
In this article, the latest in our series on the SQL FILESTREAM feature, we are going to look at the synergy and interoperability with SQL Server Full Text search, another powerful SQL Server feature
We can use SQL Server Full Text search to query on the columns containing character data. Suppose we have a column containing an employee names. We usually use the like operator to search against such column, but in this case, SQL Server needs to do a table scan to get the required data. SQL Server provides the ability to perform a SQL Server Full Text search against text columns. If we have millions of records in the SQL FILESTREAM table, it is difficult to search for the particular document containing a particular keyword without any index on it. SQL Server Full Text feature supports FILESTREAM tables as well. In this article, let us explore the combination of SQL FILESTREAM and .
Full Text search Installation
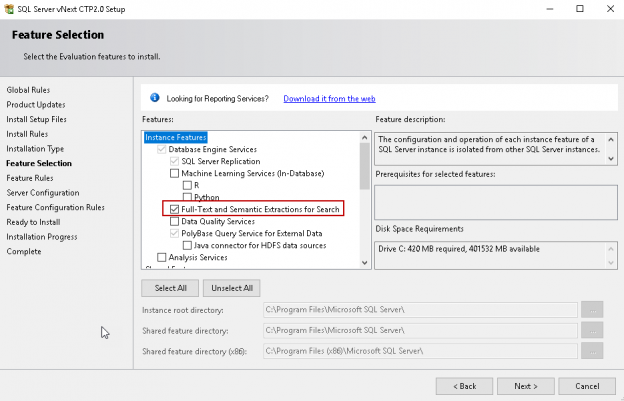
We can install the SQL Server feature during the installation wizard for option ‘Full Text and Semantic Extractions’. In this article, I am using the SQL Server 2019 version.
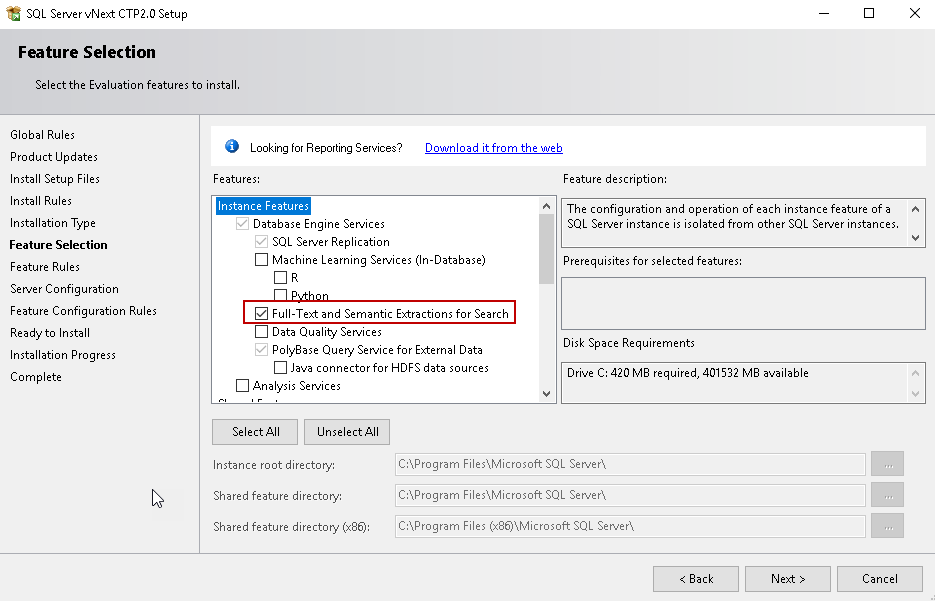
It installs a new service ‘SQL Full Text Filter Daemon Launcher’. You can check the status in the SQL Server Configuration Manager.
The SQL Server FILESTREAM feature stores files in the file system. If we have the documents in the file system for a SQL FILESTREAM table, we need to know the way to query for the FILESTREAM object. We have the following questions before we start exploring this feature.
