
In this article, you will see how to implement a star schema in Power BI. Microsoft Power BI is a business analytics tool used to manipulate and analyze data from a variety of sources.
What is a Star Schema?
Star schema refers to the logical description of datasets where data is divided into facts tables and dimension tables.
The facts table contains the actual information and the dimensions table contains the related information. Star schema is very similar to a one-to-many relationship, where a table can have multiple/duplicate foreign keys from a foreign key column.
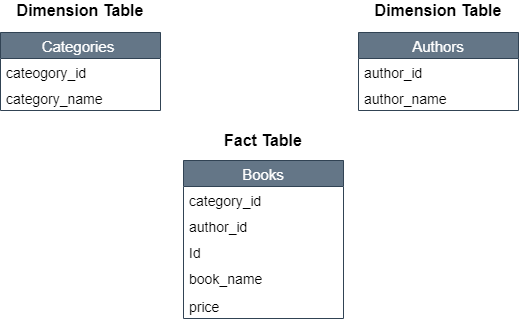
Take a look at the following figure. In the figure below, we have two tables that are dimensional: Categories and Authors and one fact table Books.
As a rule of thumb, the tables that contain values that can be repeated in the other tables are dimension tables and the table which contains foreign keys from other tables is implemented as a fact table.
For instance, if you look at the Authors table it contains values as author_id and author_name. Since one author can write multiple books, there can be multiple records in the Books table where the value for the author_id will be the same and so repeated. Therefore, the Authors table will be implemented as a dimension table in a star schema in Power BI. In the same way, the Categories table has been implemented as a dimension table.
If you look at the Books table, it contains columns that can be used to retrieve data from other tables i.e. using category_id and author_name columns from the Books table, the category names, and author names can be retrieved. Since the Books table contains keys that can be used to retrieve data from other tables, the Books table is implemented as a fact table.
Now that you understand what star schema is and what dimensions and facts tables are, let’s briefly look at why you might want to use a star schema in Power BI.
The main advantages of star schemas are:
Simplicity
Star schemas are very easy to understand, read and use. Dimensions are used to slice and dice the data, and facts to aggregate numbers.
Performance
Star schemas contain clear join paths and relatively small numbers of tables. This means that queries run more quickly than they will on an operational system.
Scalability
Star schemas can accommodate changes, such as adding new dimensions, attributes or measures very easily. Making changes to your star schema in Power BI will be simple once you are set up.
Support
Star schemas are the most commonly used schemas in BI. This means that they are widely understood and supported by a large number of BI tools.
Now that we understand what star schema is and why you might want to implement star schema in Power BI, let’s create a database in SQL Server that will be used as a source to Power BI desktop. The database will be used to implement the start Schema in Power BI.
Creating a dummy database
We will create a simple SQL Server database for a fictional book store. The name of the database will be the BookStore.
The following script creates our database:
|
1 |
CREATE DATABASE BookStore |
The database will contain only one table i.e.:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
USE BookStore CREATE TABLE Books ( Id INT PRIMARY KEY IDENTITY(1,1), book_name VARCHAR (50) NOT NULL, price INT, category_id INT, category_name VARCHAR (50) NOT NULL, author_id INT, author_name VARCHAR (50) NOT NULL, ) |
The Books table contains 7 columns: Id, book_name, price, cateogory_id, category_name, author_id, and author_name.
Let’s add some dummy records in the Books table:
|
1 2 3 4 5 6 7 8 9 10 11 |
USE BookStore INSERT INTO Books VALUES ( 'Book-A', 100, 1, 'CAT-A', 1, 'Author-A'), ( 'Book-B', 200, 2, 'CAT-B', 2, 'Author-B'), ( 'Book-C', 150, 3, 'CAT-C', 2, 'Author-B'), ( 'Book-D', 100, 3, 'CAT-C', 1, 'Author-A'), ( 'Book-E', 200, 3, 'CAT-C', 2, 'Author-B'), ( 'Book-F', 150, 4, 'CAT-D', 3, 'Author-C'), ( 'Book-G', 100, 5, 'CAT-E', 2, 'Author-B'), ( 'Book-H', 200, 5, 'CAT-E', 4, 'Author-D'), ('Book-I', 150, 6, 'CAT-F', 4, 'Author-D') |
Connecting Power BI with SQL Server
We have created a dummy dataset. The next step is to connect Power BI with SQL Server and then import the BookStore dataset into Power BI. To see the detailed explanation for how to connect Power BI with SQL Server, have a look at this article on connecting Power BI to SQL. Only a brief explanation is given in this section.
