
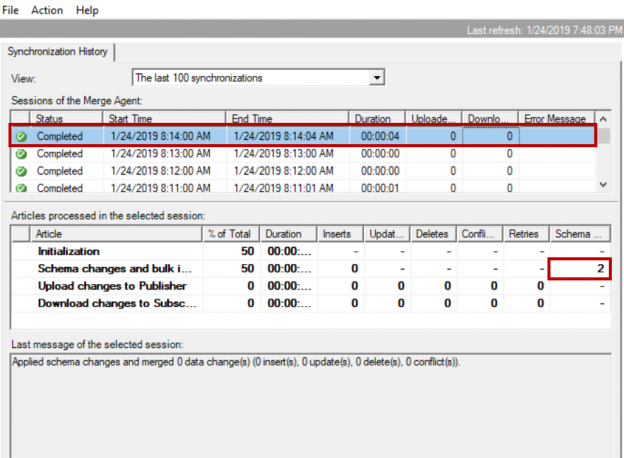
This article will review performance issues in replicating schema changes on tables involved in SQL Server Replication (Merge).
We had SQL Server merge replication configured on one of our databases to replicate data from publisher to subscriber and vice versa. Replicate schema changes was enabled on the publication to send the DDL changes made on replicated tables at publishers to subscribers.
When we applied the deployment scripts which modify the existing replicating tables by adding new columns or dropping existing columns at publisher, these schema changes took a lot of time to replicate to subscribers. Let us see what happens internally when there is a schema change on the table involved in SQL Server merge replication and why it is taking time to replicate schema changes.
To illustrate this let us create a merge publication with replicate schema changes option enabled.
Below are the server and database details in my environment. Please change the T-SQL scripts by replacing your publisher server, database and subscriber server, database names.
- Publisher Server: PUBSERV01
- Publication Database: test_pub
- Subscriber Server: SUBSERV01
- Subscriber Database: test_sub1
Please follow below steps to create table, publication, adding table to publication and creating subscribers using T-SQL scripts.
Configuring SQL Server Merge Replication
Create table “schema_test” in publisher database and enable database for SQL Server Replication (Merge).
|
1 2 3 4 5 6 |
use [test_pub] CREATE TABLE schema_test (ID INT ) use master exec sp_replicationdboption @dbname = N'test_pub', @optname = N'merge publish', @value = N'true' GO |
Now let us configure merge publication using T-SQL script. Execute sp_addmergepublication at publisher on database that is being published. Replace the snapshot folder as per your need.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