- Is it possible to use SQL Server Full Text search on the SQL FILESTREAM objects?
- If we have the documents inside the file system, is it possible to search for a specific word from the document?
Pre-requisites:
We should have the following things ready before we proceed with this article
- Full Text Service should be in running status
- The SQL FILESTREAM feature should be enabled at the instance level
- A SQL Server FILESTREAM enabled database
Prepare the environment
Let us create a new SQL FILESTREAM table for this article using the below query. We need to have a column to store the document type in the FILESTREAM table. A document type is the extension of the document such as DOC, DOCX, XLS,.PDF.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE [dbo].[FILESTREAM_Documents]( [DocumentID] [uniqueidentifier] ROWGUIDCOL NOT NULL, [DocumentName] [varchar](128) NULL, [DocumentType] [varchar](10) NULL, [DocumentFS] [varbinary](max) FILESTREAM NOT NULL, UNIQUE NONCLUSTERED ( [DocumentID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] FILESTREAM_ON [DemoFileStream] GO |
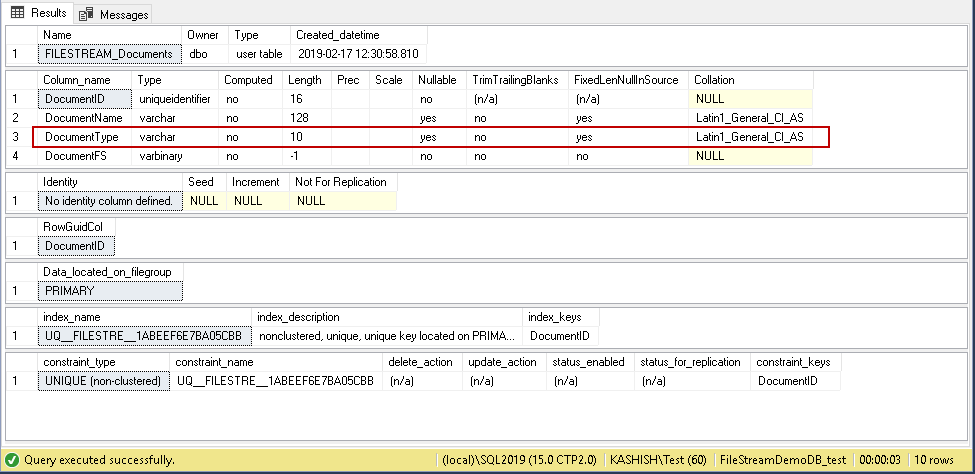
We can check the SQL FILESTREAM table properties using the sp_help command. In the following screenshot, you can look at the DocumentType column to store the files extension.
|
1 |
sp_help '[FILESTREAM_Documents]' |
We will insert the two documents in the FILESTREAM table.
-
Insert document named ‘ RS Scripter Load Log.txt” in the FILESTREAM table
12345678910111213141516DECLARE @File varbinary(MAX);SELECT@File = CAST(bulkcolumn as varbinary(max))FROMOPENROWSET(BULK 'C:\sqlshack\Draft articles\ RS Scripter Load Log.txt', SINGLE_BLOB) as MyData;INSERT INTO [FILESTREAM_Documents]VALUES(NEWID(),RS Scripter Load Log,'.txt ,@File)
-
Insert PDF file name SQL_Server_on_VMware-Best_Practices_Guide.PDF’ into the SQL FILESTREAM table
12345678910111213141516DECLARE @File varbinary(MAX);SELECT@File = CAST(bulkcolumn as varbinary(max))FROMOPENROWSET(BULK 'C:\Users\rajen_000\Documents\avis\PDF\SQL_Server_on_VMware-Best_Practices_Guide.pdf', SINGLE_BLOB) as MyData;INSERT INTO [FILESTREAM_Documents]VALUES(NEWID(),'SQL_Server_on_VMware-Best_Practices_Guide','.PDF' ,@File)
We can verify both the files insert successfully in the SQL FILESTREAM table as per the following images.

