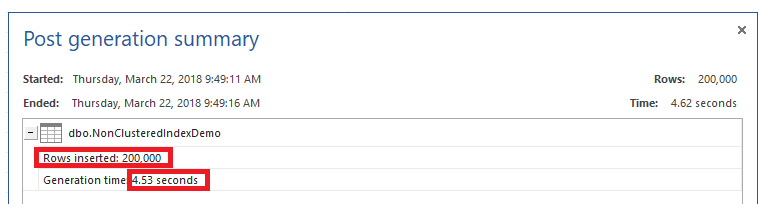
If you truncate the table and create a new Non-clustered index on that table, using the T-SQL script below:
|
1 2 3 4 5 6 7 |
TRUNCATE TABLE [NonClusteredIndexDemo] GO CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
And try now to fill the table with 200K rows again, using ApexSQL Generate. You will see that it will take 5.01 seconds to fill the table, with about 0.48 seconds overhead due to writing to both the underlying table and the Non-clustered index, as shown below:
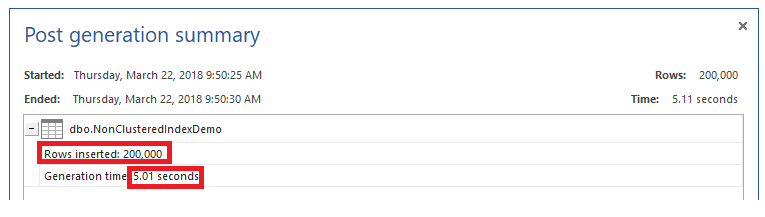
You can imagine the extra data modification overhead that will be caused by adding other indexes to that table. Let us take another example. We will drop the previously created Non-clustered index and try to update the addresses of specific students, using the T-SQL script below:
|
1 2 3 4 5 |
DROP INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] UPDATE [dbo].[NonClusteredIndexDemo] SET STDAddress='335 Delaware Avenue' WHERE STDAddress LIKE '%Delaware%' |
You will see from the IO and Time statistics show that the SQL Server Engine will perform 2117 logical reads, consume 375ms of the CPU time within 374ms, to update the table that has no index, as shown below:

If we create the covering Non-clustered index again using the CREATE INDEX T-SQL statement below:
|
1 2 3 4 5 |
CREATE NONCLUSTERED INDEX [IX_NonClusteredIndexDemo_StudentName] ON [dbo].[NonClusteredIndexDemo] ([StudentName]) INCLUDE ([ID],[STDBirthDate],[STDPhone],[STDAddress]) WITH ( ONLINE=ON, FILLFACTOR=90) GO |
Then execute a new UPDATE statement:
|
1 2 |
UPDATE [dbo].[NonClusteredIndexDemo] SET STDAddress='336 Delaware Avenue' WHERE STDAddress LIKE '%Delaware%' |
The IO and Time statistics will show that, the SQL Server Engine will perform 7876 logical reads on the main table and the Non-clustered index pages “Worktable”, consume 391ms of the CPU time within 398ms, to update the table that has no index, with all counters larger than updating the table that has no index, as shown below:

The previous statistics show the overhead caused by performing an INSERT and an UPDATE operation one time. You can imagine the overhead caused on a table with heavy INSERT, UPDATE and DELETE requirements, with multiple numbers of Non-clustered indexes. But again, you need to compromise between data retrieval and the data modification operations that are performed on your table, before planning to create a new index on that table.
In this article, we tried to cover all aspects of the Non-Clustered index concept, theoretically and practically. In the next article, we will go through the other types of the SQL Server Indexes. Stay tuned!
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021