
In this series of the SQL Server FILESTREAM (see TOC at bottom), We have gone through various aspects of this feature to store large size objects into the file systems.
In the previous SQL Server FILESTREAM articles, we have covered the following benefits from this feature:
- The benefit of NTFS data streaming
- Less overhead on SQL Server for the large BLOB objects
- Backup includes the metadata along with the FILESTREAM container data
- FILESTREAM also allows Point-in-time restore for the database
- FILESTREAM provides the transactional consistency also which is the primary requirement of any database
Now let’s review a few more features of SQL Server FILESTREAM.
FILESTREAM database Container
We cannot use the FILESTREAM container for another database. This restriction also applies to the subfolder of the FILESTREAM container. In the previous article, we used the file system ‘ C:\sqlshack\Demo’ for the sample database.
Database Name | FILESTREAM Container (file system location) | Remarks |
FileStreamDemodatabase_test | C:\sqlshack\Demo | It works fine. |
FileStreamDemodatabase_test _New | C:\sqlshack\Demo | Error: Since other database is using this location. |
FileStreamDemodatabase_test _New | C:\sqlshack\Demo\New | Error: we cannot use the child folder as well. In this case, the parent folder is being used by the FILESTREAM database ‘DemoSQL.’ |
Checking whether FILESTREAM is enabled or not in database
We can check whether the SQL Server FILESTREAM feature at database level using the filegroup.
|
1 2 3 |
Use FileStreamDemodatabase_test Go SELECT * FROM sys.filegroups |

The SQL Server FILESTREAM filegroup type is ‘FD’ therefore we can check the property using the above command, or we can use the print statement to give the output.
|
1 2 3 4 5 6 7 8 |
IF EXISTS ( SELECT * FROM sys.filegroups WHERE type = 'FD' ) BEGIN PRINT 'FILESTREAM Filegroup Exists for the database; you can check the Physical file location'+@Physicalfilename END ELSE BEGIN PRINT 'FILESTREAM Filegroup does not exist for this database' END |
If I run this query on the FILESTREAM database, we get the below output.

Otherwise, we get the output below.

Checking whether the table can hold FILESTREAM data using SQL Server FILESTREAM feature
We must have a UNIQUEIDENTIFIER column with ROWGUIDCOL property in the table to hold the FILESTREAM data. You can check this using join system tables and views.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
IF EXISTS ( SELECT * FROM sys.key_constraints sc INNER JOIN sys.indexes si ON sc.unique_index_id = si.index_id AND si.object_id = OBJECT_ID('DemoFileStreamTable_1') INNER JOIN ( SELECT * , COUNT(*) OVER ( PARTITION BY index_id, object_id ) AS ColCount FROM sys.index_columns ) ic ON ic.index_id = si.index_id AND ic.object_id = si.object_id INNER JOIN sys.columns c ON c.column_id = ic.column_id AND c.object_id = ic.object_id AND c.is_rowguidcol = 1 AND c.is_nullable = 0 WHERE is_unique_constraint = 1 OR ( is_primary_key = 1 AND ColCount = 1 ) ) BEGIN PRINT 'Specified table can have FILESTREAM columns; it is having ' END ELSE BEGIN PRINT 'You should modify the table to have UNIQUEIDENTIFIER column, currently it is not ready to have FILESTREAM columns' END |
We have included the table name in this query in which SQL Server FILESTREAM data needs to be added.

If the table does not meet the requirements, we get the following output:

Modifying existing VARBINARY(MAX) column to hold FILESTREAM data
We might have a requirement to change the existing Varbinary(max) column to a FILESTREAM column. It might be due to the old versions of SQL Server (older than 2008) does not support FILESTREAM. Therefore, if we want to convert the existing column to FILESTREAM, we require to copy the data (objects) into the file system container. We cannot directly modify the table property to reflect these changes.
Suppose we have a table ‘customers’, which also holds customer images into the varbinary(Max) column.
We need to perform the below steps to change this.
-
First, add a new varbinary (Max) column with FILESTREAM property: Use the below code to add this column.
1ALTER TABLE [dbo].[customers] ADD Image_temp VARBINARY(MAX) FILESTREAM NULL -
Copy data: We need to copy data from the existing column to the new FILESTREAM column. It generates the file in the FILESTREAM container for each update.
1UPDATE [dbo].[customers] SET ItemImage_New = Imagedata -
Drop old VARBINARY(MAX) column: Once we have copied the data into the FILESTREAM container, we can drop the old VARBINARY(MAX) column using below query.
1ALTER TABLE [dbo].[Items] DROP COLUMN ItemImage -
Rename the column: In this last step, we can rename the new column name to the original name so that we do not need to modify any dependent objects on it.
1234EXECUTE sp_rename@objname = '[dbo].[customers].ItemImage_New ',@newname = 'Imagedata',@objtype = 'COLUMN'
Identifying the SQL Server FILESTREAM filegroup name using the table name
We might want to know the FILESTREAM filegroup name in which the particular table belongs. We can do it using the join condition between catalog view sys.data_spaces and sys.tables. The catalog view (sys.data_spaces) shows the row for each data space such as filegroup, partition.

