
In the previous articles of this series (see the full article TOC at bottom), we discussed the internal structure of SQL Server tables and indexes, the guidelines that you can follow in order to design a proper index, the list of operations that can be performed on the SQL Server indexes, how to design effective Clustered and Non-clustered indexes, the different types of SQL Server indexes (above and beyond Clustered and Non-clustered indexes classification), how to tune the performance of the inefficient queries using different types of SQL Server Indexes and finally, how to gather statistical information about index structure and the index usage. In this article, the last article in this series, we will discuss how to benefit from the previously gathered index information in maintaining SQL Server indexes.
One of the most important administration tasks that every database administrator should care about is maintaining database indexes. As we mentioned previously, you cannot create an index to enhance the performance of your queries and leave it forever without continuously monitoring its usage statistics. The index that fits you now, may degrade the performance of your query in the future, due to the different changes performed on your database data or schema. We discussed, in the previous articles, about gathering different types of information and statistics regarding indexes. Now we will use this gathered information to perform suitable maintenance tasks on that index.
Missing and duplicate indexes
The first thing to look at, in the context of index maintenance, is identifying and creating missing indexes. These are indexes that have been recommended and suggested by the SQL Server Engine to enhance the performance of your queries.
Review the Tracing and tuning queries using SQL Server indexes article to dig deeply into the missing indexes identification method.
Another area to concentrate on is the duplication of indexes. It is wort spending time in reviewing the columns that are participating in each index in your database, that is returned by querying the sys.index_columns and sys.indexes system objects described in the previous article, and identify the duplicate indexes that are created on the exact same columns then removing the same. Recall the overhead of indexes on the data modification and index maintaining operations and that it can lead to degraded performance.
Heap tables
Heap tables are tables that contain no Clustered index. This means that the data rows, in the heap table, are not stored in any particular order within each data page. In addition, there is no particular order to control the data pages sequence, that is not linked in a linked list. As a result, retrieving from, inserting into or modifying data in the heap table will be very slow and can be fragmented more easily.
For more information about the heap table, review SQL Server table structure overview.
You need first to identify the heap tables in your database and concentrate only on the large tables, as the SQL Server Query Optimizer will not benefit from the indexes created on smaller tables. Heap tables can be detected by querying the sys.indexes system object, in conjunction with other system catalog views, to retrieve meaningful information, as shown in the T-SQL script below:
|
1 2 3 4 5 6 7 8 |
SELECT OBJECT_NAME(IDX.object_id) Table_Name , IDX.name Index_name , PAR.rows NumOfRows , IDX.type_desc TypeOfIndex FROM sys.partitions PAR INNER JOIN sys.indexes IDX ON PAR.object_id = IDX.object_id AND PAR.index_id = IDX.index_id AND IDX.type = 0 INNER JOIN sys.tables TBL ON TBL.object_id = IDX.object_id and TBL.type ='U' |
From the previous query result, identify the large heap tables and creating a Clustered index on these tables to enhance the performance of the queries reading from these tables. The result in our case will be as shown below:

Unused indexes
In the previous article, we mentioned two ways to gather usage information about database indexes, the first one using the sys.dm_db_index_usage_stats DMV and the second way using the Index Usage Statistics standard report. Unused indexes that are not used in any seek or scan operations, or are relatively small, or are updated heavily should be removed from your table, as it will degrade data modification and index maintenance operations performance, instead of enhancing the performance of your queries.
The best way to deal with the unused indexes is dropping them. But before doing that, make sure that …
- this index is not a newly created index,
- that the system will use in the near future,
- and that the SQL Server has not been restarted recently
The reason for this is that the results of these two methods will be refreshed each time the SQL Server restarted and may provide incomplete information to base index removal on. In the case of an inefficiently used Clustered index, make sure to replace it with another one and not keeping the table as heap.
Fix index fragmentation
In SQL Server, most tables are transactional tables, that are not static but are changing over time. Index fragmentation occurs when the logical ordering of the index pages, based on the key value, does not match the physical ordering inside the data file. We discussed previously that, due to frequent data insertion and modification operations, the index pages will be split and fragmented, when the page is full, or the current free space is not fit the newly inserted or updated value, increasing the amount of disk I/O operations required to read the requested data.
On the other hand, setting the Fill Factor and pad_index index creation options with the proper values will help in reducing the index fragmentation and page split issues. Different ways to gather fragmentation information about the database indexes, such as querying the sys.dm_db_index_physical_stats dynamic management function and Index Physical Statistics standard report, are mentioned in detail in the previous article.
