In this article, we will focus on how we can detect the parameter sniffing issues with different techniques.
Read more »
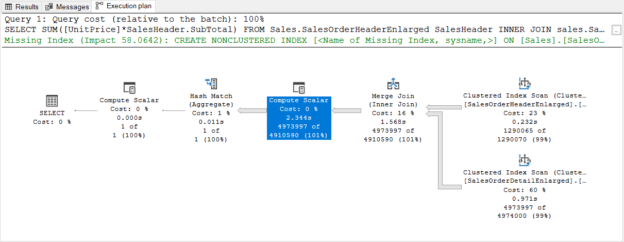
In this article, we will focus on how we can detect the parameter sniffing issues with different techniques.
Read more »
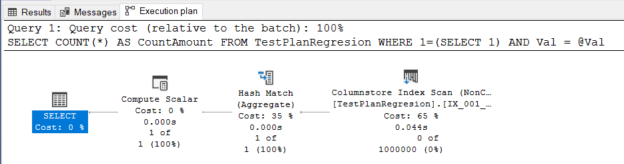
In this article, we will learn what is plan regression and how we can fix this issue with help of the Automatic Plan Correction feature.
Read more »

In this article, we will discuss how to read the SQL Server execution plan (query plan) with all aspects through an example, so we will gain some practical experience that helps to solve query performance issues. Interpreting query plans correctly is the first and major principle to troubleshoot query performance issues. When we try to find an answer to the “why is this query running slow?” question, the best starting point would be to analyze the query plan.
Read more »
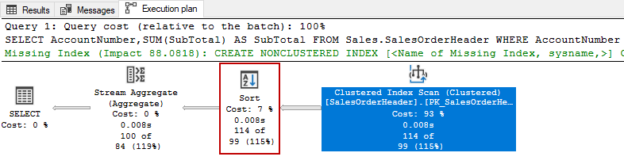
In this article, we will explore how the ORDER BY statement affects the query performance and we will also learn some performance tips related to sorting operations in SQL Server.
Read more »
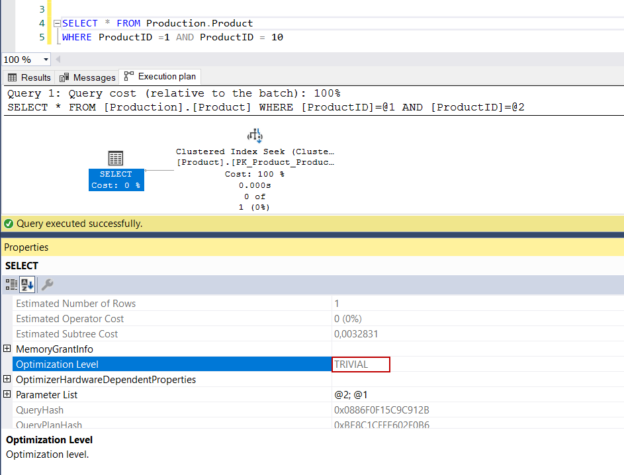
The SQL Server execution plan (query plan) is a set of instructions that describes which process steps are performed while a query is executed by the database engine. The query plans are generated by the query optimizer and its essential goal is to generate the most efficient (optimum) and economical query plan. Some query plans that are created by the query optimizer contain some interesting characteristics. In this article, we will go into details of these interesting query plans.
Read more »
Gaining experience in SQL query tuning can be very difficult and complicated for database developers or administrators. For this reason, in this article, we will work on a case study and we are going to learn how we can tune its performance step by step. In this fashion, we will understand well how to approach query performance issues practically.
Read more »
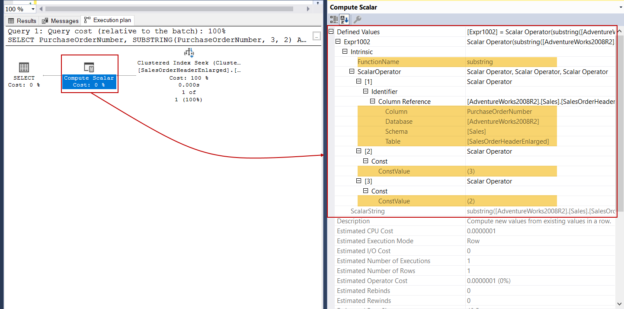
In this article, we will briefly explain the SUBSTRING function and then focus on performance tips about it.