Now join this catalog view with sys.tables to get the detail of filegroup belonging to a table.
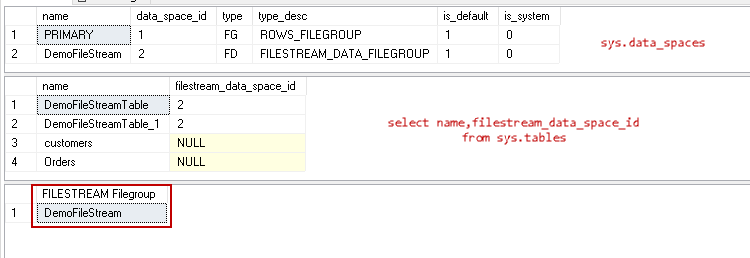
In the above image, we can see that the table belongs to ‘DemoFileStreamFILESTREAM filegroup.
Triggers for SQL Server FILESTREAM tables
We can create the DML triggers for the FILESTREAM columns as well in the table. Suppose we want to create a trigger for the update or insert activity notification any insert occurs in the FILESTREAM table using the AFTER INSERT trigger.
Execute the below code to create an AFTER INSERT trigger.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\WideWorldImporters-Full.bak', SINGLE_BLOB) as MyData; INSERT INTO DemoFileStreamTable_1 VALUES ( NEWID(), 'Installation file SQL', @File ) |
Now insert any FILESTREAM object in the table.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\WideWorldImporters-Full.bak', SINGLE_BLOB) as MyData; INSERT INTO DemoFileStreamTable_1 VALUES ( NEWID(), 'Installation file SQL', @File ) |
In the output, we get the message about the size of the inserted object.

Similarly, we can create AFTER UPDATE trigger and display the required message. For example, in the trigger below, we defined a message to print for every update in the FILESTREAM object.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TRIGGER TGR_FS_Update ON DemoFileStreamTable_1 AFTER UPDATE AS BEGIN DECLARE @Filesize INT SELECT @Filesize = DATALENGTH([FILE]) FROM INSERTED PRINT 'The updated size of the object in FILESTREAM is :' + STR(@Filesize) END |
Now, we are going to replace the existing file with a new file so the trigger will give the updated size of the FILESTREAM object.
|
1 2 3 4 5 6 7 |
UPDATE DemoFileStreamTable_1 SET [File] = (SELECT * FROM OPENROWSET( BULK 'C:\AdventureWorks2017.bak', SINGLE_BLOB) AS Document) WHERE fileid = '8662F1FA-8918-48D7-B752-AFBC0392902C' GO |
Once the update completes for the FILESTREAM table, we get the below message printed.