Index defragmentation makes sure that the index pages are contiguous, providing faster and more efficient way to access the data, instead of reading from spread out pages across multiple separate pages.
SQL Server provides us with different ways to fix the index fragmentation problem. The first method is using the DBCC INDEXDEFRAG command, that defragments the leaf level of an index, serially one index at a time using a single thread, in a way that allows the physical order of the pages to match the left-to-right logical order of the leaf nodes, improving scanning performance of the index. The DBCC INDEXDEFRAG command is an online operation that holds no long-term locks on the underlying database object without affecting any running queries or updates. The time required to defragment an index depends mainly on the level of fragmentation, where an index with a small fragmentation percentage can be defragmented faster than a new index can be built. On the other hand, an index that is very fragmented might take considerably longer to defragment than to rebuild. If the DBCC INDEXDEFRAG command is stopped at any time, all completed work will be retained.
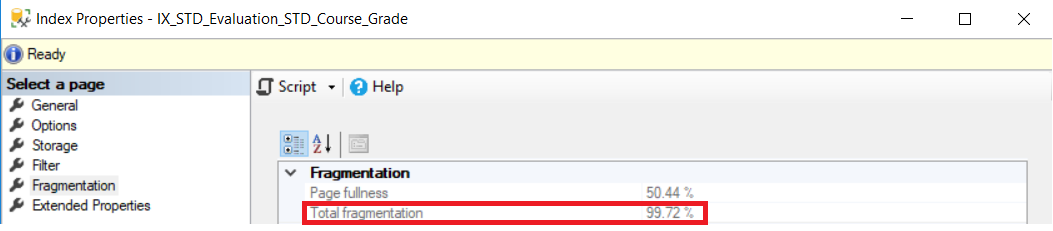
Assume that we have the below index with fragmentation percentage equal to 99.72%, as shown in the snapshot below, taken from the index properties:
The DBCC INDEXDEFRAG command can be used to defragment all indexes in a specific database, all indexes in a specific table or a specific index only depend on the provided parameters. The below script is used to defragment the previous index that has very high fragmentation percentage:
|
1 2 |
DBCC INDEXDEFRAG (IndexDemoDB, 'STD_Evaluation', IX_STD_Evaluation_STD_Course_Grade); GO |
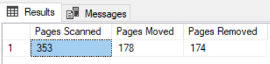
The result returned from the command, shows the number of pages that are scanned, moved and removed during the defragmentation process, as shown below:
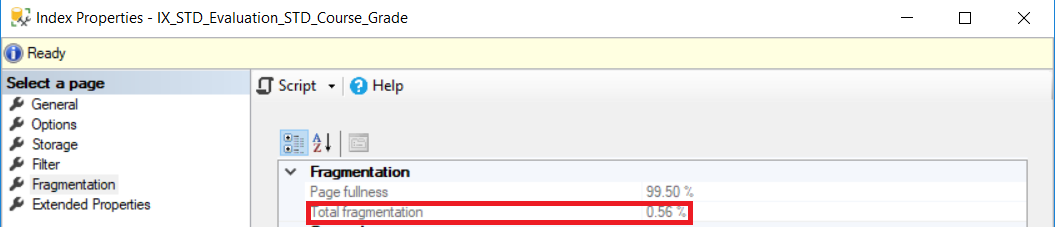
Checking the fragmentation percentage after running the DBCC INDEXDEFRAG command, the fragmentation percentage become less than 1% as shown below:
Index fragmentation can be also resolved by rebuilding and reorganizing the SQL Server indexes regularly. The Index Rebuild operation removes fragmentation by dropping the index and creating it again, defragmenting all index levels, compacting the index pages using the Fill Factor values specified in rebuild command, or using the existing value if not specified and updating the index statistics using FULLSCAN of all the data. Recall that rebuilding a disabled index brings it back to life. The index rebuild operation can be performed online, without locking other queries when using the SQL Server Enterprise edition, or offline by holding locks on the database objects during the rebuild operation. In addition, the index rebuild operation can use parallelism when using Enterprise edition. On the other hand, if the rebuild operation failed, a heavy rollback operation will be performed. The index can be rebuilt using ALTER INDEX REBUILD T-SQL command.