To connect Power BI with SQL Server, open the Power BI main dashboard, and then select the “Get Data” option from the top menu. A dialogue box will appear where you have to enter the SQL Server and the database names. Enter the server name as per your SQL Server instance name. In the Database field, enter “BookStore”.
Once the connection is established, you will see the following window.
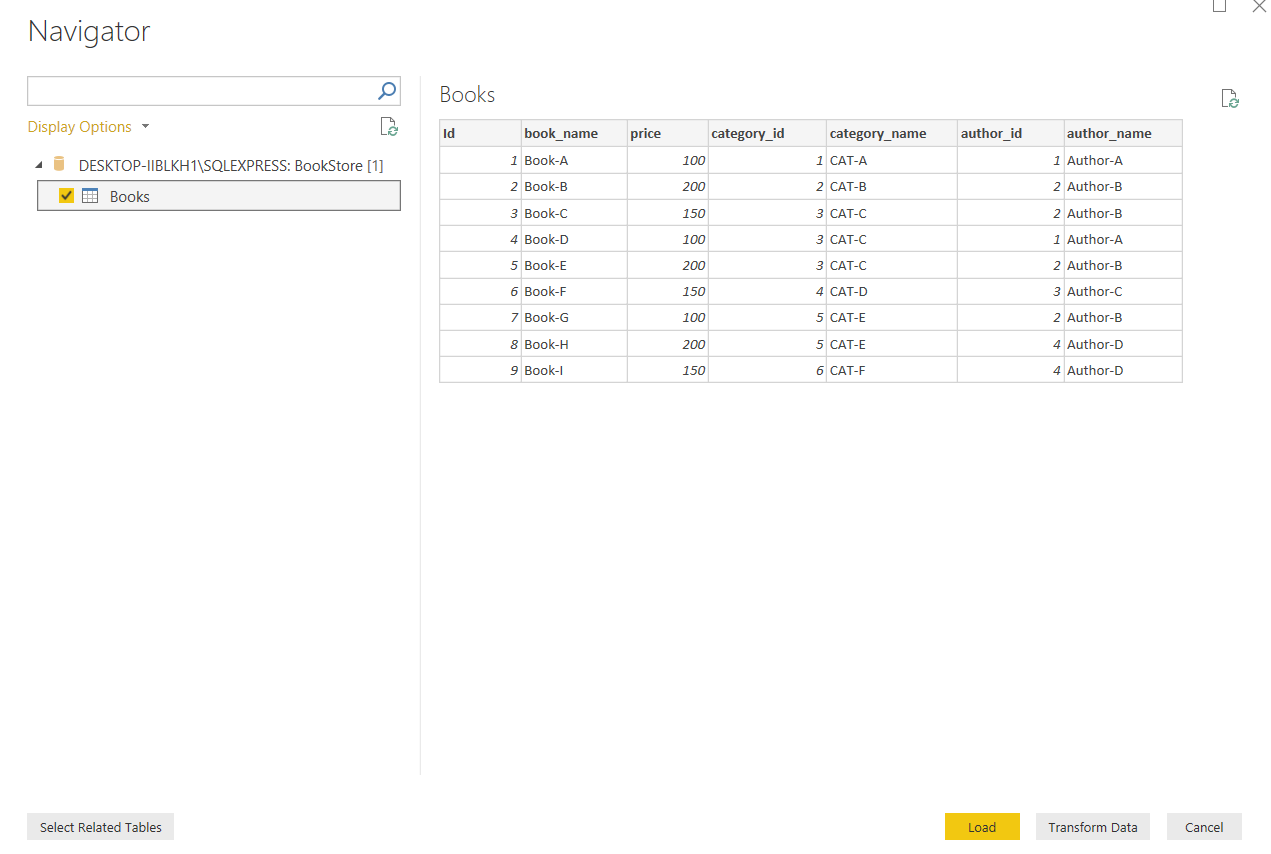
Click on the table name “Books” and then click “Transform Data” button. The data will be loaded into the Query Editor.