USE [test_pub] EXEC sp_addmergepublication @publication = N'test' ,@description = N'Merge publication of database ''test_pub''.' ,@sync_mode = N'native' ,@retention = 14 ,@allow_push = N'true' ,@allow_pull = N'true' ,@allow_anonymous = N'true' ,@enabled_for_internet = N'false' ,@snapshot_in_defaultfolder = N'false' ,@alt_snapshot_folder = N'D:\Replication\ReplData' ,@compress_snapshot = N'false' ,@ftp_port = 21 ,@ftp_subdirectory = N'ftp' ,@ftp_login = N'anonymous' ,@allow_subscription_copy = N'false' ,@add_to_active_directory = N'false' ,@dynamic_filters = N'false' ,@conflict_retention = 14 ,@keep_partition_changes = N'false' ,@allow_synctoalternate = N'false' ,@max_concurrent_merge = 0 ,@max_concurrent_dynamic_snapshots = 0 ,@use_partition_groups = N'false' ,@publication_compatibility_level = N'100RTM' ,@replicate_ddl = 1 ,@allow_subscriber_initiated_snapshot = N'false' ,@allow_web_synchronization = N'false' ,@allow_partition_realignment = N'true' ,@retention_period_unit = N'days' ,@conflict_logging = N'both' ,@automatic_reinitialization_policy = 0 |
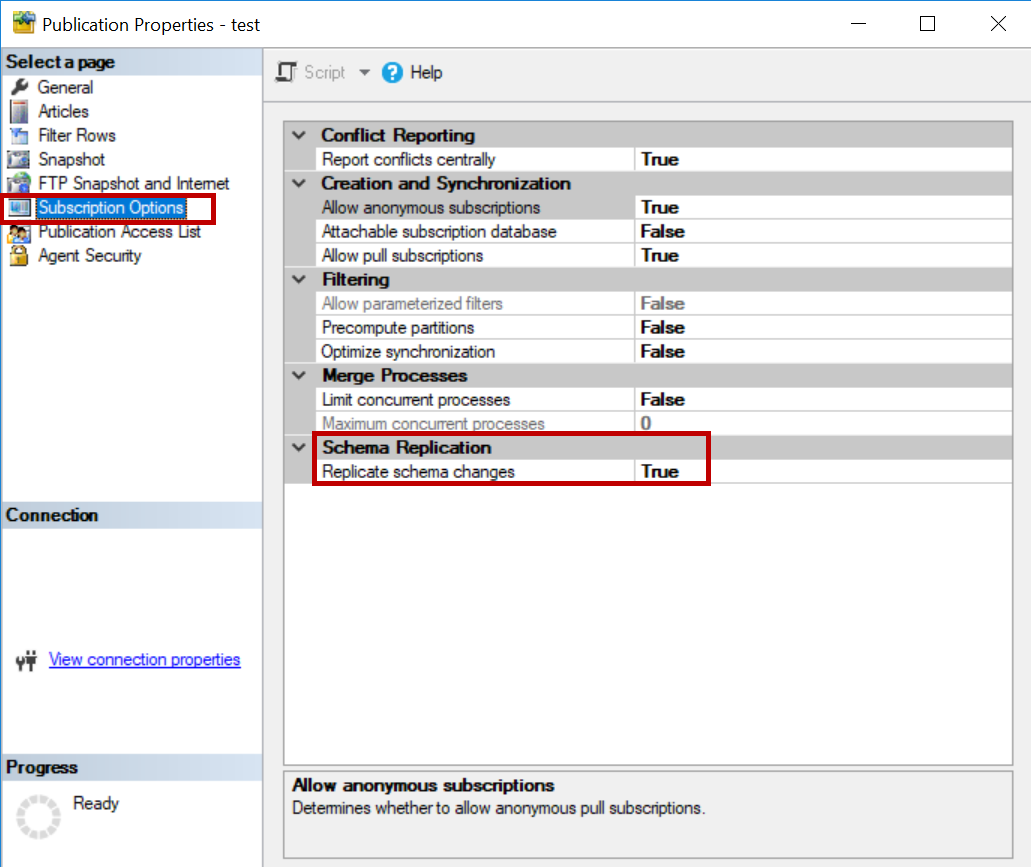
Once the publication is created, Navigate to the Local Publications under the replication folder in SQL Server Management Studio. Right click on the publication you created and click on Properties -> Subscription Options and make sure replicate schema changes is enabled.
Now add table “schema_test” to the merge publication created earlier. Execute below stored procedure on publisher database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
USE [test_pub] EXEC sp_addmergearticle @publication = N'test' ,@article = N'schema_test' ,@source_owner = N'dbo' ,@source_object = N'schema_test' ,@type = N'table' ,@description = N'' ,@creation_script = N'' ,@pre_creation_cmd = N'drop' ,@schema_option = 0x000000010C034FD1 ,@identityrangemanagementoption = N'none' ,@destination_owner = N'dbo' ,@force_reinit_subscription = 1 ,@column_tracking = N'false' ,@subset_filterclause = N'' ,@vertical_partition = N'false' ,@verify_resolver_signature = 1 ,@allow_interactive_resolver = N'false' ,@fast_multicol_updateproc = N'true' ,@check_permissions = 0 ,@subscriber_upload_options = 0 ,@delete_tracking = N'true' ,@compensate_for_errors = N'false' ,@stream_blob_columns = N'true' ,@partition_options = 0 |
Once the table is added to publication, create a snapshot agent for the publication “test”.
Here I used a snapshot agent to run under the SQL Server Agent process account. Make sure the account you to run the snapshot agent have the permission on the snapshot folder you used earlier.