The Index Reorganize operation physically reorders leaf level pages of the index to match the logical order of the leaf nodes. The index reorganize operation will be always performed online. Microsoft recommends fixing index fragmentation issues by rebuilding the index if the fragmentation percentage of the index exceeds 30%, where it recommends fixing the index fragmentation issue by reorganizing the index if the index fragmentation percentage exceeds 5% and less than 30%. The index reorganize operation will use single thread only, regardless of the SQL Server Edition used. On the other hand, if the reorganize operation fails, it will stop where it left off, without rolling back the reorganize operation. The index can be reorganized using ALTER INDEX REORGANIZE T-SQL command.
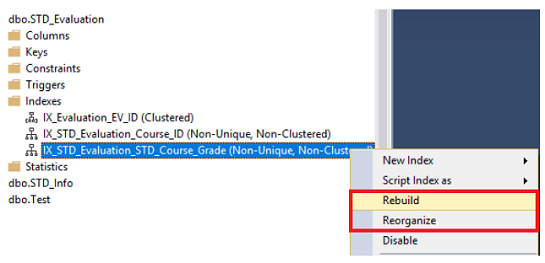
The index can be rebuilt or reorganized using SQL Server Management Studio by browsing the Indexes node under your table, choose the index that you manage to defragment, right-clicking on that index and choose the Rebuild or Reorganize option, based on the fragmentation percentage of that index, as shown below:
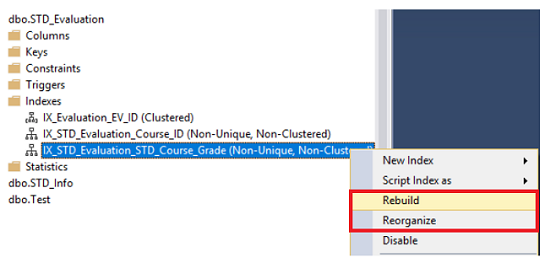
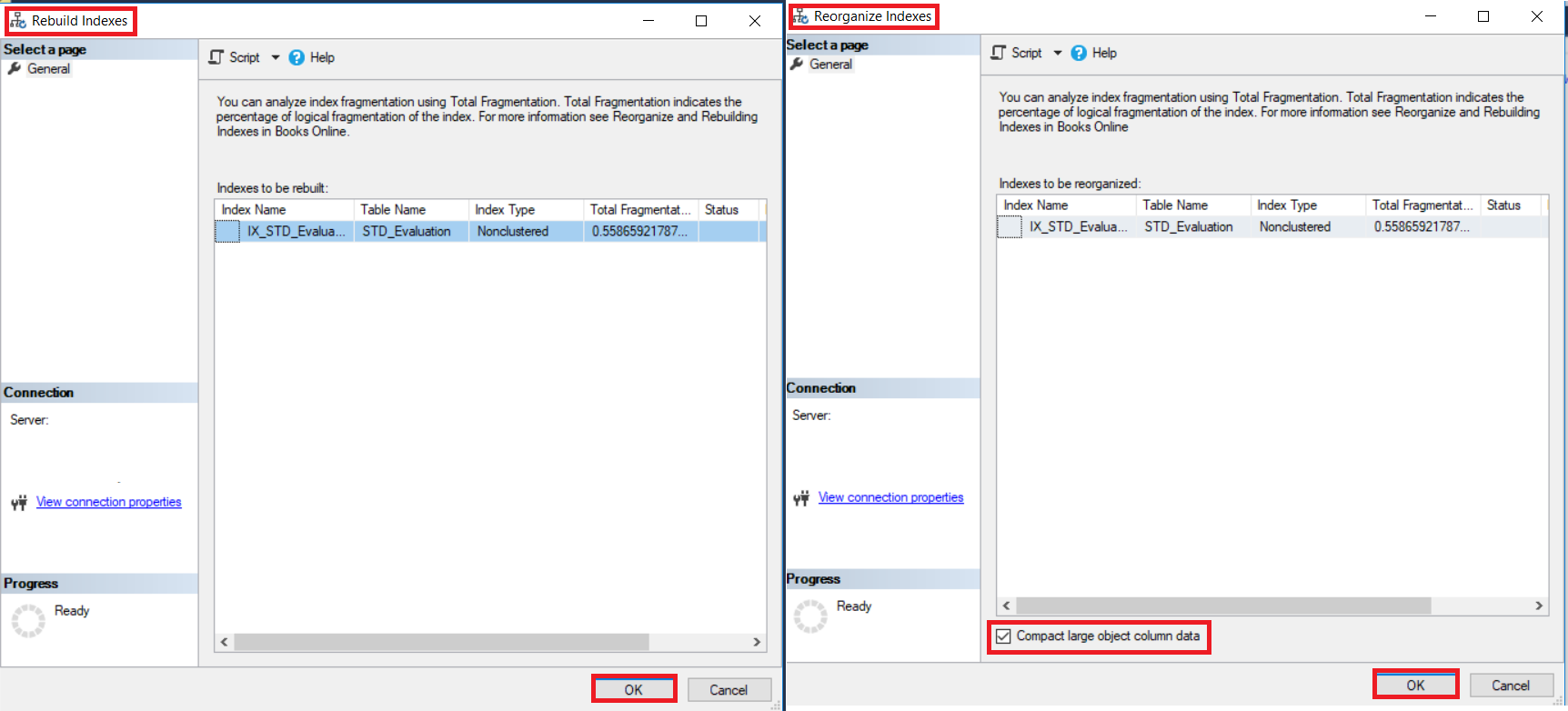
In the displayed Rebuild or Reorganize windows, click on the OK button to defragment the selected index, with the ability to compact all column data that contains LOB data while reorganizing the index, with the fragmentation level of each index, as shown in the snapshot below:
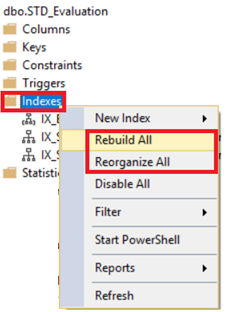
SQL Server allows you to rebuild or reorganize all table indexes, by right-clicking on the Indexes node under your table and choose to Rebuild All or Reorganize All option, as shown below:
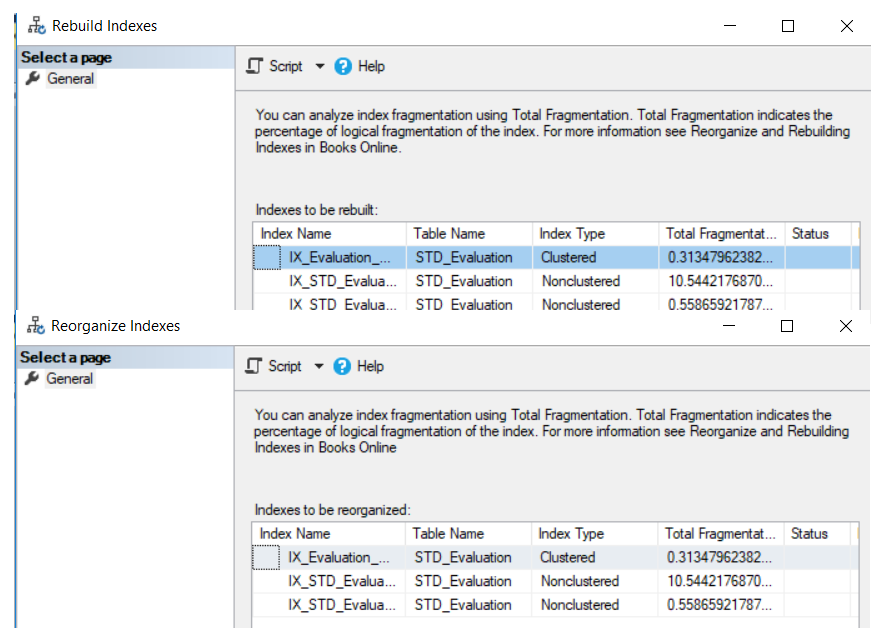