Read more »
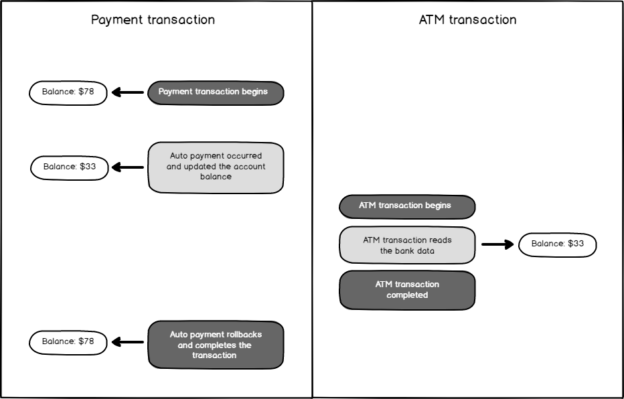
In this article, we will discuss the Dirty Read concurrency issue and also learn the details of the Read Uncommitted Isolation Level.
Read more »
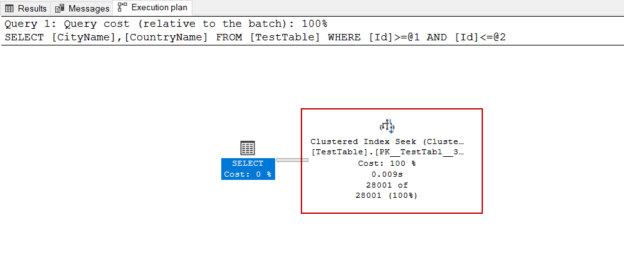
In this article, we will analyze a simple T-SQL query execution plan with different aspects. This will help us to improve our practical skills instead of discussing theoretical knowledge.
Read more »
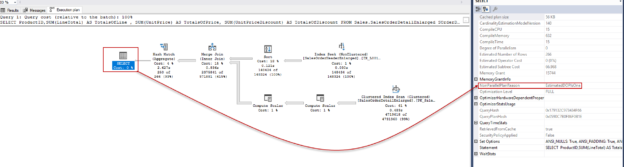
In this article, we will learn the basics of Parallel Execution Plans, and we will also figure out how the query optimizer decides to generate a parallel query plan for the queries.
Read more »
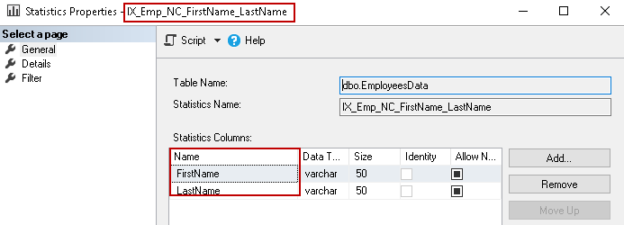
In this article, we will explore the Composite Index SQL Server and the impact of key order on it. We will also view SQL Server update statistics to determine an optimized execution plan of the Compositive index.
Read more »
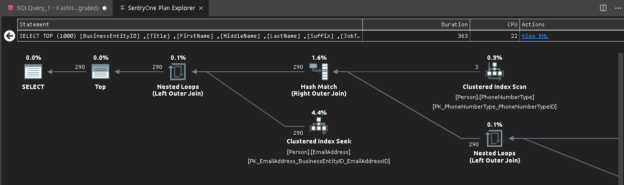
This article gives an overview of viewing execution plans in the Azure Data Studio.