Implementing Star Schema in Power BI with Query Editor
If you look at the Books table in the query editor, it contains 7 columns as shown below:
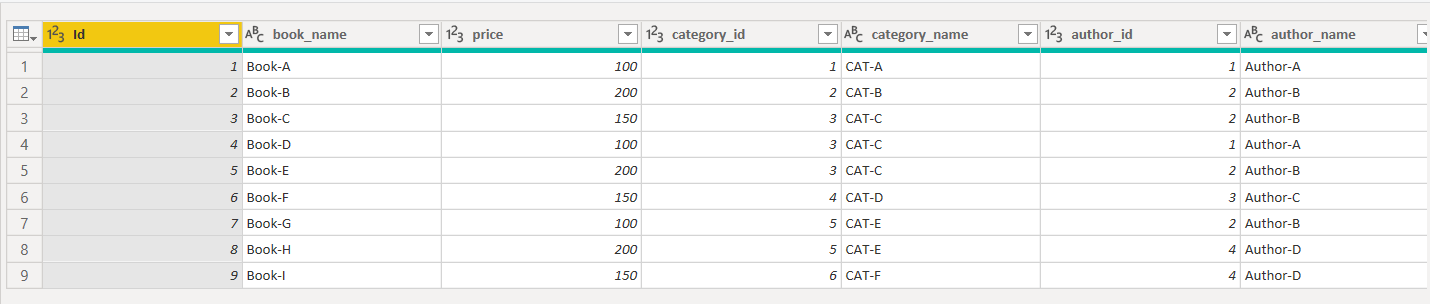
To implement Star Schema in Power BI using the Books table, as I explained earlier, we need to split the Books table into three tables i.e. Books, Categories and Authors. A single dataset or table in the Power BI Query Editor is called a query. From now on, I will use the term query for each table.
Creating a Dimensional Query for Categories
As a first step, we will create a dimension table for Category. To do so, right-click on the Books query (table), and select “Reference” from the drop-down menu as shown below. This will create a new query that references the actual Books query. The new query