The displayed rebuild or reorganize window will list all the table indexes that will be defragmented using that operation, with the fragmentation level of each index, as shown in the snapshots below:
The same operations can be also performed using T-SQL commands. You can rebuild the previous index, using the ALTER INDEX REBUILD T-SQL command, with the ability to set the different index creation options, such as the FILL FACTOR, ONLINE or PAD_INDEX, as shown in below:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REBUILD PARTITION = ALL WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
Also, the index can be reorganized, using the ALTER INDEX REORGANIZE T-SQL command below:
|
1 2 3 4 |
USE [IndexDemoDB] GO ALTER INDEX [IX_STD_Evaluation_STD_Course_Grade] ON [dbo].[STD_Evaluation] REORGANIZE WITH ( LOB_COMPACTION = ON ) GO |
You can also organize all the table indexes, by providing the ALTER INDEX REORGANIZE T-SQL statement with ALL option, instead of the index name, as in the T-SQL statement below:
|
1 2 3 |
ALTER INDEX ALL ON [dbo].[STD_Evaluation] REORGANIZE ; GO |
And rebuild all the table indexes, by providing the ALTER INDEX REBUILD T-SQL statement with ALL option, instead of the index name, as in the T-SQL statement below:
|
1 2 3 |
ALTER INDEX ALL ON [dbo].[STD_Evaluation] REBUILD WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) GO |
In SQL Server 2014, new functionality was introduced that allows us to control how the locking mechanism, that is required by the online index rebuild operation, is handled. This mechanism is called Managed Lock Priority, that benefits from the newly defined Low-Priority queue that contains the processes with priorities lower than the ones waiting in the wait queue, giving the database administrator the ability to manage the waiting priorities.