Read more »
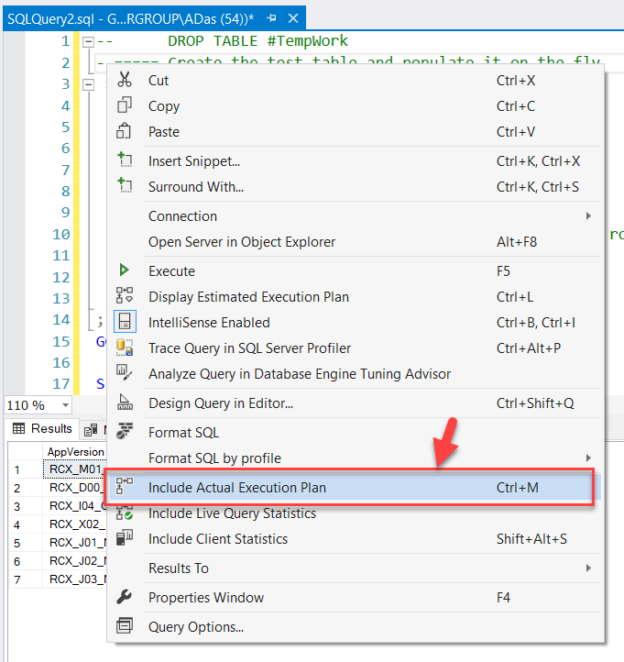
In this article, I’m going to explain what the Execution Plans in SQL Server are and how to understand the details of an execution plan by reading the various metrics available once we hover over the components in the plan.
Read more »

In this article, we will learn the SQL Average function which is known as AVG() function in T-SQL. AVG() function is an aggregate function that calculates the average value of a numerical dataset that returns from the SELECT statement.
Read more »

In this article, we will discuss a few very common questions that you may be asked during a SQL Server administrator or developer technical job interview.
Read more »
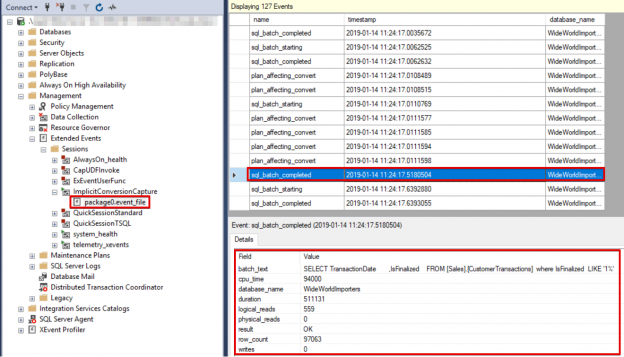
This article will provide an overview of SQL Server implicit conversion including data type precedence and conversion tables, implicit conversion examples and means to detect occurrences of implicit conversion
Read more »
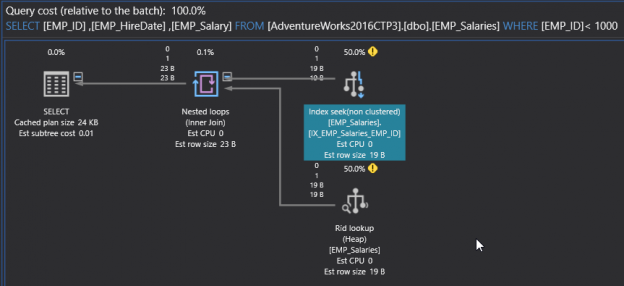
In the previous articles of this series (see the index at bottom), we discussed the characteristics of the SQL Execution Plan from multiple aspects, that include the way the SQL Execution Plan is generated by the SQL Server Query Optimizer internally, what are the different types of plans, how to identify and analyze the different components and operators of the Execution Plans, how to work with the plans using different tools and finally, tuning the performance of simple and complex T-SQL queries using the Execution Plans. In this, the last article of this series, but not the least, we will discuss where the Execution plan is stored and how to save it for future use.

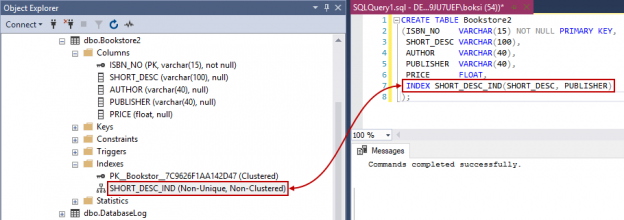
A SQL index is used to retrieve data from a database very fast. Indexing a table or view is, without a doubt, one of the best ways to improve the performance of queries and applications.
A SQL index is a quick lookup table for finding records users need to search frequently. An index is small, fast, and optimized for quick lookups. It is very useful for connecting the relational tables and searching large tables.