Also, Replace the publisher_login and publisher_password with your own credentials which are used to connect publisher. This script should be executed on publisher database.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
USE [test_pub] EXEC sp_addpublication_snapshot @publication = N'test' ,@frequency_type = 1 ,@frequency_interval = 0 ,@frequency_relative_interval = 0 ,@frequency_recurrence_factor = 0 ,@frequency_subday = 0 ,@frequency_subday_interval = 0 ,@active_start_time_of_day = 500 ,@active_end_time_of_day = 235959 ,@active_start_date = 0 ,@active_end_date = 0 ,@job_login = NULL ,@job_password = NULL ,@publisher_security_mode = 0 ,@publisher_login = N'sa' ,@publisher_password = N'' |
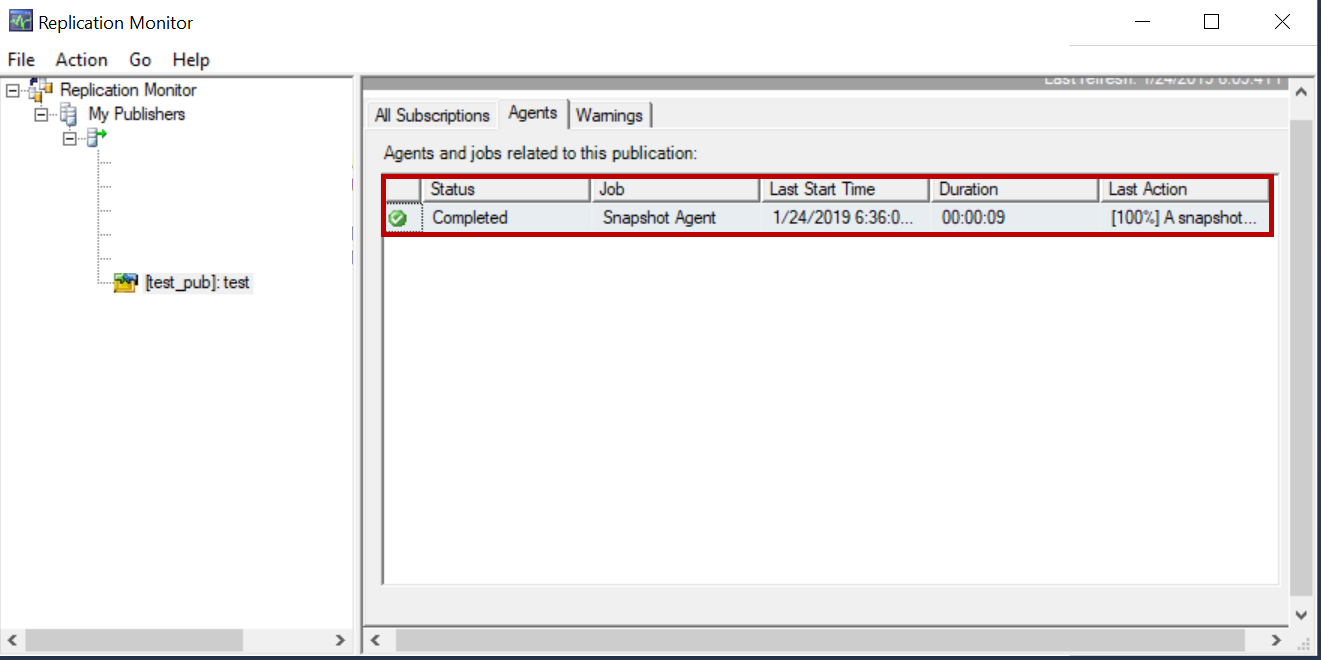
Right click on the publication you just created, launch SQL Server replication monitor Click on your publication (test) navigate to Agents Tab. Make sure the snapshot is completed.
Once the snapshot is completed add the subscriber to publication. Here in my case I used push subscription and the merge agent is scheduled to run for every one minute. This script needs to be run on publisher database.
Merge agent is configured to run under SQL Server Agent service account and SQL Server login “sa” was used to connect subscriber. Make sure the logins used for connecting subscriber has access to subscriber database.