For more information, check out How to control online Index Rebuild Locking using SQL Server 2014 Managed Lock Priority.
Maintain the index statistics
Index statistics are used by the SQL Server Query Optimizer to determine if the index will be used in query execution. Outdated statistics will lead the Query Optimizer to select the wrong index while executing the query. From the SQL Server operating system aspect, when selecting an index, the SQL Server Query Optimizer will ignore the index if it has a high fragmentation percentage (as searching in it will cost more than the table scan), the index values are not very unique, the index statistics are outdated or the columns order in the query does not match the index key columns order.
Index statistics can be updated automatically by the SQL Server Engine, or manually using the sp_updatestats stored procedure, that runs UPDATE STATISTICS against all user-defined and internal tables in the current database, or using the UPDATE STATISTICS T-SQL command, that can be used to update the statistics of all the table indexes or update the statistics of a specific index in the table.
The below T-SQL statement is used to update the statistics of all indexes under the STD_Evaluation table:
|
1 2 |
UPDATE STATISTICS STD_Evaluation; GO |
Where the below T-SQL statement will update the statistics of only one index, under that table:
|
1 2 |
UPDATE STATISTICS STD_Evaluation IX_STD_Evaluation_STD_Course_Grade; GO |
You can also update the statistics of all the table indexes, by specifying the sampling rows percentage, as shown in the T-SQL statement below:
|
1 2 |
UPDATE STATISTICS STD_Evaluation WITH SAMPLE 50 PERCENT; |
Or forced it to scan all the table rows during the table’s statistics update, using the FULLSCAN option, shown below:
|
1 2 3 |
UPDATE STATISTICS STD_Evaluation WITH FULLSCAN, NORECOMPUTE; GO |
Automating SQL server index maintenance
Until this point, we are familiar with how to make a decision if we will rebuild or reorganize a SQL Server index, based on the fragmentation percentage, and how to defragment a specific index or all table indexes using the rebuild or reorganize methods. We also reviewed the importance of performing the different types of index maintenance tasks regularly, in order to allow the SQL Server Query Optimizer to consider these indexes to enhance the performance of the different queries and minimize the overhead of these indexes on the overall database system.
On the other hand, performing index maintenance tasks manually is not a good practice, as these operations may take a long time that the DBA will not have that patience to wait for, in addition to that the DBA is not always available to remember running these tasks, which may lead to cumulatively high fragmentation percentage.
There are two options to automate the indexes maintenance. The first option is to schedule a customized index maintenance script, to rebuild, reorganize, defrag and update statistics based on the index fragmentation percentage using SQL Server Agent job, that can be your own script based on your system behavior and requirement, or customize my favorite flexible Ola Hallengren’s index maintenance script, that provide you with large number of options that can fit wide range of systems behaviors.