Read more »
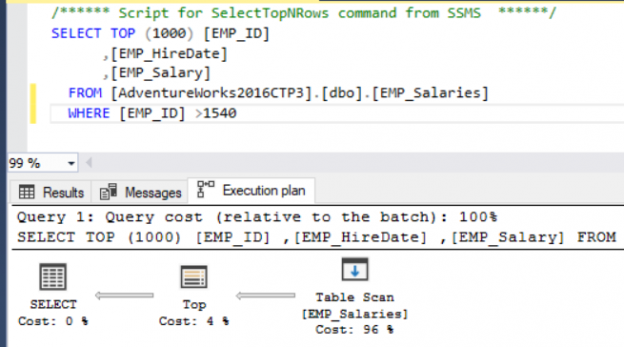
In the previous articles of this series (see the index at bottom), we went through many aspects of the SQL Execution Plan, where we discussed how the Execution Plan is generated internally, the different types of plans, the main components and operators and how to read and analyze the plans that are generated using different tools. In this article, we will show how we can use an Execution Plan in tuning the performance of T-SQL queries.
Read more »
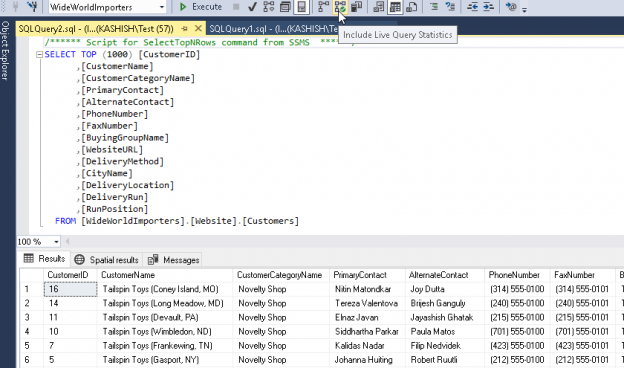
Database administrators are used to dealing with query performance issues. As part of this duty, it is an important aspect to identify the query and troubleshoot the reason for its performance degradation. Normally, we used to enable SET STATISTICS IO and SET STATISTICS TIME before executing any query.
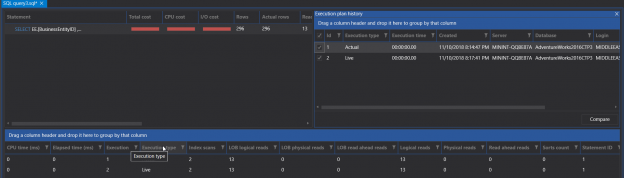
In the previous articles of this series (see the index at bottom), we discussed many aspects of the SQL Execution Plans, starting with the main concept of SQL Execution Plan generation, diving in the different types of the plans and showing how to analyze the components and operators of the SQL Execution Plans.
Read more »
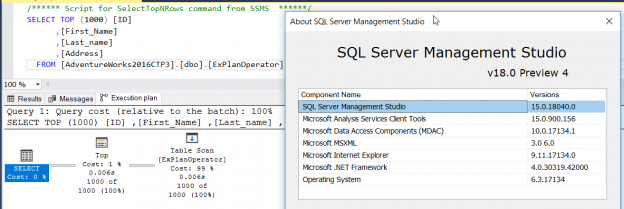
This article will provide an overview of the SSMS 18.0 with particular focus on improvements to the SQL execution plan feature. To work with Microsoft SQL Server Database Engine, you need to have an environment to edit, debug and deploy scripts written in different languages such as T-SQL, DAX, MDX, XML and JSON. In addition, you need a GUI tool that helps you to configure, query, monitor and administrate your SQL Server instances wherever they are hosted; locally at your machine, on a remote Windows or Linux server or in the cloud. All this can be achieved using SQL Server Management Studio aka SSMS.
