
Description
As per Wikipedia, the Halloween problem was first discovered by Don Chamberlin, Pat Selinger, and Morton Astrahan, on Halloween day, 1976.
Logically, there are two cursors performing a typical update operation. One to read and other to write. A read cursor identifies the row which is to be updated and another cursor that performs the write operation to update the rows. In terms of execution, this process is thus divided into two separate parts. To be more specific, first, the write cursor of an updated plan does not affect the second read cursor.
This means that if the data is updated first by the “write” cursor before the data was read by the “read” cursor, then it could be possible to change the position of the row just by updating it. Consequently, read it a second time and it might be different. The means of a key being updated using such an operation in SQL Server, is called the Halloween effect. Let me explain in detail for more clarification.
In this situation, a row (or rows) in the queried data may move position within the result set. In the context of the aforementioned operations; let me provide an example of this. The cursor for writing, I liken it to a cricket game and for the second cursor in terms of reading, I also assume to be players. In this example, prior to all players available on the ground, the cricket game starts! This would obviously not be a good situation.
We must ensure data is available to the write, which has been fully read. For securing protection against this scenario, it’s possible to introduce a blocking operator in the plan. For our example, the SPOOL operator would be a good candidate. Unfortunately, inserting a blocking operator, such as an eager spool, into the updated plan is required for copying all rows output by the read cursor and this copying is quite expensive. It is not necessary for the introduced blocking operator (e.g. spool) in every scenario, though. Generally, SQL Server uses this operator, because its cost is lower in comparison to other blocking operator. Functionally, the data has been inserted into tempDB, before it is used by a write operation. In short, it needs to be ensured the data is read first before modification happen.
There is a different type of blocking operators available in SQL Server. For the purpose of more clarification, I have described operators overview.
Non-blocking VS Blocking operator
Generally, execution plan operators are logically divided into 4 different groups
- Logical and physical operators
Also called iterators. Its highlighted as blue icons, it may represent query execution or DML operations.
- Parallelism physical operators
These are the same highlighted as blue icons. It might be a subset of logical and physical operators.
- Cursor operators
These display color in yellow icons and is used it while cursor used in T-SQL.
- Language Elements
Language elements display as green icons. Its represent T-SQL language elements.
Out of those operators, A non-blocking operator gives output immediately, while performing the action logically. I have mentioned some non-blocking operators like Compute Scalar, Merge Join, Stream Aggregate, Lazy Spool, etc.
A blocking operator first reads all the input for performing the action, then return the data. Logically We can say simply it to stop and go operators as well. I have mentioned some blocking operators like are as follows.
- Sort
- Eagar Hash Distinct
- Eagar Table spool
- Eagar Row Count Spool
- Hash Join
- UDX
- Scalar
- Batch Hash Table build
- Remote range
- Remote query
- Remote fetch
- Remote modify
- Hatch Match(Aggregate)
The Halloween problem was originally detected in an update, but it could also occur in an Insert, Delete or Merge Statement as well. For more clarification, I will demonstrate it now.
Halloween problem with an Update statement
The Halloween problem can appear in certain update operations. For demonstration purposes, here is the database creation sample script.
Sample Script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
CREATE DATABASE Halloween GO USE Halloween GO CREATE TABLE Halloween_Protection ( id INT PRIMARY KEY IDENTITY(1,1), custCode TINYINT, creditAmount DECIMAL(18,2), debitAmount DECIMAL(18,2) ) GO INSERT INTO Halloween_Protection ( custCode, creditAmount, debitAmount ) SELECT 101,1000,0 UNION ALL SELECT 102,500,0 UNION ALL SELECT 103,900,0 UNION ALL SELECT 104,800,0 UNION ALL SELECT 105,700,0 UNION ALL SELECT 106,1500,0 UNION ALL SELECT 107,0,3000 GO |
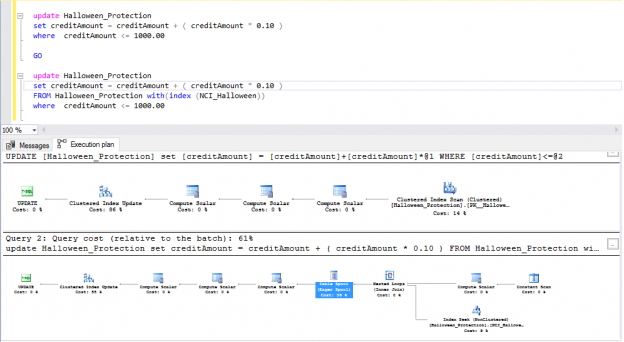
I have applied above mentioned script, I have DB Halloween ready for execution. As per my requirement, I need to update credit amount with 10% commission, which customer credit value is residing up to 1000. Based on that I have created a script and execute as follows with include execution plan.