Add subscription script varies in case of pull subscription.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
USE [test_pub] EXEC sp_addmergesubscription @publication = N'test' ,@subscriber = N'SUBSERV01' ,@subscriber_db = N'test_sub1' ,@subscription_type = N'Push' ,@sync_type = N'Automatic' ,@subscriber_type = N'Local' ,@subscription_priority = 0 ,@description = NULL ,@use_interactive_resolver = N'False' EXEC sp_addmergepushsubscription_agent @publication = N'test' ,@subscriber = N'SUBSERV01' ,@subscriber_db = N'test_sub1' ,@job_login = NULL ,@job_password = NULL ,@subscriber_security_mode = 0 ,@subscriber_login = N'sa' ,@subscriber_password = '' ,@publisher_security_mode = 1 ,@frequency_type = 4 ,@frequency_interval = 1 ,@frequency_relative_interval = 1 ,@frequency_recurrence_factor = 1 ,@frequency_subday = 4 ,@frequency_subday_interval = 1 ,@active_start_time_of_day = 0 ,@active_end_time_of_day = 235959 ,@active_start_date = 20190124 ,@active_end_date = 99991231 ,@enabled_for_syncmgr = N'False' ,@enabled_for_syncmgr = N'False' |
You can also use SQL Server Management GUI to configure publication, add tables to replication and to create subscribers.
- Please refer to my previous article on SQL Server Replication (Merge) – What gets replicated and what doesn’t which shows how to configure merge publication, adding tables and creating subscribers using SQL Server Management Studio.
Once the initial snapshot is applied on subscribers please refer to below steps.
SQL Server Replication (Merge) tracks the data changes using triggers. For each table added to merge replication three triggers one for insert, one for update and one for delete were created on the table. Also, few procedures, views and conflict table were created for each table added to merge publication. You can view them using table dependencies or you can query them using article id.
Navigate to the replicated table and right click on the table and click on View Dependencies.
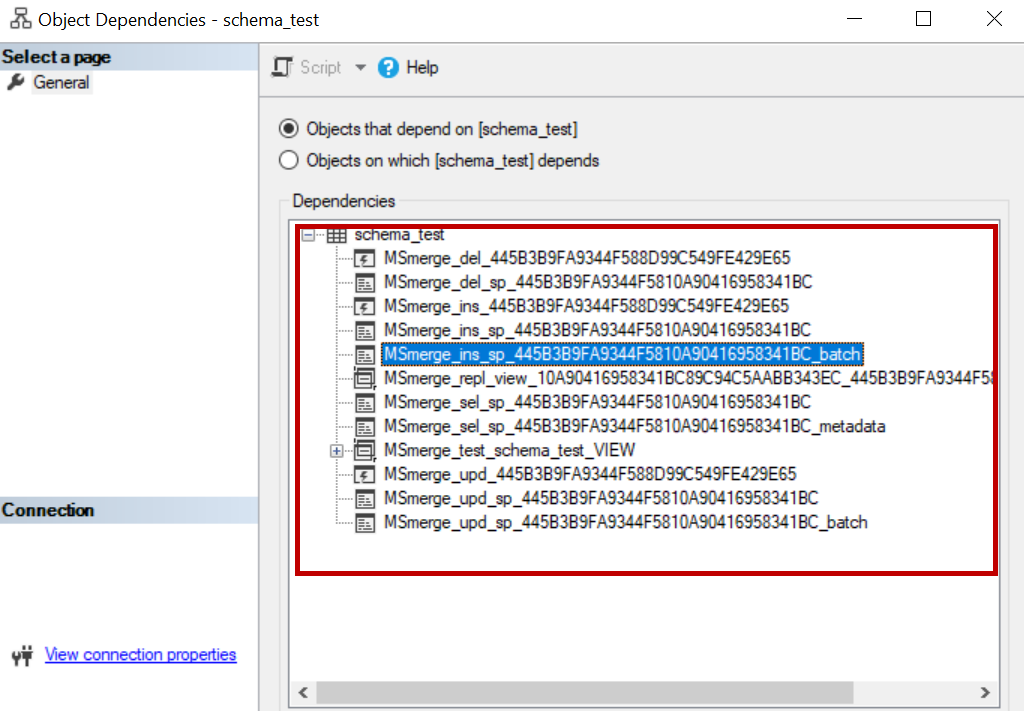
sysmergearticles has an entry of each table added to merge publication. This table has information about the procedures, conflict table, filters if configured, conflict table, conflict resolvers and identity ranges if auto identity management is chosen. Query this table on publisher database to find the article id of the table. Query sys.objects using the first part of the article id to find the objects related to replicated table.