will not have any connection with the actual data source. This new query will be used to create a dimension query for Category. Click on the query name and rename it to DIM-Category.
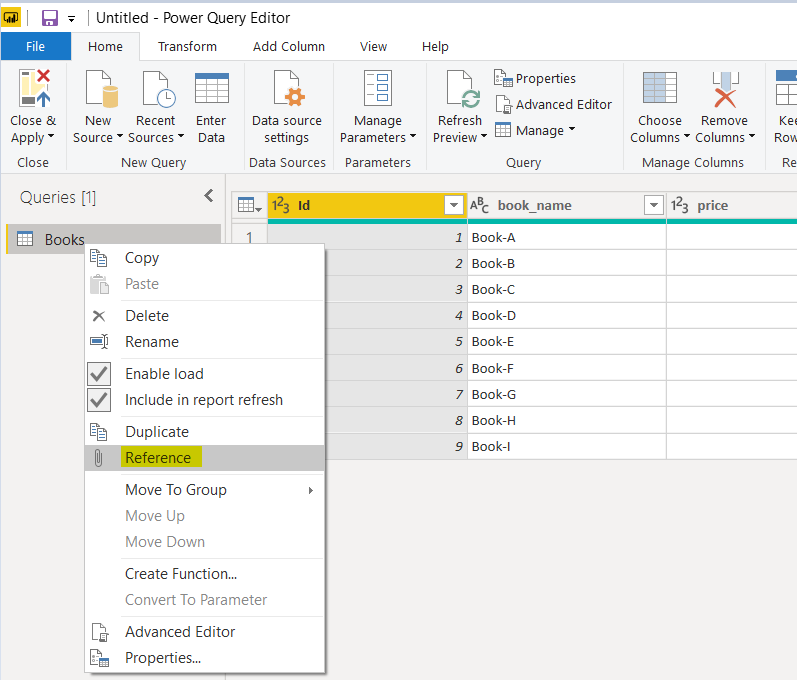
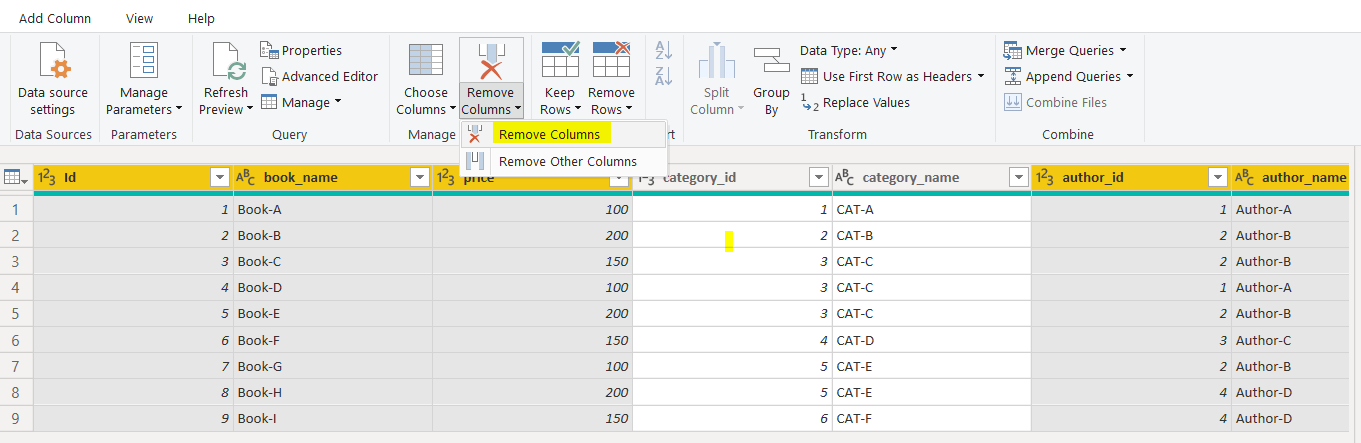
The DIM-Category query will contain all the same seven columns as Books query. In the DIM-Category query, we only need the category_id and category_name columns. Therefore, select all the columns except those two, and click the “Remove Columns” option from the top menu as shown in the following screenshot.
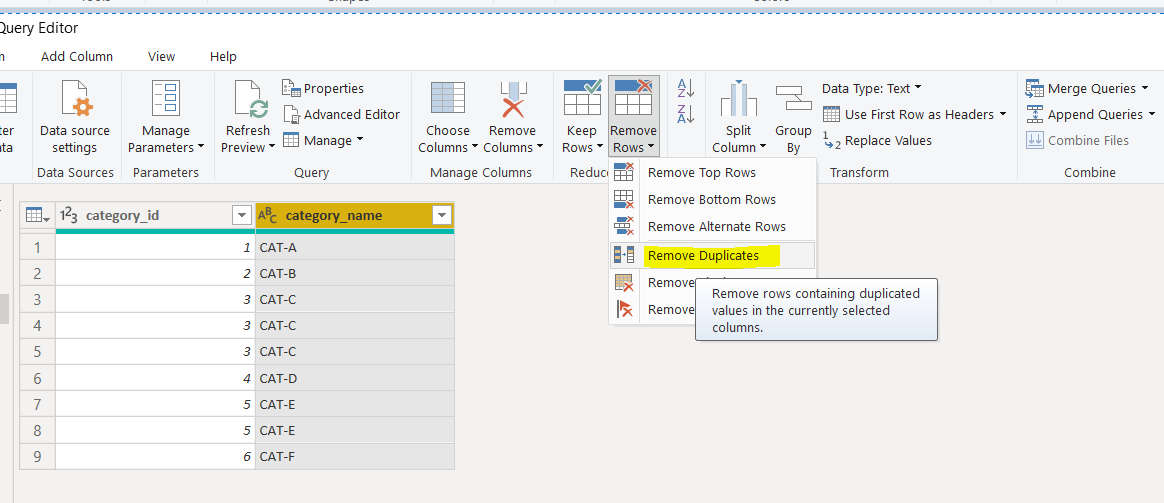
The next step is to remove the duplicate rows from the DIM-Category query. To do so, select any column and then click “Remove Rows -> Remove Duplicates” option from the top menu.