Here the whole update operation is divided into multiple phases, it’s referred to as phase separation. In the first phase, all the records are found, based on where clauses predicate, and information is curated for the next phase. Once phase1 is completed, the whole set of update information is passed to the next second phase, in which each record is updated using a unique identifier and the new creditAmount is updated. In the last phase, the data integrity constraint validation of this process is checked.
The process in this execution flow reads rows at a time from the base source table. If rows are filtered with where clauses, as per above mentioned query the credit amount is increasing, this process is repeated until all rows are processed from the source table.
Look at wat the Clustered index scan operator found. It reads rows one at a time from the storage engine until it does not get the filtered records, here for the phase separation correctness introduced compute scalar operator. It performs a scalar computation and returns the computed value. Mostly this operator represents a minimal cost with respect execution plan. Despite of this, there are different type of blocking operator found in the plan. For more clarity purpose, I will demonstration it now.
Adding Blocking operators
As per the above script, the table is ready. Now I am going to add a non-clustered index.
|
1 2 3 4 5 6 |
USE [Halloween] GO CREATE NONCLUSTERED INDEX [NCI_Halloween] ON [dbo].[Halloween_Protection] ( [creditAmount] ASC ) |
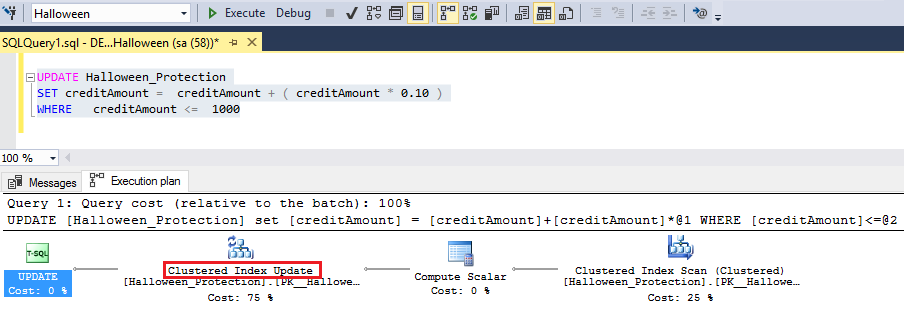
After adding an index, I executed two update statements with include execution plan.
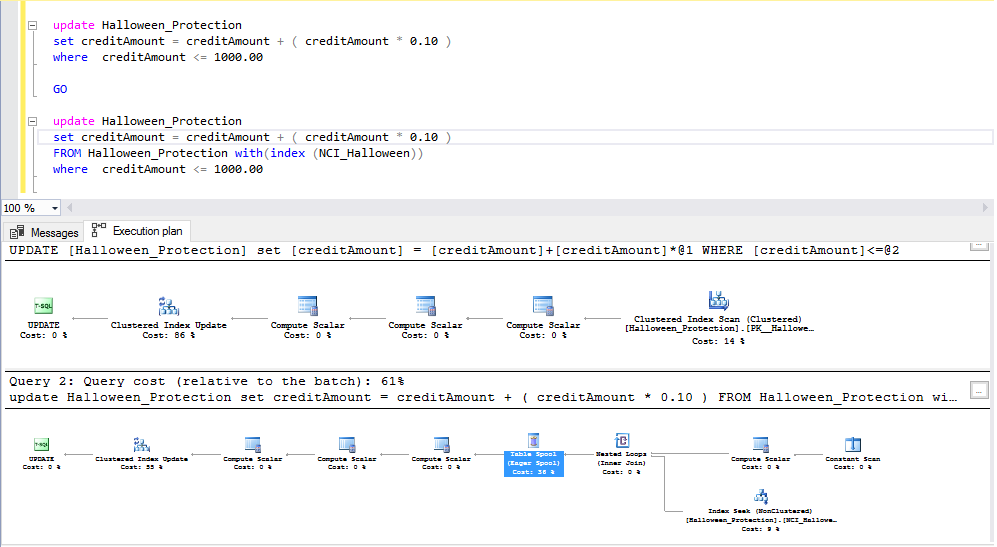
As per te above-mentioned query1 plan, we have found multiple compute scalars due to a non-clustered index. It means here index NCI_Halloween is created on column creditAmount, due to this query is finding qualified rows in which an index exists. In Query2, I have tried to used index NCI_Halloween, due to that introduced blocking operator Table spool.
Halloween problem with Insert statement
I have applied the insert statement with the not exists statement for the purpose of maintaining unique data into the table based on custcode column.