The second option to automate the index maintenance tasks is using the Rebuild Index, Reorganize Index and Update Statistics Maintenance Plans, from the Management nodes, as shown below:
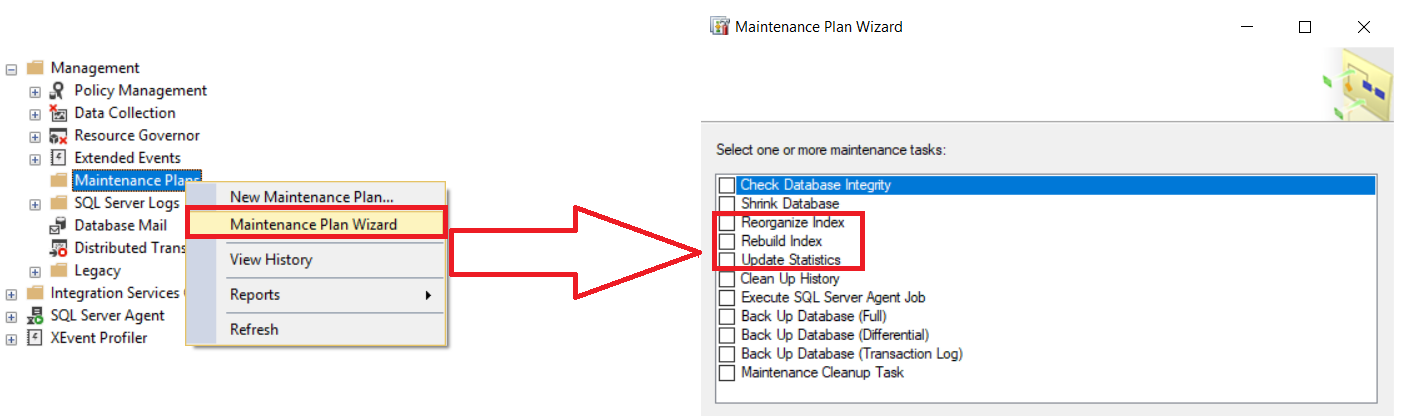
You need to specify the name of the database or databases that you manage to perform the index maintenance task on, with the ability to narrow it to be performed on a specific table or table, and schedule that maintenance to be performed during the non-peak time, based on workload that specifies the maintenance windows available on your company, your database structure, how fast the data is fragmented and the SQL Server Edition. Recall that the downtime required to perform index maintenance tasks can be decreased by using the Enterprise Edition, that allows you to perform the index rebuild operation online and use parallel plans.
Using SQL Server Maintenance Plans to automate the index maintenance tasks is not a preferred option when using SQL Server versions prior to 2016, due to lack of control on these heavy operations. This is because these maintenance tasks will be performed on all table or database indexes regardless of the fragmentation percentage of these indexes. Such operations will require long maintenance window and will intensively consume the server resources when maintaining large databases.
Starting from SQL Server 2016, new options were added to the index maintenance tasks that allow us to perform the Rebuild Index and Reorganize Index tasks, based on the fragmentation percentage of the index, and other useful options to control the index maintenance process.
For more information about this enhancement, check the SQL Server 2016 Maintenance Plan Enhancements.
The following snapshots summarize how we can specify the fragmentation percentage parameters for both the index rebuild and reorganize maintenance plans, and other controlling options, as shown below:
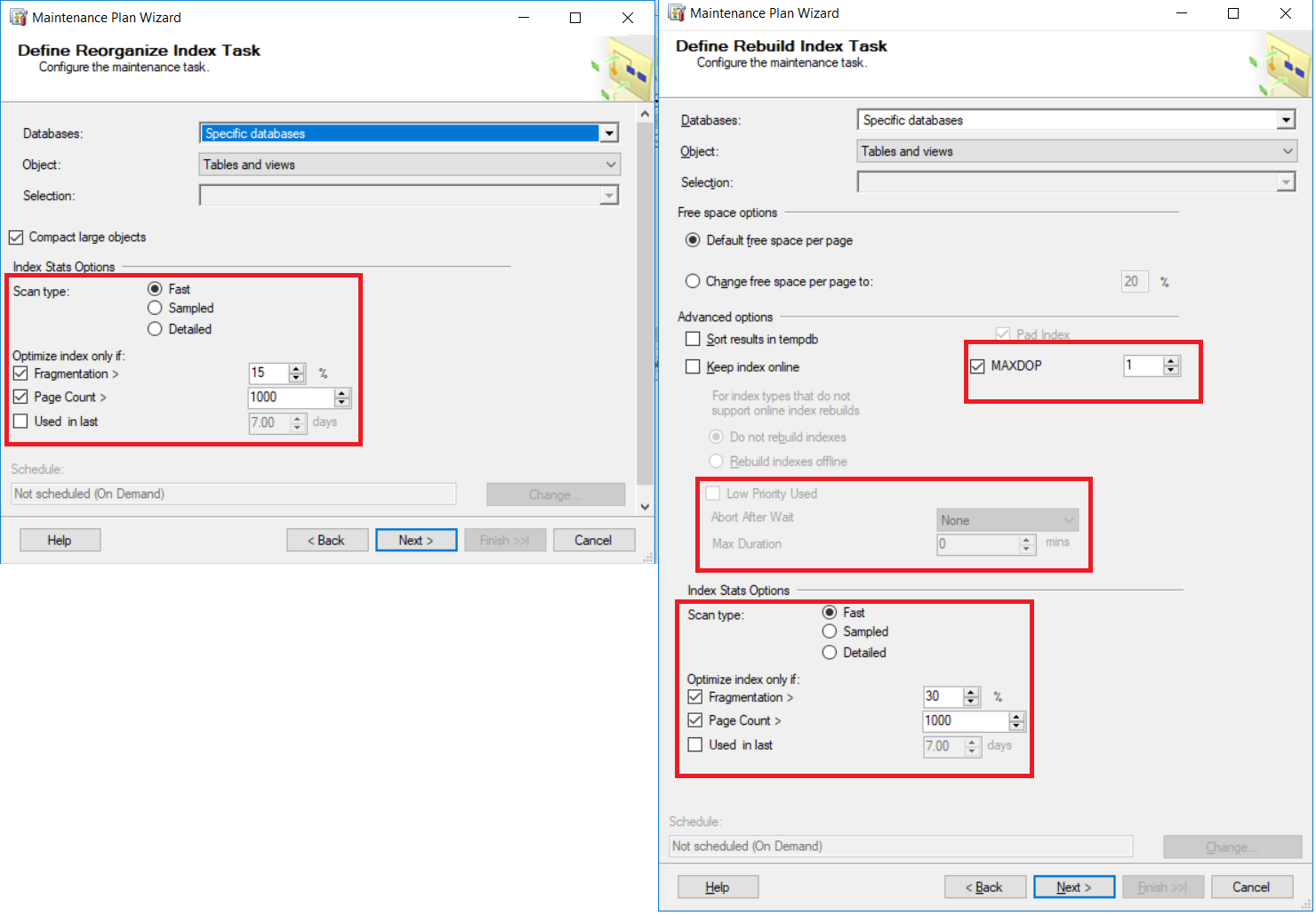
Index maintaining requirements
When you rebuild an index, additional temporary disk space is required during theoperation to store a copy of the old index, rolling back the changes in case of failure, and to isolate the index online rebuild operation from the effects of modifications made by other transactions using row versioning and sorting the index key values. If the SORT_IN_TEMPDB option is enabled, tempdb space, that fits the index size, should be available to sort the index values. This option speeds up the index rebuild process by separating the index transactions from the concurrent user transactions, if the tempdb database is in a separate disk drive. On the other hand, additional permanent disk space is required to store the new structure of the index.