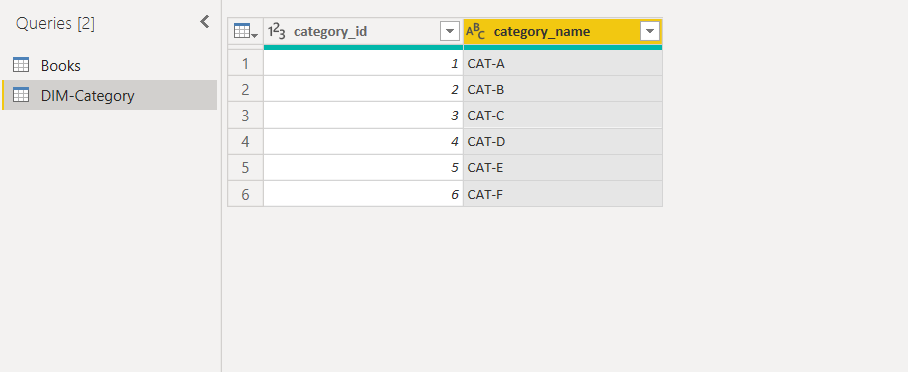
Once you remove the duplicates you should see the following query. You can see that the DIM-Category query now only contains unique ids and names of the authors.
Creating a Dimensional Query for Authors
To create a dimension query for the Authors, again create a new reference query and rename it “DIM-Author”. Next remove all the columns from the DIM-Author query, except author_id, and author_name as shown below:
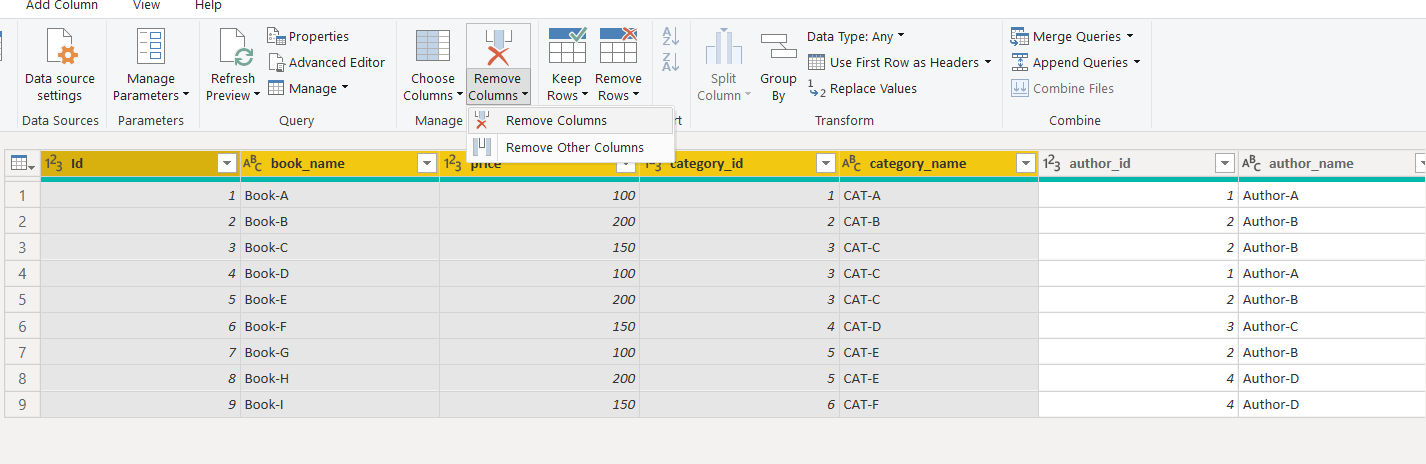
Next, remove the duplicate columns from the DIM-Author query by clicking the “Remove Rows -> Remove Duplicates” option from the top menu.
