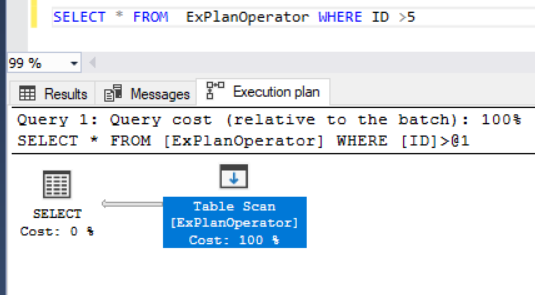
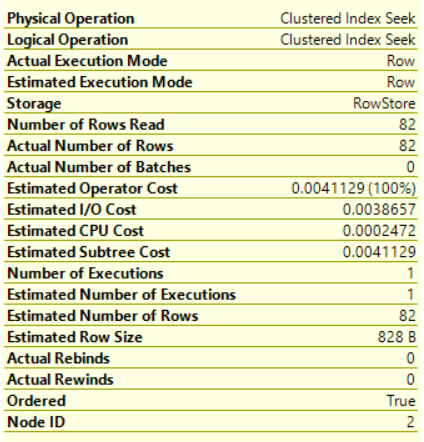
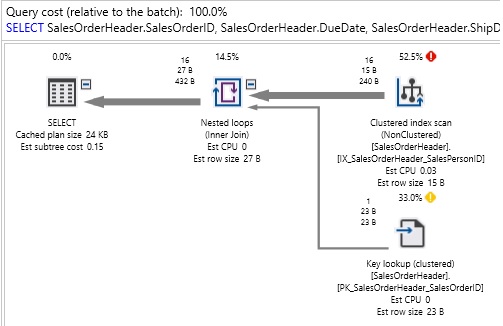
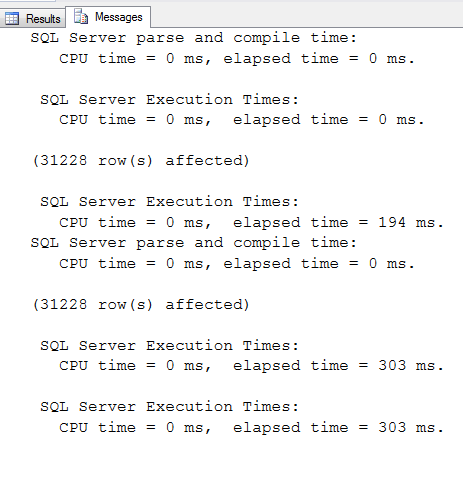
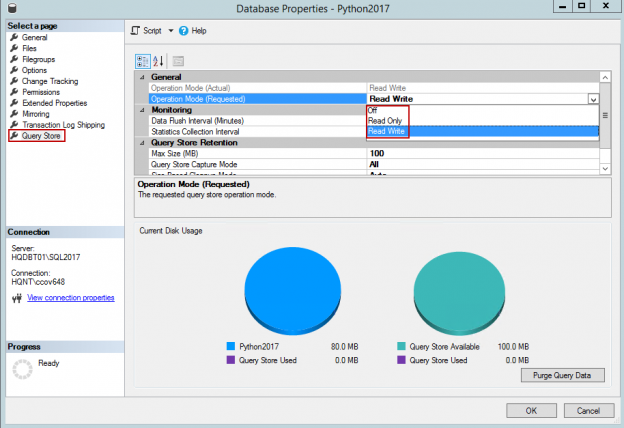
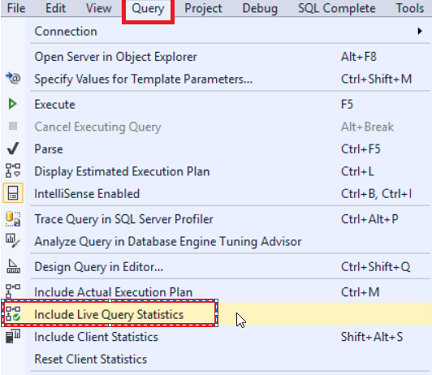
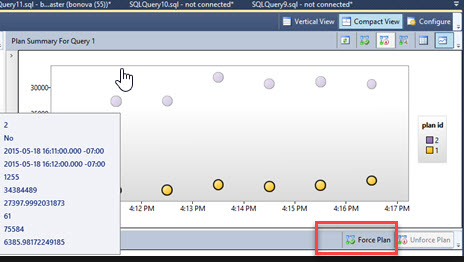
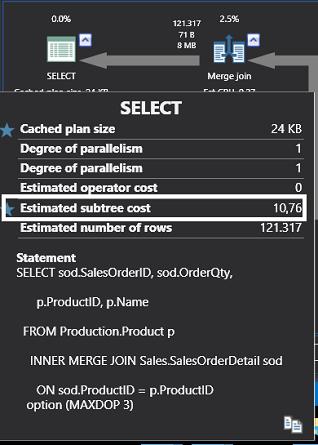
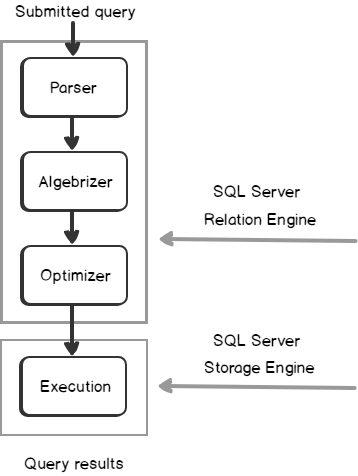
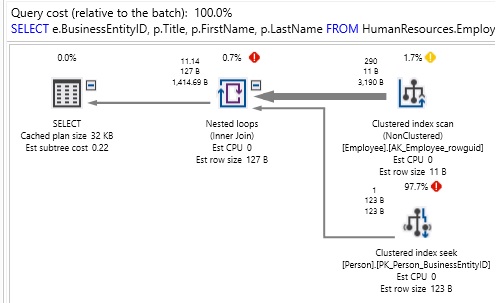
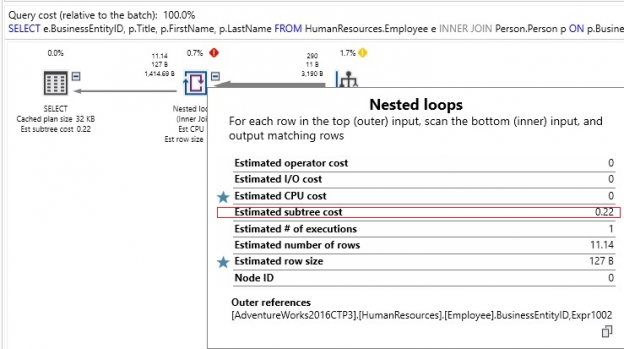
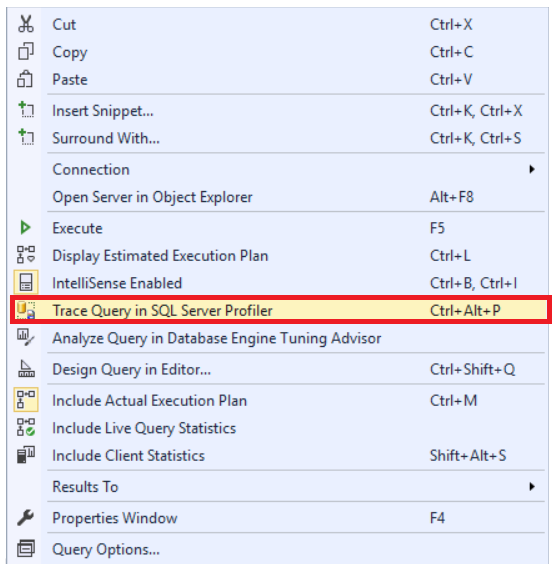