To perform large-scale operations, such as index Rebuild and Reorganize operations, that can fill the transaction log quickly, the database transaction log file should have sufficient free space to store the index operation transactions, that will not be truncated until the operation is completed successfully, and any concurrent user transactions performed during the index operation.
The huge amount of log transactions written to the database transaction log files during the index defragment operations requires a longer time to backup the transaction log file. This effect can be minimized by performing transaction log backups more frequently during index maintenance operations or changing the database recovery model to SIMPLE or BULK LOGGED to minimize the logging during that operation, if applicable. In addition, extra network overhead will be caused by pushing a large amount of transaction logs to the mirrored or Availability Groups secondary servers. If a noticeable network issue is caused during index maintenance operations, you can overcome that issue by pausing the data synchronization process during the index maintenance operations, if applicable.
Conclusion
In this articles series, we tried to cover all concepts that are related to the SQL Server indexing, starting from the basic structure of the SQL Server tables and indexes, diving in designing the indexes and tuning the queries using these indexes, and finishing with gathering statistical information about the index and use this information to maintain the indexes. I hope that you enjoyed this series and improved your knowledge.
Table of contents

He is a Microsoft Certified Solution Expert in Data Management and Analytics, Microsoft Certified Solution Associate in SQL Database Administration and Development, Azure Developer Associate and Microsoft Certified Trainer.
Also, he is contributing with his SQL tips in many blogs.
View all posts by Ahmad Yaseen
- Azure Data Factory Interview Questions and Answers - February 11, 2021
- How to monitor Azure Data Factory - January 15, 2021
- Using Source Control in Azure Data Factory - January 12, 2021