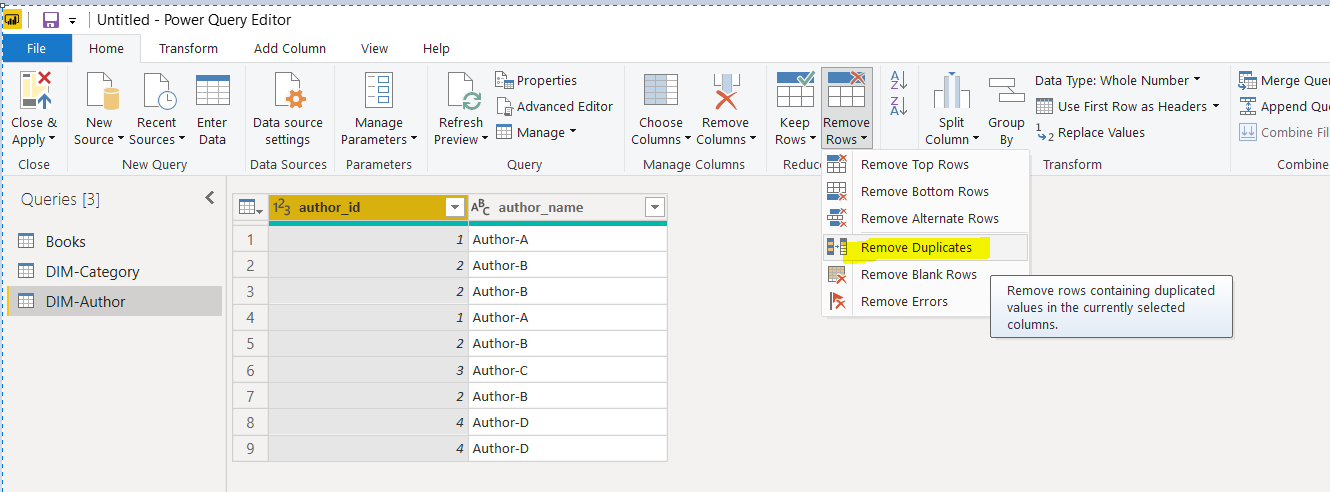
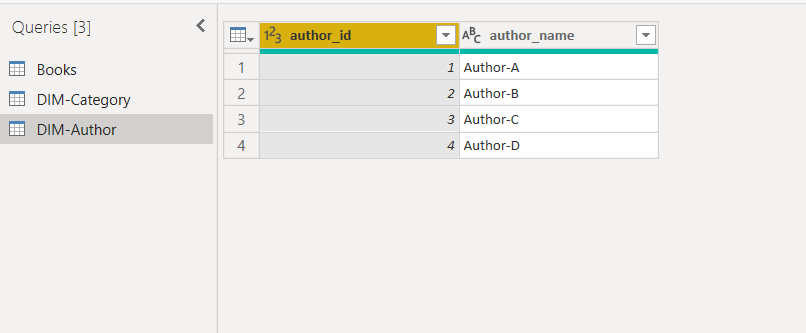
The DIM-Author query will look like this once you remove the duplicates.
Creating a Fact Query for Books
The final step is to create a fact query for Books. Again, create a new reference query.
We can simply remove the author_name and category_name columns to create a fact query for books.
However, to make sure that the category_id and author_id columns actually refer to the category_id and author_id columns of the DIM-Category and DIM-Author queries, we will take a different approach. So click on “Merge Queries” option from the top menu as shown below:
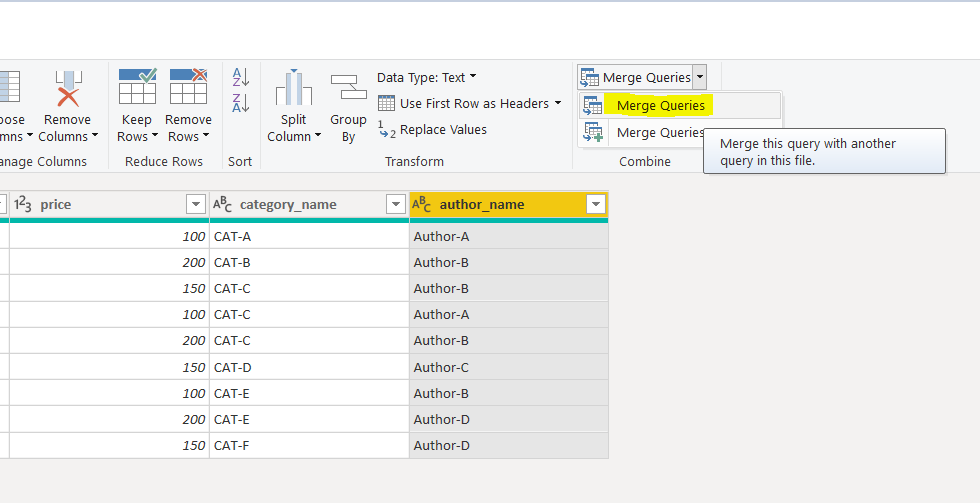
Next select the category_name column from the Fact-Book query and from the DIM-Category query, also select category_name as shown below. Click the “OK” button.