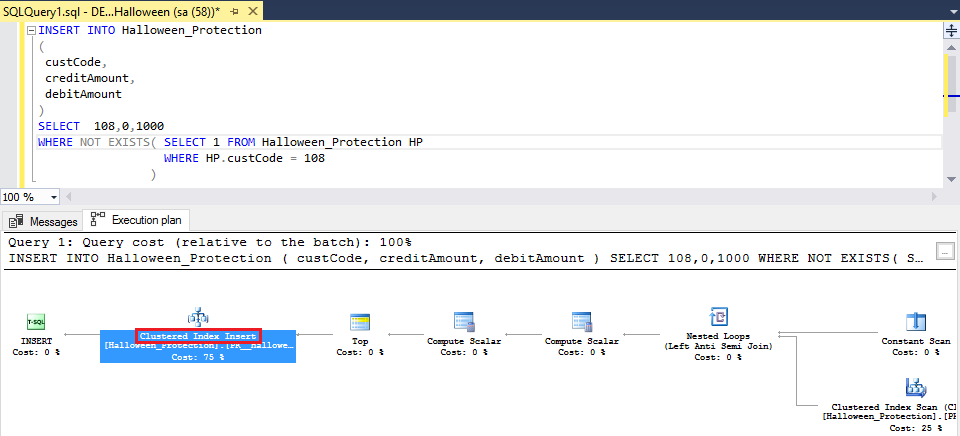
Generally, while on the insert statement Halloween protection found where the target table is also referenced in the select statement, though I have found a Clustered Index Insert in the query plan.
Halloween problem with Delete statement
I have also applied a delete statement with using the exists keyword.
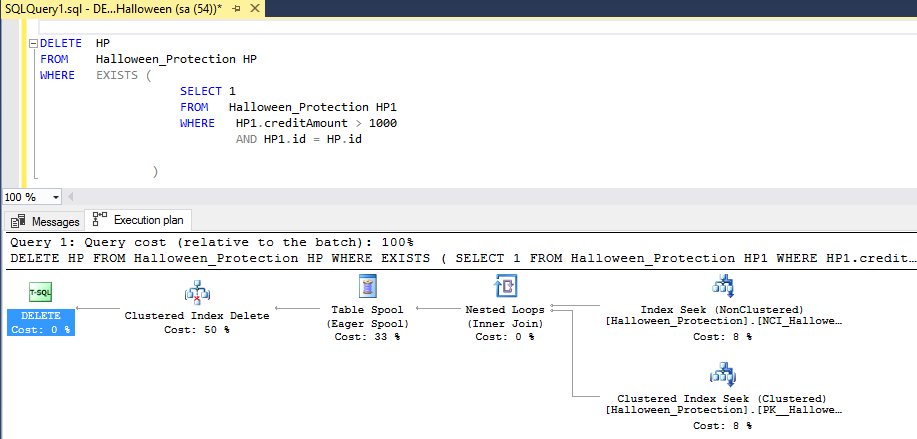
By using self-join references while deleting the records based on particular condition, there is a requirement for Halloween protection as well as phase separation.
Recommended actions
This is a SQL protection issue, not an exception or query specific issue. But sometimes due to this Halloween problem, we have a case of a performance bottleneck being realized. So, for such cases, we need to take care while during database design and development. Pursuant to this, I am trying to share generic views which might be useful in this scenario.
- Try to apply a clustered index on the unique column in the table and keep the column in index key which is not updated infrequently.
- Keep clustered Index size narrow and static same in non-clustered as well.
- Despite having a table with a clustered index, proper indexing in the table, is also required, as per use cases.
- Whenever executing T-SQL Statements specifically with Insert, select, delete, update or merge try to index tuned, its need to index seek in lieu of scan of huge data. Try to introduce temporary table or table variable in lieu of prepared single complex DML statement.
- On the coding side, make sure the T-SQL Statement is optimal in terms of Query cost.
- It would be more intuitive if we reduce the data volume in an update transaction using Means Used set based operation, Partition scheme etc. There are several approaches using T-SQL which could be useful for reducing query cost.
- Using Merge statement, we can avoid Halloween protection in join cases. In some case, Halloween protection in Merge statement could be required as well. It depends on T-SQL statements.
- As always, prior rollout in production, everything should be thoroughly tested.
References
- Halloween effect issue
- Cardinality Estimation Place in the Optimization Process
- SQL Server query execution plans – Basics
- The “Halloween Problem” for XML APIs
- Halloween Protection


During his career, he strongly workes on his DBA development and has been working with SQL Server 2000, 2005, 2008, 2012, 2014 and 2016.
Currently, his main role is query tuning with respect to optimization and server performance. He is interested in constant learning and likes to face challenges. In his spare time, he spends time with his family.
- Hash partitions in SQL Server - June 28, 2018
- The Halloween Problem in SQL Server and suggested solutions - May 4, 2018
- How to identify and resolve Hot latches in SQL Server - November 7, 2017