We can also check these files in the FILESTREAM container as well.

We need to configure SQL Server Full Text search on this FILESTREAM table to query on the document. We need to do the following tasks to use SQL Server Full Text search.
- Create a Full Text catalog
- Create a Full Text index on tables
Let us explore both the steps one by one.
Create a Full Text catalog
We need to create the Full Text catalog first. In SSMS, expand the FILESTREAM database, go to storage, and right click on the ‘Full Text Catalogs’ and select ‘New Full Text Catalog’.
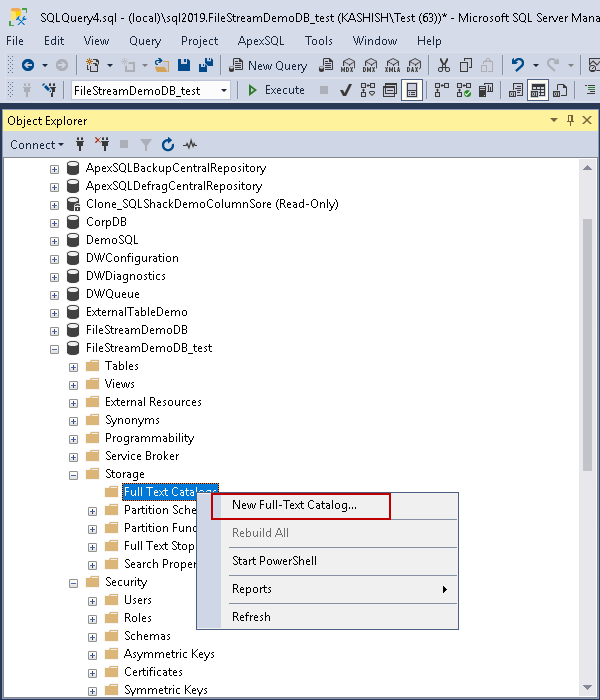
It opens the Full Text catalog window. Enter the name for the Full Text catalog and in the options make it as default catalog. We also have the option to make the accent sensitive to insensitive. Let us make the ‘Accent sensitivity’ insensitive.
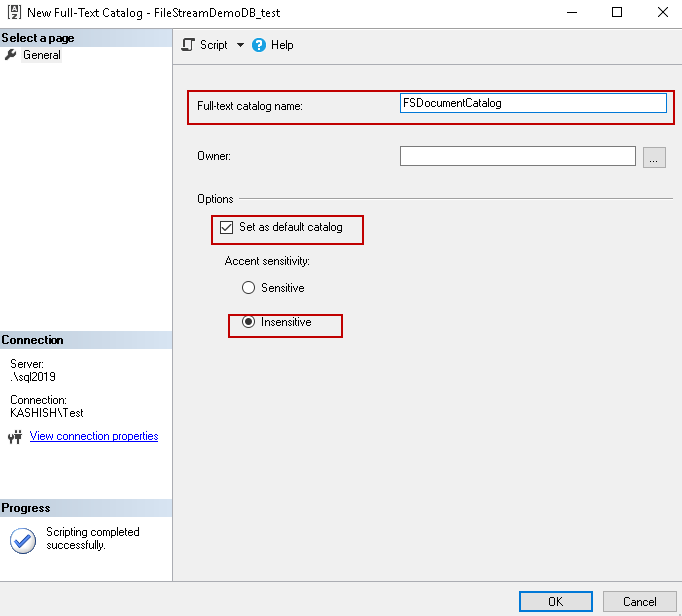
We scripted out the Full Text catalog query using the ‘script’ option at the top.
|
1 2 3 4 5 6 |
USE [FileStreamDemoDB_test] GO CREATE FULLTEXT CATALOG [FSDocumentCatalog] WITH ACCENT_SENSITIVITY = OFF AS DEFAULT GO |
Create a Full Text index on FILESTREAM tables
The next step is to create a Full Text index using the Full Text catalog we just created. We are going to create the Full Text index on the ‘[DocumentFS]’ column that stores the metadata for the document stored in the file system.
