
Now that we understand what Clustered Index Scan and Clustered Index Seek are, how they occur, and how to eliminate table scans in my previous article SQL Server Query Execution Plans for beginners – Clustered Index Operators, the next topic would be looking at Non-Clustered Indexes
We can start off with the Non-Clustered Index Scan …
Non-Clustered Index Scan
- When
- A Non-Clustered Index Scan occurs when columns are part of the non-clustered index and the query goes about accessing a large amount of data across this particular index
- Good or Bad
- Bad unless large data with most columns and rows retrieved
- Action Item
- The action item here is pretty clear. Just look at redefining or refining your Non-Clustered Index. By considering the columns configured in that NON-Clustered index
After refining your Non-Clustered Index, you might get into a Non-Clustered Index Seek.
Non-Clustered Index Seek
- When
- Non-Clustered Index Seek occurs when Columns part of non-clustered index accessed in query and rows located in the B+ tree
- Good or Bad
- It is good and ideal to have a Non-Clustered Index Seek
- Action Item
- Evaluate other operators
Let us take a quick example to see how this can be seen and some of the options and methods to go ahead and mitigate.
We are going to use the same table that we created in my previous article.
Then, you can notice some interesting options using that data which will make it very clear on how to get the most performance using non-clustered indexes.
First, let us create one non-clustered index based on [OrderQty] and [ProductID] columns.
|
1 2 3 4 |
CREATE NONCLUSTERED INDEX [IX_MySalesOrderDetail_OrderQty_ProductID] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] ([OrderQty],[ProductID]) GO |
Now, we can execute the following script and enable include actual execution plan.
|
1 2 3 4 |
SET STATISTICS IO ON GO SELECT SalesOrderID, SalesOrderDetailID, ProductID, OrderQty FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] |
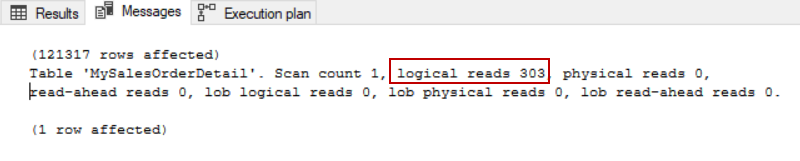
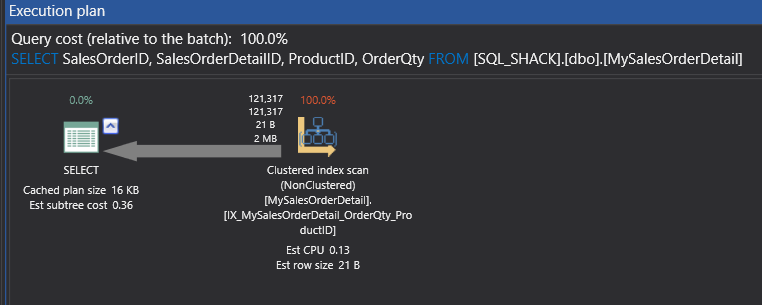
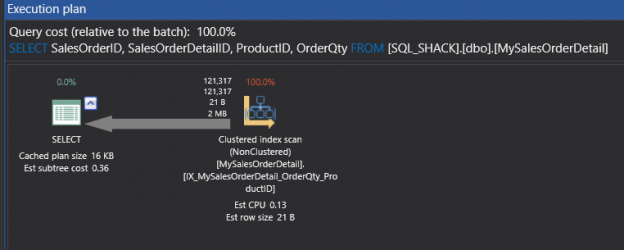
This will show us the result of 121,317 rows and 303 logical reads. Hence, you can see that I was doing a select some columns from an actual table where the query could get satisfied from the non-clustered key and hence, you got a scan of non-cluster.
Interestingly, if I go ahead and add a where condition on the [ProductID] column:
|
1 2 3 4 5 6 |
SET STATISTICS IO ON GO SELECT SalesOrderID, SalesOrderDetailID, ProductID, OrderQty FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE ProductID = 799 GO |