Read more »
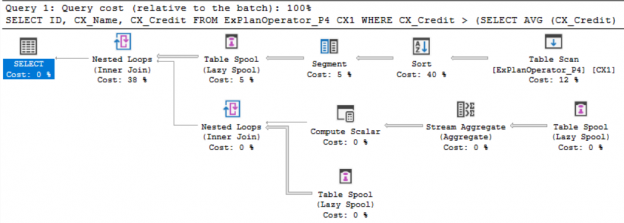
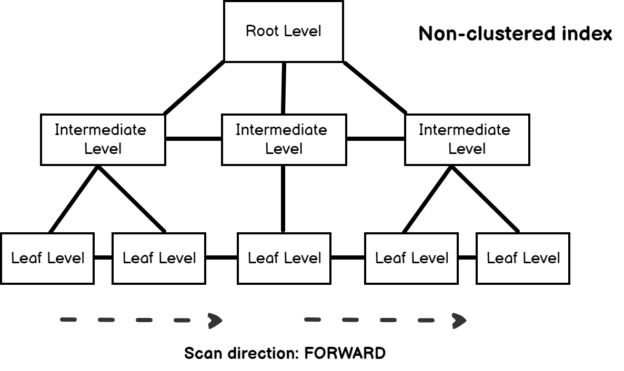
In the previous articles of this series, we went through three sets of SQL Server Execution Plan operators that you will meet with while working with the different Execution Plan queries. We described the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup, Sort, Aggregate – Stream Aggregate, Compute Scalar, Concatenation, Assert, Hash Match Join, Hash Match Aggregate , Merge Join and Nested Loops Join Execution Plan operators. In this article, we will dive in the fourth set of these SQL Server Execution Plan operators.
Read more »
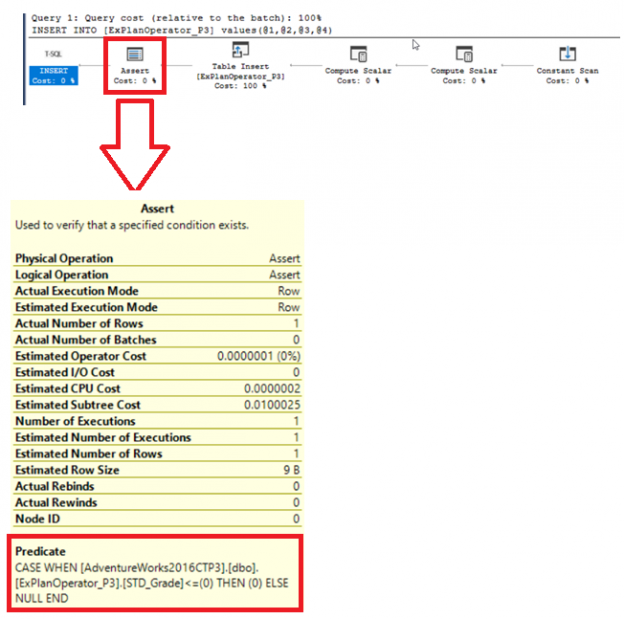
In the previous articles of this series, we discussed a group of SQL Server Execution Plan operators that you will face when studying the SQL Execution Plan of different queries. We showed the Table Scan, Clustered Index Scan, Clustered Index Seek, the Non-Clustered Index Seek, RID Lookup, Key Lookup and Sort Execution Plan operators. In this article, we will discuss the third set of these SQL Execution Plan operators.
Read more »
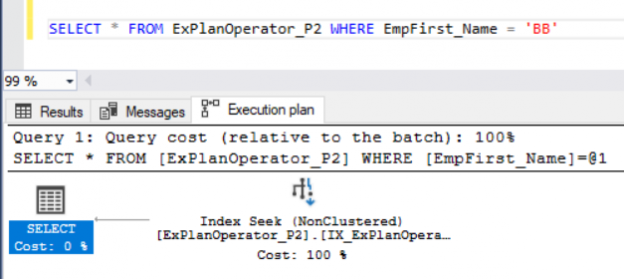
In the previous article, we talked about the first set of operators you may encounter when working with SQL Server Execution Plans. We described the Non Clustered Index, Seek Execution Plan operators, Table Scan, Clustered Index Scan, and the Clustered Index Seek. In this article, we will discuss the second set of these SQL Server execution plan operators.
Read more »© Quest Software Inc. ALL RIGHTS RESERVED. | GDPR | Terms of Use | Privacy