In the FILESTREAM, go the FILESTREAM table ‘[FILESTREAM_Documents]’, go to Full Text Index, and define Full Text index.
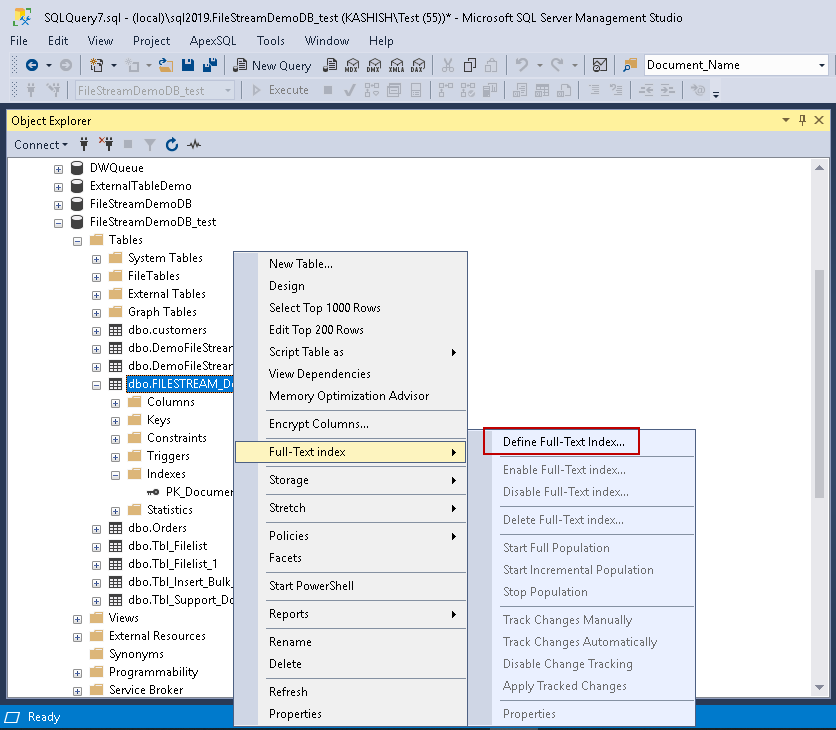
It opens up the SQL Server Full Text indexing wizard.
Click ‘Next’ and select the unique index for this table. We already have the index ‘ UQ__FILESTRE__1ABEEF6E7BA05CBB’ that you can see in the unique index list. If we do not have the unique index in the FILESTREAM table, we need to create it first.
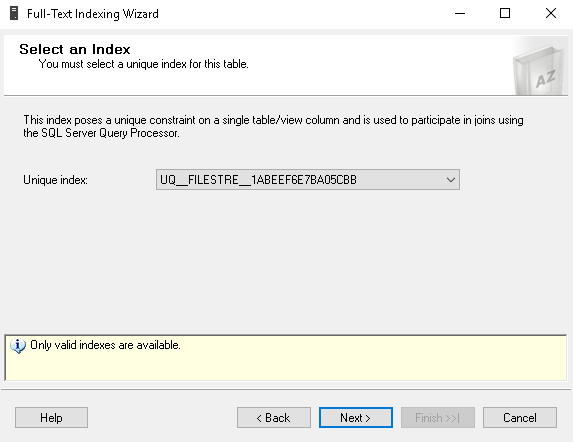
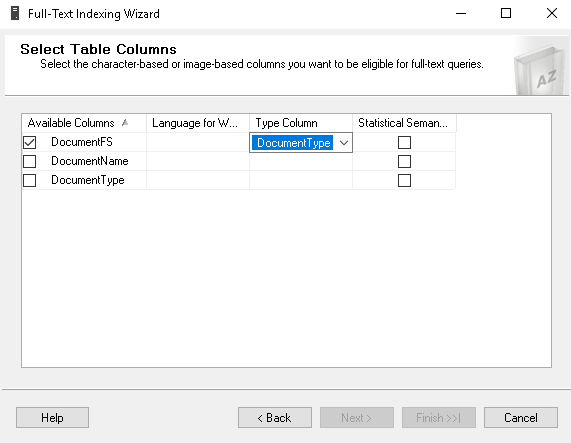
In the next page, we need to select the text-based column in which we want to perform the Full Text queries. We have selected the ‘documents’ FILESTREAM column. In the type column, we need to use the file extensions such as as.PDF, .txt. In the SQL FILESTREAM table ‘DocumentType’ column contains the file extension; therefore, we used this column in the ‘Type Column’. SQL Server Full Text uses the file extension to parse the data and provide the content for the specific word. We can also specify the language for the word breaker as well. Specifying the word breaker language is optional.