Multiple FILESTREAM filegroups
We might be using the FILESTREAM for a large number of objects and might be big files such as videos. In the database, we usually create multiple secondary data files on different disks to split the load from a single disk or data store. The question may arise here whether SQL Server allows creating multiple FILESTREAM filegroups. We can create multiple FILESTREAM filegroups due to the disk space limitation. We can also create multiple filegroups to get the benefits of the multiple disks IO read and write latency and performance.
You can notice in the below that we created the multiple FILESTREAM filegroups.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE DATABASE [FS_MultipleFG] ON PRIMARY ( NAME = N'FS_MultipleFG', FILENAME = N'C:\MS\FS_MultipleFG.mdf' , SIZE = 8192KB , FILEGROWTH = 65536KB ), FILEGROUP [FILESTREAM_1] CONTAINS FILESTREAM DEFAULT ( NAME = N'FS_FG_1', FILENAME = N'C:\MS\FS_FG_1' ), FILEGROUP [FILESTREAM_2] CONTAINS FILESTREAM ( NAME = N'FS_FG_2', FILENAME = N'C:\NPE\FS_FG_2' ) LOG ON ( NAME = N'FS_MultipleFG_log', FILENAME = N'C:\MS\FS_MultipleFG_log.ldf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) GO |
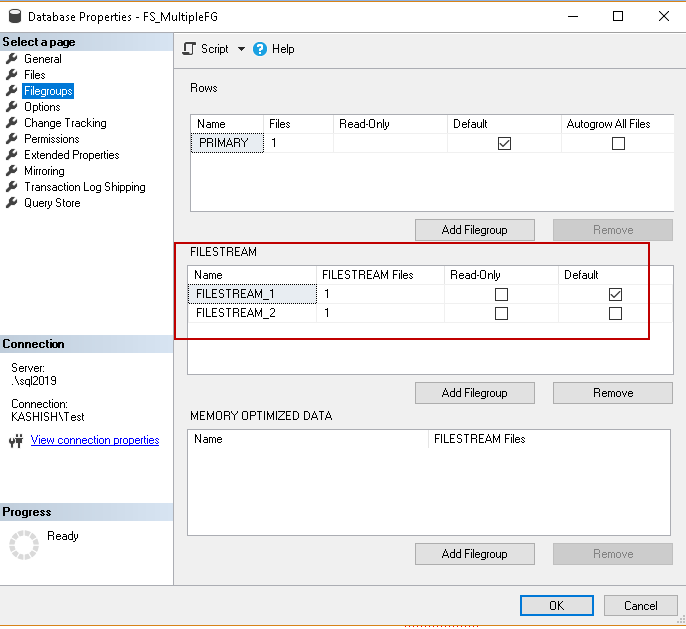
Execute the above code and open the database properties from SSMS. In the ‘Filegroups’ page, you can see two FILESTREAM filegroups and defined ‘FILESTREAM_1’ as default FILESTREAM filegroup.
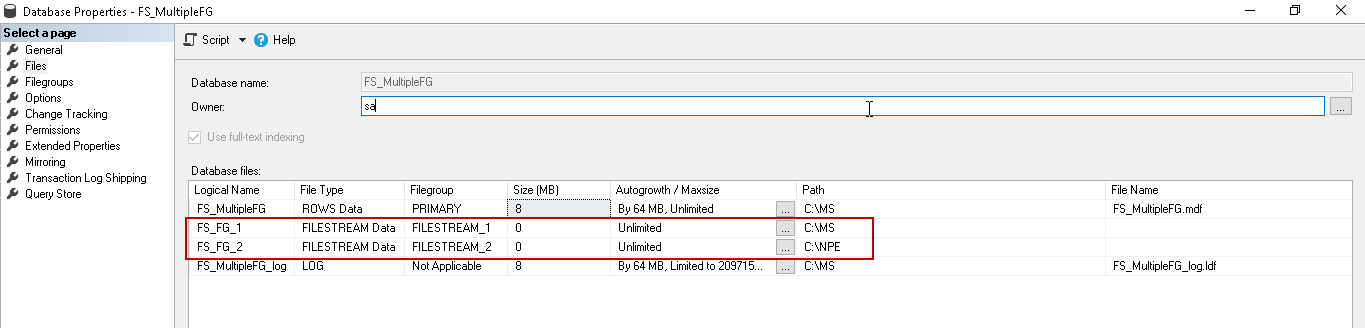
In the database files, we created multiple FILESTREAM files in the different filegroups.
We have multiple FILESTREAM filegroups in this database. Therefore, we need to define the FILESTREAM filegroup while creating the table. If we do not specify any filegroup, it uses the default FILESTREAM filegroup (in this example FILESTREAM_1) to create the object.
Let us create the tables to use the default FILESTREAM filegroup and specific FILESTREAM filegroup.
- Default filegroup: in the below command, we did not specify any FILESTREAM filegroup.
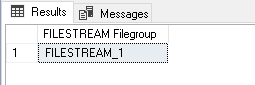
12345CREATE TABLE [DemoFileStreamTable_1] ([FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,[FileName] VARCHAR (25),[File] VARBINARY (MAX) FILESTREAM);GOIn the below image, we can see SQL Server created the table in the default FILESTREAM filegroup.

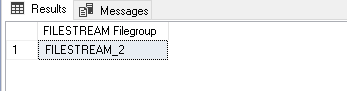
- Object creation in specific FILESTREAM filegroup: In the below code, we instructed SQL Server to create the table in the’ FILESTREAM_2′ filegroup.
123456CREATE TABLE [DemoFileStreamTable_2] ([FileId] UNIQUEIDENTIFIER ROWGUIDCOL NOT NULL UNIQUE,[FileName] VARCHAR (25),[File] VARBINARY (MAX) FILESTREAM)FILESTREAM_ON FILESTREAM_2GO
Conclusion
In this article, we explored various aspects the SQL Server FILESTREAM feature available from SQL Server 2008 onwards. I will continue writing on this topic to complete this series. Stay tuned for the next article.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023