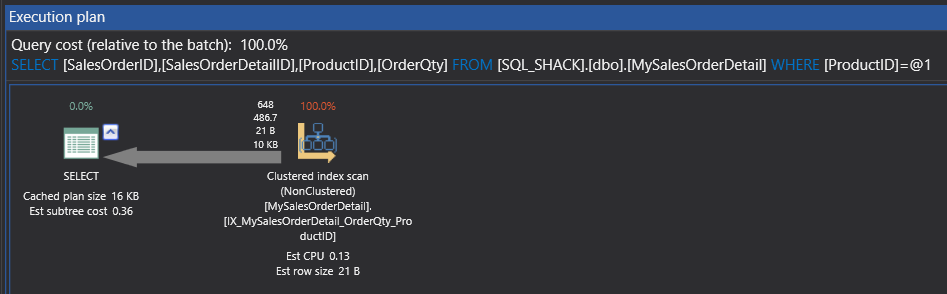
It is obvious that we have got the result of 648 rows which is less than the previous result but SQL Server has done the same 303 logical reads and we still did not use non-clustered index seek. So, how can I change and refine to redefine the non-clustered index so that it can start getting better results and a better plan?
One of the methods that can be used here is to change the where conditions to add additional information so that SQL Server can use the non-clustered index effectively.
Remember, we had the index created on order quantity and product ID.
I will add the order quantity condition as I know that the order quantity is always greater than zero. and in my previous example, I had got 648 rows.
|
1 2 3 4 5 6 |
SET STATISTICS IO ON GO SELECT SalesOrderID, SalesOrderDetailID, ProductID, OrderQty FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE ProductID = 799 AND OrderQty > 0 GO |

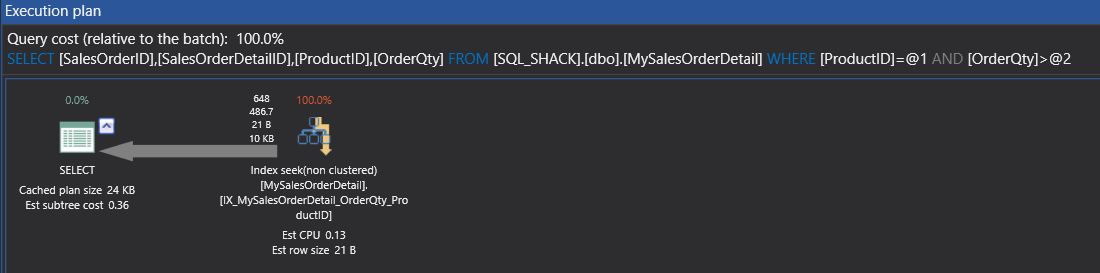
On execution of this particular query gives me the same 648 rows.
Although the messages show me a logical read of 303 yet, you can see the index that is used, the physical operation that is used is an index seek.
Another method to play over here is to redefine the particular index which for that query by reordering the columns in the index:
|
1 2 3 4 5 6 |
drop INDEX [IX_MySalesOrderDetail_OrderQty_ProductID] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] CREATE NONCLUSTERED INDEX [IX_MySalesOrderDetail_ProductID_OrderQty] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] ([ProductID],[OrderQty]) GO |
Then we can execute our original query with only the condition of [ProductID] column:
|
1 2 3 4 5 6 |
SET STATISTICS IO ON GO SELECT SalesOrderID, SalesOrderDetailID, ProductID, OrderQty FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE ProductID = 799 GO |

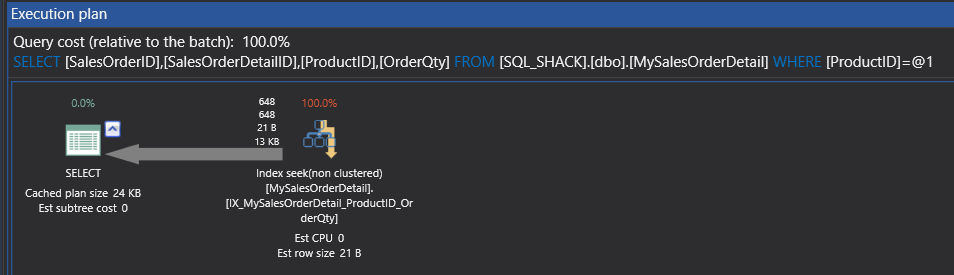
Now, we have the most optimal plan with logical reads of 5 only.
Hence, you could see when we went ahead creating a non-clustered index and got a non-clustered scan, we used two methods, one of them is redefining the where clauses to get actually an index seek, yet you could see that IO is never reduced.
The other way that we have used is to actually define a right index of non-clustered in the right order. Here, you can see the IO is reduced considerably.
This is how we have converted a non-clustered index scan to the most optimal non-clustered index seek.
Let us now look at the next operator, lookups …
Lookups
- When
- Query Optimizer uses the non-clustered index to search few column data and base table for other columns data
- Good or Bad
- Bad
- Action Item
- The best way to mitigate them is to have either a covering index or use an index with included columns
Here is a typical example of how lookups would happen using the same sample table:
|
1 2 3 4 5 6 7 8 |
SET STATISTICS IO ON GO SELECT SalesOrderID, SalesOrderDetailID, ProductID, OrderQty, SpecialOfferID FROM [SQL_SHACK].[dbo].[MySalesOrderDetail] WHERE ProductID = 789 GO |