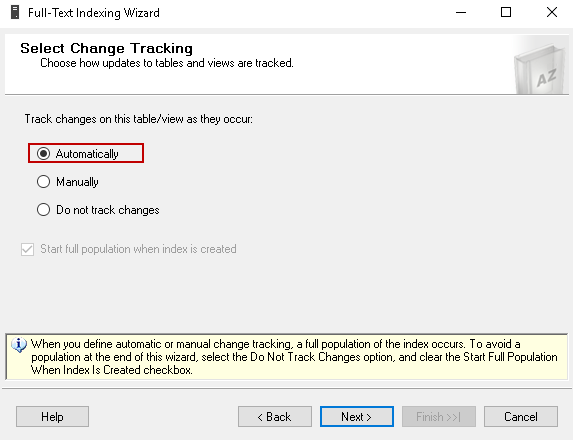
As a routine activity, we can do the insert, update or delete on the SQL FILESTREAM column as per application requirement. In this, we do not want to track changes on this table manually. In the next page, we can select the tracking type for this table.
- Automatic: it will automatically track the changes in the FILESTREAM table for the Full Text index
- Manual: We need to initiate the Full Text index population process manually
- No Tracking: We do not want any changes to be tracked in the SQL FILESTREAM table
When we define the automatic or the manual tracking option, it first initiates a full population of the Full Text index.
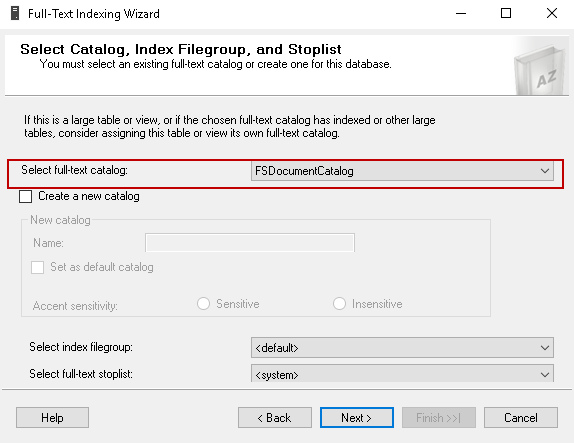
We can create the Full Text catalog from the following page of the wizard as well. We have already created the Full Text catalog, therefore, select the Full Text catalog and go to the next screen. In this example, we do not want to specify the index filegroup and Full Text stoplist. We are going to leave these options as default.
In the following page, we can define the Full Text catalog population schedule. It is an optional page. Therefore, skip this page.
Now, verify the description of the work being performed by the Full Text catalog wizard and ‘Finish’ to start the process.
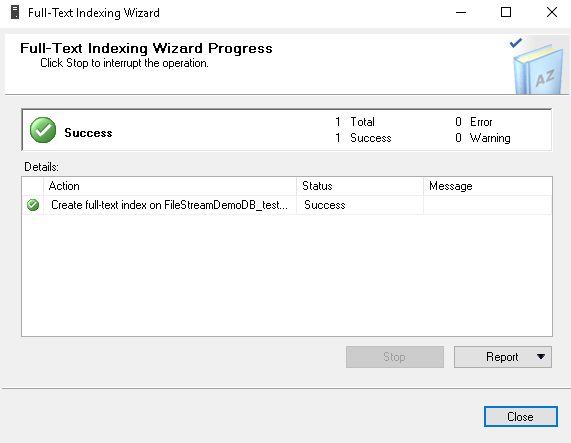
In the following image, you can observe that we have created the Full Text index successfully on the FILESTREAM table.
