
The SQL CREATE INDEX statement is used to create clustered as well as non-clustered indexes in SQL Server. An index in a database is very similar to an index in a book. A book index may have a list of topics discussed in a book in alphabetical order. Therefore, if you want to search for any specific topic, you simply go to the index, find the page number of the topic, and go to that specific page number. Database indexes are similar and come handy. Particularly, if you have a huge number of records in your database, indexes can speed up the query execution process. There are two major types of indexes in SQL Server: clustered indexes and non-clustered indexes.
In this article, you will see what the clustered and non-clustered indexes are, what are the differences between the two types and how they can be created via SQL CREATE INDEX statement. So let’s begin without any further ado.
Creating dummy data
The following script creates a dummy database named BookStore with one table i.e. Books. The Books table has four columns: id, name, category, and price:
|
1 2 3 4 5 6 7 8 9 10 |
CREATE Database BookStore; GO USE BookStore; CREATE TABLE Books ( id INT PRIMARY KEY NOT NULL, name VARCHAR(50) NOT NULL, category VARCHAR(50) NOT NULL, price INT NOT NULL ) |
Let’s now add some dummy records in the Books table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
USE BookStore INSERT INTO Books VALUES (1, 'Book1', 'Cat1', 1800), (2, 'Book2', 'Cat2', 1500), (3, 'Book3', 'Cat3', 2000), (4, 'Book4', 'Cat4', 1300), (5, 'Book5', 'Cat5', 1500), (6, 'Book6', 'Cat6', 5000), (7, 'Book7', 'Cat7', 8000), (8, 'Book8', 'Cat8', 5000), (9, 'Book9', 'Cat9', 5400), (10, 'Book10', 'Cat10', 3200) |
The above script adds 10 dummy records in the Books table.
Clustered indexes
Clustered indexes define the way records are physically sorted in a database table. A clustered index is very similar to the table of contents of a book. In the table of contents, you can see how the book has been physically sorted. Either the topics are sorted chapter wise according to their relevance or they can be sorted alphabetically.
There can be only one way in which records can be physically sorted on a disk. For example, records can either be sorted by their ids or they can be sorted by the alphabetical order of some string column or any other criteria. However, you cannot have records physically sorted by ids as well as names. Hence, there can be only one clustered index for a database table. A database table has one clustered index by default on the primary key column. To see the default index, you can use the sp_helpindex stored procedure as shown below:
|
1 2 |
USE BookStore EXECUTE sp_helpindex Books |
Here is the output:

You can see the clustered index name and the column on which the clustered index has been created by default.
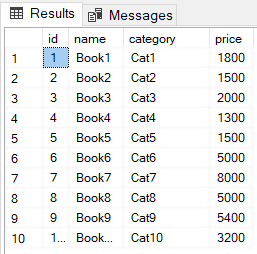
To see the records arranged by default clustered index, simply execute the SELECT statement to select all the records from the books table:
|
1 |
SELECT * FROM Books |
You can see that the records have been sorted by default clustered index for the primary key column i.e. id.
To create a clustered index in SQL Server, you can modify SQL CREATE INDEX. Here is the syntax:
|
1 2 |
CREATE CLUSTERED INDEX <index_name> ON <table_name>(<column_name> ASC/DESC) |
Let’s now create a custom clustered index that physically sorts the record in the Books table in the ascending order of the price. Since there can be only one clustered index, we first need to remove the default clustered index created via the primary key constraint. To remove the default clustered index, you simply have to remove the primary key constraint from the table that contains the default clustered index. Look at the following script:
|
1 2 3 4 |
USE BookStore ALTER TABLE Books DROP CONSTRAINT PK__Books__3213E83F7DFA309B GO |
Now we can create a new clustered index via SQL CREATE INDEX statement as shown below:
|
1 2 3 |
use BookStore CREATE CLUSTERED INDEX IX_tblBook_Price ON Books(price ASC) |
In the script above, we create a clustered index named IX_tblBook_Price. This clustered index physically sorts all the records in the Books table by the ascending order of the price.
Let’s now select all the records from the Books table to see if they have been sorted in the ascending order of their prices:
|
1 |
SELECT * FROM Books |
Here is the output:
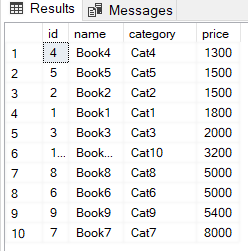
From the output, you can see that records have actually been sorted by the increasing amount of price.
Non-clustered indexes
A non-clustered index is an index that doesn’t physically sort the database records. Rather, a non-clustered index is stored at a separate location from the actual database table. It is the non-clustered index which is actually similar to an index of a book. A book index is stored at a separate location, while the actual content of the book is separately located.
The SQL CREATE INDEX query can be modified as follows to create a non-clustered index:
|
1 2 |
CREATE NONCLUSTERED INDEX <index_name> ON <table_name>(<column_name> ASC/DESC) |
Let’s create a simple non-clustered index that sorts the records in the Books table by name. You can modify the SQL CREATE INDEX query as follows:
|
1 2 3 |
use BookStore CREATE NONCLUSTERED INDEX IX_tblBook_Name ON Books(name ASC) |
As I said earlier, the non-clustered index is stored at a location which is different from the location of the actual table, the non-clustered index that we created will look like this:
|
Name |
Record Address |
|
Book1 |
Record address |
|
Book2 |
Record address |
|
Book3 |
Record address |
|
Book4 |
Record address |
|
Book5 |
Record address |
|
Book6 |
Record address |
|
Book7 |
Record address |
|
Book8 |
Record address |
|
Book9 |
Record address |
|
Book10 |
Record address |
Now if a user searches for the name, id, and price of a specific book, the database will first search the book’s name in the non-clustered index. Once the book name is searched, the id and price of the book are searched from the actual table using the record address of the record in the actual table.
Conclusion
The article covers how to use SQL CREATE INDEX statement to create a clustered as well as a non-clustered index. The article also shows the main differences between the two types of clustered indexes with the help of examples.

View all posts by Ben Richardson
- Working with the SQL MIN function in SQL Server - May 12, 2022
- SQL percentage calculation examples in SQL Server - January 19, 2022
- Working with Power BI report themes - February 25, 2021