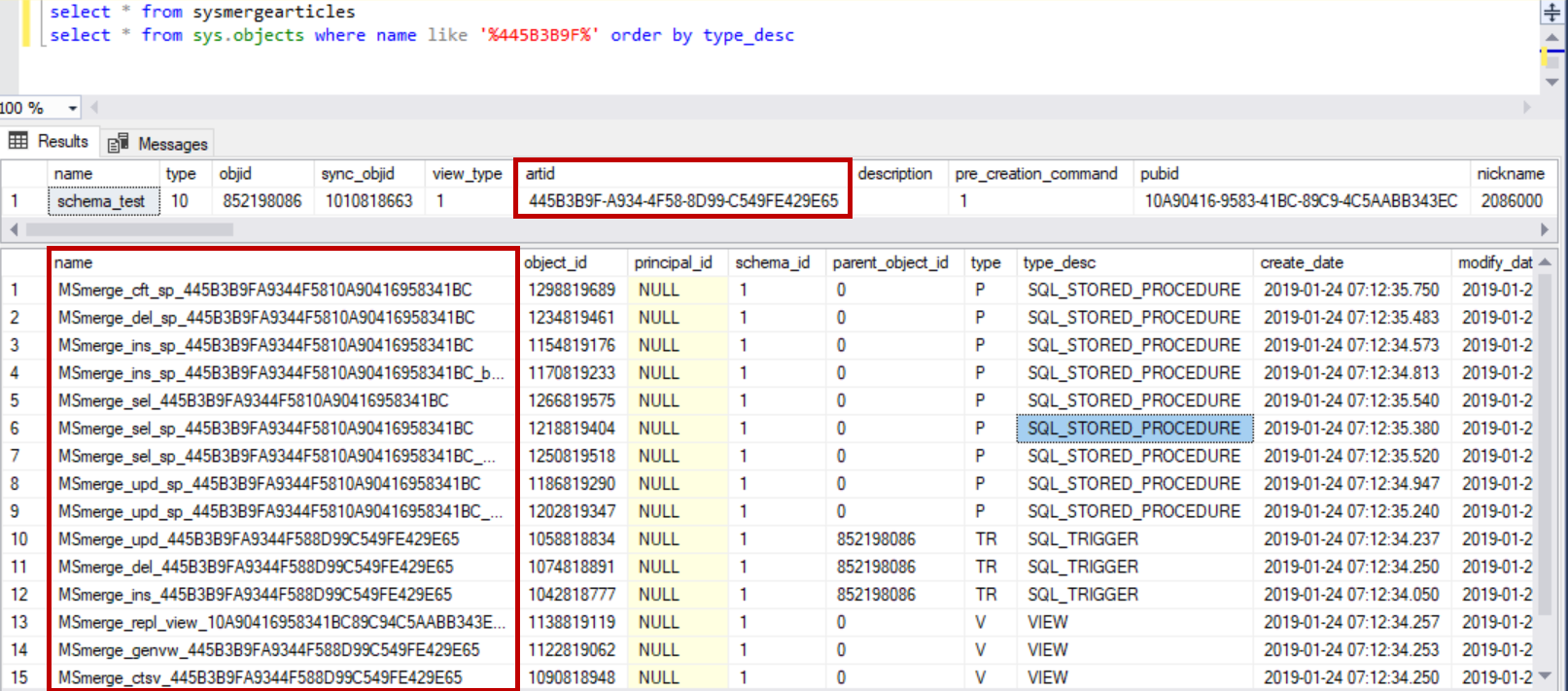
Now, on the publisher database, let us add new column to the table “schema_test”.
|
1 2 |
ALTER TABLE schema_test ADD ID2 INT |
After adding new column, the schema change commands were inserted in sysmergeschemachange table and all the procedures, triggers, views related to the article (table) were modified to incorporate newly added column.
From the below image we can see all the objects related to replicated table were modified.