Now we are ready to query the SQL FILESTREAM table using the Full Text index. Suppose we have a large number of documents in the FILESTREAM table and we want to know the list of documents containing a particular keyword. We can use the predicates CONTAINS and FREETEXT in the select statement to query using SQL Server Full Text search on the FILESTREAM table.
Suppose we want to get the list of the document containing word ‘Server’. We can run the following query in the FILESTREAM database. You can notice query using the CONTAINS predicate to query using SQL Server Full Text search.
|
1 2 |
select * from [FILESTREAM_Documents] where contains ([DocumentFS],'Server') |
It returns the document name for the specified condition.

Let us run another query to find out the document containing the word ‘VMWare’. In the following screenshot, you can see the name of the document after SQL Server Full Text search.
|
1 2 |
select * from [FILESTREAM_Documents] where contains ([DocumentFS],'VMWare') |

We can use the FREETEXT predicate to search for all the documents that contain the words ‘ VMware Best Practices Guide’.
|
1 2 |
select * from [FILESTREAM_Documents] where FREETEXT ([DocumentFS],'VMware Best Practices Guide') |

One more example to search the document having the word ‘GFM_Load_Reports.’
|
1 2 |
select * from [FILESTREAM_Documents] where FREETEXT ([DocumentFS],'GFM_Load_Reports') |

We have defined the change tracking as automatic while creating the Full Text index. If there are any changes in the FILESTREAM table, it should track the changes automatically. We should be able to query the FILESTREAM table using the Full Text index for the changes as well. Let us insert one more PDF document in the FILESTREAM table using the following query.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE @File varbinary(MAX); SELECT @File = CAST( bulkcolumn as varbinary(max) ) FROM OPENROWSET(BULK 'C:\Users\rajen_000\Documents\avis\PDF\asa_9_db_admin_guide.pdf', SINGLE_BLOB) as MyData; INSERT INTO [FILESTREAM_Documents] VALUES ( NEWID(), 'asa_9_db_admin_guide', '.PDF' , @File ) |
We have three documents in the FILESTREAM table now. FILESTREAM table contains the text and PDF documents in the FILESTREAM container.

In the new inserted document, we have the word Sybase while the other two documents do not contain that word. We should get only the latest document name if we search for the keyword ‘Sybase’. Execute the below query in the FILESTREAM database.
|
1 2 |
select * from [FILESTREAM_Documents] where Contains ([DocumentFS],' Sybase') |
In the result set, you can see we get the correct document name. We did not execute the full-index catalog full or incremental population manually.

Conclusion
In the article, we explored the powerful combination of SQL FILESTREAM and SQL Server Full Text search. With the combination of these features, we can easily search for a required file or document with a particular keyword.
Table of contents

I am the author of the book "DP-300 Administering Relational Database on Microsoft Azure". I published more than 650 technical articles on MSSQLTips, SQLShack, Quest, CodingSight, and SeveralNines.
I am the creator of one of the biggest free online collections of articles on a single topic, with his 50-part series on SQL Server Always On Availability Groups.
Based on my contribution to the SQL Server community, I have been recognized as the prestigious Best Author of the Year continuously in 2019, 2020, and 2021 (2nd Rank) at SQLShack and the MSSQLTIPS champions award in 2020.
Personal Blog: https://www.dbblogger.com
I am always interested in new challenges so if you need consulting help, reach me at rajendra.gupta16@gmail.com
View all posts by Rajendra Gupta
- Understanding PostgreSQL SUBSTRING function - September 21, 2024
- How to install PostgreSQL on Ubuntu - July 13, 2023
- How to use the CROSSTAB function in PostgreSQL - February 17, 2023