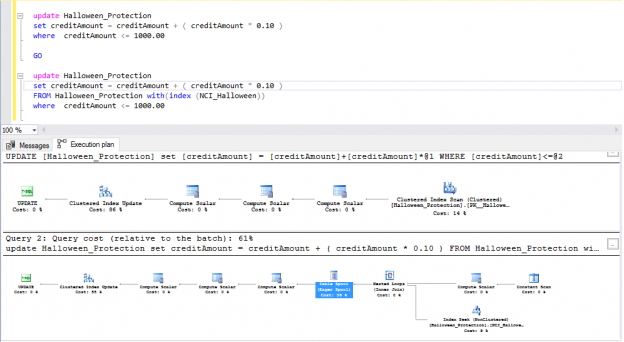
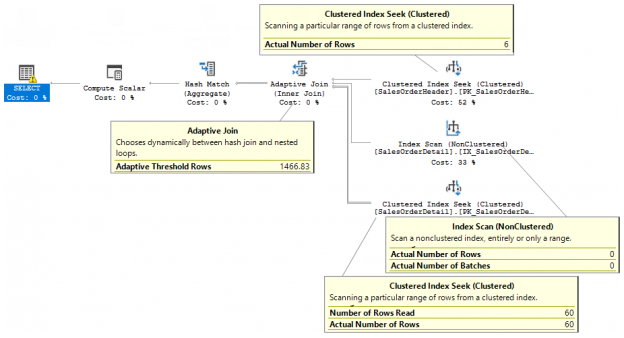
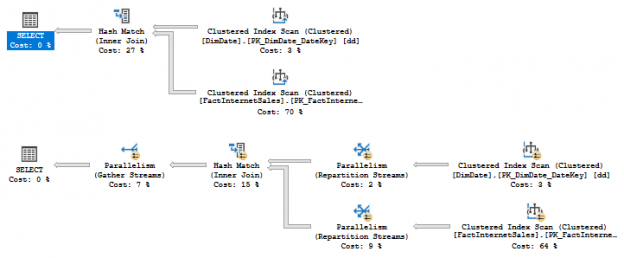
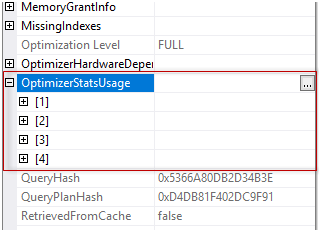
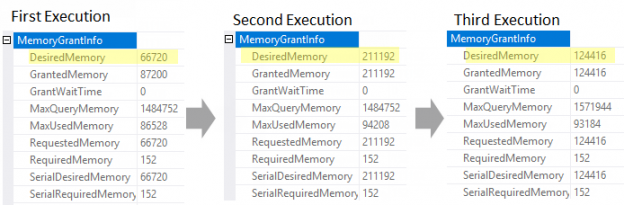
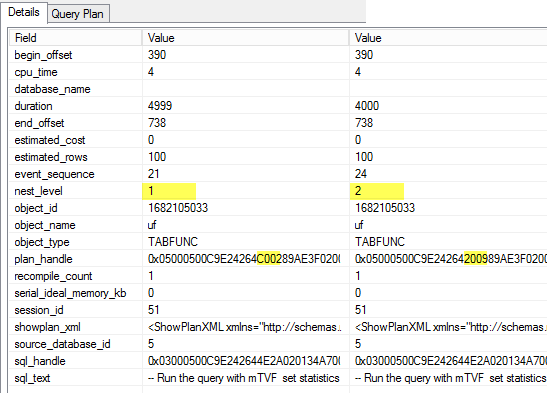
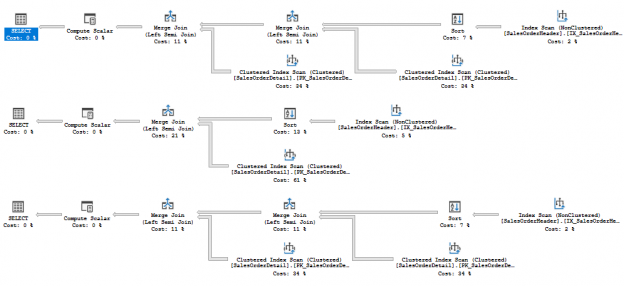
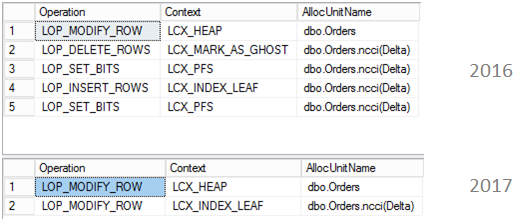
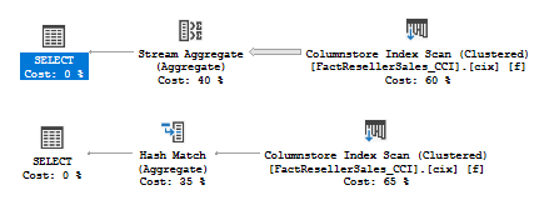
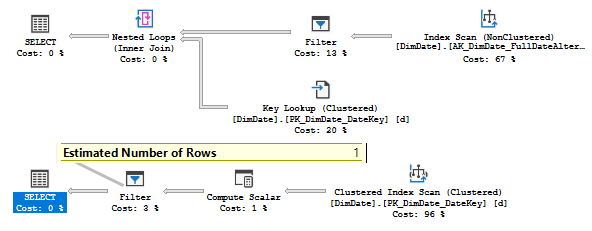
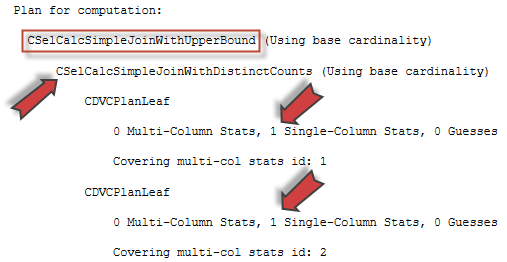
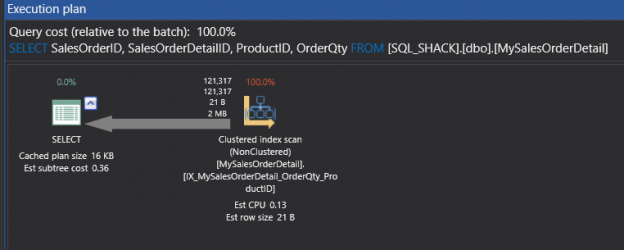
In the previous articles of this series, SQL Server Execution Plans overview , SQL Server Execution Plans types and How to Analyze SQL Execution Plan Graphical Components, we discussed the steps that are performed by the SQL Server Relational Engine to generate the Execution Plan of a submitted query and the steps performed by the SQL Server Storage Engine to retrieve the requested data or perform the requested modification operation.
Read more »