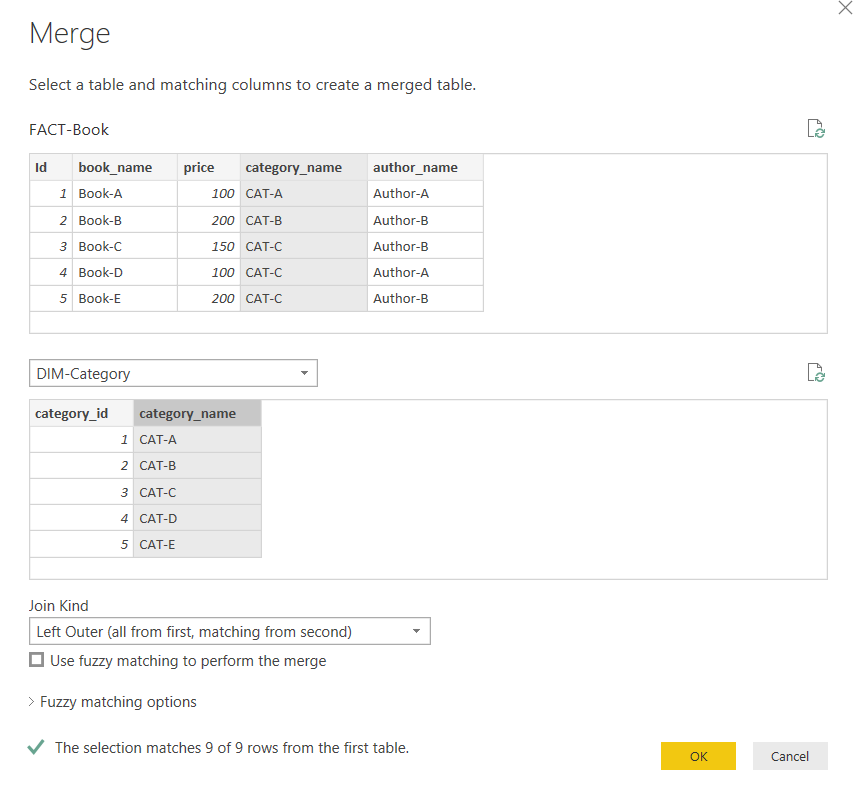
You will see the DIM-Category column in the FACT-Book query.
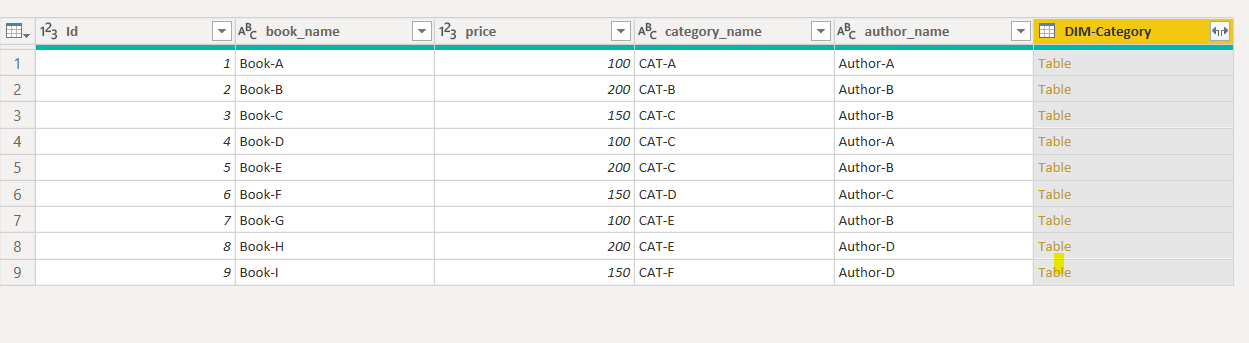
Click on the button on the extreme right in the DIM-Category column header. You will see the following window.