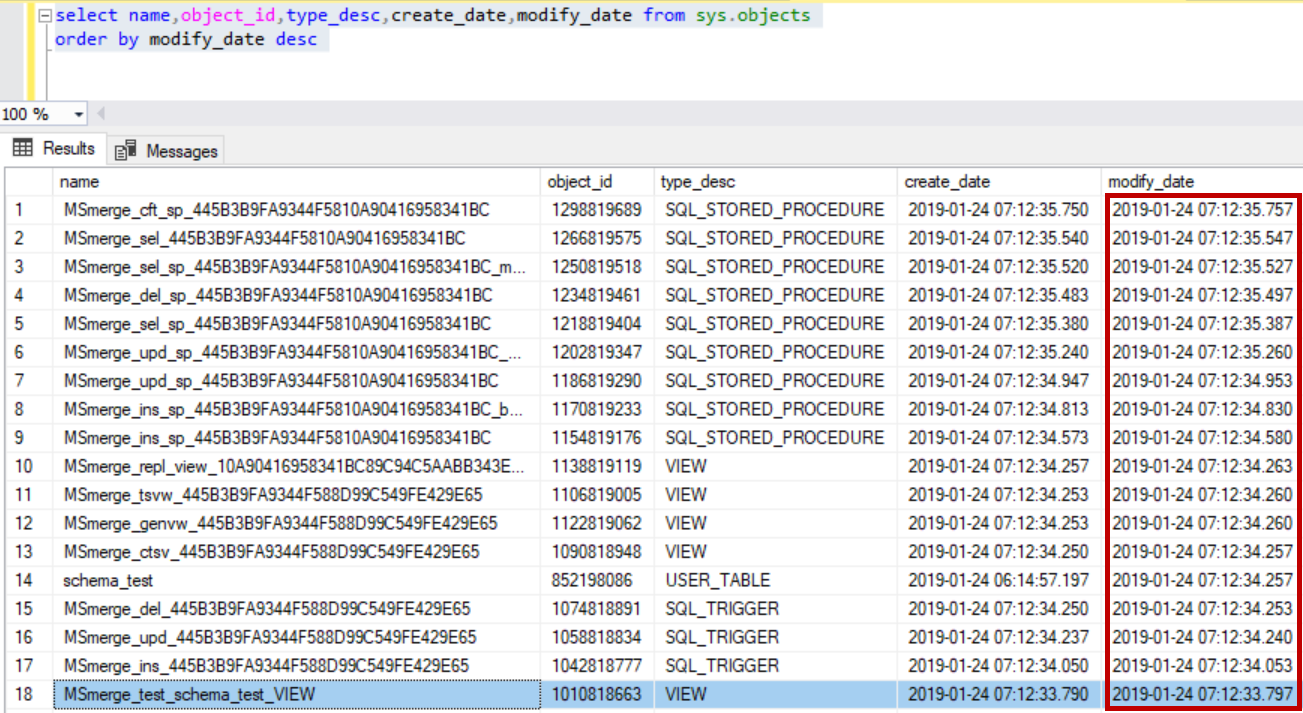
When the add new column command gets replicated to the subscriber these procedures, views, triggers were again modified at the subscriber as well to incorporate new column.
In my case, we received the deployment/upgrade script from developers with multiple ALTER TABLE statements to add new columns on same table as shown in below script.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
ALTER TABLE schema_test ADD ID3 INT ALTER TABLE schema_test ADD ID4 INT ALTER TABLE schema_test ADD ID5 INT ALTER TABLE schema_test ADD ID6 INT ALTER TABLE schema_test ADD ID7 INT ALTER TABLE schema_test ADD ID8 INT ALTER TABLE schema_test ADD ID9 INT ALTER TABLE schema_test ADD ID10 INT ALTER TABLE schema_test ADD ID11 INT ALTER TABLE schema_test ADD ID12 INT |
Now these changes were considered as individual DDL changes and all the objects related to the article were modified for each alter table statement issued on the replicated table.
For example, if we have 18 SQL Server Replication internal objects related to the article “schema_test” and we added 10 columns using 10 alter table statements. All these 18 objects are modified 10 times (Total modifications will be 180).