This produced 364 rows with huge 1854 logical reads
The execution plan has used a where condition which was based on the [ProductID] column using an index seek non-clustered for the operation and it was seeking another extract column so it had to do what we call as a key lookup.
The output list shows this [SpecialOfferID] column which is something that the key lookup was sending out.
So, this particular column is needed to satisfy the select statement.
The first option here, I’m going to create an index, a non-clustered index which is based on covering index.
|
1 2 3 4 5 6 |
DROP INDEX [IX_MySalesOrderDetail_ProductID_OrderQty] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] CREATE NONCLUSTERED INDEX [IX_MySalesOrderDetail_ProductID_OrderQty_SpecialOfferID] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] ([ProductID],[OrderQty],[SpecialOfferID]) GO |
And execute the same query again:

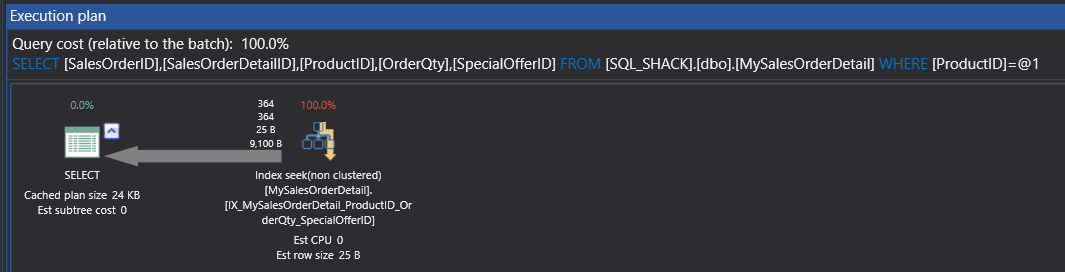
Now, we have obtained the same result set of 364 rows with logical reads of 6 only and also we have eliminated the key lookup operator.
Second, is to use all the columns required by the select statement in the included columns of the non-clustered index, as below:
|
1 2 3 4 5 6 7 |
DROP INDEX [IX_MySalesOrderDetail_ProductID_OrderQty_SpecialOfferID] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] CREATE NONCLUSTERED INDEX [IX_MySalesOrderDetail_ProductID_OrderQty_SpecialOfferID] ON [SQL_SHACK].[dbo].[MySalesOrderDetail] ([ProductID]) INCLUDE ([OrderQty],[SpecialOfferID]) GO |
And execute the same query again:

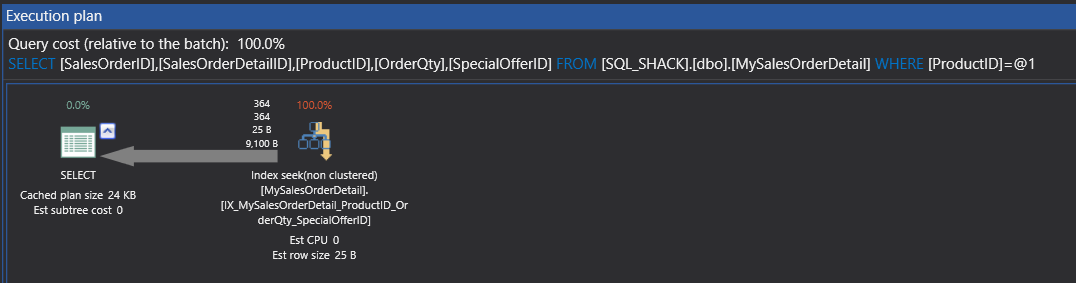
Now, we can see that it has done an Index Seek Non-Clustered and the bookmark lookup has been eliminated.
Summary
Non-clustered indexes are very important part of performance optimization life cycle. Every DBA should know what exactly can be done with them. I tried here to touch the basics of the non-clustered indexes operators and I hope you found this article helpful.
Previous articles in this series:
- SQL Server Query Execution Plans for beginners – Types and Options
- SQL Server Query Execution Plans for beginners – Clustered Index Operators
References
- Nonclustered Index Scan Showplan Operator
- Nonclustered Index Seek Showplan Operator
- Key Lookup Showplan Operator

Living in Egypt, have worked as Microsoft Senior SQL Server Database Administrator for more than 4 years.
As a DBA, I design, install, maintain and upgrade all databases (production and non-production environments), I have practical knowledge of T-SQL performance, HW performance issues, SQL Server replication, clustering solutions, and database designs for different kinds of systems. I worked on all SQL Server versions (2008, 2008R2, 2012, 2014 and 2016).
I love my job as the database is the most valuable thing in every place in the world now. That's why I won't stop learning. In my spare time, I like to read, speak, learn new things and write blogs and articles.
View all posts by Ayman Elnory
- SQL Server Query Execution Plans for beginners – NON-Clustered Index Operators - April 24, 2018
- SQL Server Query Execution Plans for beginners– Clustered Index Operators - March 5, 2018
- A walk through the SQL Server 2016 full database backup - February 12, 2018