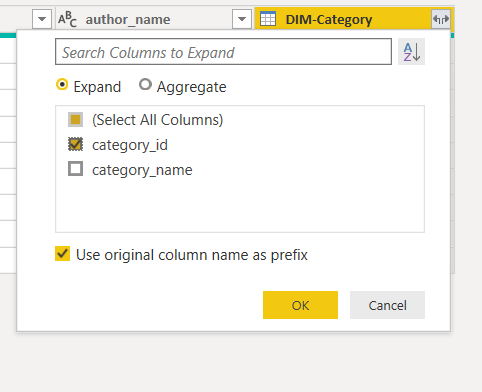
Select the “category_id” column and you will see a column “DIM-Category.category_id” in the FACT-Book query as shown below. This column actually refers to the category_id column of the DIM-Category query and connects it with the FACT-Book.
In the same way, you can merge the author_name column of the DIM-Author and FACT-Book query as shown below:
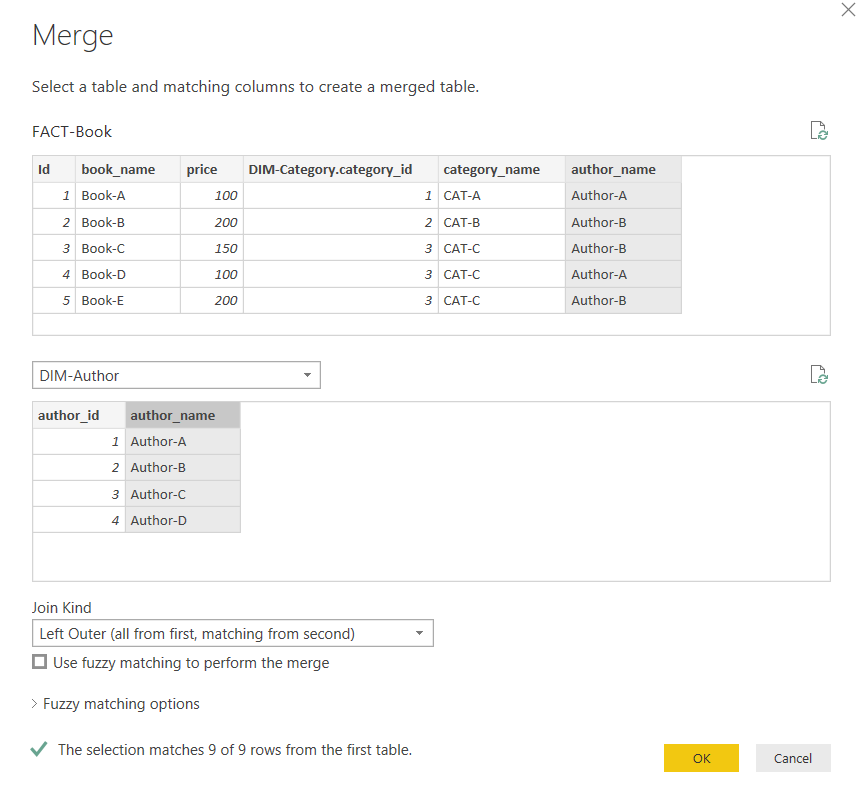
Finally, remove the author_name, and category_name columns to get the final version of the FACT-Book query.
Conclusion
Star schema is one of the most commonly used schemas for logical implementation of related data. This article shows how to implement the star schema in Power BI Query Editor, with the help of an example.

View all posts by Ben Richardson
- Working with the SQL MIN function in SQL Server - May 12, 2022
- SQL percentage calculation examples in SQL Server - January 19, 2022
- Working with Power BI report themes - February 25, 2021