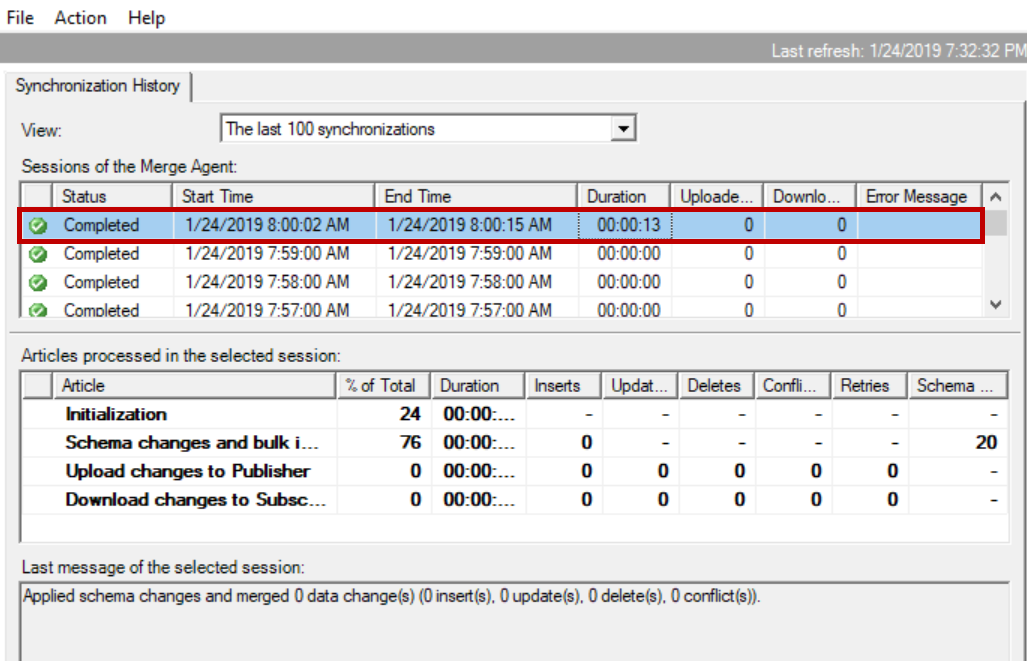
On the publisher database it took 15 seconds to add 10 columns if new columns were added in multiple ALTER TABLE statements:

Launch the SQL Server replication monitor and we can see it took 13 seconds to sync these changes to subscriber. This may vary if your table structure is complex. Sync time would go high if you have lot of tables involved merge replication and adding/dropping columns using multiple alter table statements more tables.
Now let us compare timings by adding 10 more columns to table “schema_test” using single ALTER TABLE statement as shown in below T-SQL script.
|
1 2 |
ALTER TABLE schema_test ADD ID13 INT, ID14 INT, ID15 INT, ID16 INT, ID17 INT, ID18 INT, ID19 INT, ID20 INT, ID21 INT, ID22 INT |
Now it took one second to add 10 new columns to the table “schema_test” because the SQL Server Replication internal objects were modified only once instead of 10 times.
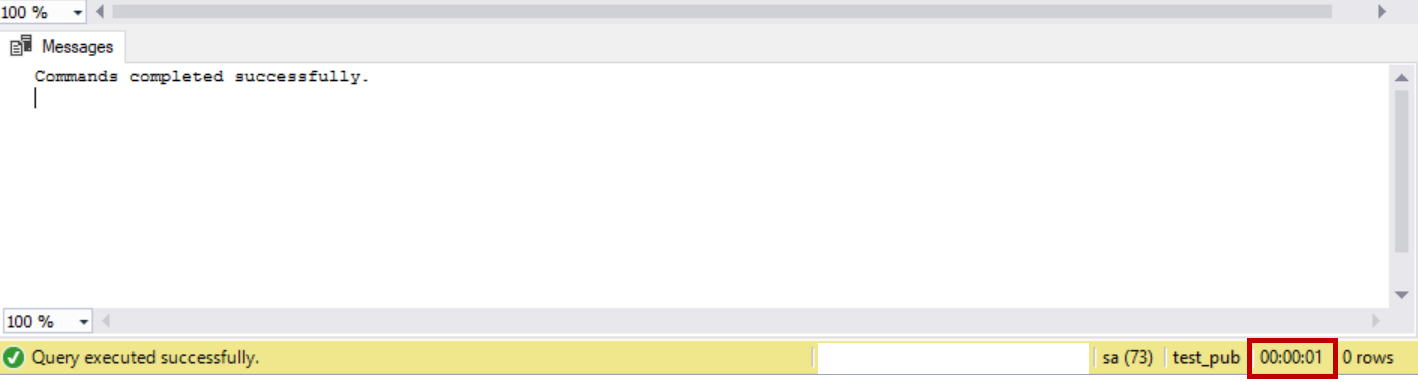
Launch the SQL Server replication monitor and check the sync timings. It took around four seconds to sync the schema changes to subscriber. Please refer to the below snapshot from replication monitor.
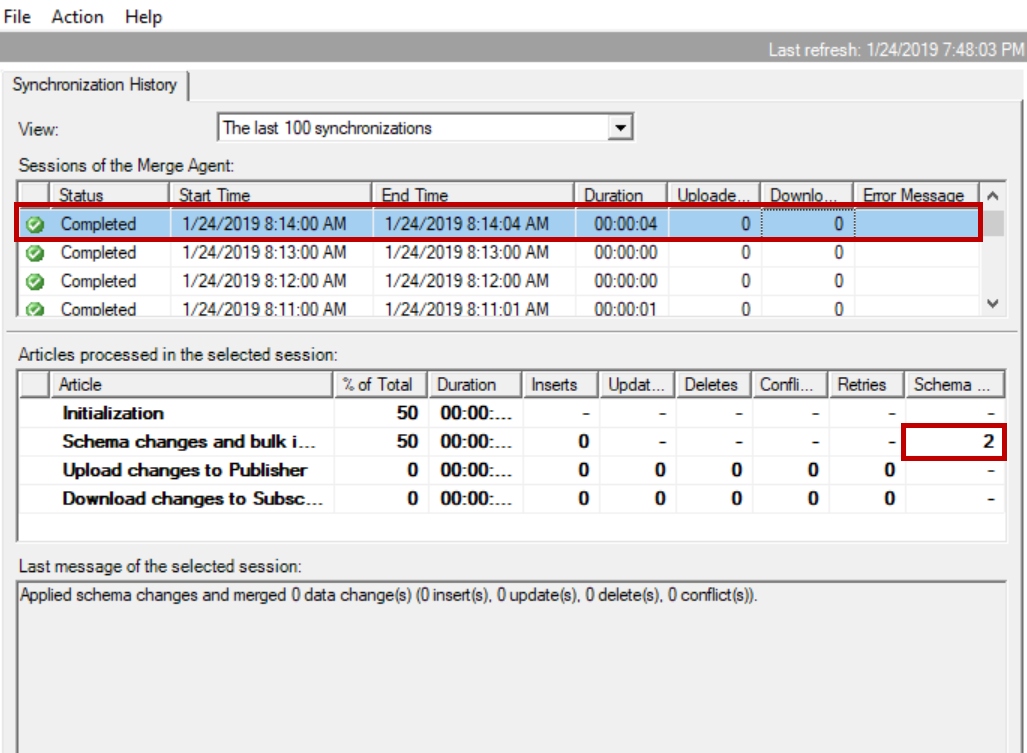
In this case the SQL Server Replication internal objects are modified only once at publisher and once at subscriber when the schema changes synced to subscriber. So, avoid using multiple ALTER TABLE statements to add columns or drop columns on the same table which is involved in merge replication.
When I performed same tests using transactional replication results are as below.
Using multiple ALTER TABLE statements in transactional SQL Server replication
At the publisher, adding 10 new columns with multiple ALTER TABLE statements took 3 seconds (As there are no systems objects created related to the replicated table like in merge replication)
To replicate these schema changes to subscriber it took 3 seconds.
Using single ALTER TABLE statement in transactional SQL Server replication
At the publisher, adding 10 new columns using single ALTER TABLE took less than a second and to replicate these schema changes to subscribers it took 1 second.
Using a single ALTER TABLE statement to add new columns or drop existing columns on same existing table is always better either in case of SQL Server merge replication or transactional replication.
Table of contents
| SQL Server Replication with a table with more than 246 columns |
| Foreign key issues while applying a snapshot in SQL Server merge replication |
| SQL Server Replication (Merge) – What gets replicated and what doesn’t |
| SQL Server Replication (Merge) – Performance Issues in replicating schema changes |
| Merge SQL Server replication parameterized row filter issues |
| SQL Server Replication on a mirrored database |
| Log shipping on a mirrored database |

- Geo Replication on Transparent Data Encryption (TDE) enabled Azure SQL databases - October 24, 2019
- Overview of the Collate SQL command - October 22, 2019
- Recover a lost SA password - September 20, 2019